
什么是Amundsen数据目录?
Amundsen是Lyft开发的一个数据发现平台和元数据引擎,旨在解决数据科学家、工程师和研究人员在典型工作流程中面临的常见痛点。
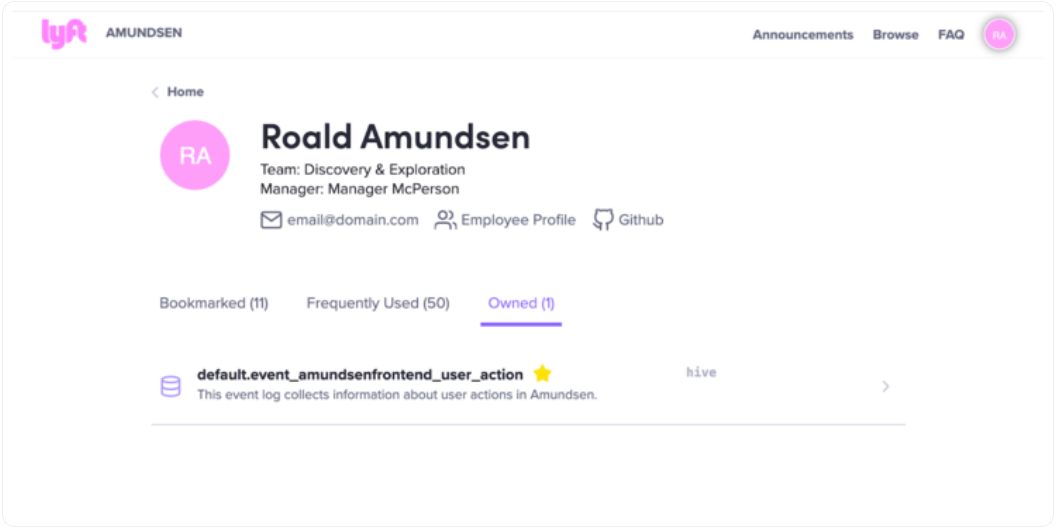
阿蒙森由Lyft工程团队土生土长,以挪威探险家罗尔德·阿蒙森的名字命名,他因领导第一次成功的南极探险而闻名。
阿蒙森将Lyft的数据科学家、分析师和研究人员的生产力提高了约20%
Lyft为什么要建造Amundsen?
Lyft报告称,2021年第一季度的活跃骑手基数为1349万。现在,想象一下,这个数字反过来会产生大量的数据来存储、处理和分析,还有大量的人可能每天都在使用这些数据来做出明智的决定。
在Lyft这样一家基本上现代的数据驱动公司,每一次互动都是由数据驱动的,如果数据团队没有能力高效地使用这些数据,就不可能可持续地扩展。
Lyft认识到了这一挑战,并开发了Amundsen,他们于2019年4月推出了该产品,以解决数据发现难题。
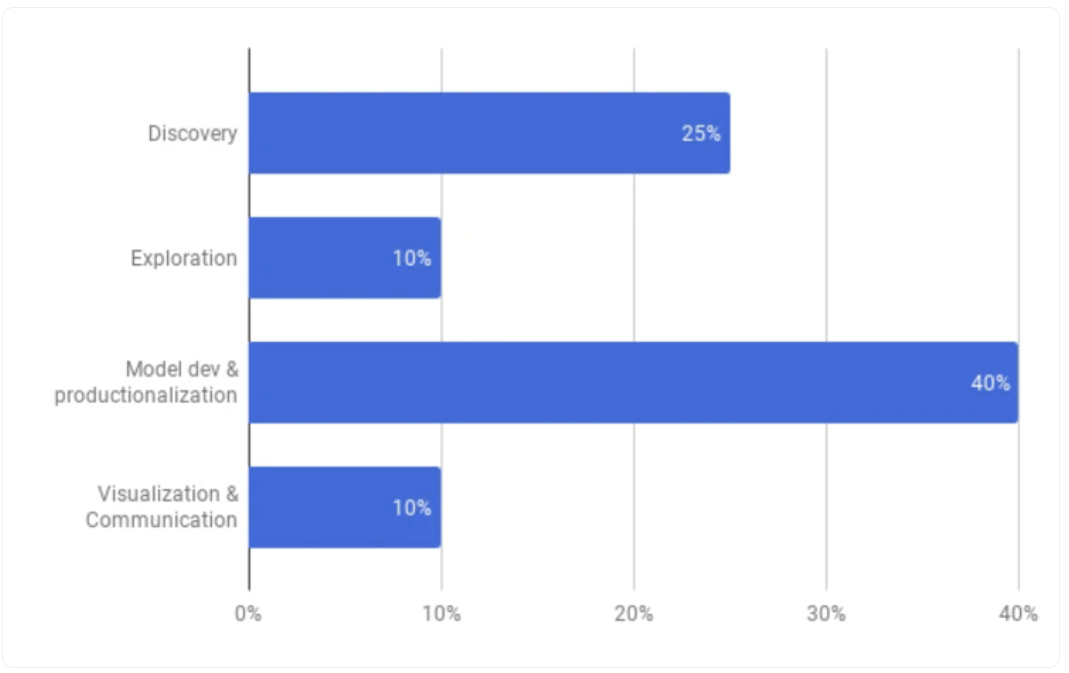
Lyft创造了阿蒙森,使其能够
- 从所有不同的数据源捕获元数据
- 生成数据在其生命周期中如何演变的可见性(通过元数据)
- 通过前端与用户共享此元数据,使他们能够发现、信任和使用数据。
Amundsen数据目录是开源的吗?
Amundsen于2019年10月开源,一年前在Lyft投入生产,并根据Apache许可证2.0版获得许可。许可证的副本可以在这里找到。以下是管理许可证的权限、限制和条件的汇总。
Amundsen was donated to Linux Foundation AI in July 2020.
Amundsen据目录是如何工作的?
阿蒙森数据目录主要致力于让用户能够发现、信任和理解他们的数据。阿蒙森的各种特征共同作用,实现了同样的目的。以下是阿蒙森的主要能力:
- 轻松发现可信数据
- 自动化和精心策划的元数据
- 能够与同事共享上下文
- 从数据使用中学习和理解
轻松发现可信数据
阿蒙森通过简单的文本搜索帮助查找组织内的数据。搜索结果在一定程度上显示了内联元数据,其中包括数据的描述以及数据更新的最后日期。受页面排名启发的算法返回受欢迎程度排名和推荐——查询量高的表会被提升到更高的位置以供考虑,而使用量最小的表会在稍后的结果中填充。

自动化和精心策划的元数据
当点击数据资产时,会向用户显示其详细描述和行为。详细描述包括用户手动整理的信息。有关数据行为的信息是通过浏览审计日志生成的。通过设计,鼓励用户使用基于受欢迎程度的列级数据。用户还可以看到受欢迎的用户和数据的一般概况。
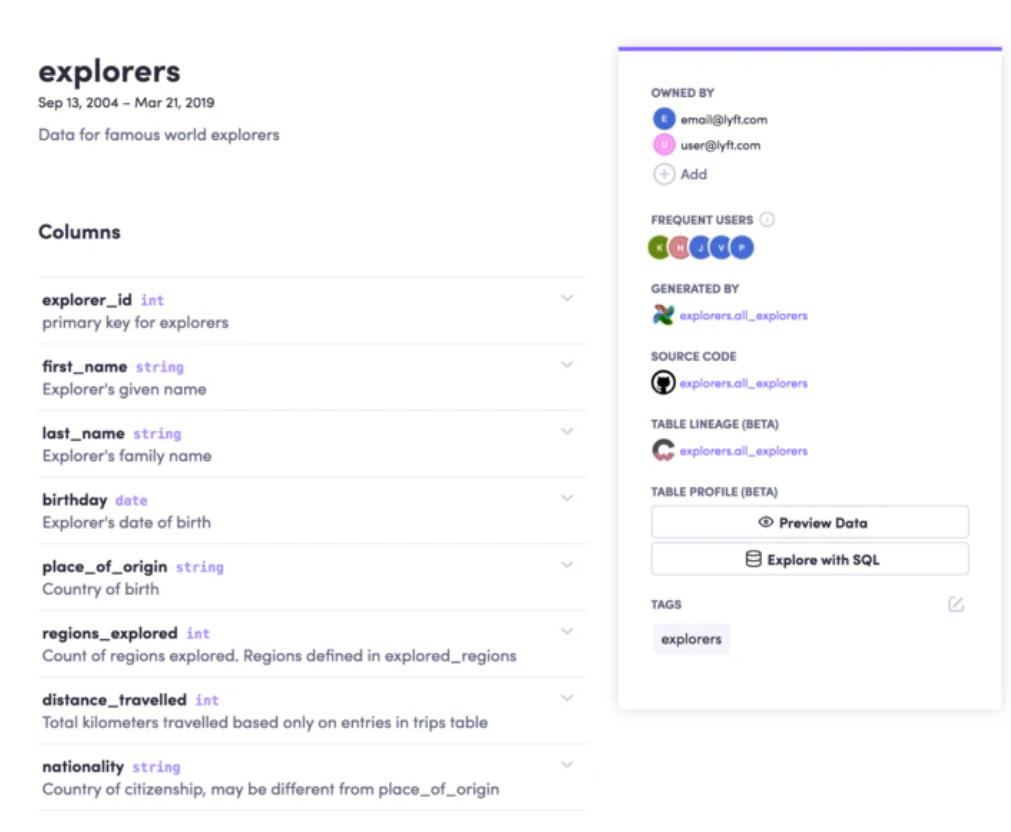
能够与同事共享上下文
人们可以更新对数据资产的描述,从而减少在特定数据资产中寻找更多上下文的同事之间的来回交流——例如,用描述更新表和列可以为数据用户提供关于哪个表最适合特定查询以及该表中哪个特定查询特别感兴趣的必要信息。
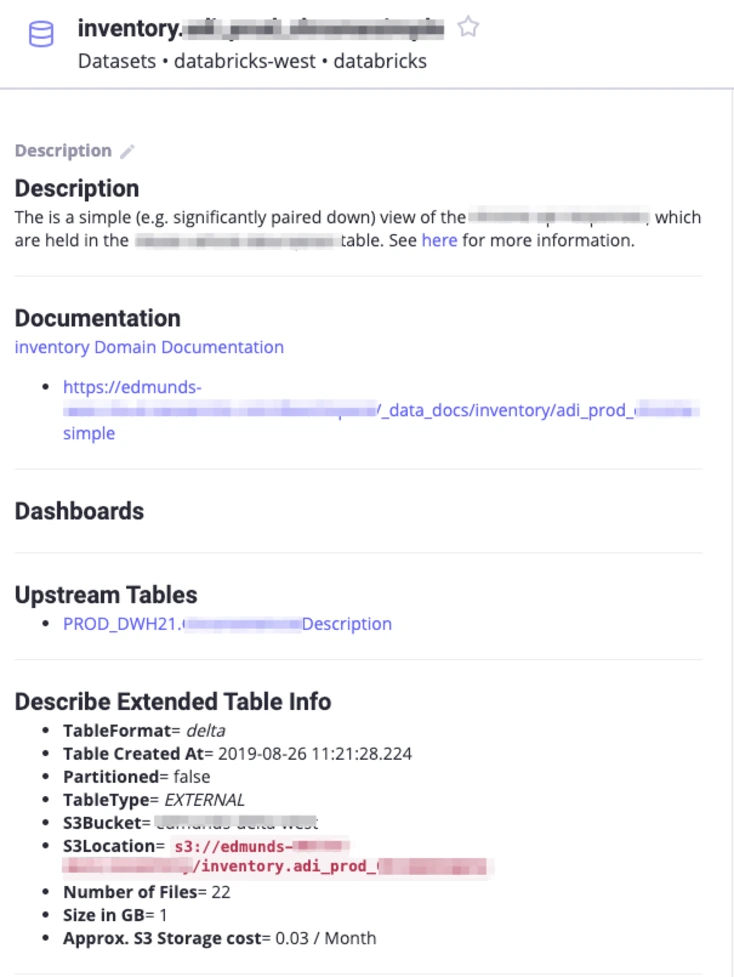
从数据使用中学习和理解
用户可以查看哪些数据资产被频繁使用、拥有或添加书签。通过查看在给定表上构建的仪表板,甚至可以理解表的最常见查询。这被归类为行为元数据,并且是自动策划的。
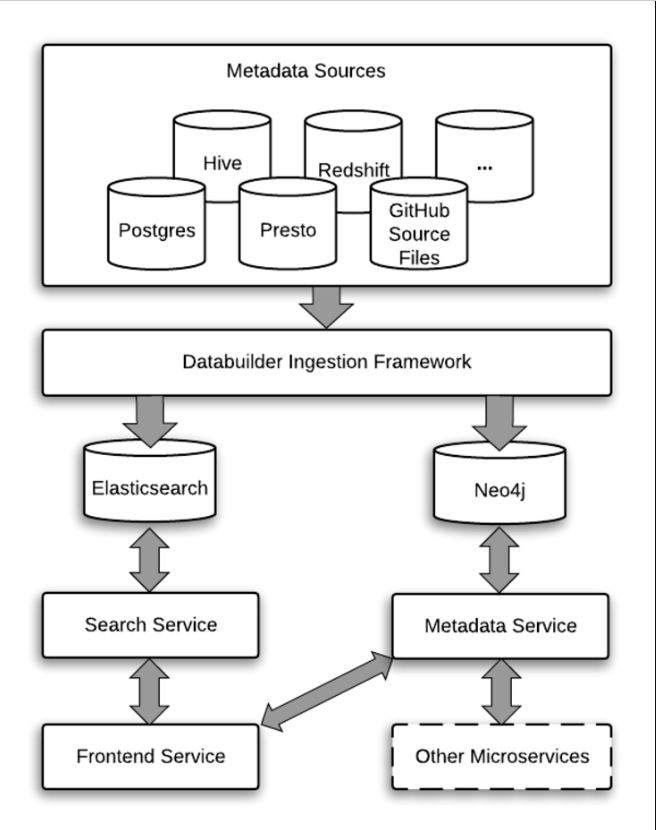
Lyft Amundsen架构
Lyft的Amundsen由五个主要组件组成,并遵循微服务架构:
- 元数据服务:能够处理来自前端服务和微服务的请求
- 搜索服务:支持弹性搜索
- 前端服务:承载web应用程序
- 数据构建器:从各种来源提取元数据的摄入框架
- 公共组件:保存微服务之间公共代码的库存储库
元数据服务
能够处理来自前端服务和微服务的请求。从本质上讲,元数据通过前端服务公开给最终用户,也用于Lyft的其他服务。值得注意的是,元数据实体目前在阿蒙森上建模为图形,这使得在生成更多实体时更容易扩展模型。
搜索服务
由Elastic搜索支持-搜索服务提供API,将资源索引到搜索引擎中,并通过前端服务为最终用户的搜索查询提供服务。目前,阿蒙森支持以下类型的搜索:
- 普通搜索:指定特定术语和资源术语的搜索
- 类别搜索:过滤的资源如果搜索词与元数据类别匹配,则在提供结果时会考虑相关性
- 通配符搜索:用户可以对不同的资源进行通配符搜索
前端服务
承载web应用程序。它由两个不同的部分组成:
- 用于编写用户界面的React应用程序
- 充当元数据或搜索服务请求中介的Flask服务器
数据生成器
ETL Ingestion框架从各种来源提取元数据。据说它受到了阿帕奇哥布林的高度启发。数据生成器的每个组件都是高度模块化的。组件包括:
- Extractor
- Transformer
- Loader
- Publisher (optional)
通用组件
Amundsen微服务的公共代码库
Lyft的数据发现民主化
Lyft有750名数据用户使用Amundsen。
数据团队多种多样。数据工程师、数据科学家、分析师、产品经理和高管都在寻找数据来处理和做出明智的决策。当每个寻找数据资源的人都确切地知道系统中有哪些可用数据以及如何使用这些数据时,真正的民主化是可能的,但这也可能对数据隐私和安全带来挑战。阿蒙森试图通过将元数据分为两组来平衡民主化和安全:
基本元数据
基本元数据,如表和字段的名称和描述、所有者、上次更新等,对所有人都可见。这使用户能够发现它的存在,并了解它是否适合他们的查询。
更丰富的元数据
更丰富的元数据,如列统计数据、预览等,仅对有数据访问权限的用户可用。如果人们确信更丰富的元数据适合他们,他们也可以请求访问这些元数据。
Lyft Amundsen关键链接
- Lyft Amundsen Website
- Lyft Amundsen GitHub
- Experience Amundsen hands-on: Access a sandbox environment loaded with sample data
Mail Lists:
让您开始使用Amundsen的资源:
- Amundsen demo: Take a test drive and get a feel for how the Amundsen data catalog works. Get access to a sandbox instance populated with sample data.
- Amundsen setup: We will guide you through the steps required to configure and install Amundsen.
- A step-by-step walk-through of setting up Amundsen data lineage with dbt
区别是什么:比较开源数据发现工具
- Learn more about how Amundsen compares with other open source data catalog and metadata tools:
- Lyft Amundsen Vs. Linkedin DataHub: A deep dive into how Amundsen and DataHub compare in terms of architecture, metadata ingestion, ease of deployment, and core data discovery features.
- Lyft Amundsen Vs. Apache Atlas: Read more about how Amundsen and Apache Atlas compare and contrast in data discovery, data catalog, and data lineage features.
- Understanding AWS Glue data catalog: Architecture, components, and crawlers
了解有关数据目录的详细信息:
- Evaluating a data catalog? Here are the 5 essential features to look for in a modern data catalog
- Data Catalog: The Must-Have Tool for Data Leaders in 2023
- What are the benefits of a data catalog? 5 key reasons why you need one
- Data catalogs are going through a paradigm shift! Here is everything you need to know about the Third-Generation Data Catalog.
- Learn more about Atlan: The pioneering third-generation data catalog for modern data teams.
Amundsen在Lyft中被广泛采用,并拥有一个由扩展和使用它的个人和组织组成的有凝聚力的社区。然而,与任何其他开源工具一样,它是由工程师和工程师制作的,因此设置起来相当技术化。
最新内容
- 35 minutes 51 seconds ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago