
category
与大型语言模型(LLMs)相关的产品和服务的增长非常显著。很明显,小语言模型(SLM)正准备破坏这个生态系统。
大量的小型语言模型(SLM)是开源的,可以通过HuggingFace轻松下载并准备进行本地离线推理。
LLM能力概述
在讨论SLM之前,需要考虑LLM的当前用例。
大型语言模型有几个关键特征,这些特征推动了它的采用。这些措施包括:
- 自然语言生成
- 常识推理
- 对话和会话上下文管理
- 自然语言理解
- 非结构化输入数据
- 知识密集型
除了LLM是知识密集型的这一事实之外,所有这些能力都在它的承诺中实现了。
虽然LLM是知识密集型的,但这一特征使企业失败的原因如下:
- LLMs已经证明它会产生幻觉。幻觉可以被描述为LLM产生高度简洁、合理、可信和上下文准确的反应的情况。但是,这实际上是不正确的。
- LLM对基础模型的训练数据有一个截止日期。除了有一个知识结束的日期外,法学硕士并不掌握所有的知识。
- 法学硕士不具备行业、组织或公司特定的知识和信息。
- 更新LLM需要对基础模型进行微调,这需要数据准备、成本、测试等。这为LLM引入了一种非梯度不透明的数据传输方法。
检索增强生成(RAG)
为解决这个问题而引入的解决方案是RAG。
当涉及到小语言模型(SLM)时,RAG起到了均衡器的作用。RAG补充了SLM内部缺乏知识密集型能力的问题。
除了缺乏一些知识密集型功能外,SLM还具备上述其他五个方面的能力。
微软Phi-2
微软最近开源了他们的Phi-2型号,利用LM Studio,我可以在MacBook上本地下载并运行SLM。模型细节如下:
{
"name": "Phi2",
"arch": "phi2",
"quant": "Q2_K",
"context_length": 2048,
"embedding_length": 2560,
"num_layers": 32,
"rope": {
"dimension_count": 32
},
"head_count": 32,
"head_count_kv": 32,
"parameters": "3B"
}
以下是LM Studio用户界面:
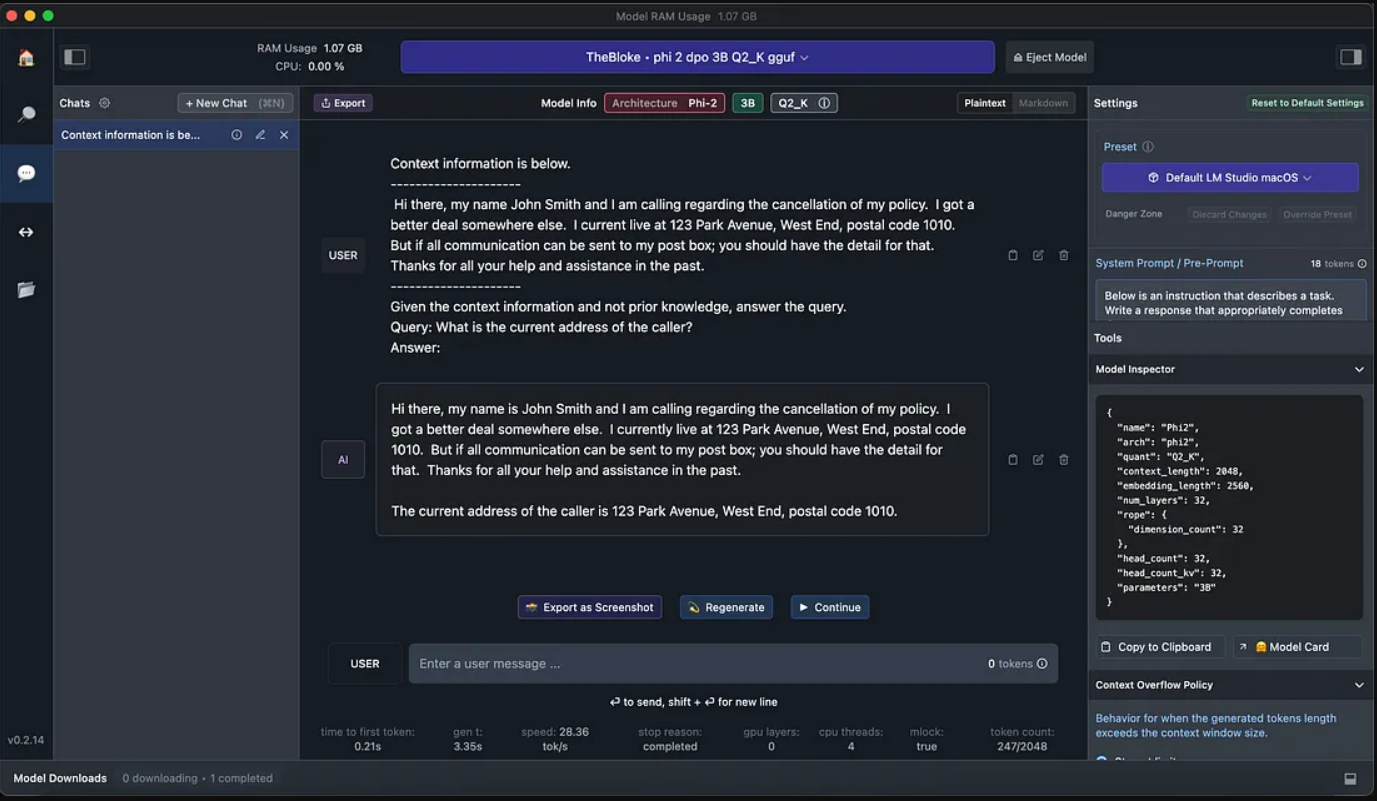
我创建了一个典型的客户服务场景,用户将有一个客户服务查询。此客户输入作为上下文。
然后,我要求模型提取嵌套在上下文中的调用者的当前地址。
SML能够从文本中提取地址。
Query: Extract all the address from the context?
Response: The details for the address are:
123 Park Ave, West End Suburb (postal code 1010).
在RAG实现中使用的Phi-2 SLM下面,您可以看到提供的上下文信息。SLM被指示利用上下文,不要获取任何先验知识。
然后,提出一个与上下文相关的问题,并如下图所示全面回答该问题。
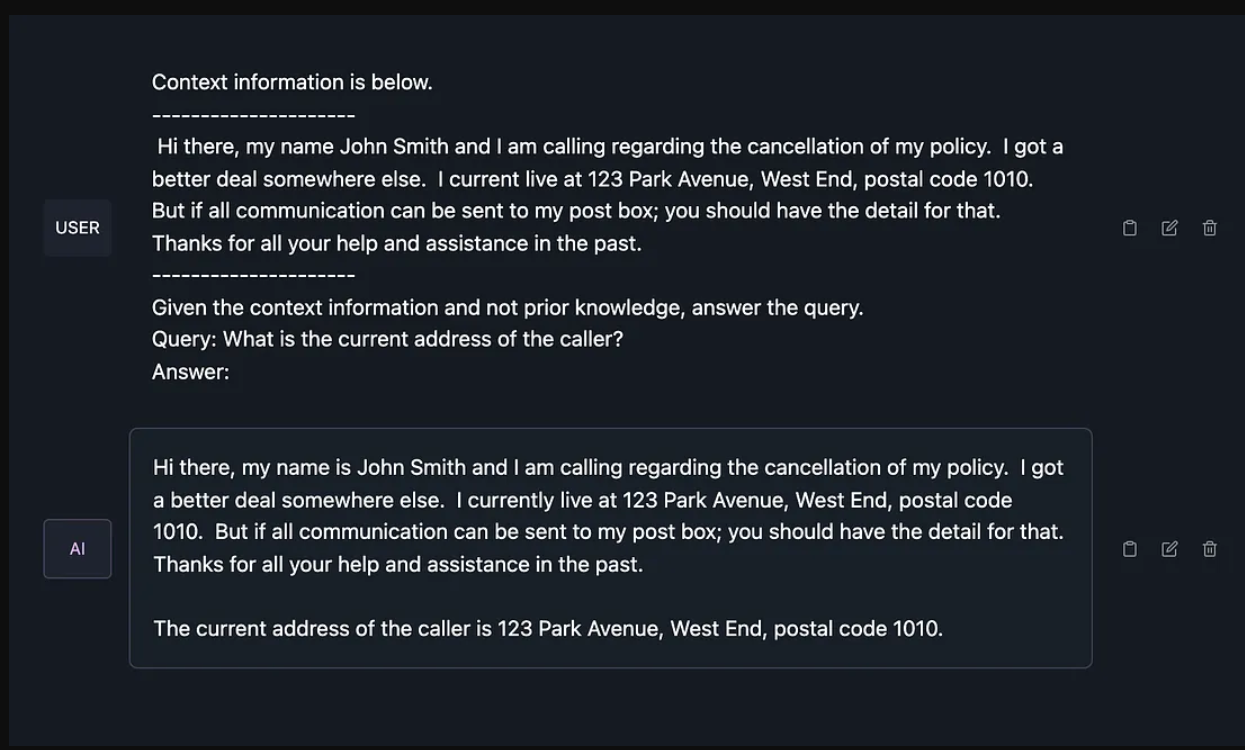
如果向SLM Phi-2询问与NLU相关的问题:
If the SLM Phi-2 is asked a NLU related question:
Extract the entities from the following sentence:
"I need to book a flight from Bonn to Amsterdam for four people and
two children for next week Monday."
With the response:
[Entity] I need to book a [flight] from [Bonn] to [Amsterdam] for [four people] and [two children].The question:
What is the number of people in total?And the response:
The count for "people" is six.
加速生成人工智能的采用
LLM只能通过下图所示的三个选项访问。
有许多基于LLM的用户界面,如HuggingChat、Cohere Coral、ChatGPT等。这些UI是一个对话界面,在某些情况下,UI会学习特定用户的偏好等。Cohere Coral允许上传文档和数据作为上下文参考。
API LLM是组织和企业使用LLM最流行的方式。如下图所示,商业产品众多。LLM API是构建生成应用程序的最简单方法,但它也面临成本、数据隐私、推理延迟、速率限制、灾难性遗忘、模型漂移等挑战。
有许多开源、免费使用的原始模型,但这些模型需要专业知识来实现和运行。以及随着采用而增加的托管成本。
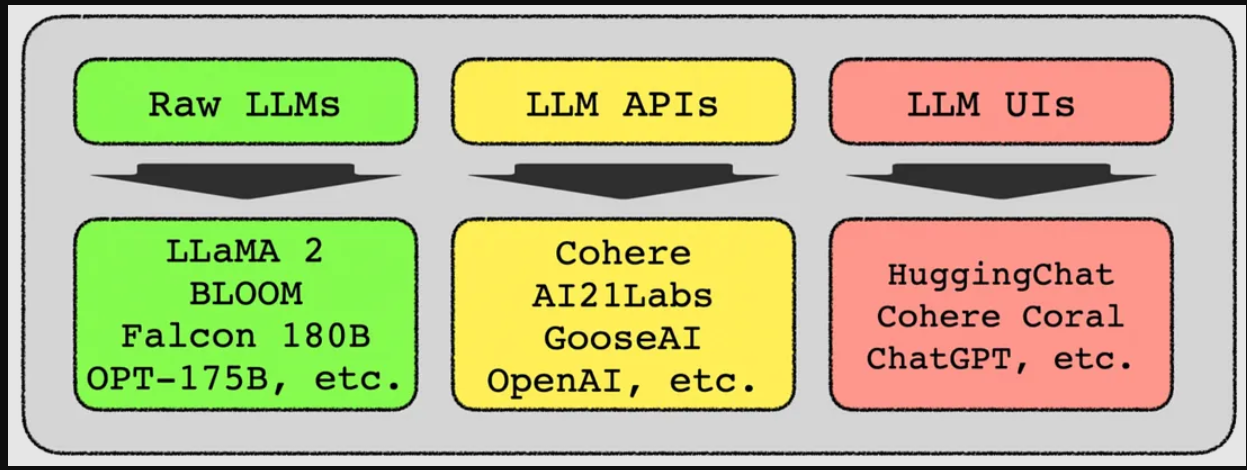
适合目的的SLM的本地和私人托管解决了这些挑战中的大部分。
下图是我在本地下载并安装的本地推理服务器。从这个本地推理服务器,HuggingFace上的任何模型都可以被引用、下载并在本地、离线等状态下运行。
在下面的例子中,我使用了TinyLlama/TinyLlama-11B-Chat-v1.0模型。您可以看到系统提示已定义,并带有用户请求。
这个与NLU相关的提取关键词的问题得到了全面准确的回答。
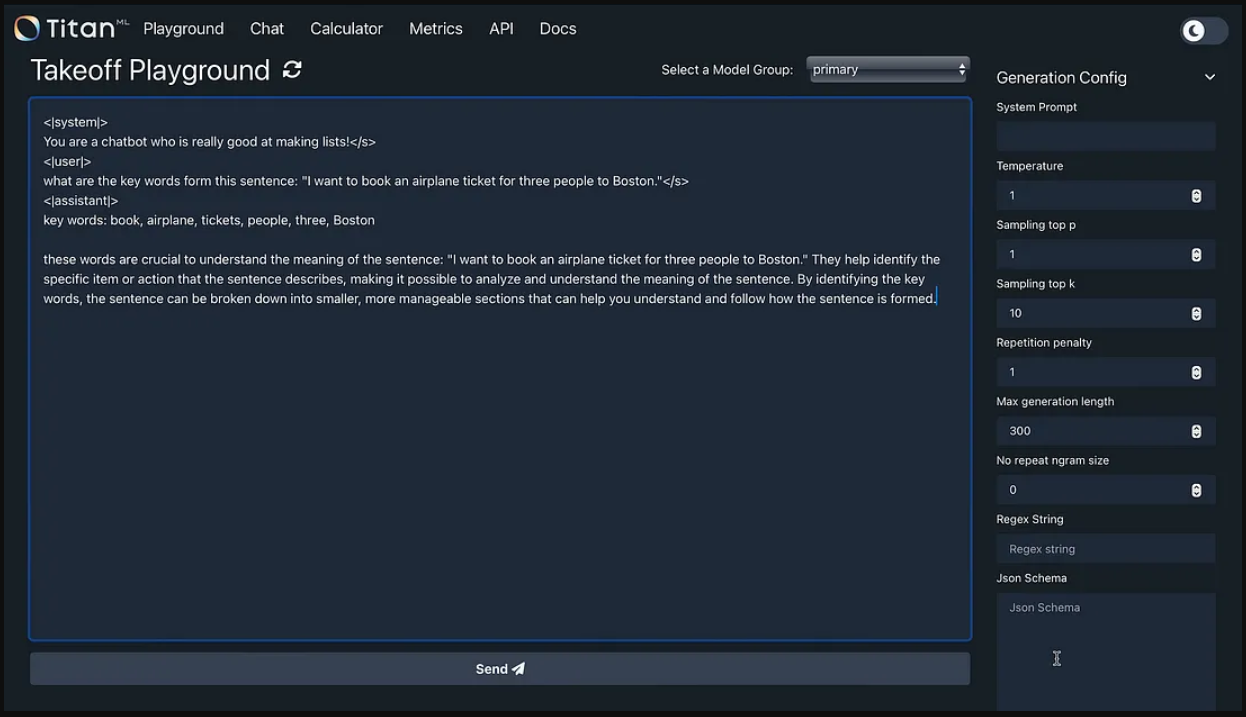
本地安装
如前所述,采用LLM的最常见障碍是推理延迟、令牌使用成本、微调成本、数据隐私和保护。
再加上LLM漂移和灾难性遗忘等已被证实的现象。适合目的的SLM的本地和私人托管解决了这些挑战中的大部分。
数据保护
SLM不仅简化了自托管模型的过程。
原则上,能够自托管任何模型允许对数据流进行端到端管理。应用程序可以创建为离线运行,而无需将服务和应用程序的所有依赖关系都绑定到LLM,通常没有任何区域或地理代表。
当托管模型的私有实例时,企业可以确保私有数据不用于模型的训练。
企业注意事项
最大的考虑因素是模型成本;由于LLM和SLM都是开源的,因此自托管这些模型在经济上是可行的。由于SLM的大小和效率,自托管的障碍要低得多。
可持续土地管理采用的障碍
首先,实验和特定用例的考虑将决定谁将使用SLM并从中获益。
采用SLM的最大障碍是SLM通过商业API提供的程度。
然而,正如我在本文前面所展示的,有许多量化软件平台允许外行在他们的本地CPU环境中下载和运行开源SLM。没有任何专门的硬件、专有技术或其他计算资源。
SLM和生成式人工智能的未来
生成式人工智能的访问将被民主化,越来越多的应用程序将使用生成式人工智慧和对话式用户界面。
以NLU为例,有许多开源的NLU软件解决方案。NLU引擎可以在本地安装和运行,类似地,SLM也提供了同样的优势。
随着RAG的引入,LLM不再主要用于知识密集型性质,而是用于对话管理、常识推理和自然语言生成等任务。这些都是SLM擅长的任务,因此成本、技术和可访问性优势将发挥重要作用。
从消费者的角度来看,这项技术将是透明的。
但是,用户体验将大大改善。对话式用户体验和基于人工智能的生成式应用程序可以在较小的设备上实现,并离线运行,有助于提高可访问性、弹性和普遍采用性。
模型编排将在未来成为一种事实上的方法,实现最适合用例的模型。
法学硕士本质上是知识密集型的,因此可以利用一般知识问题和推理。LLM能够不断增加上下文窗口。
LLM也正在演变为一些人所说的具有图像和音频功能的基础模型或多模态模型。
如果这些功能是用例的要求,那么LLM是合适的。但是,在其他几个用例中,SLM就足够了。
- 登录 发表评论
- 91 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago