
最少的数据量是多少? 您如何处理不平衡的数据问题?
- YOLOv5模型
- 韩国人行道数据集
- 最小数据集大小
- 对抗阶级失衡
- 如何更新模型
- 结论
- 参考

在本文中,我想回答关于对象检测模型的训练数据集的三个问题:
- 最大精度增益的最小数据集大小是多少?
- 你如何处理类不平衡问题?
- 用新数据更新已经训练好的模型的最佳方法是什么?
第一个问题的重要性怎么强调都不为过。预处理数据(收集、清理和注释数据)占 AI 开发的 80% 以上。因此,理想情况下,您希望以最大回报投资资源。
类不平衡问题是任何真正的 AI 项目的常见问题。具有大量数据的类的准确性可以很好地训练,而对于不常见的对象很难达到良好的准确性。欠采样和过采样是解决类不平衡问题的常用技术,我们将看到它们的效果。
更新已经训练好的模型变得越来越重要,因为 AI 模型无法规定其使用的上下文,因此经常需要适应新的领域。
我想使用 YOLOv5 和一个名为 Korean Sidewalk Dataset 的公共数据集来凭经验回答这些问题。
1. YOLOv5 模型
对象检测是指从图像或视频中检测对象实例的技术。在下图中,您可以看到由带有标签的边界框标记的“人”、“长凳”和“汽车”类的实例。

From the Korean Sidewalk dataset
为了实现这样的壮举,对象检测模型需要定位目标对象的位置并识别它们属于哪些类别。前一个任务称为“对象定位”,后一个任务称为“对象分类”。
要训练对象检测模型,您需要提供一个数据集,其中包含图像以及相应的位置和标签信息。构建这样一个数据集是由人工在环完成的耗时且劳动密集型的工作。幸运的是,有许多公开可用的数据集。例如,用于对象检测的 COCO 数据集包含 80 个不同类别的图像和注释。
YOLOv5 是一系列使用 COCO 数据集进行预训练的对象检测模型。实验以yolov5s.pt为基础,通过迁移学习的方法进行训练。使用超参数的默认配置,批量大小和时期除外。批量大小固定为 16,并且在大多数实验中使用了 100 个 epoch。
2. 韩国人行道数据集
示例数据集是韩国人行道数据集。它是一个大规模的公共数据集,包含超过 670,000 张带有边界框、多边形分割、表面掩蔽或深度预测标签的图像。最初的目的是为 AI 模型构建一个训练数据集,以帮助有视力障碍的人自行导航。其中一半(352,810 张图像)带有边界框注释,我们可以使用这些边界框来训练对象检测模型。此处列出了数据集中的对象类标签列表和定量相对比率:
https://gist.github.com/changsin/dc2fa9758e1f3642eb0711e95a198fce/raw/a…
#,class,ratio(%) 1,car,24.10 2,person,12.85 3,tree_trunk,12.48 4,pole,11.91 5,bollard,8.66 6,traffic_sign,5.40 7,traffic_light,4.48 8,truck,4.21 9,movable_signage,4.02 10,potted_plant,2.29 11,motorcycle,1.84 12,bicycle,1.59 13,bus,1.43 14,chair,0.94 15,bench,0.65 16,barricade,0.52 17,stop,0.50 18,fire_hydrant,0.34 19,carrier,0.31 20,kiosk,0.31 21,table,0.28 22,traffic_controller,0.21 23,stroller,0.18 24,power_controller,0.18 25,dog,0.14 26,wheelchair,0.11 27,scooter,0.06 28,parking_meter,0.01 29,cat,0.01
实验只使用前 15 个类,它们分为训练集、验证集和测试集。 训练集和验证集之间的比例一直保持在 80:20。 使用单独的测试集来测量 mAP(平均精度)。
关于数据集需要注意的几点是:
- 不平衡:如您所见,数据集明显不平衡。 前 5 个类对象占所有对象的 70%,前 15 个类对象占所有对象的 90%。 最常见的对象类是“汽车”,占数据集的 24%。
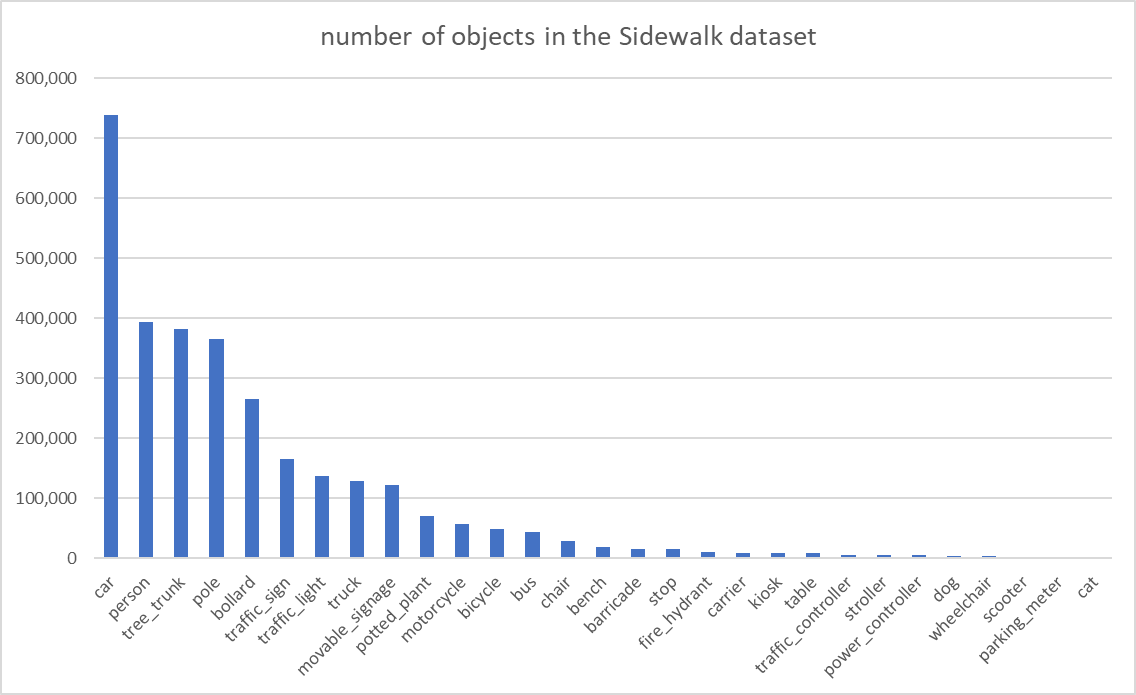
- 同一个图像中的多个实例:在每个图像中,有多个相同类对象的实例。 例如,汽车类每个图像有 3-4 个实例。 这是可以理解的,因为这些图像是汽车通常在附近的人行道图像。 在图像中找到所有不同大小的实例对模型来说是一个额外的挑战。
- 去识别化:人行道图像包含一些个人信息,如面部和车牌号码。 为了保护隐私,包含 PII(个人身份信息)的图像在注释和以后分发之前会被“去识别”(模糊)。 这是一张突出显示模糊车牌的汽车图像。

数据集的三个特征都是人工智能开发中相当普遍的问题。给定真实的数据集,让我们检查一下我们在开始时提出的问题。
3. 最小数据集大小
根据 Saleh Shahinfar 等人的说法。 (2020) 在“我需要多少张图片?”在论文中,训练模型显示每个类大约有 150-500 张图像的拐点,早期的性能提升开始趋于平稳。
为了复制实验,准备了随机采样图像的数据集,每个数据集包含 100 张图像。它们作为训练数据集增量提供,并且在模型训练 100 个 epoch 后测量 mAP。为了比较不同类的性能增益,将它们分为 3 类:
- 前 5 名:汽车、人、tree_trunk、杆、系柱
- 前 10 名:traffic_sign、traffic_light、卡车、moveable_signage、potted_plant
- 前 15 名:摩托车、自行车、公共汽车、椅子、长凳
每组中的 mAP 被平均,结果证实了 Saleh 等人的观察。 (2020 年)。

由于每个图像有多个实例,尤其是汽车类实例,前 5 个类的性能在大约 300 个图像早期趋于平稳。无论如何,趋势是明确的。大约 150-500 张图像似乎是看到性能提升的拐点。前 15 名的 mAP 遵循类似的模式,只是由于对象数量较少,它追赶得很慢。
4. 对抗阶级失衡
在之前的实验中,前 5 名从一开始就表现出不错的性能提升,但是前 10 名和前 15 名的类追赶得很慢,即使添加了 1000 张图像,它们的 mAP 仍然与前 5 名相差甚远。显而易见原因是缺乏数据。所以让我们解决这个问题。
有两种常见的方法来解决类不平衡问题。第一种方法称为“欠采样”,这意味着从多数类中抽取更少的样本。过采样则相反。您从少数族裔中抽取更多样本。由于我们的数据集严重不平衡,让我们两者都做:即对多数类进行欠采样,对少数类进行过采样。结果是一个重新采样的数据集。
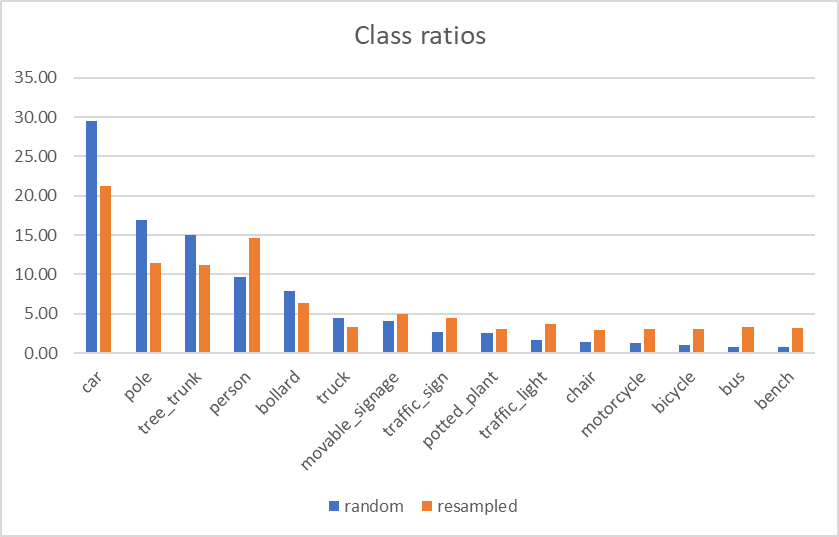
由于数据的性质,完全平衡的数据集是不可能的。 例如,在对公共汽车或摩托车进行采样时,您也被迫采用汽车实例。
重新采样数据集的准确性显示了改进。
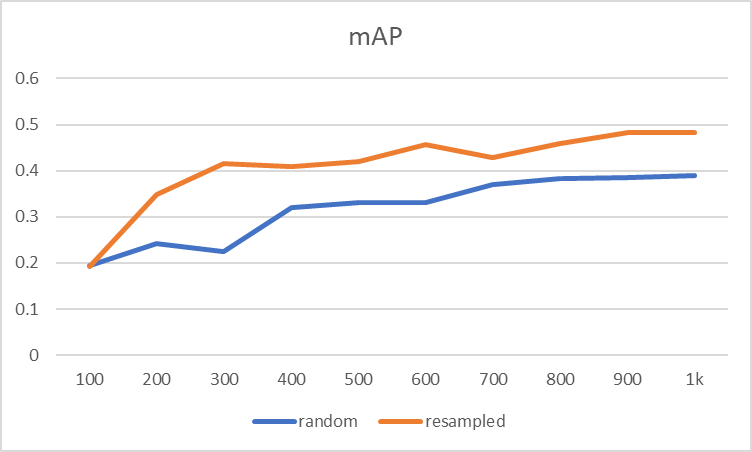
然而,这种改进不能从表面上看。 少数类的数据相对较多意味着多数类的数据较少。 随着少数类的准确度提高,多数类的准确度可能会更差。 我们如何确定是否是这种情况?
加权平均值是考虑到其数据点的相对重要性的平均值。 在我们的例子中,如果我们将每个类的平均值乘以该类的数据点数,然后取平均值,我们将得到整个数据集的加权平均值。
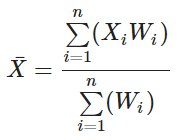
结果显示重采样数据集的改进不太显着。
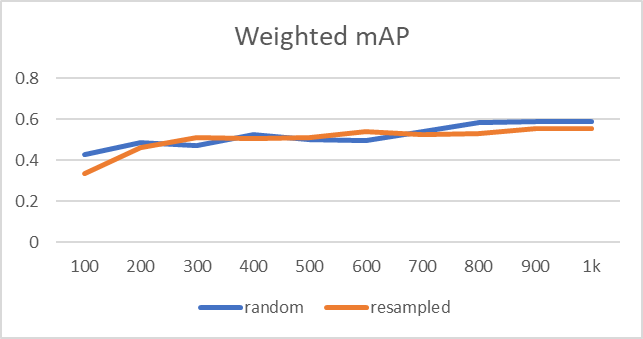
换句话说,数据的绝对数量和模型的准确性之间似乎存在直接的相关性,以至于对大多数类别的抽样不足会对它们的准确性产生负面影响。 我们可以从结果中吸取的教训是,在训练模型时需要有一个抽样策略和适当的指标。
5.如何更新模型
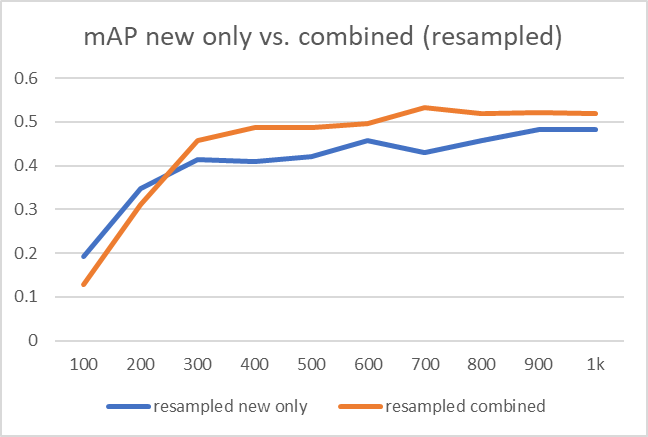
部署模型时,它可能会遇到不同的类分布或未经训练的新对象。 因此,通常根据监测结果定期更新模型。 更新模型时,数据集可以有两种不同的策略:
- 仅使用新数据
- 使用新旧数据的组合数据集
结果很清楚。 对于随机样本数据集和重采样(过采样和欠采样)数据集,新旧数据的组合数据集提供了更好的训练结果。

我们需要回答的另一个问题是是从头开始训练模型还是每次都进行迁移学习。 最后的图表显示了判决。
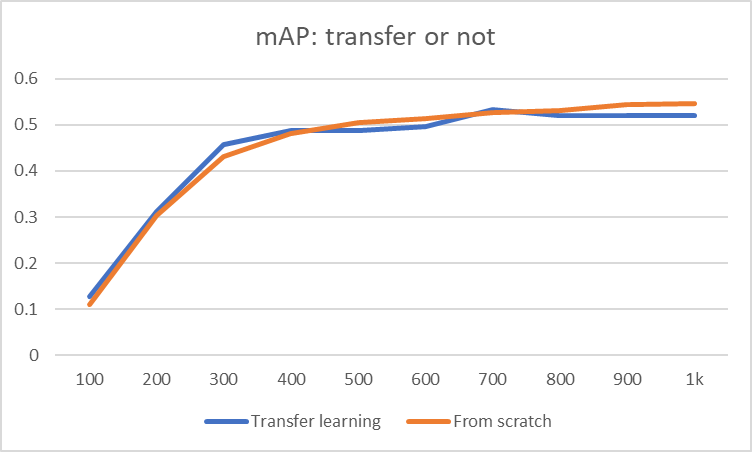
两种训练策略似乎没有区别。 唯一的区别是迁移学习可以让您更早地收敛,因为要训练的新数据较少,因此您可以通过迁移学习节省时间。
结论
以下是我们从实验中学到的:
- 用于训练的最小图像数据数量约为 150-500。
- 使用欠采样和过采样来补偿类不平衡问题,但要注意重新平衡的数据集分布。
- 要更新模型,请在新旧数据的组合数据集上进行迁移学习。
“我们需要多少张图像来训练一个模型?”这个问题的正确答案。 应该是“我不知道”或“这取决于”。 但我希望你学会了如何计划收集所需的数据以及训练对象检测模型的最佳实践。 谢谢阅读。
参考
- Junghwan Cho, et al. “HOW MUCH DATA IS NEEDED TO TRAIN A MEDICAL IMAGE DEEP LEARNING SYSTEM TO ACHIEVE NECESSARY HIGH ACCURACY?” (2016)
- Saleh Shahinfar, et al. “How many images do I need?: Understanding how sample size per class affects deep learning model performance metrics for balanced designs in autonomous wildlife monitoring.”(2020)
原文:https://changsin.medium.com/how-many-images-do-you-need-for-object-dete…
最新内容
- 1 week 1 day ago
- 2 weeks 2 days ago
- 2 weeks 6 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago