
category
Triton推理服务器使团队能够无缝部署源自多个深度学习和机器学习框架的各种人工智能模型。
它拥有与流行框架的兼容性,如TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPID FIL等。Triton的多功能性扩展到支持一系列计算环境的推理,包括云、数据中心、边缘和嵌入式设备,以满足NVIDIA GPU、x86和ARM CPU以及AWS Inferentia的需求。作为NVIDIA AI Enterprise的一个组成部分,Triton推理服务器不仅有助于优化各种查询类型的性能,包括实时、批量、集成和音频/视频流,而且有助于加速整个数据科学管道。
它被纳入NVIDIA AI Enterprise软件平台,简化了开发和部署流程,确保了高效、稳健的生产AI实施。
TRITON的架构:
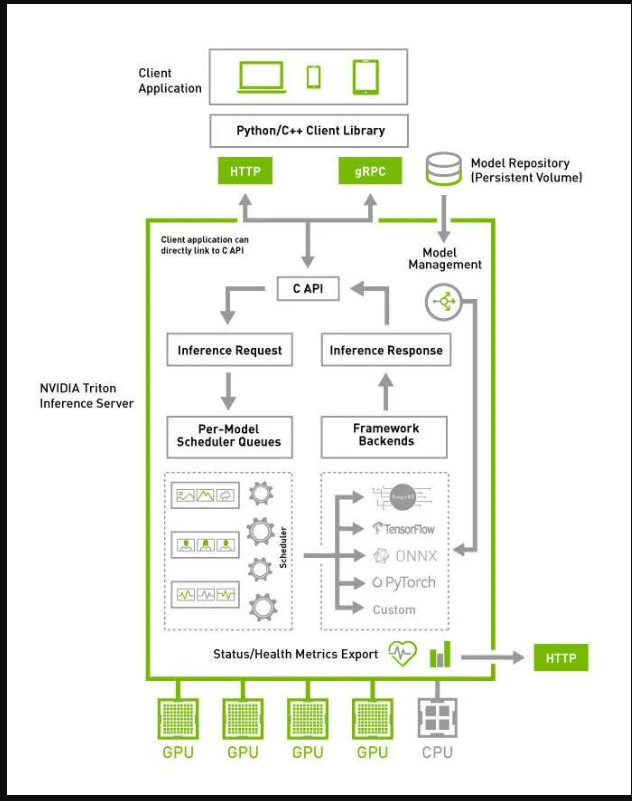
来源https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide…
主要功能:
1.多功能框架支持:
Triton推理服务器擅长与多个深度学习和机器学习框架无缝集成,为团队提供了从各种平台部署模型的灵活性,包括TensorRT、TensorFlow、PyTorch、ONNX和OpenVINO。
2.高效的并发模型执行:
该服务器支持模型的并发执行,优化计算资源,提高推理任务的整体性能。
3.动态批处理:
Triton支持动态批处理,通过有效管理批处理大小来提高吞吐量和资源利用率,从而适应不同的工作负载。
4.序列批处理和隐式状态管理:
Triton推理服务器特别有利于有状态模型,它提供序列批处理和隐式状态管理,确保人工智能模型中序列数据的稳健处理。
5.后端API的可扩展性:
后端API的提供使用户能够结合自定义后端和预/后处理操作,从而根据特定的应用程序需求定制服务器。
6.高级功能的管道模型:
Triton支持模型管道,允许用户通过Ensembling或业务逻辑脚本(BLS)实现复杂的功能,增强已部署模型的功能。
7.用于不同环境的推理协议:
通过支持基于社区开发的KServe协议的HTTP/REST和GRPC推理协议,Triton确保了与各种部署环境和首选项的兼容性。
8.直接应用程序集成:
Triton提供C和Java API,便于直接集成到边缘和其他进程中用例的应用程序中,增强了服务器的适应性和可访问性。
9.综合指标监测:
该服务器提供了详细的指标,包括GPU利用率、服务器吞吐量和延迟,为部署模型的性能和效率提供了宝贵的见解。
让我们来看看Quickstart部分:
在这里,我们将学习,如何启动和维护Triton推理服务器围绕着在Ubuntu Linux中构建模型存储库的使用。
Creating a Model Repository
Launching Triton
Send an Inference Request
请确保您已经安装了这些要求。
Git bash
python 3
python3-pip
pytorch or tensorflow
docker2
创建模型存储库
安装完需求后,我们必须从NVDIA的GitHub存储库中克隆名为“SERVER”的存储库。
git clone https://github.com/triton-inference-server/server
然后从Nvdia中取出triton服务器
sudo docker pull nvcr.io/nvdia/tritonserver:<latest>-py3 (for me its 21.05)
模型存储库用于存储Triton的模型。您可以在docs/examples/model_repository中找到一个示例存储库。在使用它之前,请运行提供的脚本,从公共模型动物园中获取任何丢失的模型定义文件。
启动Triton
Triton经过优化,通过使用GPU提供最佳推理性能,但它也可以在仅使用CPU的系统上工作。在这两种情况下,您都可以使用相同的Triton Docker图像。在这里,我们将只看到如何使用CPU。
在没有GPU的系统上,Triton应该在不使用Docker的--GPUs标志的情况下运行。
$ docker run --rm -p8000:8000 -p8001:8001 -p8002:8002
-v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver
--model-repository=/models
其中<xx.yy>是您要提取的版本。
由于没有使用-GPU标志,GPU不可用,因此Triton将无法加载任何需要GPU的型号配置。
验证它是否运行良好
curl -v localhost:8000/v2/health/ready
它的反应是这样的:
< HTTP/1.1 200 OK
< Content-Length: 0
< Content-Type: text/plain
如果Triton准备就绪,HTTP请求返回状态200,如果未准备就绪,则返回非200。发送推理请求
使用docker pull从NGC获取客户端库和示例图像。
$ docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:<xx.yy>-py3-sdk
使用映像nvcr.io/nvidia/tritonserver:<xx.yyy>-py3-sdk。在其中运行示例图像客户端应用程序,使用提供的densenet_onnx模型进行图像分类。
$ /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
回复如下:
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT
就是这样!你今天完了!!感谢您抽出时间…
- 登录 发表评论
- 47 次浏览
最新内容
- 1 week 3 days ago
- 2 weeks 4 days ago
- 3 weeks 1 day ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago