
category
所有客户都可以修改内容过滤器并配置严重性阈值(低、中、高)。部分或完全关闭内容过滤器需要获得批准。只有托管客户可以通过以下表单申请完全内容过滤控制:Azure OpenAI有限访问审查:修改后的内容过滤器。此时,不可能成为管理客户。
集成到Azure OpenAI Service中的内容过滤系统与核心模型(包括DALL-E图像生成模型)一起运行。它使用一组多类分类模型来分别检测四种严重程度(安全、低、中、高)的四类有害内容(暴力、仇恨、性和自残),并使用可选的二进制分类器来检测越狱风险、现有文本和公共存储库中的代码。默认内容过滤配置设置为在中等严重性阈值下过滤提示和完成的所有四个内容危害类别。这意味着,在严重性级别为中等或高的情况下检测到的内容会被过滤,而在严重性等级为低或安全的情况下,内容过滤器不会过滤检测到的属性。在此处了解有关内容类别、严重性级别和内容过滤系统行为的更多信息。越狱风险检测和受保护的文本和代码模型是可选的,默认情况下是关闭的。对于越狱和受保护的材料文本和代码模型,可配置性功能允许所有客户打开和关闭模型。默认情况下,模型是关闭的,可以根据您的场景打开。某些模型在某些场景下需要打开,以保留客户版权承诺的覆盖范围。
内容过滤器可以在资源级别配置。创建新配置后,它可以与一个或多个部署相关联。有关模型部署的更多信息,请参阅资源部署指南。
可配置性功能在预览中可用,允许客户分别调整提示和完成设置,以过滤不同严重级别的每个内容类别的内容,如下表所示。在“安全”严重级别检测到的内容在注释中标记,但不受过滤,也不可配置。
| Severity filtered | Configurable for prompts | Configurable for completions | Descriptions |
|---|---|---|---|
| Low, medium, high | Yes | Yes | Strictest filtering configuration. Content detected at severity levels low, medium, and high is filtered. |
| Medium, high | Yes | Yes | Default setting. Content detected at severity level low isn't filtered, content at medium and high is filtered. |
| High | Yes | Yes | Content detected at severity levels low and medium isn't filtered. Only content at severity level high is filtered. |
| No filters | If approved* | If approved* | No content is filtered regardless of severity level detected. Requires approval*. |
* Only approved customers have full content filtering control and can turn the content filters partially or fully off. Managed customers only can apply for full content filtering control via this form: Azure OpenAI Limited Access Review: Modified Content Filters. At this time, it is not possible to become a managed customer.
Customers are responsible for ensuring that applications integrating Azure OpenAI comply with the Code of Conduct.
| Filter category | Default setting | Applied to prompt or completion? | Description |
|---|---|---|---|
| Jailbreak risk detection | Off | Prompt | Can be turned on to filter or annotate user prompts that might present a Jailbreak Risk. For more information about consuming annotations, visit Azure OpenAI Service content filtering |
| Protected material - code | off | Completion | Can be turned on to get the example citation and license information in annotations for code snippets that match any public code sources. For more information about consuming annotations, see the content filtering concepts guide |
| Protected material - text | off | Completion | Can be turned on to identify and block known text content from being displayed in the model output (for example, song lyrics, recipes, and selected web content). |
Configuring content filters via Azure OpenAI Studio (preview)
The following steps show how to set up a customized content filtering configuration for your resource.
-
Go to Azure OpenAI Studio and navigate to the Content Filters tab (in the bottom left navigation, as designated by the red box below).
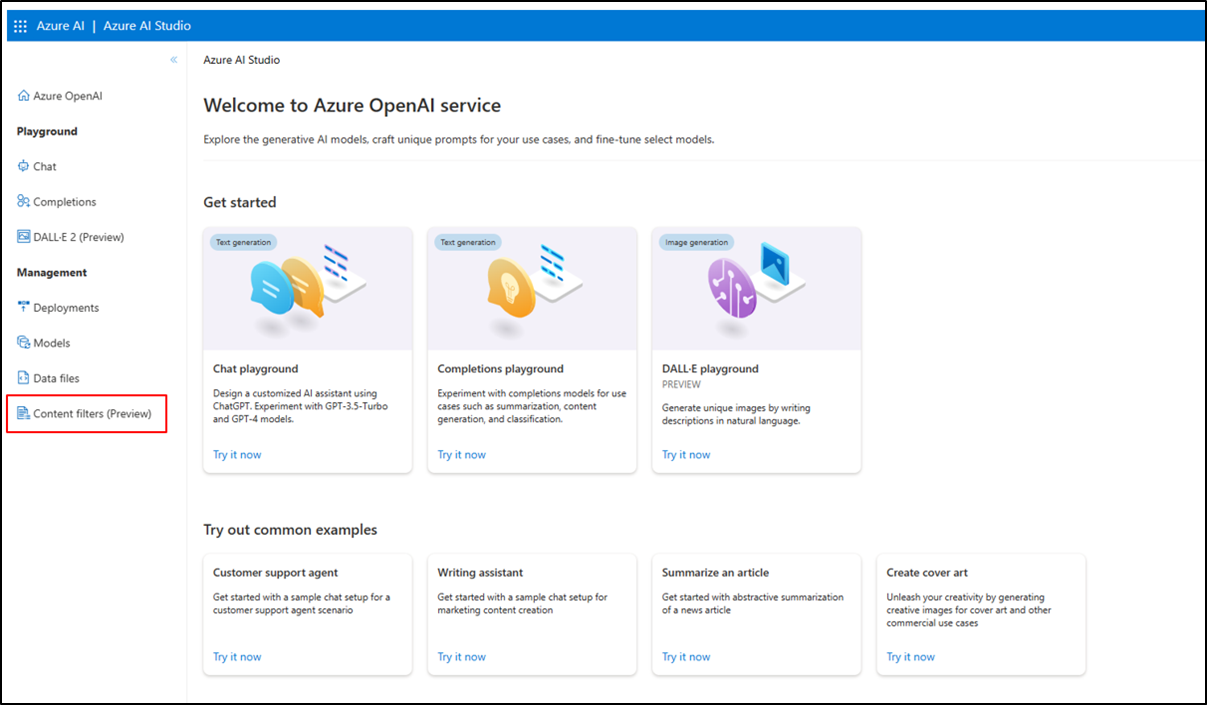
-
Create a new customized content filtering configuration.
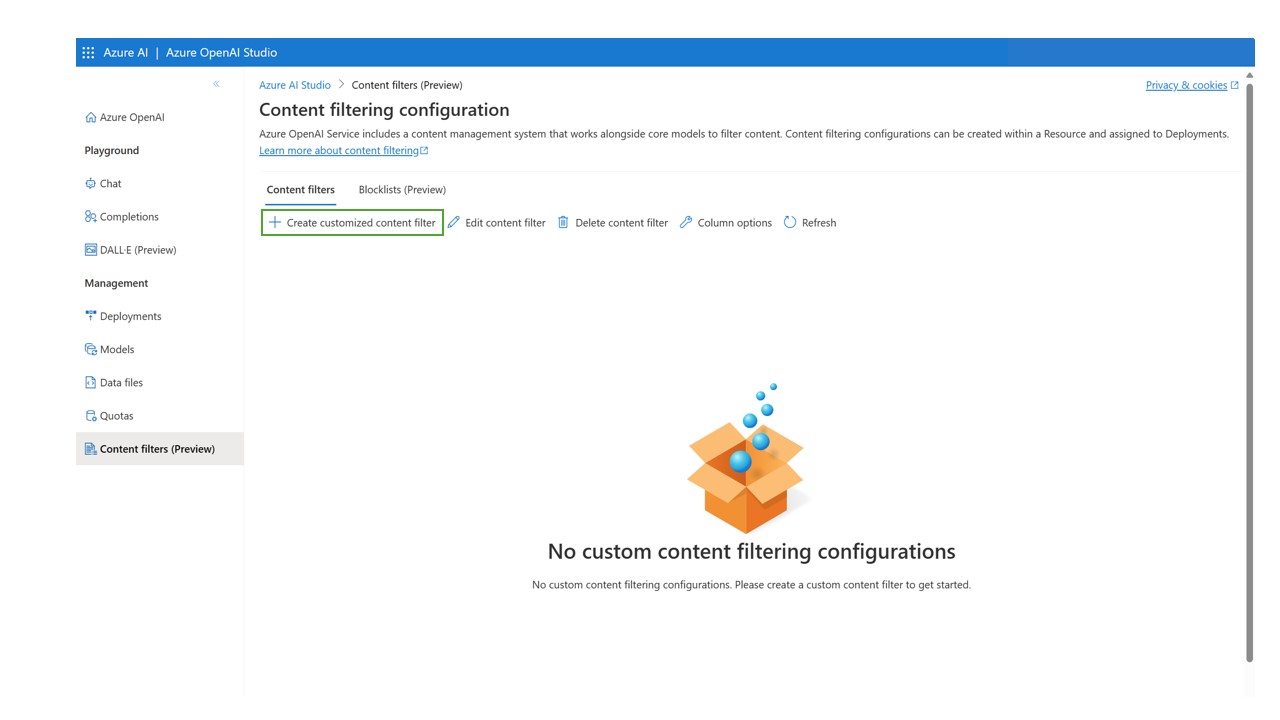
This leads to the following configuration view, where you can choose a name for the custom content filtering configuration.
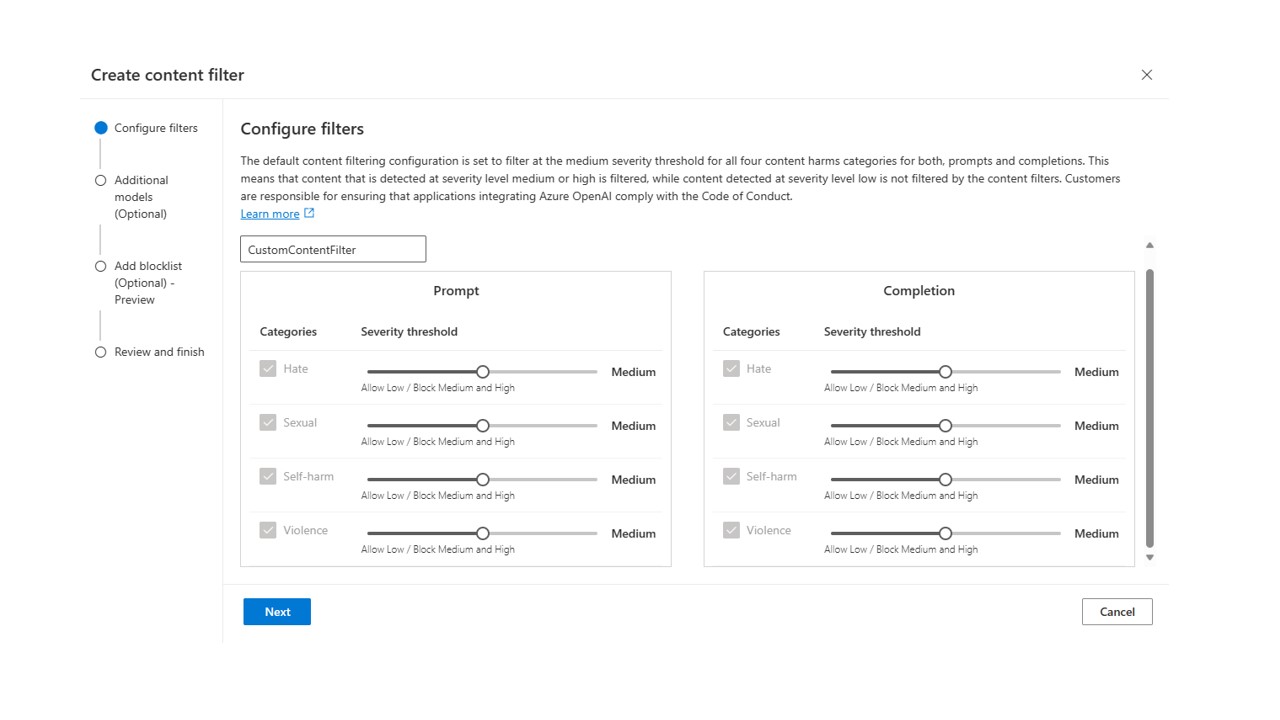
-
This is the view of the default content filtering configuration, where content is filtered at medium and high severity levels for all categories. You can modify the content filtering severity level for both user prompts and model completions separately (configuration for prompts is in the left column and configuration for completions is in the right column, as designated with the blue boxes below) for each of the four content categories (content categories are listed on the left side of the screen, as designated with the green box below). There are three severity levels for each category that are configurable: Low, medium, and high. You can use the slider to set the severity threshold.
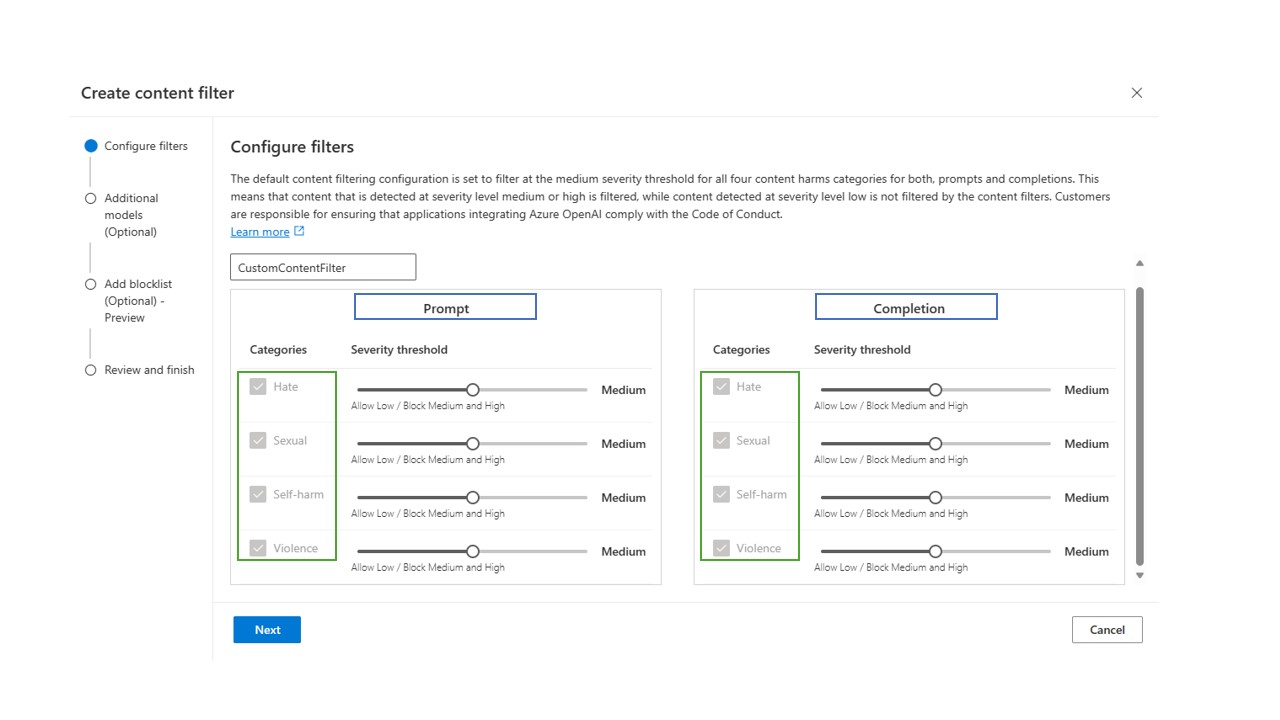
-
If you determine that your application or usage scenario requires stricter filtering for some or all content categories, you can configure the settings, separately for prompts and completions, to filter at more severity levels than the default setting. An example is shown in the image below, where the filtering level for user prompts is set to the strictest configuration for hate and sexual, with low severity content filtered along with content classified as medium and high severity (outlined in the red box below). In the example, the filtering levels for model completions are set at the strictest configuration for all content categories (blue box below). With this modified filtering configuration in place, low, medium, and high severity content will be filtered for the hate and sexual categories in user prompts; medium and high severity content will be filtered for the self-harm and violence categories in user prompts; and low, medium, and high severity content will be filtered for all content categories in model completions.
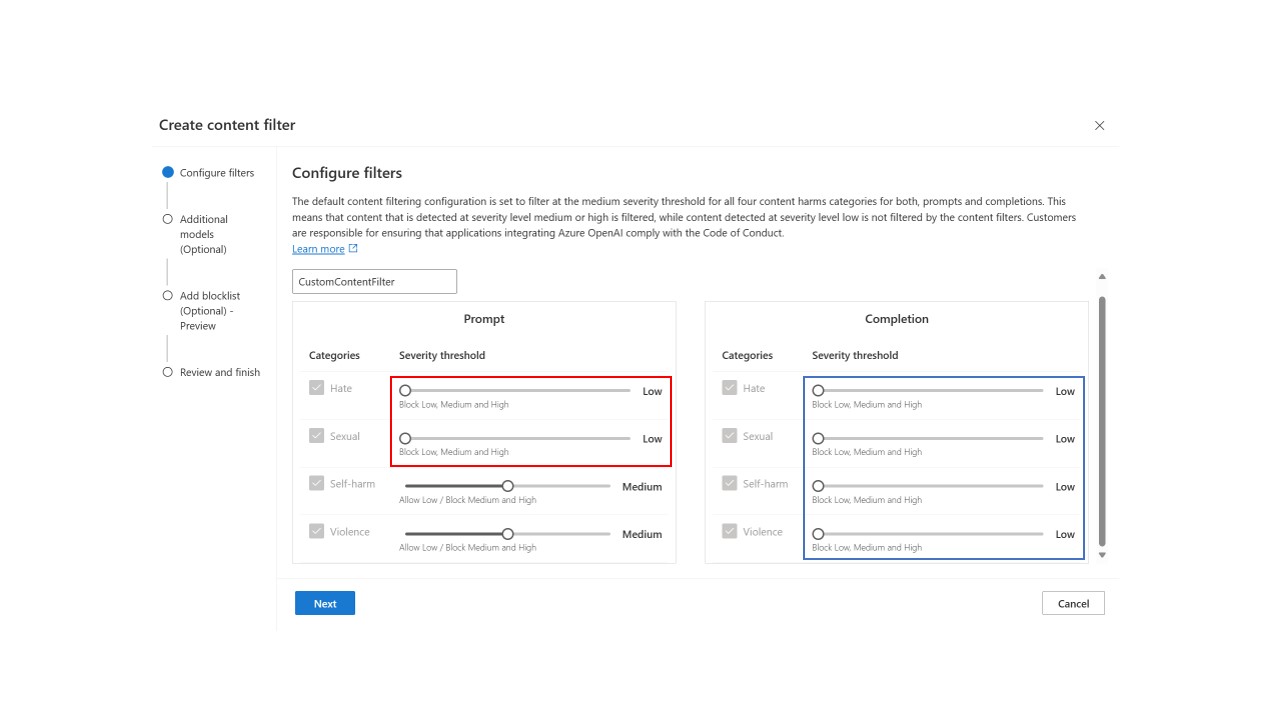
-
If your use case was approved for modified content filters as outlined above, you receive full control over content filtering configurations and can choose to turn filtering partially or fully off. In the image below, filtering is turned off for violence (green box below), while default configurations are retained for other categories. While this disabled the filter functionality for violence, content will still be annotated. To turn off all filters and annotations, toggle off Filters and annotations (red box below).
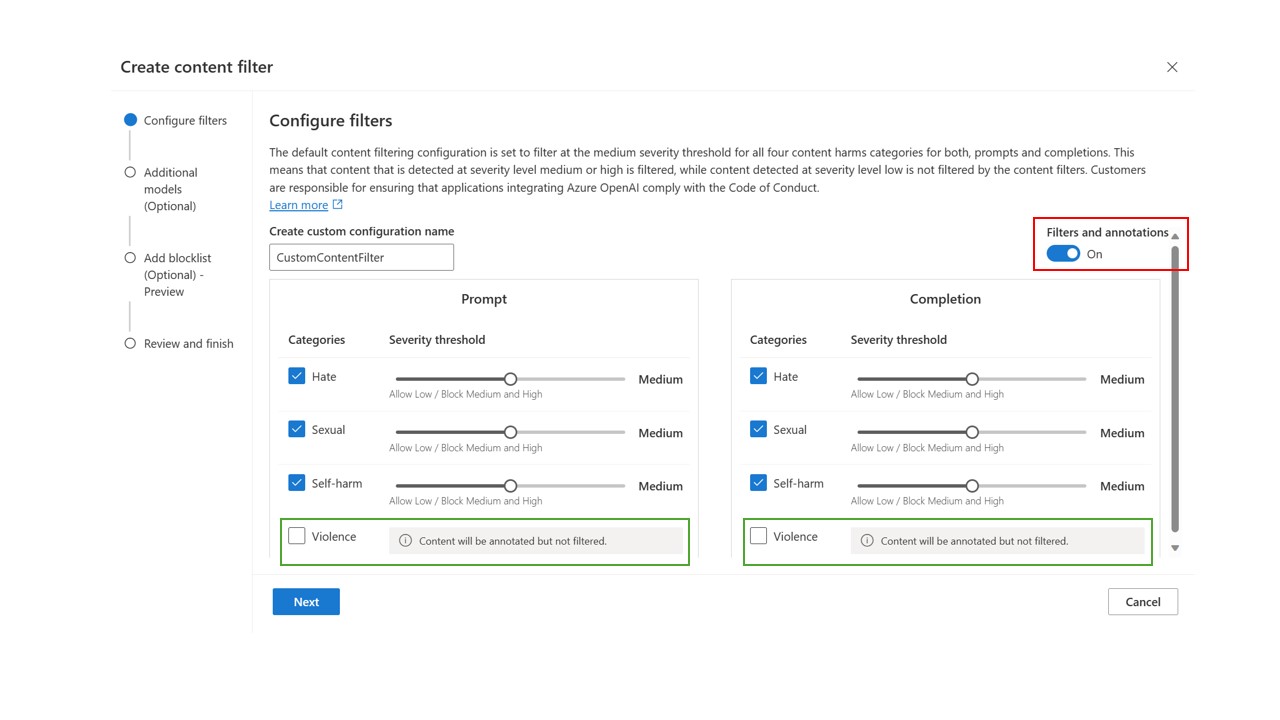
You can create multiple content filtering configurations as per your requirements.
-
To turn on the optional models, you can select any of the checkboxes at the left hand side. When each of the optional models is turned on, you can indicate whether the model should Annotate or Filter.
-
Selecting Annotate runs the respective model and return annotations via API response, but it will not filter content. In addition to annotations, you can also choose to filter content by switching the Filter toggle to on.
-
You can create multiple content filtering configurations as per your requirements.
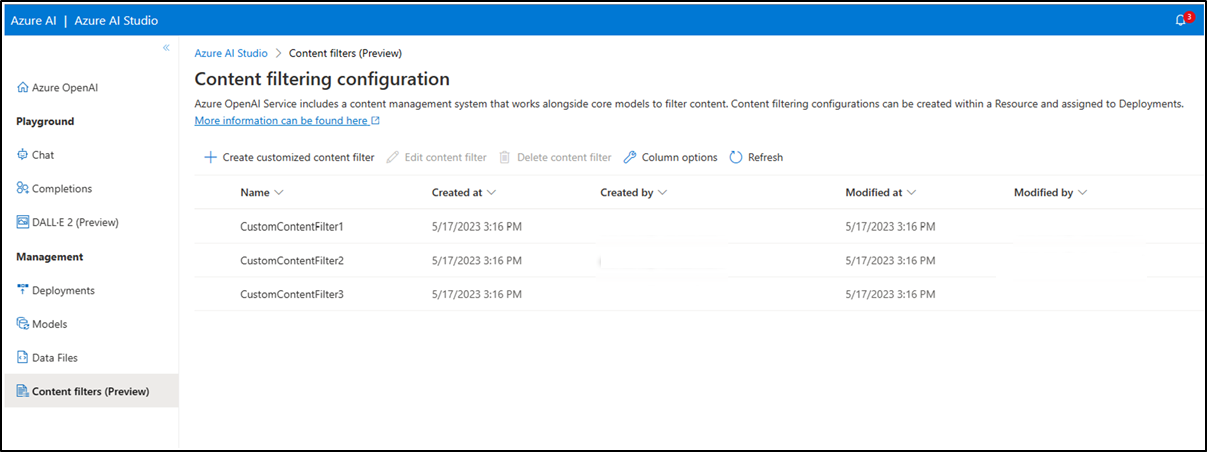
-
Next, to make a custom content filtering configuration operational, assign a configuration to one or more deployments in your resource. To do this, go to the Deployments tab and select Edit deployment (outlined near the top of the screen in a red box below).
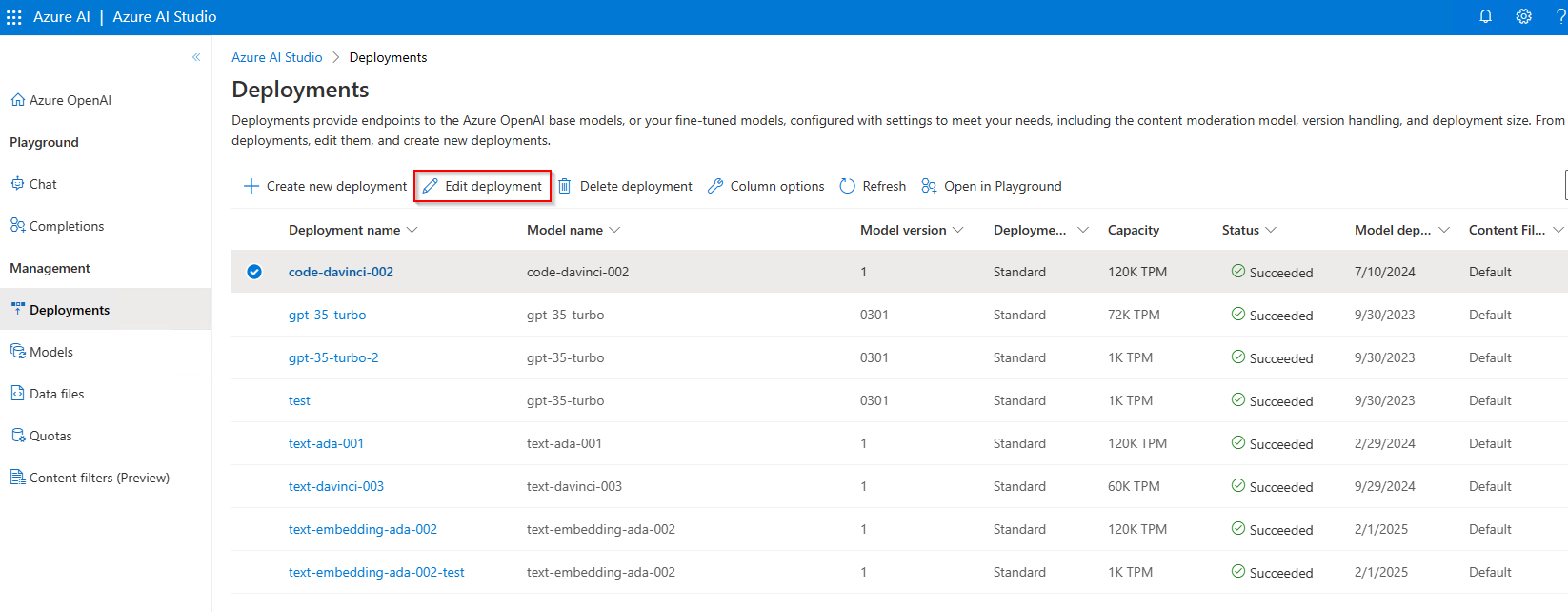
-
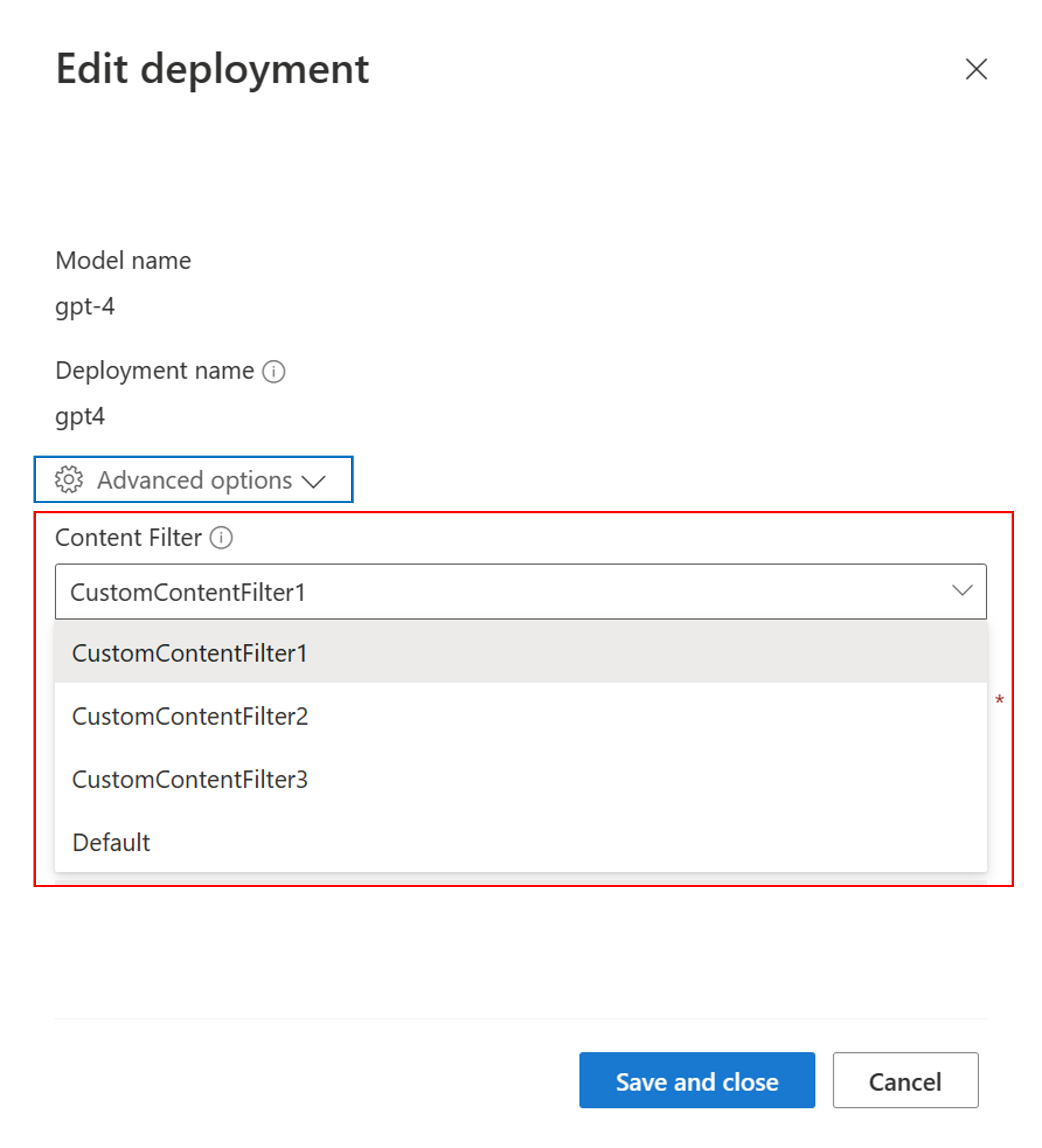
Go to advanced options (outlined in the blue box below) select the content filter configuration suitable for that deployment from the Content Filter dropdown (outlined near the bottom of the dialog box in the red box below).
-
Select Save and close to apply the selected configuration to the deployment.
-
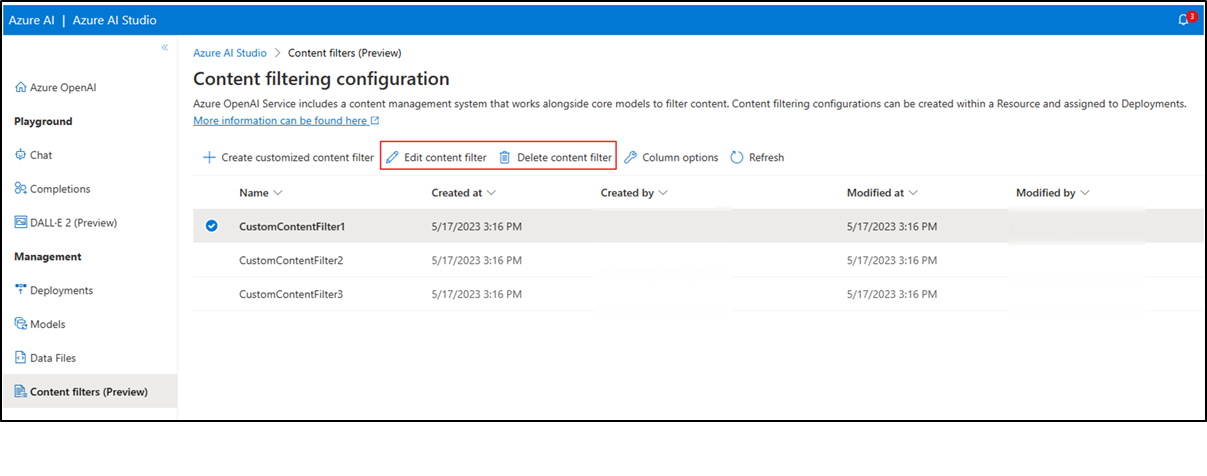
You can also edit and delete a content filter configuration if required. To do this, navigate to the content filters tab and select the desired action (options outlined near the top of the screen in the red box below). You can edit/delete only one filtering configuration at a time.
Note
Before deleting a content filtering configuration, you will need to unassign it from any deployment in the Deployments tab.











Best practices
我们建议通过迭代识别(例如红队测试、压力测试和分析)和测量过程来告知您的内容过滤配置决策,以解决与特定模型、应用程序和部署场景相关的潜在危害。在实施内容过滤等缓解措施后,重复测量以测试有效性。基于微软责任人工智能标准的Azure OpenAI责任人工智能的建议和最佳实践可以在Azure OpenAI的责任人工智能概述中找到。
Next steps
- Learn more about Responsible AI practices for Azure OpenAI: Overview of Responsible AI practices for Azure OpenAI models.
- Read more about content filtering categories and severity levels with Azure OpenAI Service.
- Learn more about red teaming from our: Introduction to red teaming large language models (LLMs) article.
- 登录 发表评论
- 132 次浏览
最新内容
- 1 month 2 weeks ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago