
category
参数高效微调——LoRA、QLoRA——动手操作
在本博客中,我们将实现LoRA——参数有效微调(PEFT)背后的思想,并探索LoRA和QLoRA这两种最重要的PEFT方法。我们还将探索“权重和偏差”,以获取训练指标。我们将微调一个小型Salesforce codegen 350m参数模型,以提高生成Python代码的效率。
在第1部分中,我们讨论了LoRA如何引入模块化,并通过允许我们使用维度显著较低的适配器模块来增强基本模型,从而减少训练时间。QLoRA通过进一步降低基础模型的尺寸,进一步推进了这一方法。这是通过量化实现的,量化包括将浮点32格式转换为较小的数据类型,如8位或4位。
在这篇博客文章中,我们将采用Salesforce codegen 350m模型,并对其进行微调,以生成复杂的Python代码。为了提高其性能,我们将利用Alpaca指令集进行更有效的微调和生成Python代码。
让我们从设置“拥抱脸”帐户和“权重和偏差”帐户开始。我们将使用权重和偏差来获取训练指标。
首先,创建一个拥抱脸帐户,并生成一个具有写入权限的访问令牌。此代币将允许我们将经过训练的模型保存在拥抱面部集线器上。我们将使用此令牌登录到拥抱脸来拉取基础模型并推送训练后的模型。
我们将使用权重和偏差来获取我们的训练和实验的指标。要创建帐户,请转到https://wandb.ai/abvijay/projects.添加一个新项目(我添加了python微调(https://wandb.ai/abvijay/python-fine-tuning)). 您可以在基本仪表板工作区中找到API键,也可以在右上角的“快速帮助”下找到它。

现在让我们开始编码。
正在安装依赖项
以下代码显示了我们将需要的各种依赖项和导入
!pip install -q -U trl transformers accelerate git+https://github.com/huggingface/peft.git
!pip install -q datasets bitsandbytes einops
!pip install -q wandb
from datasets import load_dataset
from random import randrange
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, TrainingArguments
from peft import LoraConfig, prepare_model_for_kbit_training,
get_peft_model, AutoPeftModelForCausalLM
from trl import SFTTrainer
from huggingface_hub import login
import wandb
让我们了解为什么我们需要这些不同的依赖关系
- trl:这个Python包“Transformer强化学习”用于使用强化学习来微调Transformer模型。我们将使用我们的指令数据集来执行这种强化学习并微调模型。我们将使用SFTrainer对象进行微调。
- 🤗 transformers:这个包提供了所有的API,用于下载和处理huggingface模型中心中的各种预训练模型。在我们的示例中,我们将下载Salesforce/codegen-350M-mono。我们还将使用来自transformer的位和字节库进行量化,并使用AutoTokenizer为预训练的模型创建标记器。
- 🤗 加速:这是另一个非常强大的huggingface包,它隐藏了开发人员试图编写/管理使用多GPU/TPU/fp16所需代码的复杂性。
- 🤗 peft:这个包提供了我们执行LoRA技术所需的所有API。
- 🤗 数据集:这个huggingface包提供了对huggingfacehub中各种数据集的访
- wandb:这个库提供了对权重和偏差库的访问,以在微调过程中捕获各种度量。
在下面的代码中,我们将设置模型、数据集名称和设备映射的值
model_name = "Salesforce/codegen-350M-mono"
dataset_name = "iamtarun/python_code_instructions_18k_alpaca"
device_map = {"": 0}
LoRA配置
我们可以使用LoraConfig定义LoRA的配置。hugginface PEFT库支持各种其他PEFT方法,如前缀调整、P-调整和提示调整。等等。由于我们使用的是LoRA方法,所以我们使用的就是LoraConfig类。下面的代码显示了配置,我们将使用
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
LoraConfig具有以下属性。
- lora_lpha:权重矩阵的比例因子。alpha是调整组合结果(基本模型输出+低秩自适应)的幅度的比例因子。我们已将其设置为16。您可以在LoRA的论文中找到更多详细信息。
- lora_dropout:lora层的丢失概率。此参数用于避免过拟合。这项技术基本上在向前和向后传播过程中都会漏掉一些神经元,这将有助于消除对单个神经元单元的依赖。我们将其设置为0.1(即10%),这意味着每个神经元都有10%的脱落几率。
- r: 这是低秩矩阵的维度,请参阅本博客的第1部分了解更多详细信息。在这种情况下,我们将其设置为64(这实际上意味着我们的LoRA适配器中将有512x64和64x512参数。
- bias:我们不会在这个例子中训练偏倚,所以我们将其设置为“无”。如果我们必须训练偏差,我们可以将其设置为“全部”,或者如果我们只想训练LORA偏差,那么我们可以使用“LORA_only”
- task_type:由于我们使用的是因果语言模型,因此我们将任务类型设置为Causal_LM。
此配置用于在基本模型的顶部创建LoRA适配器
我们现在需要定义QLoRA配置。我们使用BitsAndBytesConfig来定义它。以下代码显示QLoRA配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16"
)
我们将设置以下属性。(在您尝试理解这些配置参数之前,请参阅博客的第1部分,了解有关量化的更多详细信息)
- load_in_4bit:我们正在用4位量化加载基本模型,所以我们将此值设置为True。
- bnb_4bit_use_double_quant:我们还想要双重量化,以便即使量化常数也被量化。所以我们将其设置为True。
- bnb_4bit_quant_type:我们将其设置为nf4。
- bnb4bit_compute_dtype:以及我们设置为float16的计算数据类型
from huggingface_hub import notebook_login
# Log in to HF Hub
notebook_login()
wandb.login()
%env WANDB_PROJECT=python-fine-tuning
现在让我们来看一下将用于微调模型的指令集。我们将在huggingface上使用18k羊驼Python指令集。
iamtarun/python_code_instructions_18k_alpaca下面的屏幕截图显示了指令集的结构
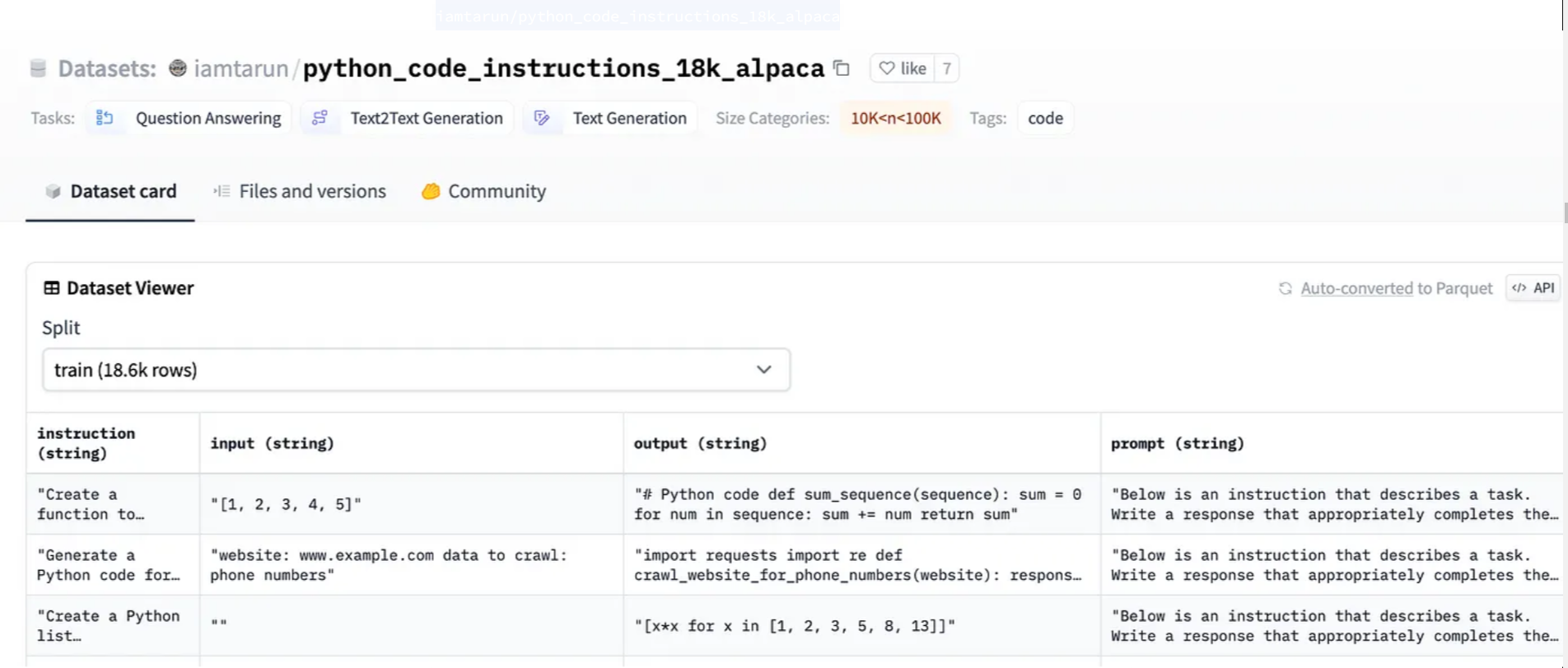
我们必须定义一种方法来处理这些指令集,该方法将由监督微调训练器调用,以将指令数据集转换为所需的指令和提示。以下方法定义了如何将此数据集中的每一行转换为指令/提示并输出。
def prompt_instruction_format(sample):
return f"""### Instruction:
Use the Task below and the Input given to write the Response,
which is a programming code that can solve the following Task:
### Task:
{sample['instruction']}
### Input:
{sample['input']}
### Response:
{sample['output']}
"""
现在让我们通过调用load_dataset()来加载数据集
dataset = load_dataset(dataset_name, split=split)
我们可以使用AutoModelForCausalLM加载模型,并且我们将传递QLoRA配置,以便加载模型,如量化
model = AutoModelForCausalLM.from_pretrained(model_name,
quantization_config=bnb_config,
use_cache = False,
device_map=device_map)
model.config.pretraining_tp = 1
让我们使用huggingface AutoTokenizer为模型定义标记器
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
现在让我们定义各种训练论点。培训师将使用这些论据对模型进行微调。让我们详细研究一下这些论点中的每一个
trainingArgs = TrainingArguments(
output_dir=finetunes_model_name,
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
optim="paged_adamw_32bit",
logging_steps=5,
save_strategy="epoch",
learning_rate=2e-4,
weight_decay=0.001,
max_grad_norm=0.3,
warmup_ratio=0.03,
group_by_length=False,
lr_scheduler_type="cosine",
disable_tqdm=True,
report_to="wandb",
seed=42
)- output_dir:存储模型预测和检查点的输出目录
- num_train_epochs=3:训练时期数per_device_train_batch_size=4:用于训练的每个GPU的批量大小
- gradient_accumulation_steps=2:累积梯度的更新步骤数
- gradient_checkpointing=True:启用渐变检查点。梯度检查点是一种在深度神经网络训练过程中用于减少内存消耗的技术,尤其是在内存使用是限制因素的情况下。渐变检查点有选择地在反向过程中重新计算中间激活,而不是将它们全部存储,从而执行一些额外的计算以减少内存使用。
- optim=“paged_adamw_32bit”:要使用的优化器,我们将使用paged_adanw_32bit
logging_steps=5:每5步登录控制台查看进度。 - save_strategy=“epoch”:在每个epoch之后保存
- learning_rate=2e-4:学习率
- weight_decay=0.001:权重衰减是训练模型时使用的一种正则化技术,通过在损失函数中添加惩罚项来防止过拟合。权重衰减通过在损失函数中添加一个项来惩罚模型权重的大值。
- max_grad_norm=0.3:此参数设置梯度剪裁的最大梯度范数。
- warmup_ratio=0.03:热身比是一个值,用于确定热身阶段将使用总训练步骤或时期的哪一部分。在这种情况下,我们将其设置为3%。预热是指一种特定的学习率调度策略,该策略在一定数量的训练步骤或时期内将学习率从初始值逐渐增加到完全值。
- lr_scheduler_type=“余弦”:学习率调度器用于在训练过程中动态调整学习率,以帮助提高收敛性和模型性能。我们将使用余弦类型的学习率调度器。
- report_to=“wandb”:我们希望向权重和偏差报告我们的指标
- seed=42:这是在训练开始时设置的随机种子。
现在让我们创建一个训练器对象。我们将在这里传递LoRA配置,以便在低秩适配器上进行训练,而不是在基本模型上。
# Create the trainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
max_seq_length=2048,
tokenizer=tokenizer,
packing=True,
formatting_func=prompt_instruction_format,
args=trainingArgs,
)
在初始化SFTTrainer类时,我们传递要训练的基本模型、训练数据集、PEFT配置、标记化以及将训练数据转换为“提示”所需的方法,因为我们已将包装指定为“True”。我们还传递了在上一步中初始化的训练参数。
我们可以通过调用train()方法来开始训练。
trainer.train()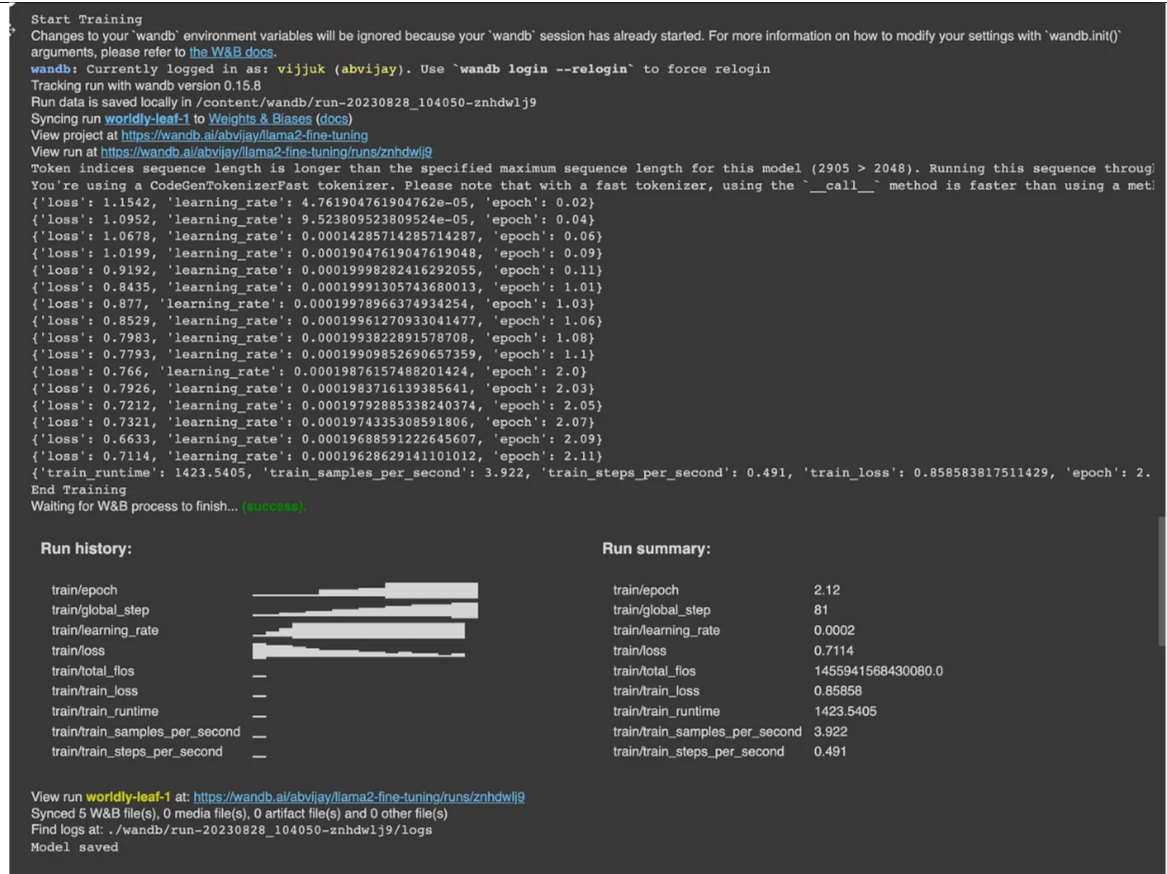
上面的屏幕截图显示了训练的输出,您还可以看到权重和偏差链接,以及关于损失和训练的各种指标。
以下屏幕截图显示了权重和偏差网站上的仪表板,其中显示了各种训练指标和性能指标——GPU使用率、内存使用率等。
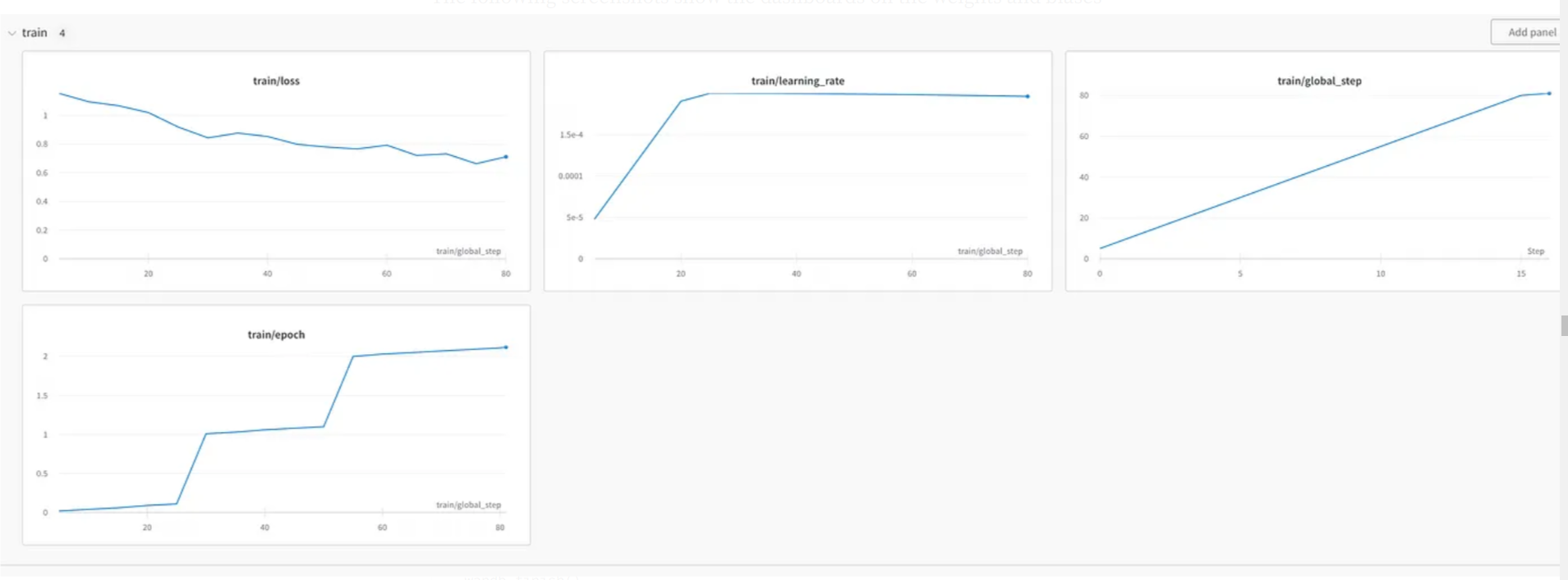
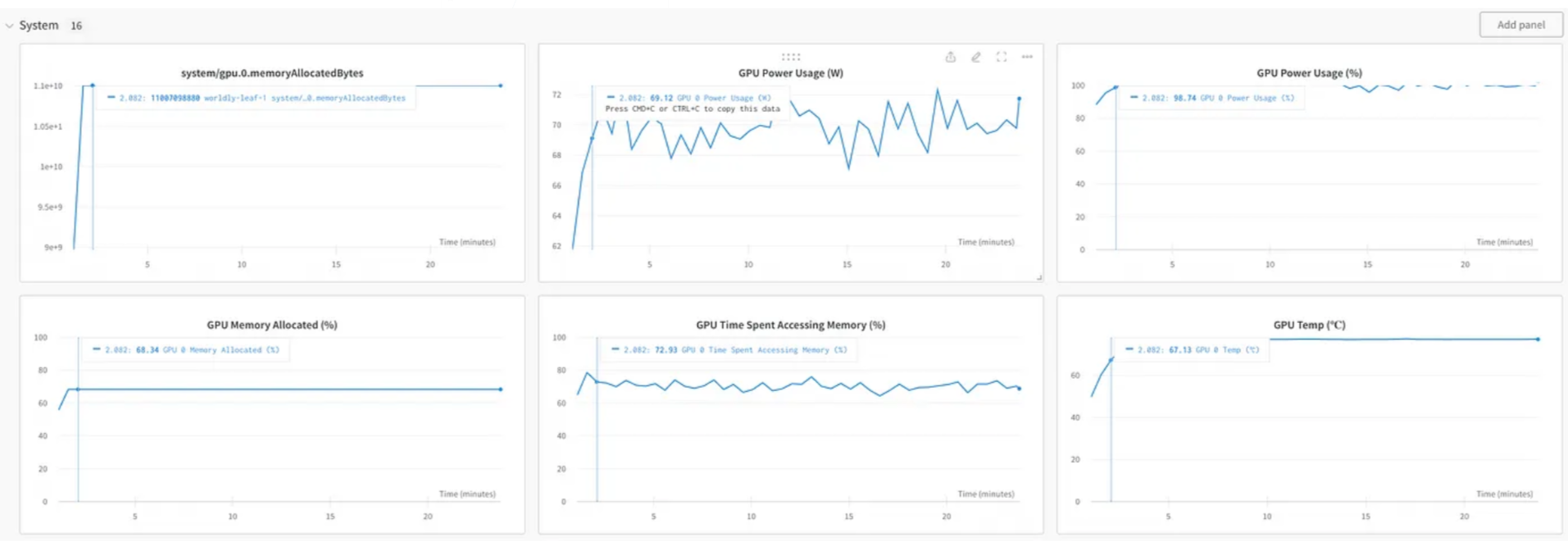
一旦训练完成,我们将保存模型并停止收集指标。
#stop reporting to wandb
wandb.finish()
# save model
trainer.save_model()
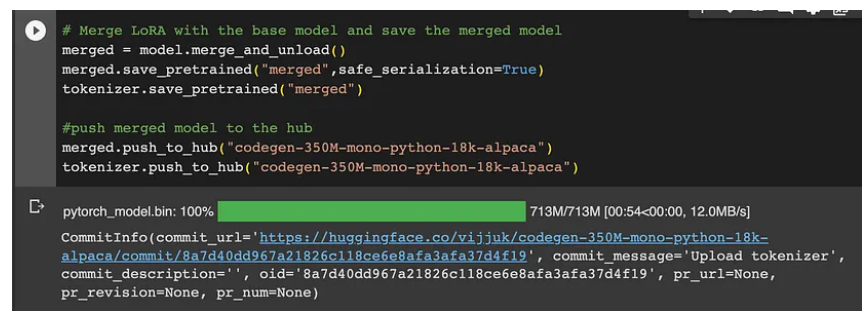
现在我们有了一个训练过的模型,我们需要将训练过的模式与基础模式合并。我们可以通过调用merge_and_unlad()来实现这一点。此方法将LORA图层与基础模型合并。下面的代码显示了合并,然后将合并后的模型上传到huggingface hub。
# Merge LoRA with the base model and save the merged model
merged = trained_model.merge_and_unload()
merged.save_pretrained("merged",safe_serialization=True)
tokenizer.save_pretrained("merged")
#push merged model to the hub
merged.push_to_hub("codegen-350M-mono-python-18k-alpaca")
tokenizer.push_to_hub("codegen-350M-mono-python-18k-alpaca")
下面的屏幕截图显示了合并并将合并后的模型上传到huggingface hub的输出
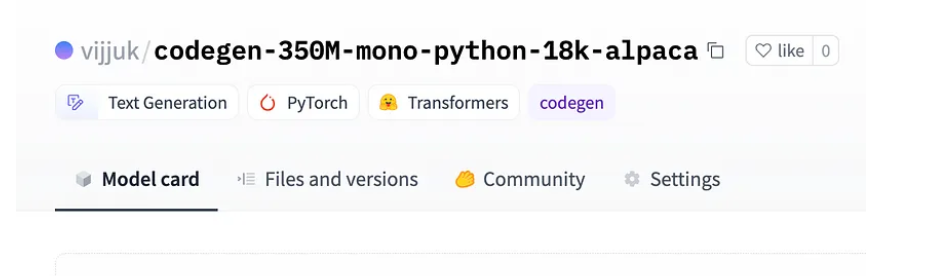
一旦上传,你应该能够在你的拥抱脸账户中找到它。下面是我的模型的屏幕截图,在拥抱脸轮毂上。
现在让我们对这些训练过的模型进行一些推断,并测试它是否真的提高了疗效。
instruction="Write a Python program to generate a Markov chain given a
text input."
input="Alice was beginning to get very tired of sitting by her sister
on the bank, and of having nothing to do: once or twice she had peeped
into the book her sister was reading, but it had no pictures or
conversations in it, `and what is the use of a book,' thought
Alice `without pictures or conversation?'"
prompt = f"""### Instruction:
Use the Task below and the Input given to write the Response,
which is a programming code that can solve the Task.
### Task:
{instruction}
### Input:
{input}
### Response:
"""
input_ids = tokenizer(prompt, return_tensors="pt", truncation=True).input_ids.cuda()
# with torch.inference_mode():
print(f"-------------------------\n\n")
print(f"Prompt:\n{prompt}\n")
print(f"-------------------------\n\n")
print(f"Before Training Response :")
output_before = model.generate(input_ids=input_ids,
max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.5)
print(f"Generated instruction:\n{tokenizer.batch_decode(output_before.detach().cpu()
.numpy(), skip_special_tokens=True)[0][len(prompt):]}")
print(f"-------------------------\n\n")
print(f"After Training Response :")
outputs = merged.generate(input_ids=input_ids,
max_new_tokens=100, do_sample=True, top_p=0.9,temperature=0.5)
print(f"-------------------------\n\n")
print(f"Generated instruction:\n{tokenizer.batch_decode(outputs.detach().
cpu().numpy(), skip_special_tokens=True)[0][len(prompt):]}")
print(f"-------------------------\n\n")
我们将在基本模型以及经过训练和合并的模型上运行相同的提示。下面的屏幕截图清楚地显示了微调后Python代码的输出是如何变得更好的。
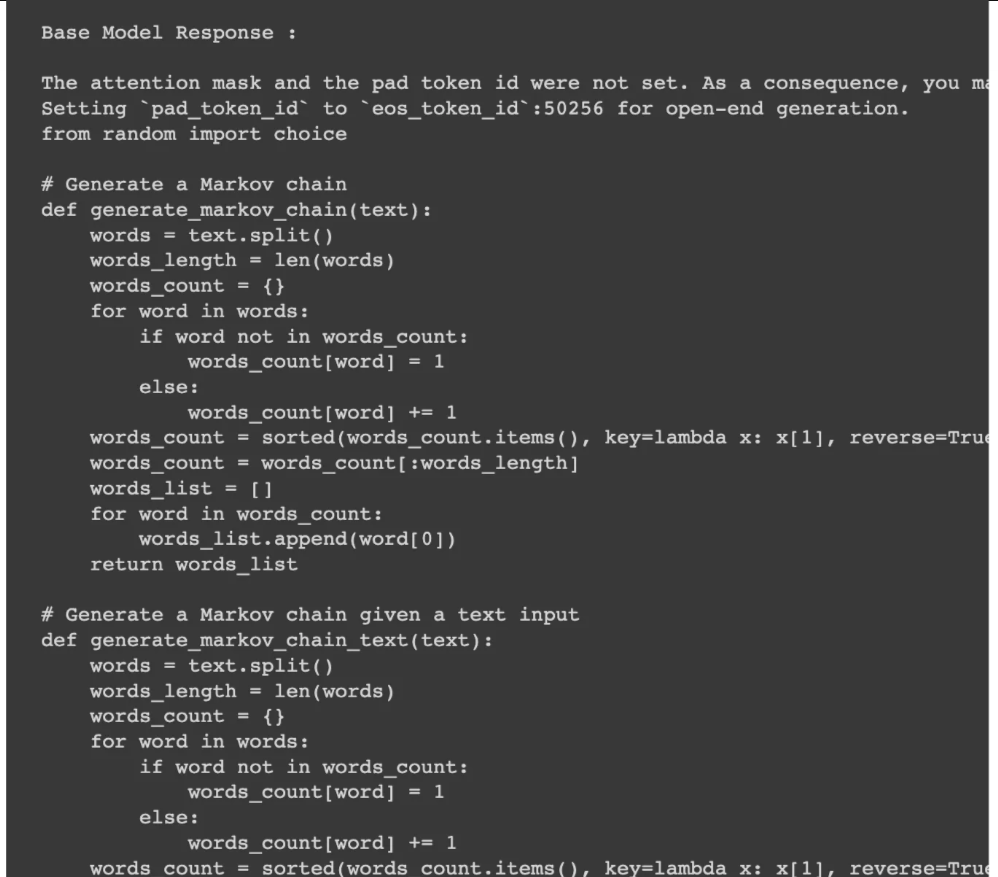
基本模型的输出

训练和合并模型的输出
现在让我们清理内存并执行垃圾收集。以下屏幕截图显示了垃圾收集之前的GPU RAM使用情况。
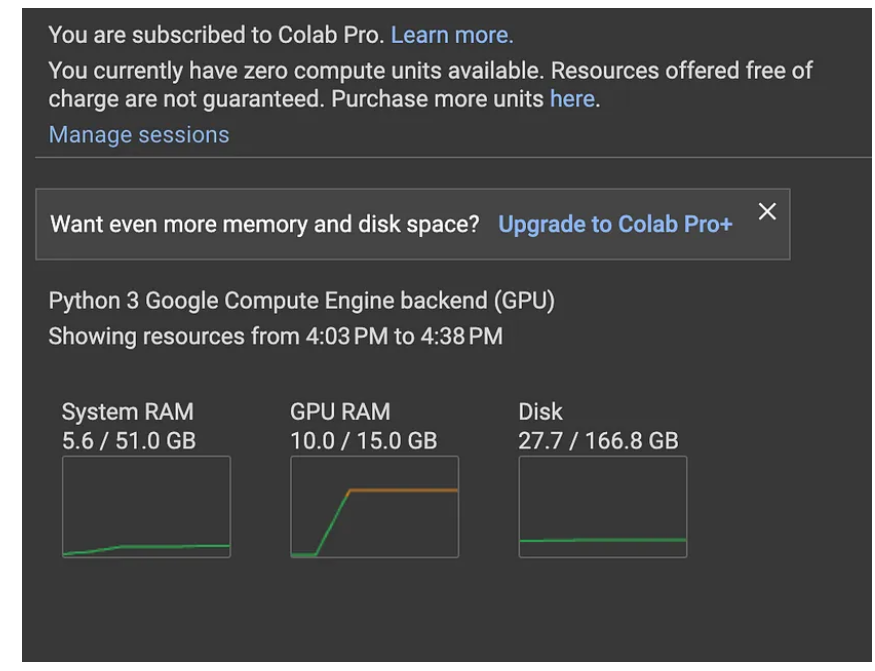
清理前的GPU RAM
import gc
# clear the VRAM
import gc
del base_model
del trained_model
del lora_merged_model
del trainer
torch.cuda.empty_cache()
gc.collect()
下面的屏幕截图显示了执行代码后的输出和GPU RAM。
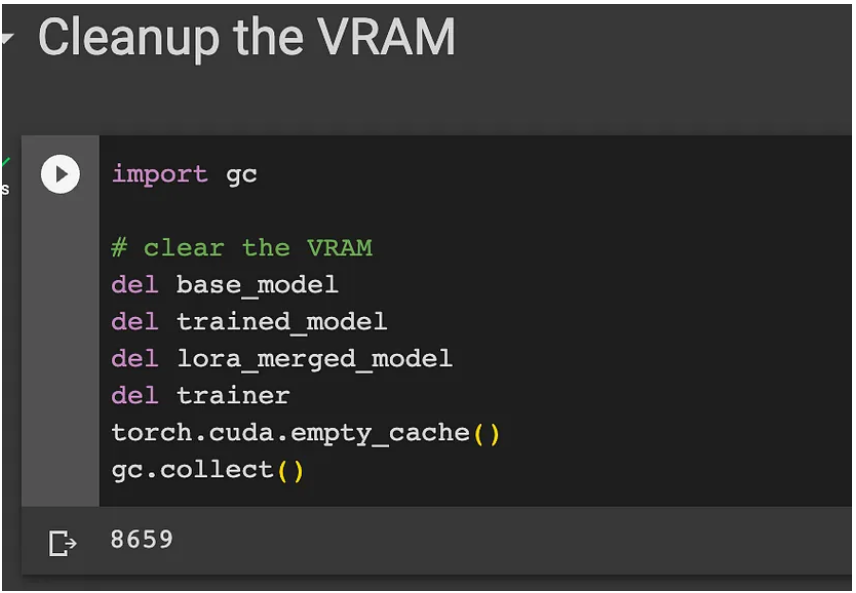
清理的输出
清理后的GPU RAM
正如你所看到的,我们能够清理RAM。通常,这是一个很好的做法,在我们进行推理之前,在训练之后这样做。
现在,我们可以使用PEFT LoRA和QLoRA技术,在Google Bollab上使用简单的T4 GPU来微调模型。你可以在我的GitHub链接上获得完整的源代码。
希望这对你有所帮助。我喜欢学习和分享我学到的东西。请随时分享您的反馈或任何错误/评论。
在此期间,我将带着更多的技术回来。玩得高兴
再见;-)
- 登录 发表评论
- 512 次浏览
最新内容
- 1 day 5 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago