
category
在为组织当前和未来的需求构建最佳数据架构的过程中,您有很多选择。由于软件的可邮寄性,这些选项几乎是无限的。但对您来说幸运的是,某些模式已经出现,可以帮助您处理数据路径,包括数据编织和数据网格。
乍一看,数据编织和数据网格概念听起来非常相似。毕竟,网格通常由一种织物制成,它们都是可延展的物品,可以放在物体上——在这种情况下,您的 IT 系统会受到不断增长的数据挤压。
但这两种方法存在根本差异,因此值得花一些时间来了解它们的差异。
数据编织
Forrester 分析师 Noel Yuhanna 是最早在 200 年代中期定义数据编织的人之一。从概念上讲,大数据编织本质上是一种元数据驱动的方式,用于连接不同的数据工具集合,这些工具以一种凝聚力和自助服务的方式解决大数据项目中的关键痛点。具体来说,Data Fabric 解决方案在数据访问、发现、转换、集成、安全、治理、沿袭和编排等领域提供功能。 Graph 也经常用于链接数据资产和用户。
Momentum 正在构建数据编织概念,作为一种在日益多样化的环境中简化数据访问和管理的方式,包括事务和操作数据存储、数据仓库、数据湖和湖屋。组织正在构建更多的数据孤岛,而不是更少,随着云计算的发展,围绕数据多样化的问题比以往任何时候都大。

- A data fabric consists of multiple data management layers (Image source: Eckerson Group)
借助几乎覆盖在各种数据存储库之上的单一数据编织,组织可以为不同的数据源和下游消费者(包括数据管理员、数据工程师、数据分析师和数据科学家)带来某种统一管理。但需要注意的是,管理是统一的,而不是实际的存储,它仍然是分布式的。
包括 Informatica 和 Talend 在内的一些工具供应商提供包含上述许多功能的实用数据编织,而其他工具供应商(例如 Ataccama 和 Denodo)则提供特定的数据编织部分。 Google Cloud 还通过其新的 Dataplex 产品支持数据编织方法。数据编织中各种组件之间的集成通常通过 API 和通用 JSON 数据格式进行处理。
数据网格
虽然数据网格旨在解决许多与数据编织相同的问题,即在异构数据环境中管理数据的困难,但它以完全不同的方式解决问题。简而言之,虽然数据编织试图在分布式数据之上构建一个单一的虚拟管理层,但数据网格鼓励分布式团队组在他们认为合适的时候管理数据,尽管有一些共同的治理规定。
数据网格概念最初是由 Zhamak Dehghani 写下的,他现在是 Thoughtworks North America 的下一代技术孵化主管。 Dehghani 在她 2019 年 5 月的报告“如何超越单体数据湖到分布式数据网格”中阐述了数据网格的许多原则和概念,随后她在 2020 年 12 月发布了题为“数据网格原则和逻辑架构”的报告。”
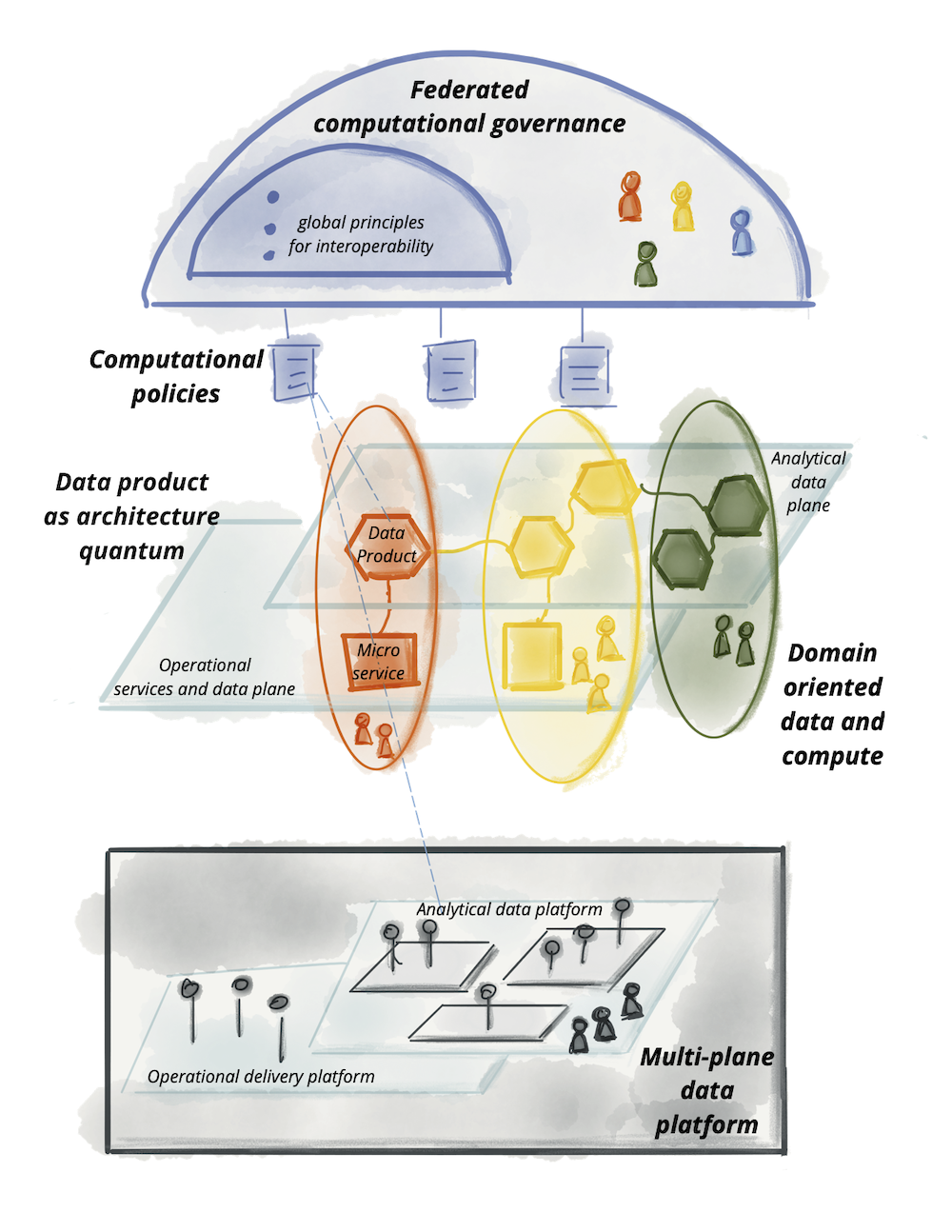
正如我们今年早些时候所写的,驱动数据网格的核心原则是纠正数据湖和数据仓库之间的不一致。第一代数据仓库旨在存储大量结构化数据让分析师用于回溯 SQL 分析,而第二代数据湖主要用于存储数据科学家构建预测性机器学习的大量非结构化数据楷模。 Dehghani 写了一个以实时数据流和云服务为标志的第三代系统 (Kappa),但它并没有解决第一代和第二代系统之间潜在的可用性差距。
许多组织构建和维护复杂的 ETL 数据管道,以尝试保持数据同步。这也推动了对负责维护拜占庭系统工作的“超专业数据工程师”的需求。
Dehghani 对这个问题提出的关键见解是,数据转换不能由工程师硬连线到数据中,而应该是一种过滤器,应用于所有用户都可用的公共数据集。因此,与其构建一组复杂的 ETL 管道来将数据移动和转换到各个社区可以分析的专用存储库,不如以大致原始形式保留数据,并且一系列特定领域的团队将拥有该数据的所有权作为他们将数据塑造成产品。 Dehghani 的分布式数据网格通过具有四个主要特征的新架构解决了这一问题:
- 面向领域的去中心化数据所有权和架构;
- 数据作为产品;
- 作为平台的自助数据基础设施;
- 联合计算治理。
实际上,数据网格方法认识到只有数据湖具有处理当今分析需求的可扩展性,但组织试图强加于数据湖的自上而下的管理方式已经失败。数据网格试图以自下而上的方式重新构想所有权结构,使各个团队能够构建满足自己需求的系统,尽管需要进行一些跨团队治理。
网格 VS 编织
正如我们所看到的,数据网格和数据编织方法之间存在相似之处。但是,也有一些差异需要考虑。
根据 Forrester 的 Yuhanna 的说法,数据网格和数据编织方法之间的主要区别在于 API 的访问方式。
“与 [数据] 编织不同,数据网格基本上是面向开发人员的 API 驱动 [解决方案],”Yuhanna 说。 “[Data Fabric] 与数据网格相反,您正在为 API 编写代码以进行接口。另一方面,数据编织是低代码、无代码的,这意味着 API 集成发生在结构内部,而不是直接利用它,而不是数据网格。”

(阿格桑德鲁/Shutterstock)
James Serra 是安永 (Earnst and Young) 的数据平台架构负责人,之前是微软的大数据和数据仓库解决方案架构师,这两种方法的区别在于用户访问它们的位置。
“数据编织和数据网格都提供了跨多种技术和平台访问数据的架构,但数据编织以技术为中心,而数据网格则专注于组织变革,”塞拉在 6 月的博客文章中写道。 “[A] 数据网格更多的是关于人和流程,而不是架构,而数据编织是一种架构方法,它以一种可以很好地协同工作的智能方式处理数据和元数据的复杂性。”
根据 Eckerson Group 分析师 David Wells 的说法,您可以同时使用数据网格和数据编织,甚至是数据枢纽
“首先,它们是概念,而不是事物,”Wells 在最近的一篇博客文章“数据架构:复杂(Complex )与复杂(Complicated.)”中写道。 “作为架构概念的数据枢纽不同于作为数据库的数据中心。其次,它们是组件,而不是替代品。架构同时包含数据编织和数据网格是切实可行的。它们不是相互排斥的。最后,它们是架构框架,而不是架构。在框架根据您的需求、数据、流程和术语进行调整和定制之前,您没有架构。”
数据网格和数据编织都在大数据表中占有一席之地。在寻找支持您的大数据项目的架构概念和架构时,一切都归结为找到最适合您自己的特定需求的方法。
Tags
最新内容
- 6 days 4 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago