

默认的Kubernetes配置可能不适合ML工作负载,从而浪费人力和计算机时间。我们展示了一轮故障排除和代码中的两行更改如何使总执行时间加快九倍。
Metaflow基础模型的MLOps
OpenAI的Whisper是一种强大的新多任务处理模型,可以在多种口语中执行多语言语音识别、语音翻译和语言识别。在之前一篇题为《基础模型的MLOps:Whisper和Metaflow》的博客文章中,Eddie Mattia讨论了使用Metaflow运行OpenAI Whisper来转录Youtube视频。它涵盖了Whisper的基本知识,如何编写Metaflow流,还简要介绍了如何在云中大规模运行此类流。尽管这里我们关注的是Whisper,但所有这些工作都可以推广到许多类型的基础模型(例如,请参阅我们关于生产用例的并行化稳定扩散的工作)。
为了部署和运行生产工作负载,许多企业都将目光投向Kubernetes,因为它已经成为在云中运行应用程序的事实方式。其与云无关的API(对用户来说)、资源的声明性语法以及庞大的开源生态系统,使其成为许多用例非常有吸引力的平台。在这一点上,我们决定在Kubernetes上使用Metaflow运行OpenAI Whisper。
然而,开箱即用,系统的性能对于ML工作负载来说可能相当糟糕。但是,通过一点故障排除,我们能够识别瓶颈并显著提高性能。其结果是一个可用于生产、性能足够高的ML工作流,能够跨多个维度进行扩展。
Whisper型号
OpenAI Whisper有多种不同大小的机器学习模型。这些是使用不同的参数集创建的,并支持不同的语言。
考虑一个团队想要评估ML模型的大小、转录时间和输出的实际质量之间的关系的情况。对于一些不同的输入,团队希望使用不同的模型大小运行Whisper并比较结果。Metaflow可以很容易地在这些维度上填充结果,因此您可以在不编写额外代码的情况下就这种权衡做出明智的决定。
对于3个不同的Youtube URL以及评估小型和大型模型,评估结果如下:
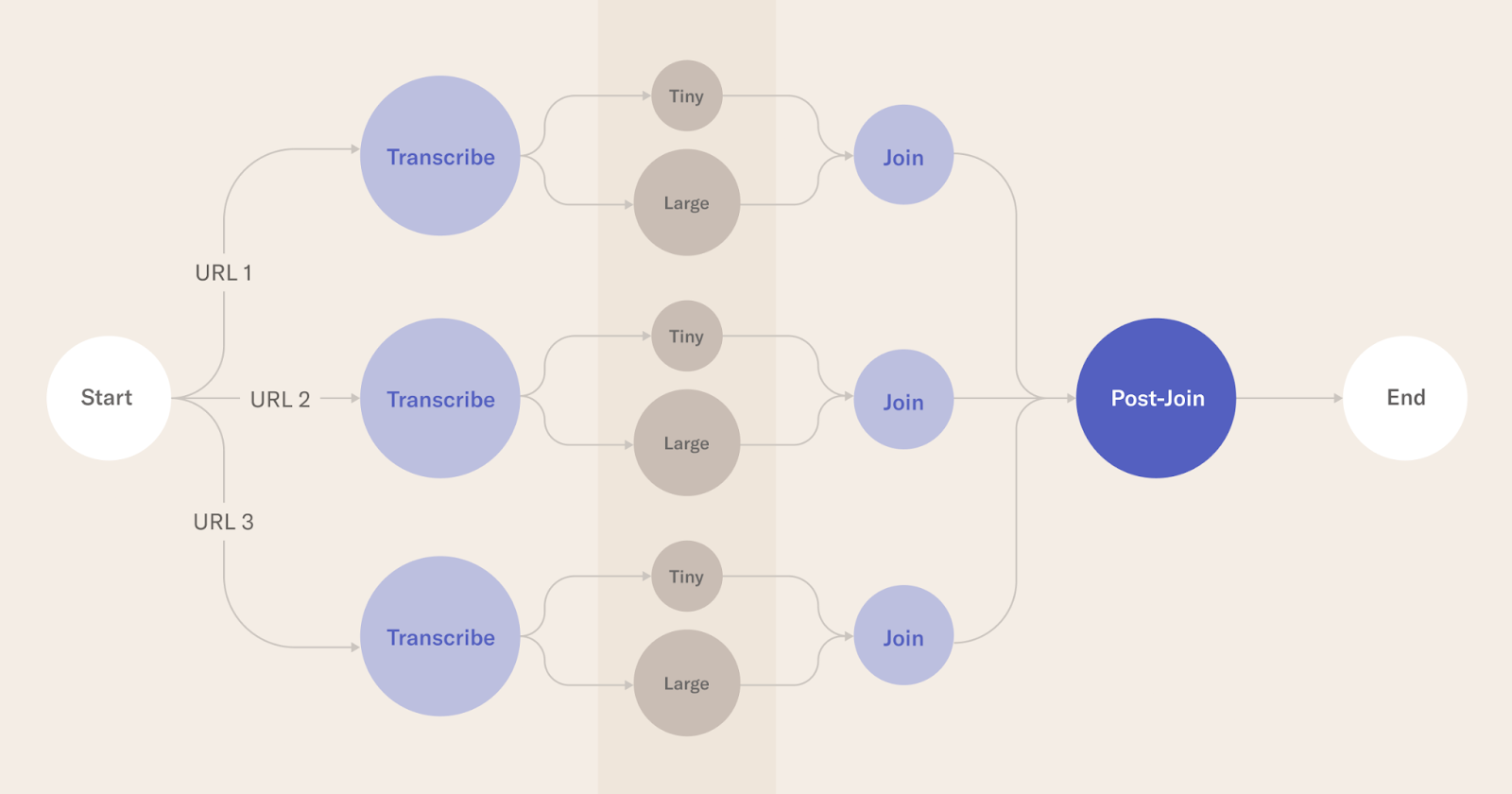
Logical block diagram of the steps involved in the Metaflow run
每个圆圈都是Metaflow中的一个步骤。transcript是使用Metaflow的foreach构造为每个URL并行调用的。对于小型和大型模型,每个转录都会做另一个foreach。
实际的转录发生在分别使用Whisper的小型和大型机器学习模型的微小和大型步骤中。
联接步骤执行特定于给定url的任何后处理。加入后步骤可以对输出质量、所花费的时间等进行实际评估。
这方面的源代码可以在这里找到:https://github.com/outerbounds/whisper-metaflow-k8s
对于这篇特别的帖子,我们使用了Youtube频道BBC Learning English的3段视频进行评估。
首先,该流程在具有64GB内存的M1 Macbook Pro上本地运行。这主要是为了确认代码执行正确,并且输出是预期的格式。
多亏了Metaflow,运行流就像执行一样简单:
python3 sixminvideos.py run
这项运行在大约10分钟内完成(见下文),考虑到在此期间并行发生了6种不同的转录,这令人印象深刻。请注意,OpenAI Whisper下载机器学习模型并将其缓存在本地。在这种情况下,这些模型已经在本地缓存。否则,时间会更长。
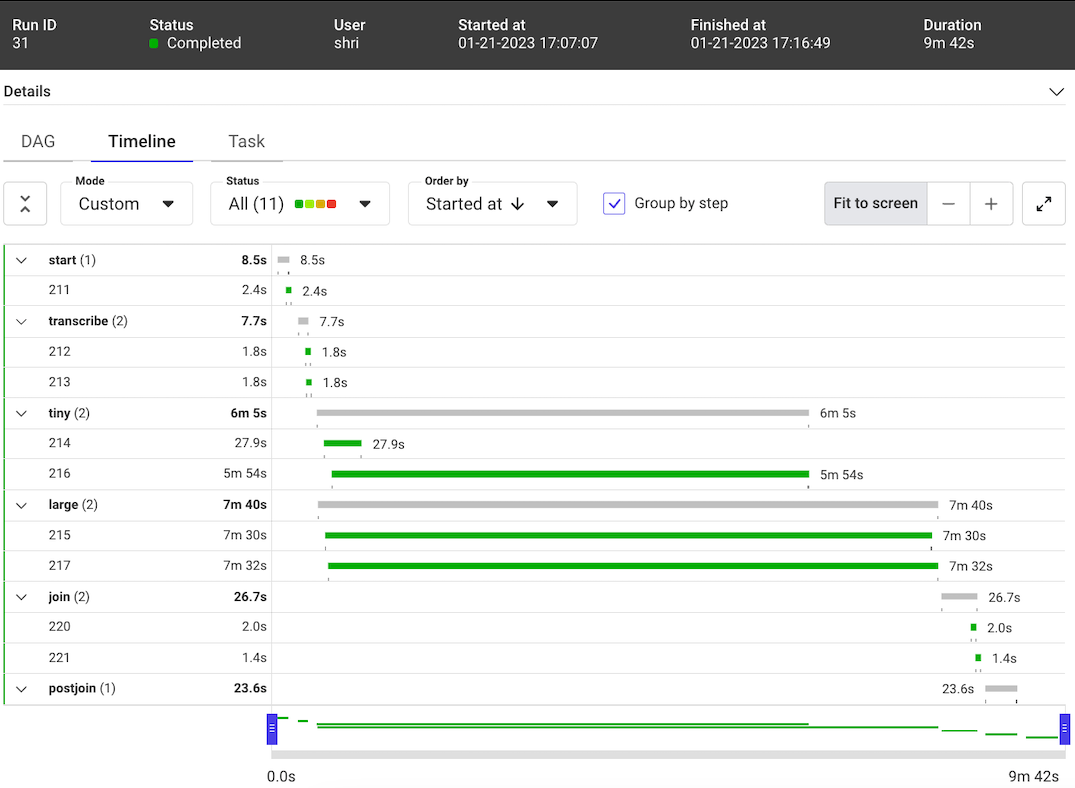
Timeline view of the Metaflow run on M1 Mac
Kubernetes上带有Metaflow的Whisper模型
让我们在Kubernetes上运行相同的流。有关更多设置和详细信息,请参阅这些说明。在我们的设置中,Kubernetes集群被设置为在AWS上运行,并包括两个m5.8xlarge EC2实例。
在Kubernetes上运行流的最简单方法是运行与上面相同的CLI命令,后跟–with Kubernetes。在后台,Metaflow连接到Kubernetes集群,并运行集群中的每个步骤。因此,使用kubernetes运行流导致每个步骤都在云中运行。
Kubernetes中最小的可执行单元是一个pod。在这种情况下,Metaflow从每个步骤中获取代码,将其放入Linux容器中,并将与该步骤对应的每个任务作为Kubernetes pod运行(一个步骤可能会在foreach中产生多个具有不同输入的任务)。
以下是在Kubernetes上执行的情况:
python3 sixminvideos.py run --with kubernetes
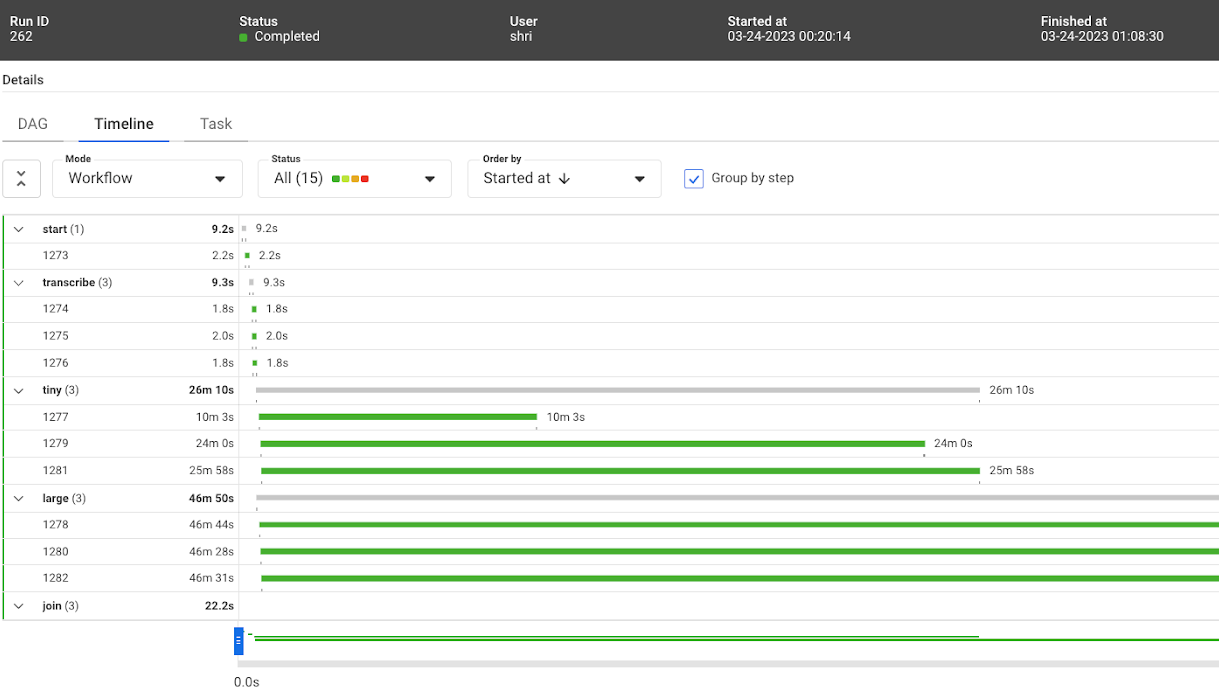
Timeline view of the first Metaflow run on Kubernetes
流程已成功完成。然而,上面的图片显示,它花费了48m15。这几乎比在本地笔记本电脑上运行此流程所需的时间慢了五倍。在云中运行流的承诺是提高性能,而不是降低性能!
流的源代码在两次运行中都是相同的。从步骤的开始和结束时间来看,很明显,Metaflow在两次运行中都正确地编排了步骤。步骤顺序得到了维护,本应并行运行的步骤实际上是并行运行的。
我们知道,M1 Mac上的本地运行和Kubernetes上的运行之间的比较并不完全公平,因为Kubernete中的每个pod都缺乏共享存储。因此,每次pod启动时都会重新下载模型,增加了一些开销。此外,如果包含ffmpeg等依赖项的Docker映像没有缓存在节点上,则需要下载它,从而增加更多的开销。
尽管如此,五倍的放缓感觉并不正确。Kubernetes中是否存在一些错误配置,导致流花费了这么长时间?让我们来看看!
分析Kubernetes中的工作负载性能
让我们更深入地了解这种性能下降的瓶颈是什么。
CPU和内存消耗
在创建pod时,Kubernetes允许用户请求一定数量的内存和CPU资源。这些资源是在创建时为pod保留的。实际使用的内存和CPU数量可能会随着吊舱的使用寿命而变化。此外,根据您的Kubernetes配置,pod实际使用的资源量可能超过请求的数量。然而,当资源超过请求的数量时,并不能保证pod会真正获得资源。
以下图表显示了该流中每个pod请求和使用的资源之间的关系(这些图表是使用集群中运行的Grafana仪表板获得的)。
在下图中,绿线表示pod的资源请求,黄线表示实际的资源使用情况。Y轴显示了吊舱完全利用的CPU内核的数量。
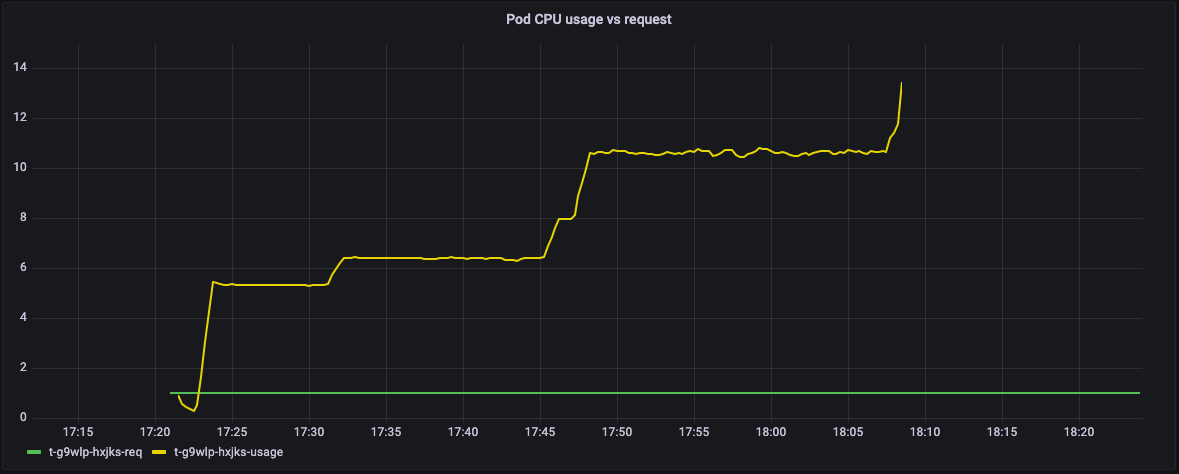
Graph of CPU utilization vs CPU requested by steps in Metaflow
事实证明,这个流中的所有pod都要求1个CPU,但实际上使用了更多,几乎13个内核。
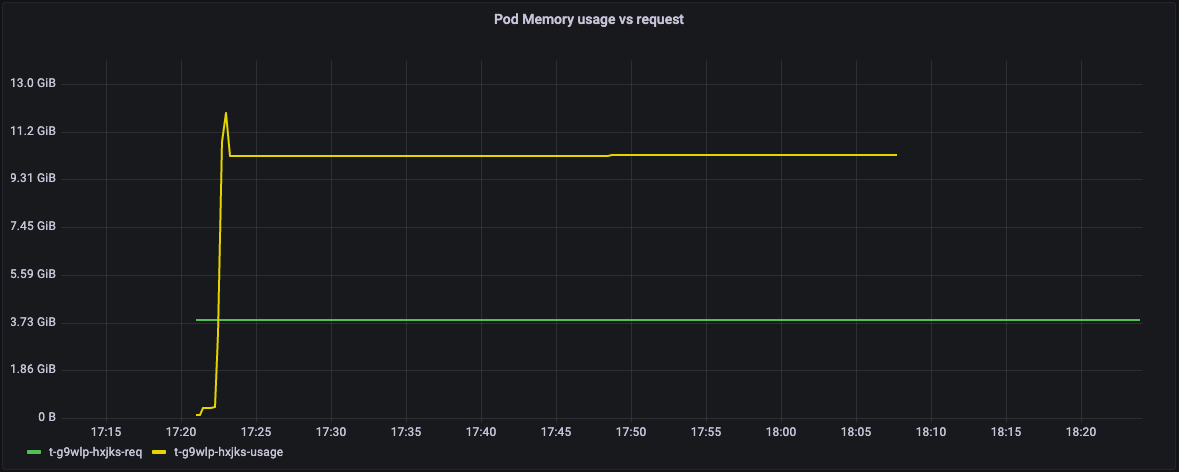
在此图表中,Y轴显示内存请求(绿线)和实际内存使用情况(黄线)。
Graph of Memory utilization vs Memory requested by steps in Metaflow
在内存方面,pod请求4GB的内存,但最终使用了近12GB的内存。
Kubernetes集群包括多个服务器(物理服务器机器、虚拟机、EC2实例等)。这些服务器被称为节点。当一个pod提交给Kubernetes时,它会选择集群中的一个节点来运行该pod。
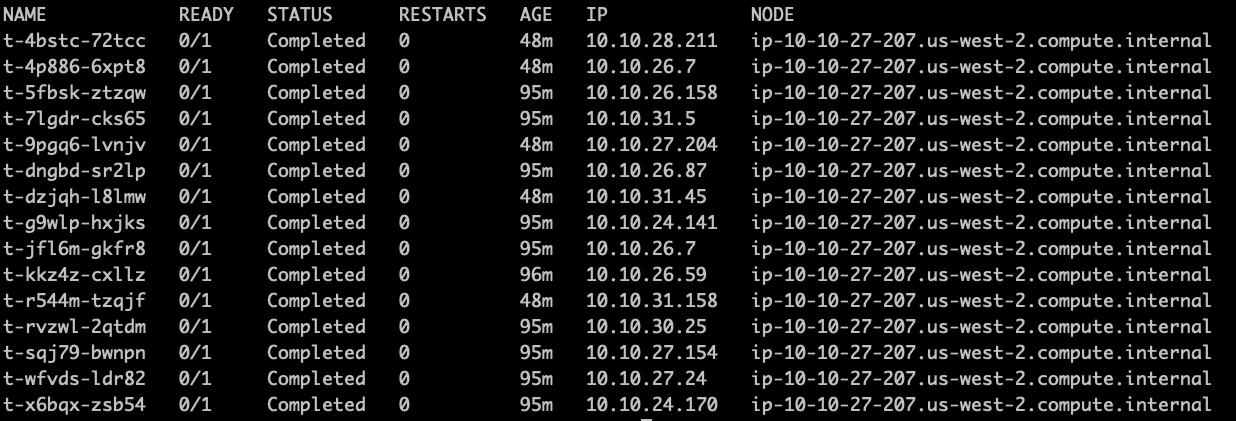
正如您在下面的stdout屏幕截图中所看到的,该流的所有pod都在同一个节点上运行:ip-10-10-27-207.us-west-2.compute.internal
List of hosts used for running steps in Metaflow
观察
关键问题是,虽然运行能够成功完成,但Kubernetes决定将所有任务安排在同一节点上,从而导致性能不理想。
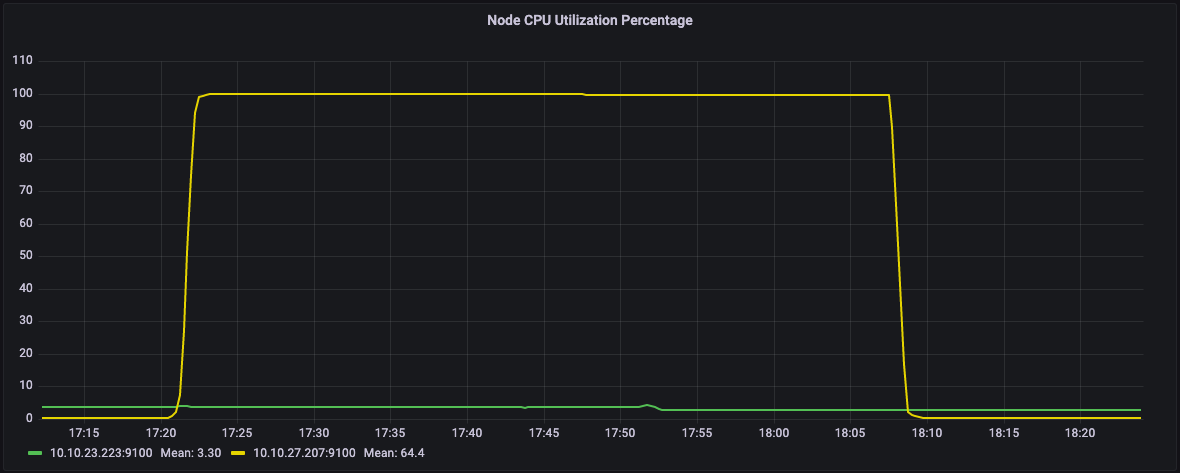
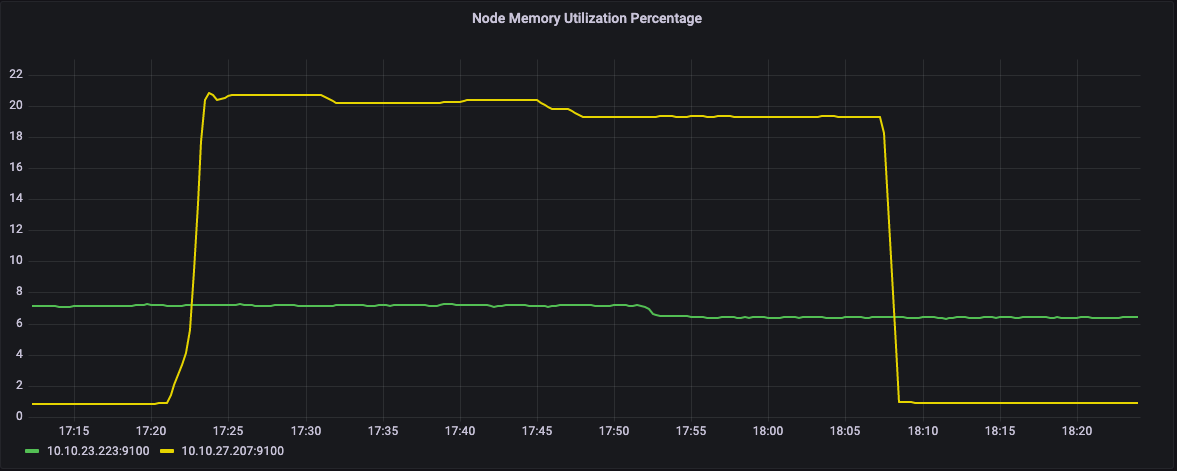
在下面的图表中,我们可以看到我们集群的两个节点。黄色线所示的节点的CPU利用率约为100%,而绿色节点处于空闲状态。相应地,绿色节点上没有使用内存。
CPU utilization percentage of the node
Memory utilization percentage of the node
在这种情况下,任务能够突破其请求的CPU数量,但由于在同一节点上的共同定位,它们在相同的稀缺资源上竞争。这清楚地证明了经常困扰多租户系统的噪声邻居问题。
令人困惑的是,调度行为取决于集群上的总体负载,因此总执行时间可能会有很大的差异,这取决于系统上同时执行的其他工作负载。像这样的可变性很难调试,而且显然是不可取的,尤其是对于应该在可预测的时间范围内完成的生产工作负载。
像这样的问题在表面上并不是很明显,因为运行最终完成时没有出现错误。这些类型的问题很容易被忽视,导致浪费人力和计算机时间,并增加云成本。
解决性能问题
Metaflow支持为各个步骤提供特定的资源需求。这些需求是作为装饰器写在代码中的。在Kubernetes pod规范中,它们被转换为CPU和内存请求。我们不依赖于机会主义的爆发,而是固定资源需求以反映实际使用情况。
这些微小的步骤可以使用8个vCPU和2GB的内存
大型步骤可以使用22个vCPU和12GB的内存。
因此,Metaflow流被相应地设置并再次运行。
...
@kubernetes(cpu=8, memory=2048, image=”https://public.ecr.aws/outerbounds/whisper-metaflow:latest”)
@step
def tiny(self):
print(f"*** transcribing {self.input} with Whisper tiny model ***")
cmd = 'python3 /youtube_video_transcriber.py ' + self.input + " tiny"
p = subprocess.run(shlex.split(cmd), capture_output=True)
json_result = p.stdout.decode()
print(json_result)
self.result = json.loads(json_result)
self.next(self.join)
@kubernetes(cpu=22, memory=12288, image=”https://public.ecr.aws/outerbounds/whisper-metaflow:latest”)
@step
def large(self):
print(f"*** transcribing {self.input} with Whisper large model ***")
cmd = 'python3 /youtube_video_transcriber.py ' + self.input + " large"
p = subprocess.run(shlex.split(cmd), capture_output=True)
json_result = p.stdout.decode()
print(json_result)
self.result = json.loads(json_result)
self.next(self.join)
...通过这种设置,流量在4m58s内完成
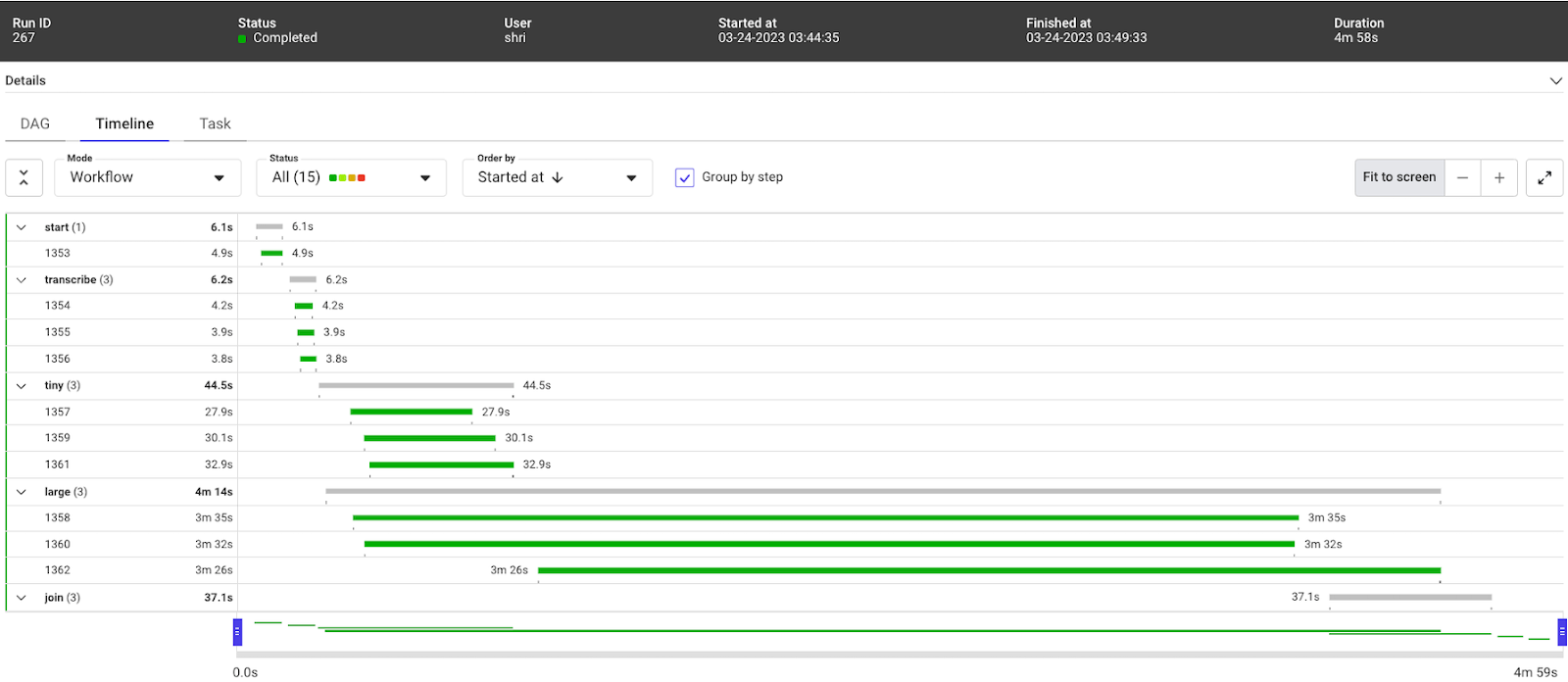
Timeline view of the efficient Metaflow run on Kubernetes
从节点CPU利用率可以看出,这一次,任务在多个节点上运行。具体来说,CPU并没有固定在100%。
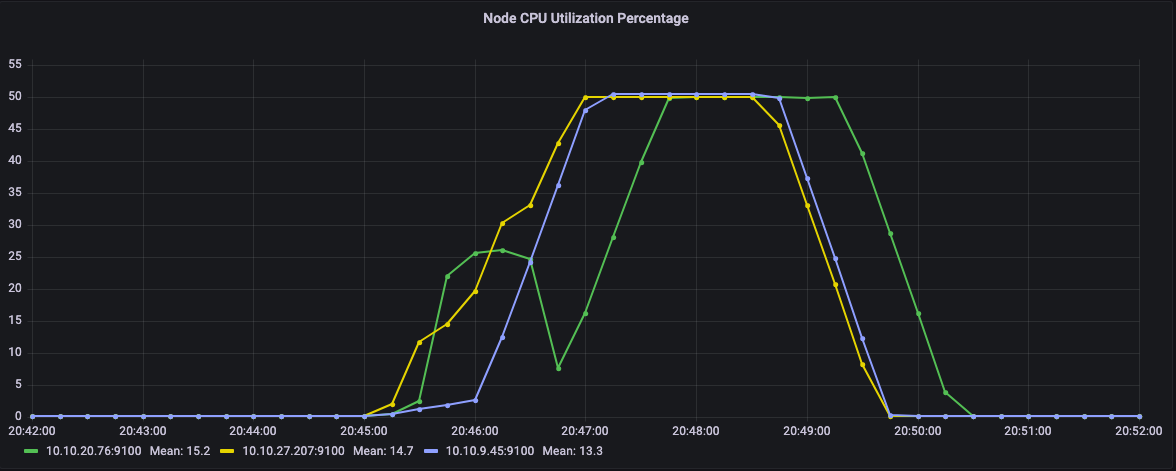
Graph of CPU utilization of the nodes in Kubernetes
结论
经过仔细观察,我们能够将之前48分钟的完成时间减少到大约5分钟,只需调整两个资源规格,就可以将性能提高9倍。
运行的优化有很多好处,包括能够进行更多的实验。现在可以通过添加更多并行步骤来测试各种模型大小,而不是仅限于测试小型和大型模型,每个步骤都将作为单独的pod运行,并拥有自己的专用资源。此外,流现在可以转录更多的视频,而不是仅限于3个。
接下来的步骤
如果您想在自己的环境中部署Metaflow和Kubernetes,可以使用我们的开源部署模板轻松完成。您可以根据需要自定义模板,并将它们连接到现有的监控解决方案中,这样您就可以如上所述调试问题。如果您有任何问题,我们很乐意在我们的Slack频道为您提供帮助。
如果您想自己使用Metaflow玩Whisper模型,您可以在我们托管的Metaflow Sandbox中免费轻松完成,该Sandbox配有托管的Kubernetes集群,无需基础设施专业知识!我们专门为Whisper提供了一个预先制作的工作空间,包含所有需要的依赖项。只需点击Metaflow沙盒主页上的Whisper工作区。
最后,如果您需要一个全栈环境来处理严重的ML工作负载,但您宁愿避免调试Kubernetes和手动优化工作负载,那么可以看看Outerbounds平台。它提供了一个定制的Kubernetes集群,经过优化以避免这里描述的问题,部署在您的云帐户上,完全由我们管理。
Tags
最新内容
- 6 days 12 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago