
我们以Databricks的Dolly为代表,展示了如何使用Metaflow轻松地训练自己的大型语言模型(LLM)。通过使用Metaflow处理LLM,您可以将它们合并到现有的生产项目中,超越概念验证。
在我们上一篇文章《大型语言模型和ML基础设施堆栈的未来》中,我们展示了关于ML驱动的应用程序的未来的示意图,这些应用程序无缝地混合了基础模型和传统ML:
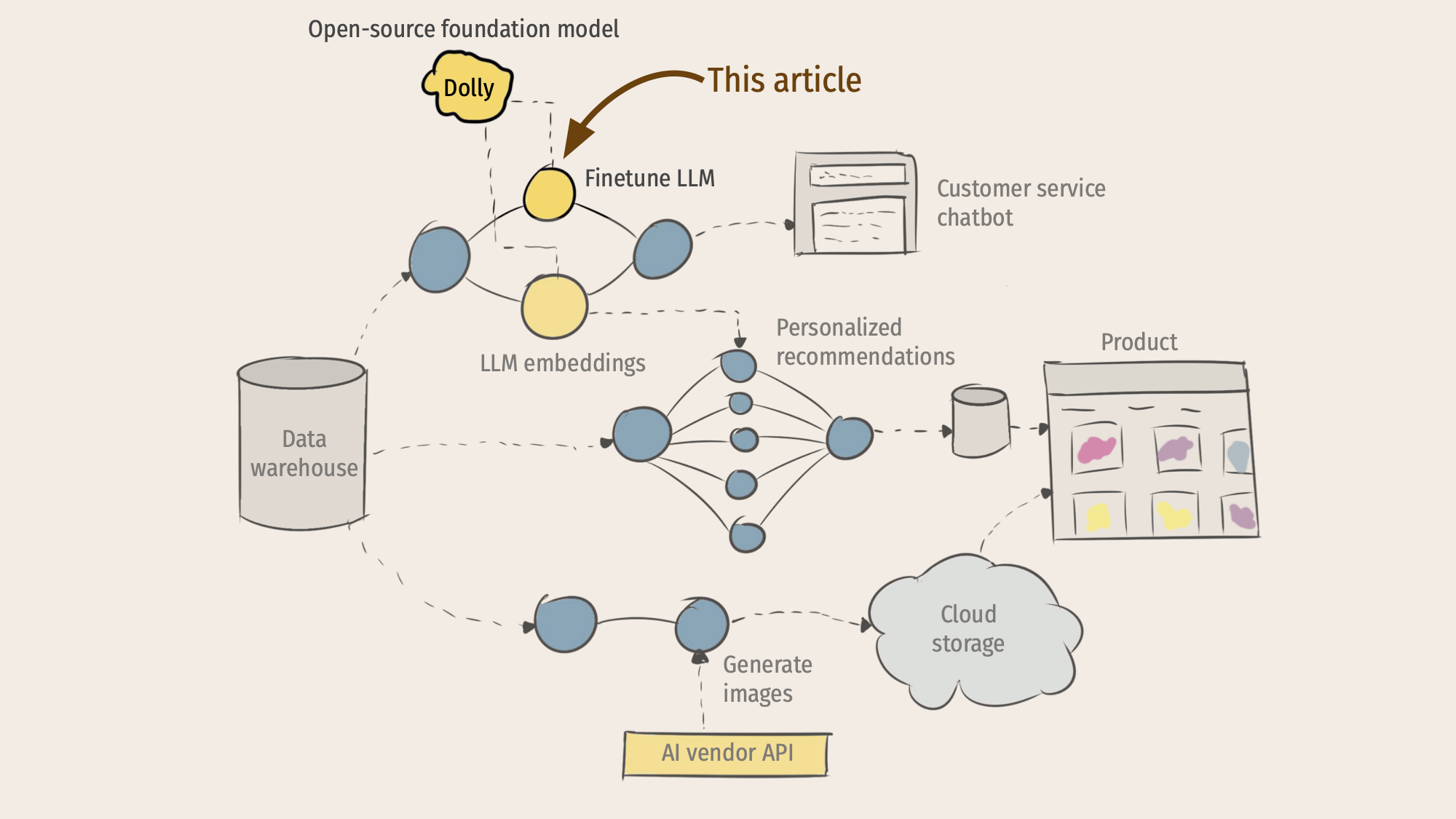
本文深入探讨了一个特定的技术主题:今天如何使用开源Metaflow来微调开源基础模型?作为一个代表性的例子,我们将使用Databricks最近发布的Dolly模型,但这里介绍的方法也适用于其他当前和许多未来的模型。
训练Dolly的源代码可以作为一组简单的Python脚本免费提供,那么使用Metaflow来编排训练有什么意义呢?原因很简单:如上所述,在一个LLM被视为支持复杂应用程序的其他模型之一的世界里,您希望利用Metaflow的常见优势:
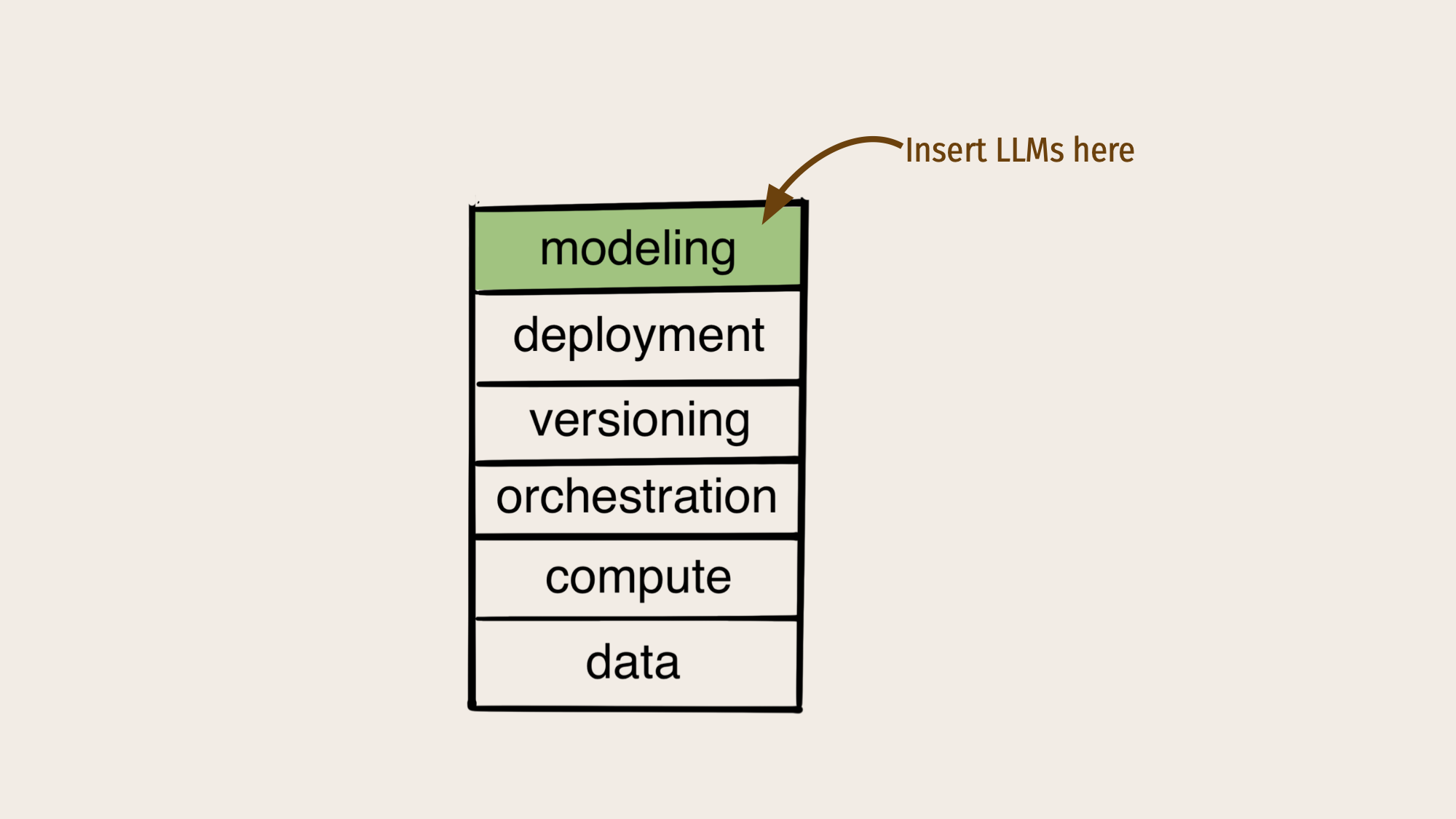
- 能够为工作使用最佳建模方法和库,支持围绕LLM快速发展的库生态系统,但以稳定、安全和可生产的方式使用它们。
- 支持各种应用程序的灵活部署模式。
- 内置数据、代码和模型的版本控制,这对于需要密切跟踪其行为的复杂模型(如LLM)尤其重要。
- 轻松协调本地和生产中的工作流序列,使其成为整个系统架构的骨干。
- 无缝支持可扩展的云计算,包括强大的GPU实例。
- 对数据的一致且快速的访问,即使是大量的数据。
考虑到这一动机,让我们深入了解技术细节。
开源基金会模型简史
在过去的六个月里,基于一些基础模型,出现了一个由各种微调LLM组成的多样化花园。这种快速发展的驱动因素是,使用云TPU或GPU从头开始训练一个新的基础模型的成本可能在30万至100万美元之间。相比之下,对基础模型的专门版本进行微调要便宜很多数量级。例如,本文中使用的Dolly模型可以在几个小时内进行训练,成本约为500-1000美元。
下图说明了这些模型的庞大谱系:
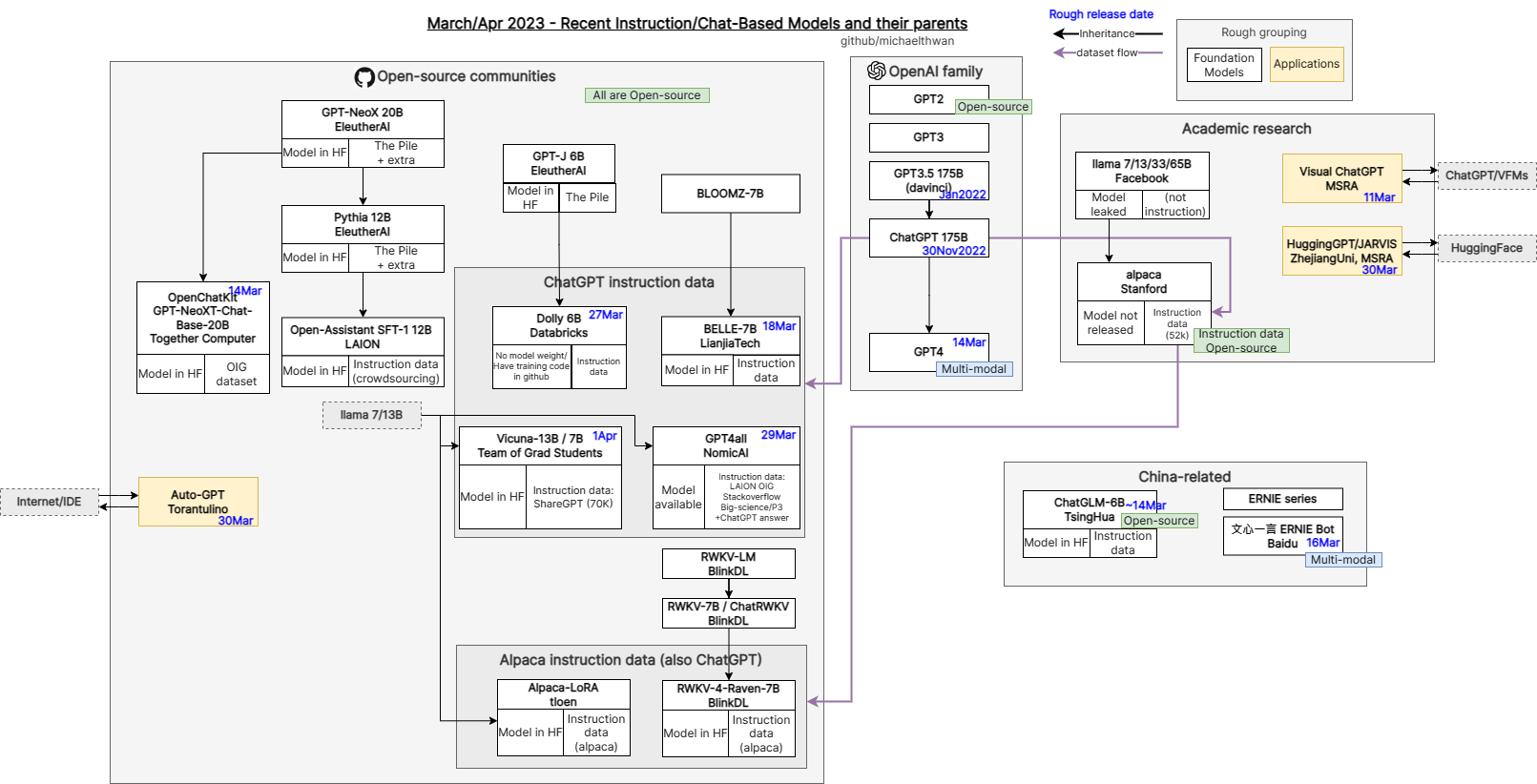
Source: github.com/michaelthwan/llm_family_chart
自最初的Dolly以来,Databricks已经推出了Dolly 2.0,它基于不同的模型,并通过使用内部策划的微调数据集使Dolly 2.0在商业上可用。两个Dolly版本都源于Eleuther AI团队构建的源模型。在第一个Dolly的情况下,60亿参数模型被称为GPT-J,其中Dolly 2.0源于120亿参数模型pythia。
最近,Stability.ai发布了StableLM,这是另一个基础语言模型,与Dolly利用的GPT-J模型类似。随着Dolly训练GPT-J,现在已经有几个模型可以开始为更具体的任务微调StableLM。
这些例子突出了LLM工作流中的最新浪潮,它们围绕着指令调优方法,使模型越来越适合提示,正如ChatGPT所推广的那样。当然,这并不是LLM的唯一用例,但它对基于问答的应用程序非常有用。
随着人们探索扩展这些工作流程的新技术和方法,指令调整模型的改进正处于狂野的西方时代。无论如何,这些模型的高周转率表明了了解这些模型来自何处以及组织现在可以做出哪些基础设施选择以支持任何这些新的建模方法的重要性。
Dolly的供应链
Dolly的用户体验表明,机器学习社区,特别是HuggingFace等服务,在让大量开发人员可以访问复杂的建模API方面取得了多大进展。我们首先加载预训练的源模型:
model = transformers.AutoModelForCausalLM. from_pretrained(“EleutherAI/gpt-j-6B”)
然后,Dolly使用HuggingFace Trainer API对一个名为Alpaca的指令调优数据集进行训练,该数据集由斯坦福大学tatsu实验室的一个团队管理。对于本文来说,最重要的是要认识到,该数据是通过提示text-davinci-003模型,使用OpenAI API生成的。这意味着我们正在从GPT-J模型的原始状态训练模型,并教它从OpenAI中提取较大的text-davinci-003模型的行为,并在较小的Dolly模型中模拟其指令跟随功能。最终的数据集包含52K个指令调优示例。
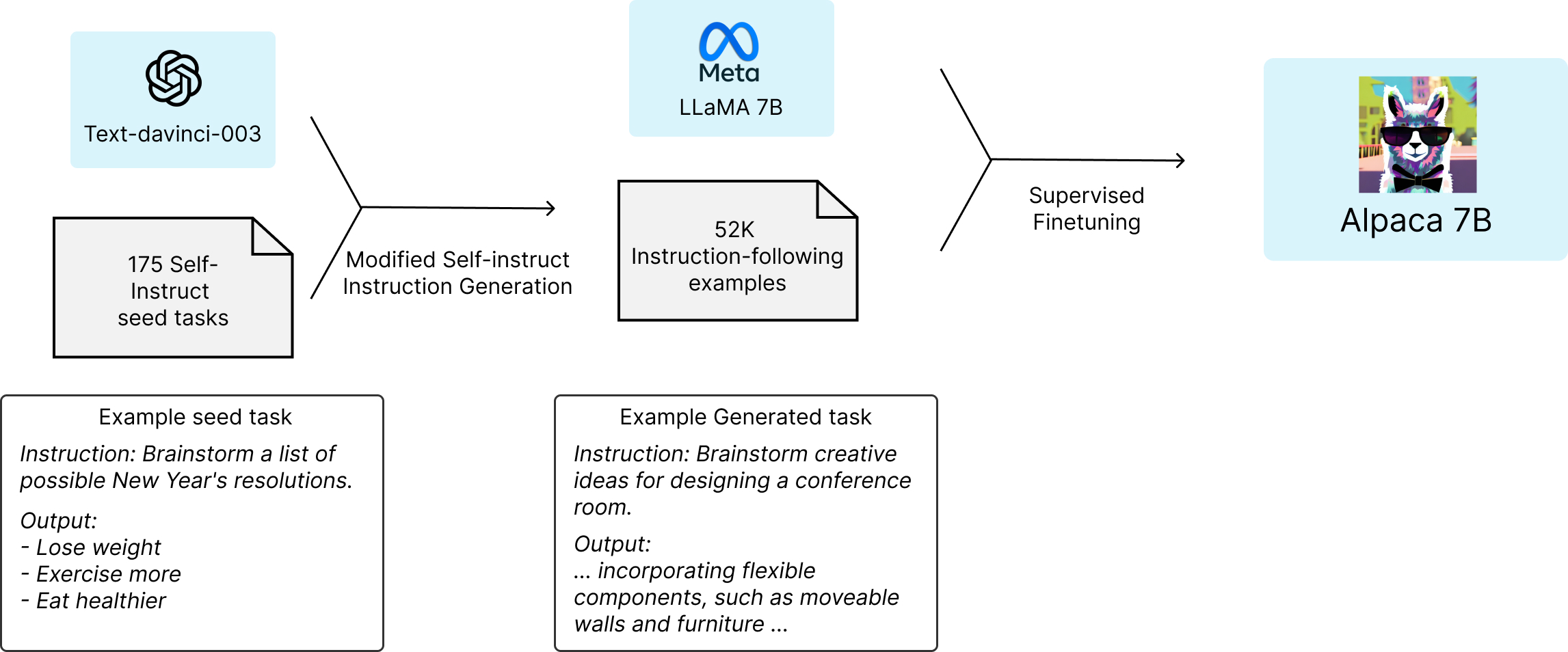
请注意,由于对Alpaca数据集的依赖,该数据集具有Creative Commons NonCommercial(CC BY-NC 4.0)许可证,您不能在商业应用程序中使用此示例或Dolly版本1,需要用您自己的指令调优数据集替换Alpaca数据依赖,或者使用具有免费商业使用许可证的东西。
使用Metaflow训练Dolly
为了重现Databricks团队的实现,并证明Metaflow对LLM用例的适用性,我们在各种上下文中训练了Dolly。您可以在此存储库中找到源代码。
我们创建了一个简单的元流,它由三个步骤组成,开始、训练和结束。Metaflow的超能力之一是,我们能够在个人GPU工作站上本地快速迭代流。我们遵循了现有的Dolly脚本,并使用微软的deepspeed库在许多GPU上分发培训。Deepspeed与PyTorch和HuggingFace代码紧密集成,因此这是一种可以用于训练大型深度学习模型的通用模式。
我们的本地工作站没有多个GPU,所以为了测试分布式训练,我们注释了步骤@kubernetes(gpu=4)在具有多个gpu的云实例上执行训练步骤。从概念上讲,流程看起来是这样的:
在源代码中,黄色方框的核心部分如下所示:
...
@kubernetes(cpu=32, gpu=4, memory=128000)
@step
def train(self):
...
subprocess.run(
[
“deepspeed”,
“–num_gpus=%d” % N_GPU,
“–module”, MODEL_TRAINING_SCRIPT,
“–deepspeed”, ds_config_file.name,
“–epochs”, “1”,
“–local-output-dir”, self.local_output_dir,
“–per-device-train-batch-size”, self.batch_size,
“–per-device-eval-batch-size”, self.batch_size,
“–lr”, self.learning_rate
],
check=True
)
# push model to S3当涉及到代码时,这就是训练模型所需要的全部内容!
但它真的有效吗?
当你开始运行流时,它会很高兴地开始在一个大型GPU实例上处理数据,并在训练过程中沉默数小时。
特别是对于这样一个新的实验项目,我们不确定深度速度设置是否正确工作,是否有效地利用了所有GPU。为了解决这种常见情况,最近我们创建了一个Metaflow卡来分析GPU的使用情况。要使用它,请将gpu_profile.py放在流文件旁边,并在代码中添加以下行:
...
@kubernetes(cpu=X, gpu=Y, memory=Z)
@gpu_profile(interval=1)
@step
def train(self):
...Metaflow任务GPU探查器向我们展示了一些东西,例如哪些NVIDIA设备在实例上可见,它们是如何连接的,最重要的是,它们在模型训练作业的整个生命周期中是如何使用的。
GPU探查器会自动将结果记录到Metaflow卡中,因此您可以在Metaflow UI(或笔记本)中方便地查看的报告中使用建模指标和其他实验跟踪数据来组织和版本化这些结果。卡片在实验过程中特别有用,因为它们永久地连接到生成卡片的运行中,因此您可以在自动版本化的代码和与实验相关的数据的上下文中轻松地观察过去的性能。
以下是一张示例卡,显示了训练Dolly时代的GPU处理器和内存利用率:
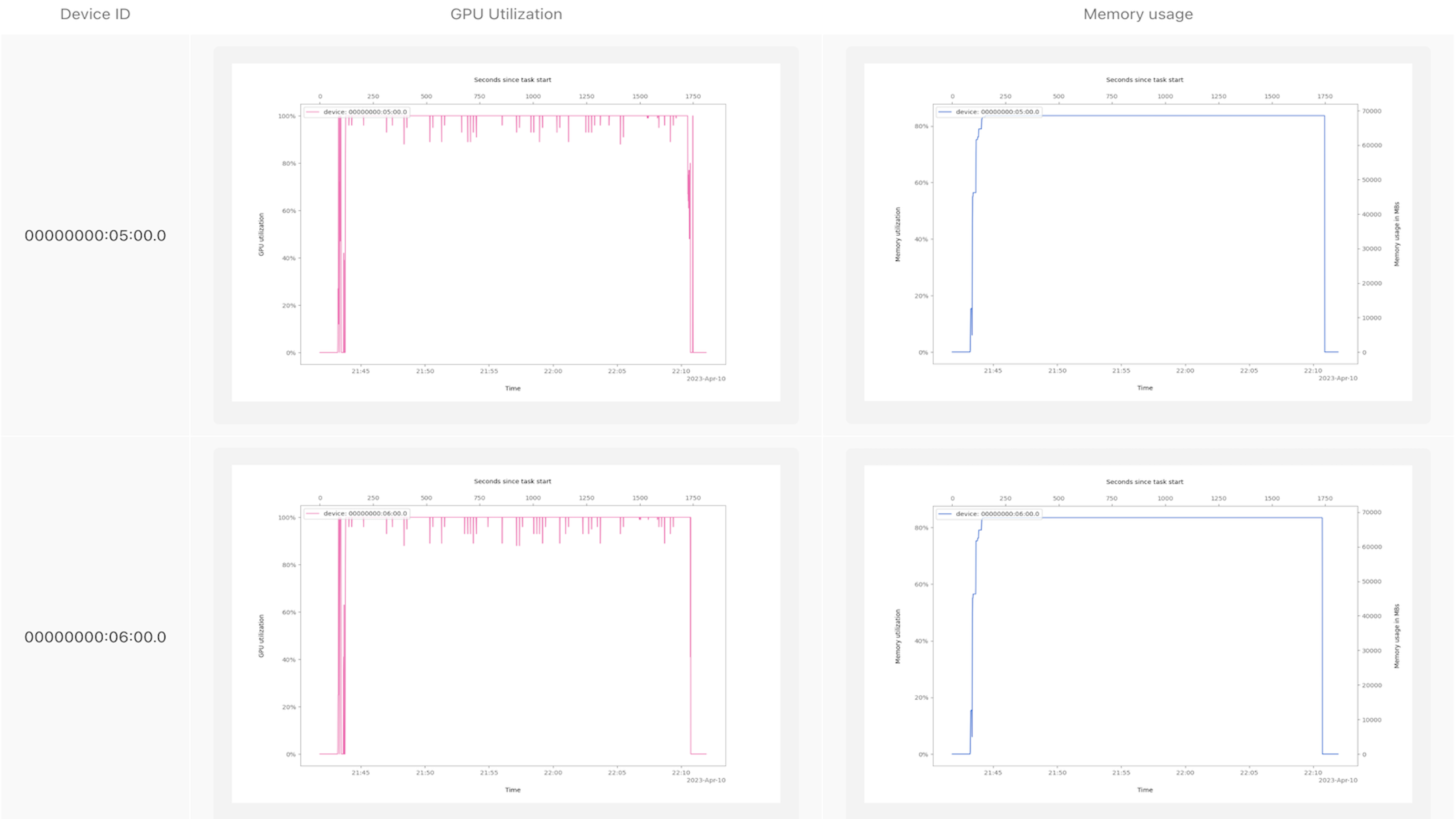
看到这些图表让我们有足够的信心相信GPU正在执行有用的工作。
常见的基础设施问题
假设您已经为Metafow设置了基础设施,您可以运行上面的Metaflow流来自己训练Dolly。您可以使用AWS Batch或Kubernetes来重现上述结果,它们可以方便地与所有主要云一起工作。或者,如果你想完全避免基础设施方面的麻烦,你可以依赖Outerbounds平台。
在我们的初始测试中,我们使用AWS一个p3dn.24xlarge EC2实例来训练Dolly一个历元。这个进程运行的实例有8个V100 GPU,每个GPU都有32GB的内存。我们使用了AWS深度学习AMI,能够在3小时15分钟内运行一个历元的模型。这大约花了100美元。由于AWS上的p4实例不可用,我们还在Corewave节点上运行了相同的软件设置,该节点具有3个A100 GPU,每个GPU具有80GB内存。我们对这个模型进行了10个时期的训练,大约花了30个小时。这大约花了200美元。
除了与寻找足够大的GPU实例来运行代码有关的头痛问题外,谨慎管理依赖关系至关重要,这是深度学习中一个无声的生产力杀手。例如,当使用NVIDIA GPU时,在数据科学层工作时,CUDA驱动程序和CUDA工具包组件(如NVCC编译器)之间的不对齐可能会导致流中断调试周期。我们发现Dolly使用以下组合:
- Ubuntu 20.04 or 22.04
- NVIDIA driver version 515.105.01
- CUDA Version >= 11.1 and <= 11.8
值得庆幸的是,无论需要环境的任务是在工作站上本地运行,还是在计算集群中远程运行,开源Metaflow和Outerbounds平台都可以轻松地对环境进行版本设置。
评价
最后,有了我们所有的基础设施,我们能够开始探索Dolly的语言和推理能力的极限。Dolly可以执行一系列令人惊讶的任务,包括文本生成、头脑风暴和开放式问答。
正如Databricks在Dolly v1 HuggingFace模型卡中所指出的那样,“Dolly的定性行为与基础模型有很大不同”,尽管“Dolly[得分]仅略好于其基础模型GPT-J-6B[在常见LLM评估基准上]”。验证Databricks的上述说法很有启发性,因为我们观察到,当我们要求模型在训练的不同阶段生成对一组常见指令的响应时,它的响应往往会发生变化。
例如,我们要求模型“写一个关于一个人的故事,他因为被决策树缠住而看不到随机森林”,看看它如何处理创造性的讲故事风格的提示。请注意,随着训练越来越多,该模型在回答中开始强调指令中的“写故事”部分,似乎在解释一个有点开放和模糊的提示时变得更好了。
| Epoch | Sample Response |
|---|---|
| 1 | When people think of random forests, they often think of the trees being randomly selected from a dataset and being used to make predictions. What they may not know is that when a random forest is built, each tree is created with a rule to determine the best split for a given feature. |
| 5 | Anil was lost in a thick forest of decision trees. Every step he took felt like he was forcing his way through an endless series of obstacles. He had been walking for hours, and he was still no closer to finding the trail he had been following. His only hope was that eventually he would stumble upon the clearing that had caused his vision to fail him earlier. |
| 10 | John was an engineer who couldn’t get past the first layer of decision trees. He had worked so hard to understand the data, but something was just wrong with the random forest he was seeing. He worked his way deeper and deeper into the forest, but there were just too many branches and too many combinations of variables that he didn’t understand. John was completely lost, unable to progress any further and in need of a boost to get him out. That’s when he discovered the random forest again, and it gave him the inspiration he needed to understand the data. |
这个例子说明了我们的一个主要定性观察结果,即整个训练过程中响应的演变表明,随着训练的增加,模型开始编写更详细和详细的响应,与许多人在ChatGPT等产品中熟悉的GPT模型更相似。这并不奇怪,因为我们已经讨论过,我们正在训练的Alpaca数据集是通过从OpenAI查询GPT模型生成的!这就是正在进行的蒸馏过程。
下一步怎么办
要使用Metaflow训练Dolly,您可以在此处找到我们的存储库。此外,您可以在任何gpu工作流中使用新的@gpu_profile 装饰器。我们很乐意听到您对此的反馈,以便我们能够进一步开发该功能。
如果你喜欢这篇文章,你可能会喜欢我们之前关于基础模型的帖子:使用Stable Diffusion的图像生成和使用Whisper的文本到语音翻译,以及你可能会遇到的基础设施问题。
如果您在开始使用Metaflow和/或试验基础模型和LLM方面需要帮助,请加入Metaflow Slack中的数千名其他ML工程师、数据科学家和平台工程师。
最新内容
- 2 days 12 hours ago
- 6 days 12 hours ago
- 1 month 3 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago