
category
Azure AI搜索为矢量搜索和混合搜索提供矢量存储和配置。支持是在字段级别实现的,这意味着您可以在同一搜索语料库中组合向量字段和非向量字段。
矢量存储在搜索索引中。使用创建索引REST API或等效的Azure SDK方法创建向量存储。
矢量存储的注意事项包括以下几点:
- 根据预期的矢量检索模式,设计一个适合您的用例的模式。
- 估计索引大小并检查搜索服务容量。
- 管理矢量存储
- 保护矢量存储
矢量检索模式
在Azure人工智能搜索中,有两种处理搜索结果的模式。
- 生成搜索。语言模型使用Azure人工智能搜索的数据来制定对用户查询的响应。此模式包括一个协调提示和维护上下文的编排层。在这种模式中,搜索结果被送入到提示流中,由GPT和Text Davinci等聊天模型接收。这种方法基于检索增强生成(RAG)架构,其中搜索索引提供基础数据。
- 使用搜索栏、查询输入字符串和呈现结果的经典搜索。搜索引擎接受并执行矢量查询,制定响应,然后在客户端应用程序中呈现这些结果。在Azure AI搜索中,结果以扁平行集的形式返回,您可以选择包含搜索结果的字段。由于没有聊天模型,预计您将在向量存储(搜索索引)中填充响应中可读的非向量内容。尽管搜索引擎在矢量上匹配,但应该使用非矢量值来填充搜索结果。矢量查询和混合查询涵盖了可以为经典搜索场景制定的查询请求类型。
您的索引模式应该反映您的主要用例。以下部分重点介绍了为生成人工智能或经典搜索构建的解决方案在字段组成方面的差异。
矢量存储的模式
矢量存储的索引模式需要名称、键字段(字符串)、一个或多个矢量字段和矢量配置。建议将非矢量字段用于混合查询,或用于返回不必经过语言模型的逐字可读的人类内容。有关矢量配置的说明,请参见创建矢量存储。
基本矢量场配置
矢量场通过其数据类型和矢量特定属性来区分。以下是字段集合中向量字段的样子:
JSON
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
矢量字段的类型为Collection(Edm.Single)。
向量字段必须是可搜索和可检索的,但它们不能是可过滤的、面向表的或可排序的,也不能具有分析器、规范化器或同义词映射分配。
矢量字段的维数必须设置为嵌入模型生成的嵌入数。例如,text-embedding-ada-002为每个文本块生成1536个嵌入。
使用矢量搜索简档指示的算法对矢量字段进行索引,该矢量搜索简表在索引的其他地方定义,因此在示例中未示出。有关更多信息,请参阅矢量搜索配置。
基本矢量工作负载的字段集合
除了矢量场之外,矢量存储还需要更多的场。例如,关键字字段(本例中为“id”)是索引要求。
JSON
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true,
"retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true,
"retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true,
"analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true,
"retrievable": true, "sortable": true, "facetable": true }
]
其他字段,如“content”字段,提供了“content_vector”字段的可读等效项。如果你只使用语言模型来制定响应,你可以省略非向量内容字段,但将搜索结果直接推送到客户端应用程序的解决方案应该包含非向量内容。
元数据字段对于筛选器非常有用,尤其是当元数据包括有关源文档的原始信息时。不能直接对矢量字段进行筛选,但可以设置前置或后置筛选模式,以便在矢量查询执行之前或之后进行筛选。
导入和向量化数据向导生成的架构
我们建议使用导入和向量化数据向导进行评估和概念验证测试。向导在本节中生成示例架构。
这种模式的偏见在于,搜索文档是围绕数据块构建的。如果一个语言模型制定了响应,就像RAG应用程序的典型情况一样,那么你需要一个围绕数据块设计的模式。
数据分块对于保持在语言模型的输入限制内是必要的,但当查询可以与从多个父文档中提取的较小内容块相匹配时,它也提高了相似性搜索的精度。最后,如果您使用的是语义排序,则语义排序器也有令牌限制,如果数据分块是您方法的一部分,则更容易满足这些限制。
在下面的示例中,对于每个搜索文档,都有一个chunk ID、chunk、title和vector字段。chunkID和父ID由向导填充,使用blob元数据(路径)的base64编码。块和标题是从blob内容和blob名称派生而来的。只有矢量场是完全生成的。它是chunk字段的矢量化版本。嵌入是通过调用您提供的Azure OpenAI嵌入模型生成的。
JSON
"name": "example-index-from-import-wizard",
"fields": [
{"name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true,
"filterable": true,
"retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true,
"filterable": true,
"retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true,
"filterable": false,
"retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true,
"filterable": true,
"retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true,
"retrievable": true,
"dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
RAG和聊天风格应用程序的架构
如果您正在为生成式搜索设计存储,则可以为索引和向量化的静态内容创建单独的索引,并为可在提示流中使用的对话创建第二个索引。以下索引是通过与数据解决方案加速器的聊天创建的。
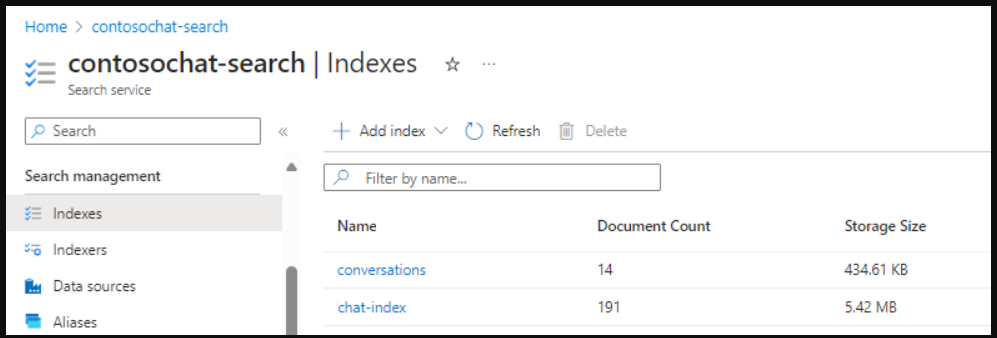
聊天索引中支持生成搜索体验的字段:
JSON
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true,
"retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false,
"retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true,
"retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false,
"retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true,
"retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true,
"retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true,
"retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true,
"retrievable": true }
]
对话索引中支持编排和聊天历史记录的字段:
JSON
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true,
"retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true,
"retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false,
"retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true,
"retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false,
"retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true,
"retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true,
"retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false,
"filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false,
"filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false,
"filterable": true, "retrievable": true }
]
这是一张屏幕截图,显示了搜索资源管理器中对话索引的搜索结果。搜索得分为1.00,因为搜索不合格。请注意为支持编排和提示流而存在的字段。会话ID标识特定聊天。“类型”表示内容是来自用户还是来自助手。日期用于从历史记录中删除聊天记录。
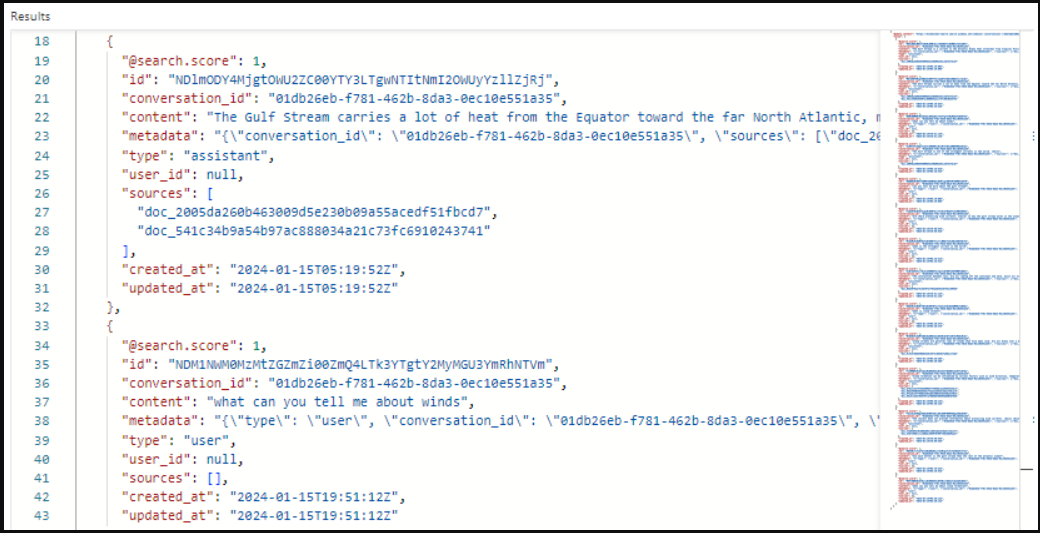
搜索浏览器的屏幕截图,其中包含为RAG应用程序设计的索引结果。
物理结构和尺寸
在Azure AI搜索中,索引的物理结构在很大程度上是一种内部实现。您可以访问其架构、加载和查询其内容、监视其大小和管理容量,但集群本身(反向索引和矢量索引)以及其他文件和文件夹)由Microsoft内部管理。
指数的大小和实质由以下因素决定:
- 文件的数量和组成
- 各个字段的属性。例如,可筛选字段需要更多的存储空间。
- 索引配置,包括矢量配置,该配置指定如何根据选择HNSW还是穷举KNN进行相似性搜索来创建内部导航结构。
Azure AI搜索对矢量存储进行了限制,这有助于为所有工作负载维护一个平衡稳定的系统。为了帮助您控制限制,在Azure门户中单独跟踪和报告向量使用情况,并通过服务和索引统计信息以编程方式进行跟踪和报告。
下面的屏幕截图显示了配置有一个分区和一个副本的S1服务。这个特定的服务有24个小索引,平均有一个向量字段,每个字段由1536个嵌入组成。第二个图块显示矢量索引的配额和使用情况。矢量索引是为每个矢量字段创建的内部数据结构。因此,矢量索引的存储总是索引总体使用的存储的一小部分。其他非向量字段和数据结构消耗其余部分。
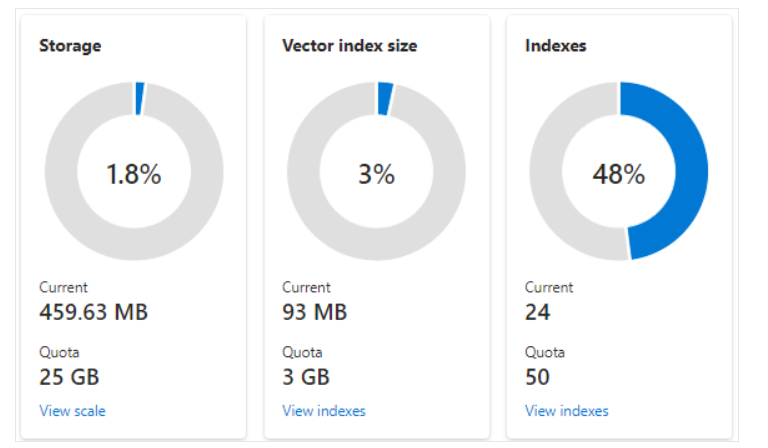
使用分片的屏幕截图,显示存储、矢量索引和索引计数。
矢量索引的限制和估计在另一篇文章中有所介绍,但需要提前强调的两点是,最大存储量因服务层以及创建搜索服务的时间而异。较新的同层服务具有更大的矢量索引容量。出于这些原因,请采取以下行动:
- 请检查搜索服务的部署日期。如果它是在2024年4月3日之前创建的,请考虑创建一个新的搜索服务以获得更大的容量。
- 如果您预计矢量存储需求会出现波动,请选择可扩展的层。基本层固定在旧搜索服务的一个分区上。考虑标准1(S1)及更高版本以获得更大的灵活性和更快的性能,或者创建一个新的搜索服务,在每个nillable层使用更高的限制和更多的分区。
基本操作和交互
本节介绍矢量运行时操作,包括连接到单个索引并确保其安全。
笔记
管理索引时,请注意,没有门户或API支持移动或复制索引。相反,客户通常会将其应用程序部署解决方案指向不
同的搜索服务(如果使用相同的索引名称),或者修改名称以在当前搜索服务上创建一个副本,然后构建它。持续可用
一旦第一个文档被索引,索引就可以立即用于查询,但在所有文档都被索引之前,索引不会完全可用。在内部,索引分布在分区之间,并在副本上执行。物理索引由内部管理。逻辑索引由您管理。
索引是连续可用的,不能暂停或使其脱机。因为它是为连续操作而设计的,所以对其内容的任何更新或对索引本身的添加都是实时发生的。因此,如果请求与文档更新一致,查询可能会暂时返回不完整的结果。
请注意,对于文档操作(刷新或删除)以及不影响当前索引的现有结构和完整性的修改(如添加新字段),都存在查询连续性。如果需要进行结构更新(更改现有字段),通常会在开发环境中使用拖放和重建工作流进行管理,或者通过在生产服务上创建新版本的索引来进行管理。
为了避免索引重建,一些进行小更改的客户选择通过创建一个与以前版本共存的新字段来“版本化”字段。随着时间的推移,这会导致以过时字段或过时的自定义分析器定义形式出现的孤立内容,尤其是在复制成本高昂的生产索引中。作为索引生命周期管理的一部分,您可以在计划的索引更新中解决这些问题。
端点连接
所有矢量索引和查询请求都以索引为目标。端点通常是以下其中一种:
| Endpoint | Connection and access control |
|---|---|
<your-service>.search.windows.net/indexes |
Targets the indexes collection. Used when creating, listing, or deleting an index. Admin rights are required for these operations, available through admin API keys or a Search Contributor role. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Targets the documents collection of a single index. Used when querying an index or data refresh. For queries, read rights are sufficient, and available through query API keys or a data reader role. For data refresh, admin rights are required. |
如何连接到Azure AI搜索
请确保您有权限或API访问密钥。除非您在查询现有索引,否则您需要管理员权限或贡献者角色分配来管理和查看搜索服务上的内容。- 从Azure门户开始。创建搜索服务的人员可以查看和管理搜索服务,包括通过访问控制(IAM)页面授予他人访问权限。
- 转到其他客户端进行编程访问。我们建议第一步使用快速启动和示例:
对矢量数据的安全访问
Azure AI Search实现了数据加密、无互联网场景下的私人连接以及通过Microsoft Entra ID进行安全访问的角色分配。Azure AI Search中的安全功能概述了所有企业安全功能。
管理矢量存储
Azure提供了一个监控平台,其中包括诊断日志记录和警报。我们建议采用以下最佳做法:
- 启用诊断日志记录
- 设置警报
- 分析查询和索引性能
另请参阅
- 登录 发表评论
- 70 次浏览
Tags
最新内容
- 5 days 10 hours ago
- 1 week 2 days ago
- 1 month 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago