
spaCy支持许多转移和多任务学习工作流,这些工作流通常有助于提高管道的效率或准确性。迁移学习指的是单词向量表和语言模型预训练等技术。这些技术可以用于将原始文本中的知识导入到您的管道中,以便您的模型能够更好地从带注释的示例中进行概括。
你可以从FastText和Gensim等流行工具转换单词向量,或者如果你安装了spacy transformer,你可以加载到任何预先训练的transformer模型中。您也可以通过spacy pretrain命令进行自己的语言模型预训练。您甚至可以在多个组件之间共享转换器或其他上下文嵌入模型,这可以使长管道的效率提高数倍。要使用迁移学习,你需要至少几个带注释的例子来说明你试图预测的内容。否则,您可以尝试使用向量和相似性的“一次性学习”方法。
单词向量和语言模型之间有什么区别?
transformer是一种大型强大的神经网络,可以为您提供更好的准确性,但更难在生产中部署,因为它们需要GPU才能有效运行。单词向量是一种稍老的技术,它可以使模型的准确性得到较小的提高,还可以提供一些额外的功能。
单词向量和上下文语言模型(如transformer)之间的关键区别在于,单词向量建模的是词汇类型,而不是标记。如果你有一个没有上下文的术语列表,像BERT这样的转换器模型并不能真正帮助你。BERT旨在理解上下文中的语言,而上下文并不是你所拥有的。单词向量表将更适合您的任务。然而,如果你在上下文中确实有单词——整个句子或正在运行的文本的段落——单词向量只能提供文本内容的非常粗略的近似值。
单词向量在计算上也是非常高效的,因为它们通过单个索引操作将单词映射到向量。因此,单词向量作为提高神经网络模型准确性的一种方法是有用的,尤其是那些较小或很少或没有经过预训练的模型。在spaCy中,单词向量表仅用作静态特征。spaCy不向预训练的字向量表反向传播梯度。静态向量表通常与较小的学习任务特定嵌入表结合使用。
我什么时候应该将单词向量添加到我的模型中?
单词向量与大多数转换器模型不兼容,但如果你正在训练另一种类型的NLP网络,那么在你的模型中添加单词向量几乎总是值得的。除了提高你的最终准确性外,单词向量通常会使实验更加一致,因为你达到的准确性对网络如何随机初始化不太敏感。随机机会导致的高方差会显著减慢你的进度,因为你需要进行许多实验来从噪声中过滤信号。
单词向量功能需要在训练前启用,并且在运行时也需要提供相同的单词向量表。一旦模型已经训练好,就无法添加单词向量特征,而且通常无法在不造成显著性能损失的情况下用另一个单词向量表替换一个单词矢量表。
共享嵌入层
spaCy允许您在多个组件之间共享单个转换器或其他令牌到向量(“tok2vec”)嵌入层。您甚至可以更新共享层,执行多任务学习。在组件之间重用tok2vec层可以使管道运行得更快,并产生更小的模型。然而,它可能会降低管道的模块化程度,并使交换组件或重新培训管道部件变得更加困难。多任务学习会影响你的准确性(无论是积极的还是消极的),并且可能需要重新调整你的超参数。

| SHARED | INDEPENDENT |
|---|---|
| smaller: models only need to include a single copy of the embeddings | larger: models need to include the embeddings for each component |
| faster: embed the documents once for your whole pipeline | slower: rerun the embedding for each component |
| less composable: all components require the same embedding component in the pipeline | modular: components can be moved and swapped freely |
通过在管道起点附近添加一个transformer或tok2vec组件,您可以在多个组件之间共享单个transformer或其他tok2vec模型。管道中稍后的组件可以通过在其模型中包含像Tok2VecListener这样的侦听器层来“连接”到它。
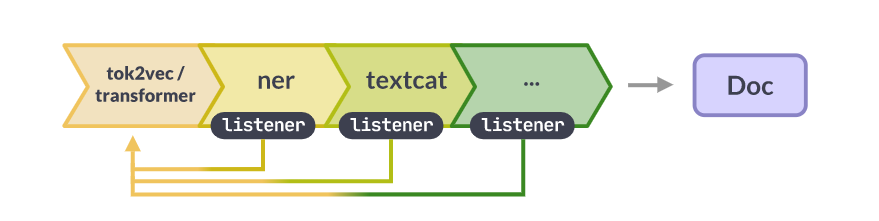
在培训开始时,Tok2Vec组件将获取对管道其余部分中相关侦听器层的引用。当它处理一批文档时,它会将其预测转发给侦听器,从而允许侦听器在最终调用预测时重用这些预测。类似的机制用于将梯度从侦听器传递回模型。Transformer组件和TransformerListener层对Transformer模型执行相同的操作,但Transformer组件也会将Transformer输出保存到Doc._中。trf_data扩展属性,使您能够在管道运行完成后访问它们。
示例:共享配置与独立配置
配置系统允许您表达共享嵌入层和独立嵌入层的模型配置。共享设置使用一个具有Tok2Vec架构的Tok2Vec组件。所有其他组件,如实体识别器,都使用Tok2VecListener层作为其模型的tok2vec参数,该参数连接到tok2vec组件模型。
SHARED [components.tok2vec] factory = "tok2vec" [components.tok2vec.model] @architectures = "spacy.Tok2Vec.v2" [components.tok2vec.model.embed] @architectures = "spacy.MultiHashEmbed.v2" [components.tok2vec.model.encode] @architectures = "spacy.MaxoutWindowEncoder.v2" [components.ner] factory = "ner" [components.ner.model] @architectures = "spacy.TransitionBasedParser.v1" [components.ner.model.tok2vec] @architectures = "spacy.Tok2VecListener.v1"
在独立设置中,实体识别器组件定义自己的Tok2Vec实例。其他组件也会这样做。这使得它们完全独立,并且不需要在管道中存在上游Tok2Vec组件。
INDEPENDENT [components.ner] factory = "ner" [components.ner.model] @architectures = "spacy.TransitionBasedParser.v1" [components.ner.model.tok2vec] @architectures = "spacy.Tok2Vec.v2" [components.ner.model.tok2vec.embed] @architectures = "spacy.MultiHashEmbed.v2" [components.ner.model.tok2vec.encode] @architectures = "spacy.MaxoutWindowEncoder.v2"
使用变型器模型
Transformers是一个神经网络体系结构家族,用于计算文档中标记的密集、上下文敏感的表示。然后,管道中的下游模型可以使用这些表示作为输入特征来改进其预测。您可以将多个组件连接到单个转换器模型,其中任何或所有组件都会向转换器提供反馈,以根据您的任务对其进行微调。spaCy的transformer支持与PyTorch和HuggingFace transformer库互操作,使您可以访问数千个预训练的管道模型。变压器模型有很多很好的指南,但出于实际目的,您可以简单地将其视为替代品,让您获得更高的准确性,以换取更高的培训和运行成本。
设置和安装
系统要求
我们建议使用至少具有10GB内存的NVIDIA GPU,以便与变压器型号配合使用。确保你的GPU驱动程序是最新的,并且你已经安装了CUDA v9+。
具体要求取决于变压器型号。在没有GPU的情况下训练基于转换器的模型对于大多数实际目的来说太慢了。
配置一台新机器需要下载大约5GB的数据:3GB CUDA运行时、800MB PyTorch、400MB CuPy、500MB权重、200MB spaCy和依赖项。
一旦安装了CUDA,我们建议您按照包管理器和CUDA版本的PyTorch安装指南安装PyTorch。如果您跳过这一步,pip将在下面作为依赖项安装PyTorch,但它可能找不到适合您安装的最佳版本。
EXAMPLE: INSTALL PYTORCH 1.11.0 FOR CUDA 11.3 WITH PIP# See: https://pytorch.org/get-started/locally/pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
接下来,安装spaCy和您的CUDA版本和变压器的额外功能。CUDA extra(例如,cuda102、cuda113)安装了cupy的正确版本,它与numpy一样,但适用于GPU。如果CUDA运行时安装在非标准位置,则可能还需要设置CUDA_PATH环境变量。综合来看,如果您在/opt/nvidia/CUDA中安装了CUDA 11.3,您将运行:
INSTALLATION WITH CUDA
export CUDA_PATH="/opt/nvidia/cuda" pip install -U spacy[cuda113,transformers]
pip install -U spacy[cuda113,transformers]对于变压器v4.0.0+和需要PencePiece的型号(例如,ALBERT、CamemBERT、XLNet、Marian和T5),安装以下附加依赖项:
INSTALL SENTENCEPIECE
pip install transformers[sentencepiece]
运行时使用
Transformer模型可以用作其他类型神经网络的替代品,因此您的spaCy管道可以以用户完全不可见的方式包含它们。用户将以标准方式下载、加载和使用该模型,就像任何其他spaCy管道一样。您也可以通过Transformer管道组件使用它们,而不是直接将Transformer用作子网络。
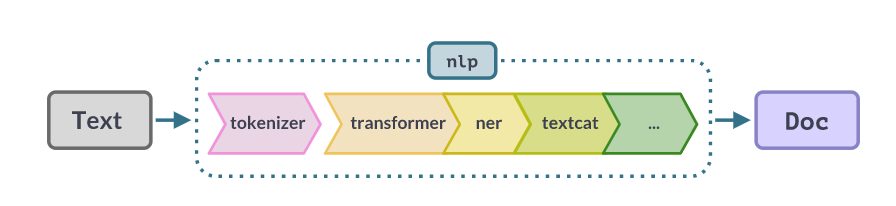
Transformer组件设置文档。trf_data扩展属性,使您可以在运行时访问transformer输出。spaCy提供的经过训练的基于变压器的管道在_trf上结束,例如en_core_web_trf。
python -m spacy download en_core_web_trf
EXAMPLE
import spacy
from thinc.api import set_gpu_allocator, require_gpu
# Use the GPU, with memory allocations directed via PyTorch.
# This prevents out-of-memory errors that would otherwise occur from competing
# memory pools.
set_gpu_allocator("pytorch")
require_gpu(0)
nlp = spacy.load("en_core_web_trf")
for doc in nlp.pipe(["some text", "some other text"]):
tokvecs = doc._.trf_data.tensors[-1]您还可以通过指定自定义的set_extra_annotations函数来自定义Transformer组件在文档上设置注释的方式。这个回调将与整个批次的原始输入和输出数据以及一批Doc对象一起调用,允许您实现所需的任何内容。使用一批Doc对象和包含该批转换器数据的FullTransformerBatch调用注释setter。
def custom_annotation_setter(docs, trf_data):
doc_data = list(trf_data.doc_data)
for doc, data in zip(docs, doc_data):
doc._.custom_attr = data
nlp = spacy.load("en_core_web_trf")
nlp.get_pipe("transformer").set_extra_annotations = custom_annotation_setter
doc = nlp("This is a text")
assert isinstance(doc._.custom_attr, TransformerData)
print(doc._.custom_attr.tensors)培训使用情况
建议的培训工作流程是使用spaCy的配置系统,通常通过spaCy-train命令。训练配置在一个地方定义了所有组件设置和超参数,并允许您通过引用创建函数(包括您自己注册的函数)来描述对象树。有关如何开始训练自己的模特的详细信息,请查看训练快速入门。
config.cfg中的[components]部分描述了管道组件和用于构建它们的设置,包括它们的模型实现。以下是Transformer组件的配置片段,以及匹配的Python代码。在这种情况下,[components.transformer]块描述了变压器组件:
CONFIG.CFG
[components.transformer]
factory = "transformer"
max_batch_items = 4096
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
name = "bert-base-cased"
tokenizer_config = {"use_fast": true}
[components.transformer.model.get_spans]
@span_getters = "spacy-transformers.doc_spans.v1"
[components.transformer.set_extra_annotations]
@annotation_setters = "spacy-transformers.null_annotation_setter.v1"[components.transformer.model]块描述传递给transformer组件的模型参数。它是一个将被传递到组件中的ThincModel对象。在这里,它引用了在体系结构注册表中注册的函数spacy-transformers.TransformerModel.v3。如果块中的键以@开头,那么它将被解析为一个函数,所有其他设置都将作为参数传递给该函数。在本例中,使用name、tokenizer_config和get_span。
get_Span是一个函数,它接受一批Doc对象,并返回可能重叠的Span对象列表,由转换器处理。有几个内置功能可用,例如,处理整个文档或单个句子。解析配置后,将创建函数并将其作为参数传递到模型中。
name值是任何HuggingFace模型的名称,该模型将在第一次使用时自动下载。您也可以使用本地文件路径。有关完整的详细信息,请参阅TransformerModel文档。
支持各种各样的PyTorch模型,但有些可能不起作用。如果一个模型似乎不起作用,请随意打开一个问题。此外,请注意,spaCy中加载的Transformers只能用于张量,并且预训练的任务专用头或文本生成功能不能用作transformer管道组件的一部分。
请记住,用于训练的config.cfg不应包含丢失的值,并且需要定义所有设置。你不希望任何隐藏的默认值悄悄出现并改变你的结果!spaCy会告诉您是否缺少设置,您可以运行spaCy-init-fill-config来自动填充所有默认值。
自定义设置
要更改任何设置,您可以编辑config.cfg并重新运行培训。要更改任何函数,如span getter,您可以替换引用函数的名称,例如@span_getters=“spacytransformers.sent_spans.v1”来处理语句。您也可以使用span_getters注册表注册自己的函数。例如,以下自定义函数返回句子边界后的Span对象,除非一个句子后面有一定数量的标记,在这种情况下,最多返回max_length标记的子内容。
import spacy_transformers
@spacy_transformers.registry.span_getters("custom_sent_spans")
def configure_custom_sent_spans(max_length: int):
def get_custom_sent_spans(docs):
spans = []
for doc in docs:
spans.append([])
for sent in doc.sents:
start = 0
end = max_length
while end <= len(sent):
spans[-1].append(sent[start:end])
start += max_length
end += max_length
if start < len(sent):
spans[-1].append(sent[start:len(sent)])
return spans
return get_custom_sent_spans要在训练期间解决配置问题,spaCy需要了解您的自定义函数。您可以通过--code参数使其可用,该参数可以指向Python文件。有关使用自定义代码进行培训的更多详细信息,请参阅培训文档。
python -m spacy train ./config.cfg --code ./code.py
自定义模型实现
Transformer组件希望传入一个Thinc Model对象作为其模型参数。您并不局限于spacy transformers提供的实现——唯一的要求是您注册的函数必须返回Model[List[Doc],FullTransformerBatch]类型的对象:也就是说,一个Thinc模型,它接受Doc对象的列表,并返回带有transformer数据的FullTransformerBatch对象。
同样的想法也适用于为下游组件提供动力的任务模型。spaCy的大多数内置模型创建函数都支持tok2vec参数,该参数应该是model[List[Doc]、List[Floats2d]]类型的Thinc层。这就是我们将使用TransformerListener层插入transformer模型的地方,该层偷偷地委托给transformer管道组件。
CONFIG.CFG (EXCERPT) [components.ner] factory = "ner" [nlp.pipeline.ner.model] @architectures = "spacy.TransitionBasedParser.v1" state_type = "ner" extra_state_tokens = false hidden_width = 128 maxout_pieces = 3 use_upper = false [nlp.pipeline.ner.model.tok2vec] @architectures = "spacy-transformers.TransformerListener.v1" grad_factor = 1.0 [nlp.pipeline.ner.model.tok2vec.pooling] @layers = "reduce_mean.v1"
TransformerListener层需要一个池化层作为参数池,该池化层的类型需要为Model[Ragged,Floats2d]。该层确定如何根据标记对齐的零个或多个源行计算每个spaCy标记的向量。这里我们使用reduce_ma均值层,它对单词行进行平均。我们可以使用reduce_max,或者您自己编写的自定义函数。
你可以让多个组件都监听同一个转换器模型,并将所有渐变返回给它。默认情况下,所有渐变都将被同等加权。您可以通过grad_factor设置来控制这一点,该设置允许您重新调整来自不同侦听器的渐变。例如,设置grad_factor=0将禁用其中一个侦听器的渐变,而grad_factol=2.0将它们乘以2。这类似于每个组件都有一个自定义的学习率。您还可以提供一个时间表,让您在训练开始时冻结共享参数,而不是常数。
静态矢量
如果你的管道包括一个单词向量表,你将能够在Doc、Span、Token和Lexeme对象上使用.ssimilarity()方法。您还可以使用.vvector属性访问向量,或者直接使用Vocab对象查找一个或多个向量。带有单词向量的管道也可以使用向量作为统计模型的特征,这可以提高组件的准确性。
spaCy中的单词向量是“静态的”,因为它们不是统计模型的学习参数,spaCy本身也没有任何学习单词向量表的算法。您可以使用floret、Gensim、FastText或GloVe等工具来训练单词向量表,或者下载现有的预训练向量。init vectors命令允许您转换向量以与spaCy一起使用,并将为您提供一个可以在训练配置中加载或引用的目录。
📖词向量与相似性
有关将单词向量加载到spaCy、使用它们进行相似性以及通过截断和修剪向量来提高单词向量覆盖率的更多详细信息,请参阅单词向量和相似性的使用指南。
在模型中使用词向量
许多神经网络模型能够使用词向量表作为附加特征,这有时会显著提高准确性。spaCy的内置嵌入层MultiHashEmbed可以配置为使用include_static_vvectors标志使用单词向量表。
[tagger.model.tok2vec.embed] @architectures = "spacy.MultiHashEmbed.v2" width = 128 attrs = ["LOWER","PREFIX","SUFFIX","SHAPE"] rows = [5000,2500,2500,2500] include_static_vectors = true
💡它是如何工作的
配置系统将在体系结构注册表中查找字符串“spacy.MultiHashEmbed.v2”,并使用块中的其余参数调用返回的对象。这将导致对MultiHashEmbed函数的调用,该函数将返回一个具有类型签名model[List[Doc],List[Floats2d]]的Thinc模型对象。因为嵌入层采用Doc对象列表作为输入,所以不需要存储矢量表的副本。向量将通过Doc.vocab.vectors属性从传入的Doc对象中检索。该过程的这一部分由StaticVectors层处理。
创建自定义嵌入层
MultiHashEmbed层是spaCy推荐的为神经网络模型构建初始单词表示的策略,但您也可以实现自己的策略。您可以将任何函数注册为字符串名称,然后在配置中引用该函数(有关更多详细信息,请参阅培训文档)。要尝试这个方法,您可以将以下小示例保存到一个新的Python文件中:
from spacy.ml.staticvectors import StaticVectors
from spacy.util import registry
print("I was imported!")
@registry.architectures("my_example.MyEmbedding.v1")
def MyEmbedding(output_width: int) -> Model[List[Doc], List[Floats2d]]:
print("I was called!")
return StaticVectors(nO=output_width)如果使用--code参数将文件的路径传递给spacy train命令,则文件将被导入,这意味着注册该函数的装饰器将运行。您的函数现在与spaCy的任何内置函数处于同等地位,因此您可以将其放入,而不是使用相同输入和输出签名的任何其他模型。例如,您可以在tagger模型中使用它,如下所示:
[tagger.model.tok2vec.embed] @architectures = "my_example.MyEmbedding.v1" output_width = 128
既然你有了一个连接到网络中的自定义函数,你就可以开始实现你感兴趣的逻辑了。例如,假设你想尝试一种相对简单的嵌入策略,它利用静态单词向量,但通过求和将它们与一个较小的学习嵌入表相结合。
from thinc.api import add, chain, remap_ids, Embed
from spacy.ml.staticvectors import StaticVectors
from spacy.ml.featureextractor import FeatureExtractor
from spacy.util import registry
@registry.architectures("my_example.MyEmbedding.v1")
def MyCustomVectors(
output_width: int,
vector_width: int,
embed_rows: int,
key2row: Dict[int, int]
) -> Model[List[Doc], List[Floats2d]]:
return add(
StaticVectors(nO=output_width),
chain(
FeatureExtractor(["ORTH"]),
remap_ids(key2row),
Embed(nO=output_width, nV=embed_rows)
)
)预训练
spacy pretrain命令允许您使用原始文本中的信息初始化模型。如果不进行预训练,组件的模型通常会被随机初始化。预训练背后的想法很简单:随机可能不是最优的,所以如果我们有一些文本可以学习,我们可能会找到一种方法让模型有一个更好的开始。
预训练使用与常规训练相同的config.cfg文件,这有助于保持设置和超参数的一致性。额外的[预训练]部分有几个配置子部分,这些子部分在训练块中很熟悉:[预训练.批处理程序]、[预训练..优化器]和[预训练.\语料库]都以相同的方式工作,期望使用相同类型的对象,尽管预训练时你的语料库不需要任何注释,所以你通常会使用不同的阅读器,例如JsonlCorpus。
原始文本格式
原始文本可以用spaCy的二进制.spaCy格式提供,该格式由序列化的Doc对象组成,也可以用JSONL(换行符分隔的JSON)提供,每个条目都有一个键“text”。这样可以逐行读取数据,同时还可以在文本中包含换行符。
{"text": "Can I ask where you work now and what you do, and if you enjoy it?"}
{"text": "They may just pull out of the Seattle market completely, at least until they have autonomous vehicles."}
您也可以使用自己的自定义语料库加载程序。
您可以通过在init-config或init-fill-config上设置--pretraining标志,将[pretraining]块添加到您的配置中:
python -m spacy init fill-config config.cfg config_pretrain.cfg --pretraining
然后,您可以使用更新的配置运行spacy预训练,并传入可选的配置覆盖,如原始文本文件的路径:
python -m spacy pretrain config_pretrain.cfg ./output --paths.raw_text text.jsonl
以下默认值用于[pretraining]块,并在使用--pretraining运行init-config或init-fill-config时合并到现有配置中。如果需要,您可以配置设置和超参数或更改目标。
[paths]
raw_text = null
[pretraining]
max_epochs = 1000
dropout = 0.2
n_save_every = null
n_save_epoch = null
component = "tok2vec"
layer = ""
corpus = "corpora.pretrain"
[pretraining.batcher]
@batchers = "spacy.batch_by_words.v1"
size = 3000
discard_oversize = false
tolerance = 0.2
get_length = null
[pretraining.objective]
@architectures = "spacy.PretrainCharacters.v1"
maxout_pieces = 3
hidden_size = 300
n_characters = 4
[pretraining.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = true
eps = 1e-8
learn_rate = 0.001
[corpora]
[corpora.pretrain]
@readers = "spacy.JsonlCorpus.v1"
path = ${paths.raw_text}
min_length = 5
max_length = 500
limit = 0预培训的工作原理
spacy预训练的影响各不相同,但如果你没有使用transformer模型,并且你的训练数据相对较少(例如,少于5000句),通常值得尝试。一个很好的经验法则是,预训练通常会给你带来与在模型中使用单词向量类似的准确性提高。如果单词向量让你的错误减少了10%,那么用spaCy进行预训练可能会让你再减少10%,总共减少20%的错误。
spacy pretrain命令将在您的一个组件中获取一个特定的子网络,并添加额外的层来为临时任务构建一个网络,该任务迫使模型学习一些关于句子结构和单词共现统计的信息。
预训练生成一个二进制权重文件,可以在训练开始时使用配置选项initialize.init _tok2vec重新加载。权重文件指定一组初始权重。然后训练照常进行。
一次只能从管道中预训练一个子网络,并且子网络必须类型为Model[List[Doc],List[Floats2d]](即它必须是“tok2vec”层)。最常见的工作流程是使用Tok2Vec组件为管道的几个组件创建一个共享的令牌到向量层,并对其整个模型应用预训练。
配置预训练
spacy pretraining命令是使用配置文件的[preptraining]部分配置的。组件和层设置告诉spaCy如何找到要预训练的子网络。图层设置应该是空字符串(使用整个模型)或节点引用。spaCy的大多数内置模型架构都有一个名为“tok2vec”的引用,它将引用正确的层。
# 1. Use the whole model of the "tok2vec" component [pretraining] component = "tok2vec" layer = "" # 2. Pretrain the "tok2vec" node of the "textcat" component [pretraining] component = "textcat" layer = "tok2vec"
将预培训与培训联系起来
为了从预训练中受益,您的训练步骤需要知道如何使用从预训练步骤中学习到的权重初始化其tok2vec分量。您可以通过将initialize.init_tok2vec设置为预训练中要使用的.bin文件的文件名来完成此操作。
一个运行了5个时期的预训练步骤,输出路径为pretrain/,例如,从pretrain/model0.bin到pretrain/mmodel4.bin。要使用最终输出,您可以在配置文件中填写此值:
CONFIG.CFG
[paths]
init_tok2vec = "pretrain/model4.bin"
[initialize]
init_tok2vec = ${paths.init_tok2vec}spacy预训练的输出与将进入initialize.vectors的预打包静态字向量的数据格式不同。预训练输出由tok2vec组件在现有管道中应该开始的权重组成,因此它进入initializ.init_tok2vec。
培训前目标
字符目标
[pretraining.objective]
@architectures = "spacy.PretrainCharacters.v1"
maxout_pieces = 3
hidden_size = 300
n_characters = 4
矢量目标
[pretraining.objective]
@architectures = "spacy.PretrainVectors.v1"
maxout_pieces = 3
hidden_size = 300
loss = "cosine"
有两个预训练目标可用,这两个目标都是完形填空任务Devlin等人(2018)为BERT引入的变体。可以通过[预训练.目标]配置块定义和配置目标。
PretrainCharacters:“characters”目标要求模型预测单词的前导和尾随UTF-8字节数。例如,设置n_characters=2,模型将尝试预测单词的前两个和最后两个字符。
预训练向量:“向量”目标要求模型从静态嵌入表中预测单词的向量。这需要对单词向量模型进行训练和加载。矢量目标可以优化余弦或L2损失。我们通常发现余弦损失表现更好。
这些预训练目标使用了一种技巧,我们称之为具有近似输出的语言建模(LMAO)。这个技巧的动机是预测一个确切的单词ID会带来很多偶然的复杂性。您需要一个大的输出层,即使这样,词汇表也太大,这会导致标记化方案与实际单词边界不一致。在训练结束时,输出层无论如何都会被丢弃:我们只想要一个任务,迫使网络对单词共现统计数据进行建模。预测前导字符和尾随字符可以充分做到这一点,因为如果准确地预测首字母和尾随字符,则可以高精度地恢复准确的单词序列。以向量为目标,预训练使用通过GloVe或Word2vec等算法学习的嵌入空间,使模型能够专注于我们实际关心的上下文建模。
最新内容
- 6 days 12 hours ago
- 2 weeks ago
- 2 weeks 4 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago