
作为一个完整的开源大数据套件,Apache Hadoop在过去十年中深刻影响了整个大数据世界。然而,随着各种新兴技术的发展,Hadoop生态系统发生了巨大的变化。Hadoop真的死了吗?如果是,哪些产品/技术将取代它?大数据分析的未来前景如何?
本文将分析:
1.Hadoop的历史及其开源生态系统
2.云原生趋势下的新兴技术选择
3.未来10年大数据分析的未来展望
理解Hadoop:大数据简史及其作用
在过去的二十年里,我们一直生活在一个数据爆炸的时代。订单和仓储等传统业务中创建的数据量增长相对缓慢,在数据总量中的比例逐渐下降。

相反,大量的人类数据和机器数据(日志、物联网设备等)被收集和存储的数量远远超过了传统的商业数据。海量数据与人类能力之间存在着巨大的技术差距,催生了各种大数据技术。在这种背景下,我们所说的大数据时代已经形成。
2006年:Apache Hadoop在大数据处理领域的崛起
得益于“大数据”和有影响力的Apache开源软件项目社区,Hadoop迅速流行起来,并涌现出许多商业公司。
Hadoop就是这样一个功能齐全的大数据处理平台。它包含各种组件,以满足不同的功能要求,例如:
- 用于数据存储的HDFS
- 资源管理Yarn
- MapReduce和Spark用于数据计算和处理
- 用于关系数据收集的Sqoop
- 实时数据管道的Kafka
- 用于在线数据存储和访问的HBase
- 用于在线特别查询等的Impala。
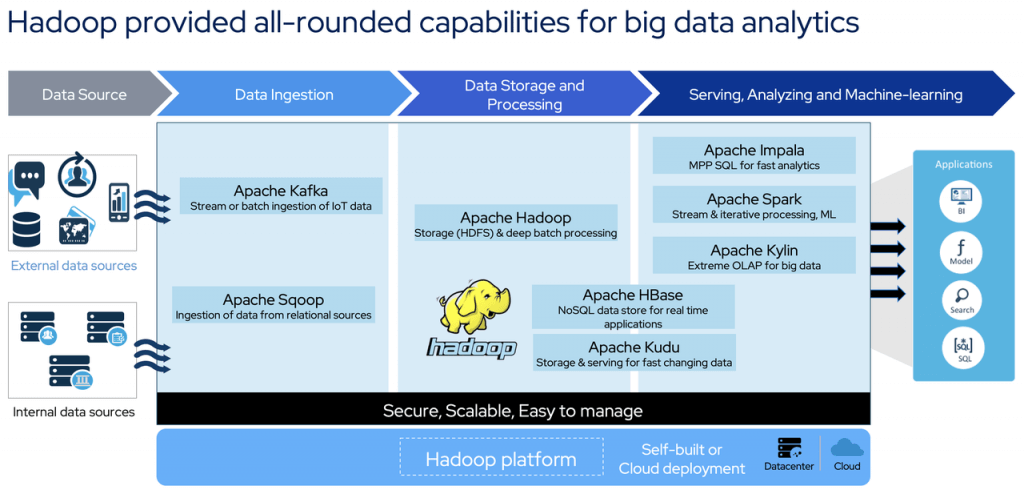
Hadoop在诞生后不久就使用集群进行并行计算,打破了超级计算机保持的排序记录。它已被实力雄厚的公司和各种组织广泛采用。
市场上排名靠前的Hadoop分销商包括Cloudera、Hortonworks和MapR这三家供应商。此外,公共云供应商还在云上提供托管Hadoop服务,如AWS EMR、Azure HDinsight等,这些服务占据了Hadoop的大部分市场份额。
2018年:随着Cloudera和Hortonworks的合并,市场发生了变化
然而,在2018年,市场经历了剧烈的变化。一则震惊Hadoop生态系统的重大消息:Cloudera和Hortonworks合并。

Chirs Preinenerger和Daniel Newman的新闻
换句话说№1和№2 两个市场参与者相互拥抱以在市场中生存。随后,HPE宣布收购MapR。这些并购表明,尽管Hadoop非常受欢迎,但这些公司在运营中面临困难,很难赚钱。
在合并Hortonworks后,Cloudera宣布将对所有产品线收费,包括以前的开源版本。开源产品不再对所有用户开放,而是只对付费用户开放。

HDP发行版过去是免费的,现在不再维护和下载。它将来将合并为一个统一的CDP平台。
2021:观察Hadoop开源生态系统的衰落
2021年4月,Apache软件基金会宣布13个大数据相关项目退役,其中10个是Hadoop生态系统的一部分,如Eagle、Sentry、Tajo等。
现在,肩负着管理Hadoop集群使命的Apache Ambari成为2022年退役的第一个Apache项目。
2022年及以后:展望大数据的后Hadoop时代
Hadoop最终会被抛弃吗?我相信这不会很快发生。毕竟,Hadoop拥有大量用户,这意味着平台和应用程序迁移的成本过高。
因此,当前用户将继续使用它,但新用户的数量将逐渐减少。这就是我们所说的“后Hadoop时代”。
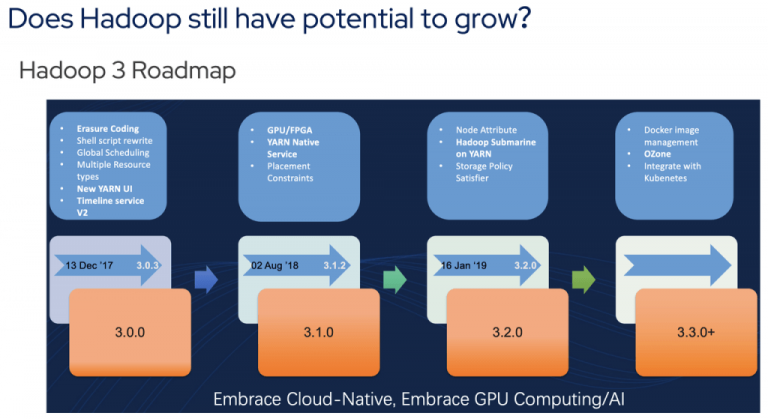
就Apache Hadoop的潜在增长而言,上述路线图取自Hadoop社区的一次会议。3.0之后,Hadoop的新特性显然不再那么好了。它们主要是关于与K8s和Docker的集成,这对大数据从业者来说没有那么大的吸引力。
是什么导致了Hadoop的衰落?
谷歌趋势显示,2014年至2017年,人们对Hadoop的兴趣达到了顶峰。在那之后,我们看到Hadoop的搜索量明显下降。Hadoop逐渐失去光环也就不足为奇了。任何技术都会经历发展、成熟和衰落的循环,任何技术都无法逃脱客观规律。
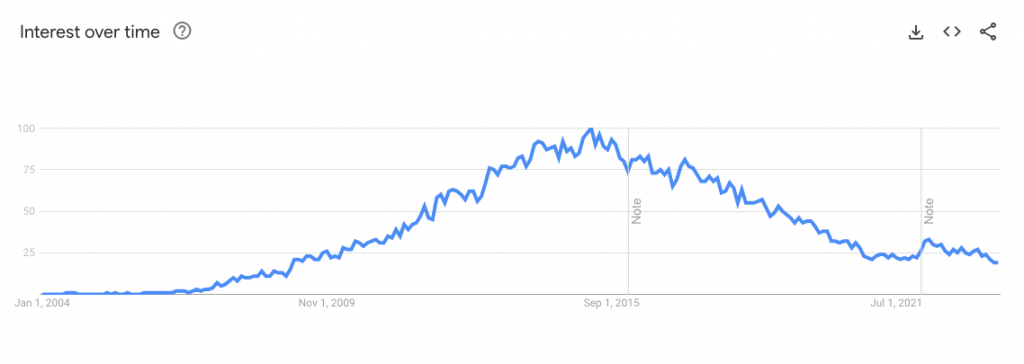
从Apache Hadoop及其生态系统的现状来看,有几个关键因素表明它最终会消亡。
数据分析和新兴技术的新市场需求
回顾Hadoop的发展历史,可以看出,软件框架的出现是因为对大数据存储的强烈需求。然而,在今天,用户对数据管理和分析有了新的需求,例如在线快速分析、存储和计算分离,或用于人工智能和机器学习的AI/ML。
在这些方面,Hadoop只能提供有限的支持。在这方面,它不能与一些新兴技术相比。比如Redis、Elastisearch、ClickHouse,这些都可以应用到大数据分析中。
对于客户来说,如果一项技术能够满足他们的需求,就不需要部署复杂的Hadoop平台。
快速增长的云供应商和服务对Hadoop相关性的影响
从另一个角度来看,云计算在过去十多年中发展迅速,不仅击败了IBM、HP等传统软件供应商,而且在一定程度上侵占了Hadoop的大数据市场。
早期,云供应商只在IaaS上部署Hadoop,例如AWS EMR(号称是世界上部署最多的Hadoop集群)。对于用户来说,云上托管的Hadoop服务可以随时启动和停止,数据可以在云供应商的数据服务平台上安全备份,使用方便,节省成本。
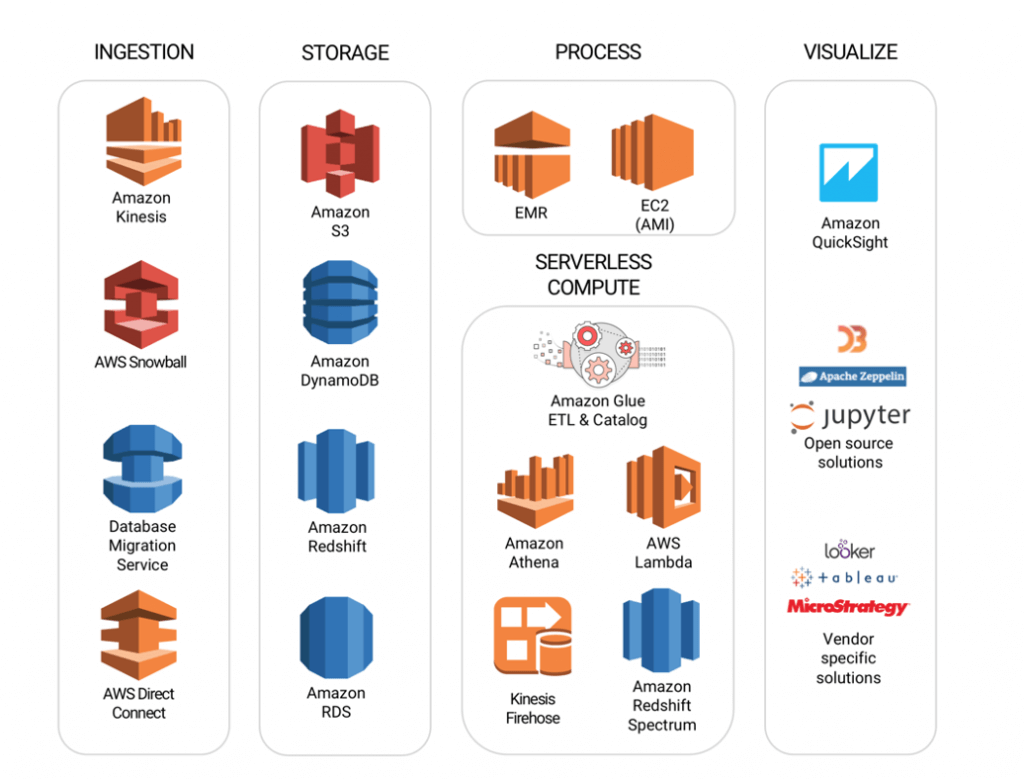
此外,云供应商为特定场景提供了一系列大数据服务,以形成一个完整的生态系统,如AWS S3实现的持久且低成本的数据存储、KV数据存储,以及Amazon DynamoDB实现的低延迟访问、分析大数据的无服务器查询服务Athena等。
检查Hadoop生态系统日益复杂的情况
除了不断提供新服务的新兴技术和云供应商,Hadoop本身也逐渐表现出“疲劳”。积木是一个不错的选择。然而,这增加了用户使用Hadoop生态系统组件的难度。
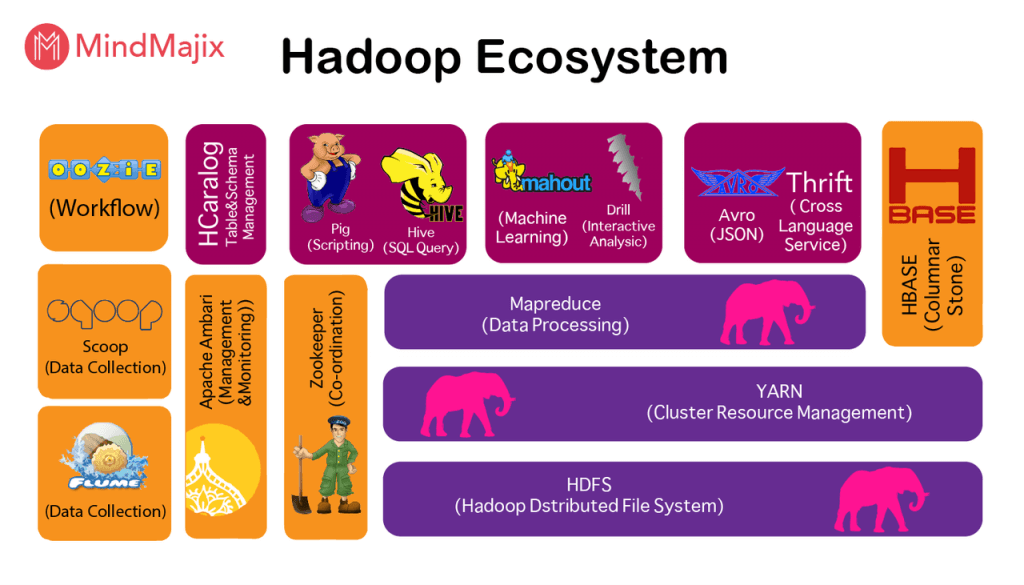
从上图中可以看出,Hadoop中已经有13个(如果不是更多的话)常用组件,这对Hadoop用户的学习和运维构成了巨大的挑战。
Cloudera和Hortonworks战略对Hadoop流行的影响

技术供应商Cloudera/Holtonworks无法在市场上发布高质量的免费产品。事实证明,他们早期的“免费版+付费版”双管齐下的方法行不通。Cloudera未来将只提供付费版的CDP,这标志着免费午餐的结束。目前还不知道其他制造商是否愿意提供免费产品。即使有这样一家制造商,其产品的稳定性和先进性仍然未知。毕竟,Hadoop的核心开发人员大多在Cloudera和Hortonworks工作。
Hadoop开源生态系统的不一致性分析
不要忘记Hadoop是Apache基金会托管的一个开源项目。Apache是为公共利益而设计的,公众可以免费获得、使用和分发。因此,如果你不想为此付费,有一个名为ApacheHadoop的选项可以免费使用。毕竟,大量的互联网公司仍然使用Apache Hadoop(按照他们的规模,只能使用开源版本)。如果他们可以,为什么我不能?
然而,开源软件质量一般,没有服务,也没有SLA保证。用户只能自己发现并解决问题。他们必须在社区中发布问题并等待结果。如果你对此没意见,那就雇佣几个工程师来尝试一下。顺便说一句,Hadoop开发或运维工程师很难雇佣,而且成本高昂。
超越Hadoop:探索大数据的替代解决方案
在后Hadoop时代,用户应该如何面对转型,他们可以选择什么?这完全取决于你有多少预算和你的技术能力。
后Hadoop市场技术供应商的关键成功因素
Hadoop生态系统中的供应商应该如何应对新时代?Apache Kylin和Kyligence的进化史就是一个很好的例子。
ApacheKylin项目和Kyligence都诞生于Hadoop时代。最初,所有Kyligence产品都运行在Hadoop上。大约4年前,Kyligence预见到客户需求正在慢慢转向云原生以及存储和计算的分离。
看到了这样的行业趋势,Kyligence对其原有的平台系统进行了大规模的改造。

2019年,Kyligence推出了Kyligence Cloud,并宣布脱离Hadoop平台。Kyligence Cloud在底层使用云原生架构,云供应商的对象存储服务,如AWS S3、ADLS等用于存储,Spark+容器化用于计算。它的资源可以直接连接到云平台上的IaaS服务和ECS。Kyligence不断扩展到多个云,并对架构进行微调,并于2021年宣布将ClickHouse等新技术合并到架构中。
改造后的体系结构带来了巨大的灵活性、可维护性和低TCO,并得到了市场的积极反馈。
技术供应商的关键成功因素(KSF)是在捕捉趋势和产品转型方面都要非常快速、敏感和大胆。
大数据和分析市场,尤其是在北美,已经成为一个非常热门和竞争激烈的市场,拥有其他行业无法与之竞争的非常敬业的投资者。供应商始终关注市场趋势,倾听用户的意见,观察他们的新需求,并根据这些输入不断迭代您的产品,这是非常重要的。
大数据和分析的未来趋势
技术将不断进步,肩负新使命的初创公司可能会来来去去,大公司仍有韧性。我写了一篇关于7个必知数据流行语的博客,并讨论了2022年的新兴趋势。为了简短起见,我只列出一些(而不是全部)研究过的有趣趋势,并与您分享一些关于它们的好文章:
- Metrics Store will rise as the ultimate solution to keep the “single source of truth” - The missing piece of the modern data stack
- The design concept of Data Mesh will continue to influence IT decision-makers - Whitepaper: The Data Mesh Shift
- Data API/Data-as-a-product is an abstract but real demand from the market - Every product will be a data product; Big Data, Cloud, AI, and Data Analytics Predictions for 2022
大数据分析中Apache Hadoop常见问题解答
我们涵盖了客户在Hadoop上分析大数据时经常提出的关键问题
Hadoop在大数据分析中的用途是什么?
Apache Hadoop是一个开源软件框架,用于大型数据集的分布式存储和处理。Hadoop在大数据分析中的主要作用包括高效处理大量数据,提供可扩展性、容错性和经济高效的解决方案。Hadoop还可以促进高级分析,如预测分析、数据挖掘和机器学习。
Apache Hadoop的核心组件和用例是什么?
Apache Hadoop的核心组件包括用于数据存储的Hadoop分布式文件系统(HDFS)、用于处理的MapReduce和用于资源管理的YARN。其主要用例涉及处理和存储海量数据集,进行大规模数据分析,以及支持医疗保健、金融、零售和电信等行业的高级数据驱动应用程序。
最新内容
- 2 days 9 hours ago
- 1 week 3 days ago
- 2 weeks ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago