
关键词:埃森哲实验室,语义搜索,数据目录,矢量搜索,数据网格
随着数据越来越成为组织运营的基础,数据目录对于管理和利用数据资产变得至关重要。数据目录允许用户根据各种标准搜索和发现相关数据,例如数据资产的名称、元数据和相关的业务术语。现有的数据目录通常依赖于简单的字符串匹配技术,这可能会限制它们理解目录中概念的含义和关系的能力。这可能导致在搜索目录时丢失可能有用的数据资产。
为了增加复杂性,管理数据的新范式,如数据网格范式,要求公司构建按域组织并由不同组织单位管理的数据产品。这些数据重组在搜索数据时带来了新的挑战,因为不同领域专家创建的数据产品可能会导致相似的概念以不同的方式表达。
语义数据目录为上述挑战提供了解决方案,因为它为组织管理分布式数据产品提供了一个框架,可以使用语义搜索引擎从集中式公共目录中有效地搜索分布式数据产品。
在本博客中,我们介绍了语义数据目录框架,该框架利用本体、本体嵌入和向量搜索的力量,使用语义搜索来改进数据发现和管理。
使用语义数据目录的潜在好处包括:
- 提高了搜索的准确性和相关性:通过理解概念的含义及其之间的关系,语义数据目录可以提供更准确、更相关的搜索结果。
- 增强的数据发现:语义数据目录可以帮助用户找到他们可能不知道的数据资产,或者使用传统技术可能不容易发现的数据资产。
- 更好的数据组织和分类:通过利用本体作为语义数据目录的关键部分,它可以帮助数据资产的组织和分类,从而形成更结构化和一致的数据环境。
- 增强的数据治理:通过提供对数据概念的含义和关系的清晰理解,语义数据目录可以帮助组织更好地管理和利用其数据。
- 更高的效率和生产力:通过让用户更容易找到和访问相关数据,语义数据目录可以帮助提高数据驱动任务的效率和生产率。
下面,我们介绍了构建简单语义数据目录的一般方法,并提供了示例代码。由于在构建目录方面存在许多挑战,本博客不会解决所有问题,但会尝试突出需要解决的问题。
构建语义数据目录。
我们从构建语义数据目录的步骤的高级概述开始。首先,我们创建一个本体目录,它为每个数据资产保存一个本体。本体表示数据资产内和数据资产之间的概念和关系。其次,我们在目录上训练本体嵌入模型,以生成数字向量,或捕捉概念的含义和关系的“嵌入”。第三,我们将嵌入加载到向量搜索引擎中,该引擎允许用户使用文本搜索查询来搜索目录中的数据资产。最后,给定用户(无论是数据工程师、数据科学家还是业务用户)的查询,我们使用模型嵌入查询,并使用向量搜索引擎检索到大多数相关概念。下图展示了语义数据目录的高级架构。
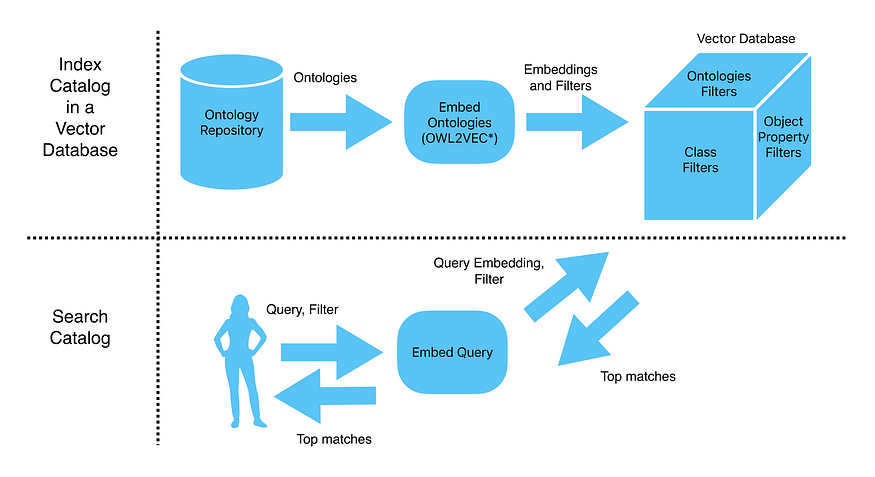
与基于字符串匹配和预定义搜索标准搜索目录的传统方法不同,语义数据目录可以使用本体嵌入技术提供更准确和相关的搜索结果。
嵌入可以随着时间的推移进行调整,以适应目录中的变化,或者进一步改进搜索结果,并允许组织更好地利用其现有的数据资产。
在这个博客中,我们描述了实现语义数据目录所需的主要步骤。正在运行的示例是为了说明目的,而不是作为一个完整目录的实现。
第一步:创建本体目录
数据目录通常包含各种类型的数据资产,从结构化数据集(例如,csv表)到高度规范化的数据集(如,第三范式),到半结构化(例如,json模式),再到非结构化数据集中(例如,blob存储上的文档)。
为了能够有效地在各种各样的数据资产中进行搜索,我们为每个数据资产创建了一个本体。本体是一个领域内一组概念和关系的形式表示,通常使用形式语言来表达。在我们的上下文中,我们创建本体来建模数据资产中的概念和关系,并在不同数据资产中连接概念。这些本体将作为我们数据资产之上的语义层。
为数据资产创建本体需要数据建模师和了解数据资产的专家共同工作,直到获得合适的概念本体。虽然这一过程可能需要大量人力,但通过利用自动化本体创建过程的工具(例如,Anzo、Stardog有一些产品),以及从公共本体库(例如,FIBO、D3FEND)借用概念,可以大大加快这一过程。
运行示例。在我们的运行示例中,我们将使用一个虚构的公司,它有三个数据资产,由三个公共本体描述:Edas(学术领域)、GoodRelations(商业领域)和Pizza(食品领域)。
A high-level view of the D3FEND Ontology in prote’ge’
评论虽然存在几种用于指定本体的语言,但W3C(万维网联盟)的OWL(网络本体语言)因其简单、可用的编辑器(例如prote'ge')以及数据管理平台(Anzo、Stardog、Neo4j、TopBraid等)的支持而脱颖而出。在我们的上下文中,最重要的是,一些最先进的本体嵌入技术要求本体用OWL编写。正如我们在下一节中所展示的那样,这一点至关重要。
第二步:在目录上训练本体嵌入模型
创建本体目录后,我们可以为本体中定义的每个概念(类、数据属性、对象属性等)创建嵌入。为此,我们可以使用预先训练的大型语言模型(Word2Vec、BERT)或本体嵌入技术(OWL2VEC*、EL嵌入和量子嵌入)。
在这个博客中,我们将使用牛津大学的开源库OWL2VEC*。OWL2VEC*获取一个本体目录,并构建一个嵌入本体的模型。关于如何做到这一点的详细信息以及对代码的访问可以在这里找到。
我们将目录中的本体放在一个目录中,并在本体上训练模型。训练完成后,嵌入模型被存储到一个文件中。
运行示例。我们克隆了OWL2VEC*项目,并将我们的示例本体放入/克隆项目中的ontologies目录。我们将该工具配置为使用预先训练的语言模型Word2Vec,并运行以下命令根据我们的本体对模型进行微调。
# Clone the OWL2Vec* project, follow the installation instructions # git clone https://github.com/KRR-Oxford/OWL2Vec-Star.git # 1. Create dir 'OWL2Vec-Star/ontologies' and place the ontologies. # 2. Create an empty directory 'OWL2Vec-Star/output' # 3. In 'OWL2Vec-Star/default_multi.cfg': # a. Uncomment the line starting with "pre_train_model =" and set the path of the local file of a pre-trained WORD2VEC model (inlude all extracted files in the same directory) # b. Comment the line starting with "cache_dir = " # c. change the training parameters: embed_size = 200; epoch = 200 # The following line will use OWL2VEC* to fine-tune the word2vec model on all ontologies in ./ontologies, and saves the trained model in ./output/multi_word2vec !python OWL2Vec_Standalone_Multi.py --ontology_dir ./ontologies --embedding_dir ./output/multi_word2vec --URI_Doc --Lit_Doc --Mix_Doc # This may take a few minutes # Install faiss, a vector search library by facebook # !pip install --upgrade pip # !pip install faiss-cpu
生成的模型存储在中/输出/multi-word2vec。
评论。
- 默认情况下,OWL2VEC*被训练来创建用于本体论概念(继承和类成员关系)之间的链接预测的嵌入。尽管如此,我们还是发现它的嵌入对搜索非常有效。这可能是由于它使用的底层语言模型(Word2VEC),该模型是在整个维基百科上训练的。
- OWL2VEC*生成的嵌入在很大程度上受到语言模型和本体嵌入配置参数的影响。因此,建议进行实验,直到产生适当的嵌入。
- 为了测试嵌入,您可以创建一个查询和匹配概念的小测试集。为了测量嵌入的准确性,您可以使用搜索引擎的常用度量,如平均倒数排名和命中率。
步骤三:将本体嵌入加载到向量搜索引擎
在为我们的本体创建嵌入之后,我们准备将模型和本体加载到向量搜索引擎中。为此,我们可以使用像FAISS这样的矢量搜索包,也可以使用像Pinecone这样的成熟矢量数据库。在矢量搜索引擎中,我们创建可搜索的索引。每个索引存储一组可以有效搜索的向量。
为了填充我们的索引,我们对本体的实体进行迭代,并使用模型生成添加到索引中的嵌入。
运行示例。在下面的代码片段中,我们创建了一个索引,其中包括所有本体的类,以及每个本体的单独索引。
首先,我们定义了一些辅助函数来规范化和嵌入文本。
from typing import List, Tuple, Dict, Union
import numpy as np
from gensim.models.word2vec import Word2Vec
# split string in camel notation to a list of words, and convert it to lower case as words in our model aer lower-cased
def parse_camel_plus(string: str) -> List[str]:
matches = re.finditer('.+?(?:(?<=[a-z])(?=[A-Z])|(?<=[A-Z])(?=[A-Z][a-z])|$)', string)
words = [m.group(0) for m in matches]
return [word.lower() for word in words]
# function to produce an embedding for a sentence by averaging the word embeddings
def embed_text(sentence:Union[str,List[str]], model:Word2Vec) -> np.ndarray:
# make sure sentence is a list of words
if isinstance(sentence, str):
sentence = sentence.split()
# init a vector of zeros to sum word embeddings, and defined known_words counter
emb_sum = np.zeros(model.vector_size, dtype=np.float32)
known_words = 0
# sum up embeddings of words known by the model
for word in sentence:
if word in model.wv.index_to_key:
emb_sum += model.wv.get_vector(word)
known_words += 1
# if there was at least one known word, return average embedding of all words
if known_words:
return emb_sum / known_words
else:
raise ValueError("no words recognized in the given sentence")然后,我们准备嵌入。我们加载模型和本体。我们使用owlready2从本体中解析和提取类,并使用模型嵌入类。我们为每个类创建两个嵌入,一个基于IRI的编码,另一个基于其标签。
import re
import gensim
import owlready2
# use the environment in which OWL2VEC* is installed and load model and ontologies
model = gensim.models.Word2Vec.load('./output/multi_word2vec')
ontologies:List[owlready2.Ontology] = [owlready2.get_ontology('./ontologies/'+onto_path).load() for onto_path in os.listdir('./ontologies')]
# Create an embedding dictionary per ontology.
# Map each ontology to a list of mappings for its classes, from class identifiers (IRI) to vector embeddings.
# Create two embedding per class based on the IRI and its label.
onto_iri2embeds:Dict[str,List[Tuple[str,np.ndarray]]] = dict()
for onto in ontologies:
onto_iri2embeds[onto.base_iri] = list()
for cls in onto.classes():
onto_iri2embeds[onto.base_iri].append((cls.iri, model.wv.get_vector(cls.iri)))
try:
cls_name = ' '.join(parse_camel_plus(cls.name))
onto_iri2embeds[onto.base_iri].append((cls.iri, embed_text(cls_name, model)))
except ValueError:
pass最后,我们创建了几个搜索索引,以支持按标准进行文本搜索。每个索引都是使用FAISS创建的。
import faiss
from faiss.swigfaiss import IndexFlatIP
from itertools import chain
# Create a faiss index out of a list of embedding mappings
def create_index(embeddings: List[Tuple[str,np.ndarray]], model: Word2Vec) -> IndexFlatIP:
# make 2D array of all embeddings
embeddings = [embedding[1] for embedding in embeddings]
embeddings_2d = np.stack(embeddings, axis=0)
# create a faiss search index, and add give embeddings to it
search_index = faiss.IndexFlatIP(model.vector_size)
search_index.add(embeddings_2d)
return search_index
# Create a dictionary of Faiss indices.
# Creat an index for all classes, and index per ontology
name2faiss_index:Dict[str, IndexFlatIP] = dict()
all_embeddings = list(chain.from_iterable(onto_iri2embeds.values()))
name2faiss_index['All'] = create_index(all_embeddings, model)
for ontology_iri in onto_iri2embeds:
name2faiss_index[ontology_iri] = create_index(onto_iri2embeds[ontology_iri], model)评论。
- 为了支持过滤搜索,我们定义了多个索引。Pinecone提供了一个支持过滤搜索的矢量数据库。这消除了创建专用过滤器的需要。
- 要包括其他本体论实体(如个人、数据属性或对象属性),只需扩展索引即可。
第四步:围绕搜索引擎索引构建包装并运行查询
为了激活我们的搜索引擎,我们可以实现一个带有查询挂钩的API或一个CLI,它可以触发系统根据文本查询生成顶级匹配的本体实体。
给定搜索查询和搜索条件,我们从匹配索引中检索最相关的实体。我们将使用我们的模型嵌入查询,并使用搜索引擎返回最匹配的实体。
运行示例。下面是一个简单的代码片段,它使用我们的训练模型和相关索引来运行文本查询。
首先,我们使用helper函数并嵌入查询。然后,我们使用相关的FAISS索引(在我们的示例中为“All”)来获得最匹配的实体。
以下是对所有目录本体的示例查询:
# query = 'onion' over entire catalog
query = 'spicy'
query_emb = embed_text(query, model).reshape(1,-1) # reshape because that's how faiss expect to receive it
scores, indexes = name2faiss_index['All'].search(query_emb, 5) # faiss returns similarity scores and indexes of the closest vectors
results = [all_embeddings[ind][0] for ind in indexes[0]] # get entity IRIs of the closest vectos
for result in results:
print(result)http://www.co-ode.org/ontologies/pizza/pizza.owl#SpicyTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#SpicyPizza
http://www.co-ode.org/ontologies/pizza/pizza.owl#SauceTopping
http://edas#MealMenu
http://www.co-ode.org/ontologies/pizza/pizza.owl#Food
可以看出,我们从pizza本体获得了四个点击,从edas本体获得了一个点击。
这是相同的查询,但仅在披萨本体上搜索。
# 'onion' query over the pizza ontology
query = 'onion'
query_emb = embed_text(query, model).reshape(1,-1) # reshape because that's how faiss expect to receive it
scores, indexes = name2faiss_index['http://www.co-ode.org/ontologies/pizza/'].search(query_emb, 5) # faiss returns similarity scores and indexes of the closest vectors
ontology_embeddings = onto_iri2embeds['http://www.co-ode.org/ontologies/pizza/']
results = [ontology_embeddings[ind][0] for ind in indexes[0]] # get entity IRIs of the closest vectos
for result in results:
print(result)
name2faiss_index.keys()
http://www.co-ode.org/ontologies/pizza/pizza.owl#OnionTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#RedOnionTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#GarlicTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#ChickenTopping
http://www.co-ode.org/ontologies/pizza/pizza.owl#Soho
挑战
在本博客中,我们介绍了构建语义数据目录的主要步骤,并提供了一个运行示例进行说明。我们在不同步骤中添加了一些考虑因素。尽管如此,重要的是要注意到,还有更多的考虑因素和挑战需要解决。首先,训练高质量的本体嵌入模型并在添加新的数据资产时保持其准确性需要时间和计算资源。此外,评估嵌入的有效性并随着目录的发展更新搜索索引是确保检索到相关结果的关键。应对这些挑战可能需要作出重大努力。我们希望,随着矢量搜索数据库成为更成熟的技术,其中一些挑战将随着时间的推移得到解决。尽管如此,为了充分发挥语义数据目录的潜力,必须考虑和解决这些挑战。
- 结束语。在这个博客中,我们描述了语义数据目录,它提供了一种强大而有效的方法来管理和发现数据网格中的数据。使用本体有助于数据资产的组织和分类,并改善数据治理,而基于本体的向量搜索可以提供更准确和相关的搜索结果,以提高数据利用率。语义数据目录也带来了一些新的挑战,我们在本博客中列出了其中的一些挑战。如果您希望改进数据管理策略,请考虑实现语义数据目录,以最大限度地发挥数据资产的全部潜力。无论您是数据工程师、数据科学家还是业务用户,语义数据目录都可以提供丰富的好处,帮助您更好地利用数据来推动更多见解和成功。
最新内容
- 6 days 19 hours ago
- 1 week 3 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago