
数据分析师、数据科学家、工程师甚至业务用户经常需要深入了解其组织数据的细节。该领域的供应商让数据目录听起来真的很花哨——例如,Atlan说“数据目录是一个协作工作空间,供不同的数据用户在企业的数据生态系统中导航。”什么?更简单地说,数据目录是我的数据集列表和其中内容的描述。
以下是数据目录可以帮助人们的一些方法-
- 查找正确的表和列(数据发现)
- 调试数据质量问题
- 编写SQL查询
已经有许多数据目录可用——既有开源的(Amundsen, DataHub),也有商业的(Atlan, Alation, Collibra)。但它们通常非常重,不可能或很难为您自己的组织进行定制。其中一些每年的成本高达10万美元!
相反,如果您可以使用不到400行纯Python的全功能(尽管有点基础)数据目录,并为您的组织定制它,会怎么样?让我们深入了解一下。
Links: Live App | Github | Youtube | Pycob | Google Slides
<yt视频>
应用程序演示
对于我们的演示,我们将使用Northwind数据库。根据链接的Github-
Northwind示例数据库由Microsoft Access提供,作为管理小企业客户、订单、库存、采购、供应商、运输和员工的教程模式。Northwind是小型企业ERP的优秀教程模式,包括客户、订单、库存、采购、供应商、运输、员工和单项会计。
表和关系如下所示。

对于我们的数据目录应用程序,我们在数据目录中有两个主页面——一个显示表列表,另一个显示每个表的内容。
第一页是表格列表,以及一些基本信息,如表格描述、行数、表格上次更新的时间等。它还有一个链接,可以查看有关表格的详细信息。

如果我们点击订单表,它会将我们带到表格详细信息页面。我们可以看到一些基本信息,比如行数(830)。
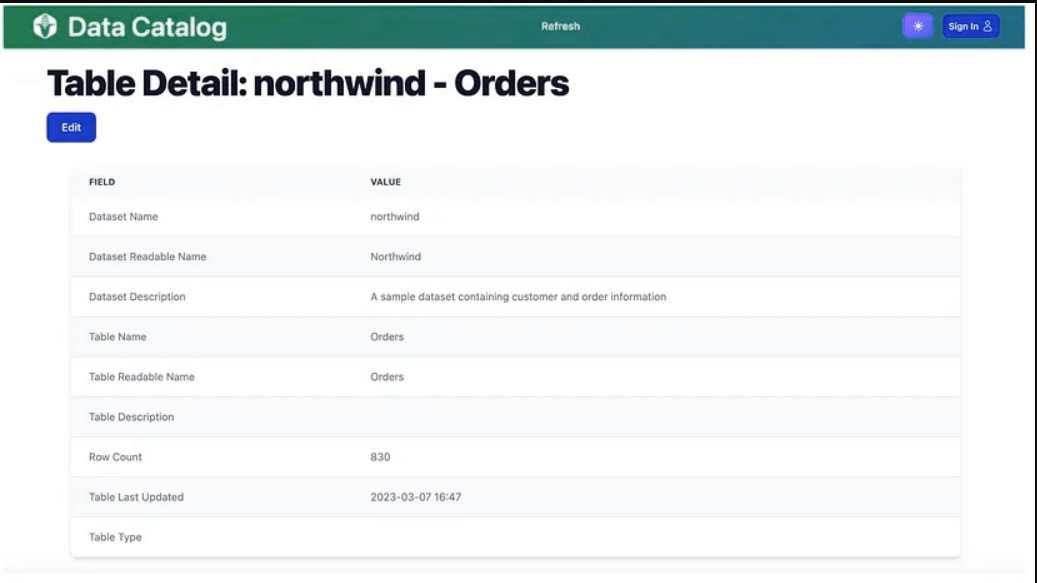
在下面,我们看到了该表中的列列表,以及一些有用的列元数据,如名称、数据类型、最小值、最大值、空值数量等。

最后,我们有几行示例数据。这让用户能够了解表中的内容。

最后,底部有一个指向“编辑表元数据”的链接。编辑页面的第一部分允许用户编辑表级信息-

第二部分允许用户在单个屏幕中编辑每个列。这对于数据分析员希望同时添加多个列的信息的工作流非常有用。

最后,注意顶部的“刷新”按钮。此按钮将通过重新读取数据库并更新表、列和统计信息来刷新数据目录中的信息。

架构
让我们从技术角度来看看这一切是如何结合在一起的。

我们有四种主要的数据结构-数据集、数据集、表、列
此外,我们还有五个页面——tables、refresh、edit、table_detail和update。
代码
接下来我们将逐步了解一些重要的代码。
首先,让我们看看数据集的数据类。我们有四个字段,包括表列表。我们还有两个函数,一个如下所示,它将表转换为DataFrame。
@dataclass
class Dataset:
name: str
readable_name: str
description: str
tables: list[Table]
def to_dataframe(self) -> pd.DataFrame:
records = []
for table in self.tables:
row = {}
row['dataset_name'] = self.name
row['dataset_readable_name'] = self.readable_name
row['dataset_description'] = self.description
row['table_name'] = table.name
row['table_readable_name'] = table.readable_name
row['table_description'] = table.description
row['row_count'] = table.row_count
row['table_last_updated'] = table.last_updated.strftime("%Y-%m-%d %H:%M")
row['table_type'] = table.type
records.append(row)
return pd.DataFrame(records)然后,我们获取我们的云泡菜,利用Pycob功能,使我们能够轻松地保存和读取云泡菜-
# PyCob has a built-in cloud pickle feature that allows you to save and load objects to the cloud.
dsets: Datasets
try:
print("Loading from cloud pickle")
dsets = app.from_cloud_pickle("northwind.pkl")让我们来看看一些刷新代码的内核。我们使用一些SQL命令(SQLite)来获取有关表和列的信息。
for table_name in tables['name']:
# Get table metadata
# Get columns
columns = pd.read_sql_query(f"PRAGMA table_info('{table_name}')", conn)
# Remove the "Picture" or "Photo" column from the sample data
columns = columns[columns['name'] != 'Picture']
columns = columns[columns['name'] != 'Photo']
page.add_pandastable(columns)
sample = pd.read_sql_query(f"SELECT * FROM \"{table_name}\" LIMIT 10", conn)既然我们已经将数据存储在云pickle中,并且已经读取了该pickle,那么让我们显示这些表。add_datagrid做了一些肮脏的工作,并在应用程序上呈现了一个漂亮的表小部件。
def tables(server_request: cob.Request) -> cob.Page:
page = cob.Page("Tables")
page.add_header("Tables")
if dsets is None:
page.add_alert("Refresh required", "Error", "red")
return page
action_buttons = [
cob.Rowaction(label="View", url="/table_detail?dataset_name={dataset_name}&table_name={table_name}", open_in_new_window=False),
]
page.add_datagrid(dsets.to_dataframe(), action_buttons=action_buttons)
return page接下来,让我们看看table_detail页面的内容。在这里,我们对add_pandastable进行了三次调用,并在页面上呈现了表元数据、列列表和示例数据。
table_df = dset.to_dataframe().iloc[table_index,:].reset_index()
table = dset.tables[table_index]
table_df.columns = ["Field", "Value"]
# Make the field names more readable
table_df['Field'] = table_df['Field'].map(lambda x: x.replace("_", " ").title())
page.add_pandastable(table_df)
page.add_header("Columns", size=2)
page.add_pandastable(table.to_dataframe())
page.add_header("Sample Data", size=2)
page.add_pandastable(table.sample)
page.add_link("Edit Table Metadata", f"/edit?dataset_name={dset.name}&table_name={table_name}")最后是编辑页面。在这里,我们有特定于表的值以及一个循环来获取所有列可编辑字段。
with page.add_card() as card:
card.add_header(f"Edit")
card.add_header(f"{dset.readable_name} - {table.readable_name}", size=2)
with card.add_form(action="/update") as form:
form.add_formhidden("dataset_name", value=dataset_name)
form.add_formhidden("table_name", value=table_name)
form.add_formtext("Dataset Readable Name", "dataset_readable_name", value=dset.readable_name)
form.add_formtext("Table Readable Name", "table_readable_name", value=table.readable_name)
table = dset.tables[table_index]
form.add_formselect("Table Type", "table_type", options=["Fact", "Dimension"], value=table.type)
form.add_formtextarea("Table Description", "table_description", placeholder="Table Description", value=table.description)
for column in table.columns:
form.add_text(f"Column <code>{column.name}</code>")
with form.add_container(grid_columns=2) as container:
container.add_formtext(f"Readable Name", f"column_{column.name}_readable_name", value=column.readable_name)
container.add_formtextarea(f"Description", f"column_{column.name}_description", value=column.description, placeholder="Column Description")
form.add_formsubmit("Save")部署
现在我们已经在本地机器上运行了该应用程序,让我们将其部署到Pycob的云主机上,以便我们组织中的其他人可以访问它。部署非常简单,只要有了API密钥,只需一步。你所需要做的就是-
python3 -m pycob.deploy
等待大约5分钟,应用程序就可以在服务器上运行了!
在您的组织中使用数据目录应用程序
为了使其适合您的组织,您可能需要进行许多修改和增强。整个应用程序是100%免费和开源的,可以在您的环境中本地运行,也可以通过Pycob外部托管。您可能需要进行一些更改-
- 自定义连接字符串。这是强制性的-你不想要Northwind的数据:)。
- 向列和表中添加更多计算。
- 安排更新自动运行。
最新内容
- 5 days 14 hours ago
- 1 week 2 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago