
我们如何设计配额微服务来防止资源滥用
随着业务的增长,Grab的基础设施已经从一个单一的服务变成了几十个微服务。这个数字很快就会以数百的形式出现。随着我们的工程团队并行发展,拥有一个微服务框架可以提供更高的灵活性、生产力、安全性和系统可靠性。团队与客户定义服务水平协议(SLA),即服务的API接口及其相关性能指标的规范。只要保持sla,各个团队就可以专注于他们的服务,而不必担心破坏其他服务。
然而,迁移到一个微服务框架可能会很棘手——因为有大量的服务,而且必须在它们之间进行通信。对于基于微服务的框架来说,容易解决或不存在的问题(如服务发现、安全性、负载平衡、监控和速率限制)是具有挑战性的。可靠、可伸缩和高性能的通用系统级问题解决方案是微服务成功的关键,现在有一个广泛的倡议来提供这些通用解决方案。
作为该计划的一个重要组成部分,我们编写了一个名为quota的微服务,这是一个高度可伸缩的API请求速率限制解决方案,以缓解服务滥用和级联服务故障的问题。在本文中,我们将讨论配额解决的挑战、如何设计它以及最终结果。
配额尝试解决什么问题?
限价是一个众所周知的概念,多年来许多公司都在使用。例如,电信公司和内容提供商经常使用流行的速率限制算法(如漏桶、固定窗口、滑动日志、滑动窗口等)来限制滥用用户的请求。所有这些都避免了资源滥用,保护了重要的资源。各公司还开发了服务间通信的速率限制解决方案,例如Doorman (https://github.com/youtube/doorman/blob/master/doc/design.md)、Ambassador (https://www.getador.io/reference/services/rate-limitservice)等。
费率限制可以在本地或全球强制执行。本地速率限制意味着一个实例积累API请求信息并在本地进行决策,而不需要进行协调。例如,本地速率限制策略可以指定每个服务实例每秒最多可以为一个API服务1000个请求,并且服务实例将保留一个本地时间感知的请求计数器。一旦接收的请求数量超过阈值,它将立即拒绝新请求,直到下一个具有可用配额的时间桶。全局速率限制意味着多个实例共享相同的实施策略。通过全局速率限制,无论客户端调用的服务实例是什么,它都将受到相同的全局API配额。全局速率限制确保存在全局视图,并且在许多场景中首选全局视图。在云环境中,通过自动伸缩策略设置,服务的实例数量可以在流量高峰期显著增加。如果只实施本地速率限制,累积效应仍然会对数据库、网络或下游服务等关键资源造成巨大压力,累积效应会导致服务失败。
然而,在分布式环境中支持全局速率限制并不容易,而且当服务和实例的数量增加时,这将变得更具挑战性。为了支持全局视图,限额需要知道一个客户端服务有多少请求。与所定义的阈值相比,服务A是配额的客户端)现在在一个端点上。如果请求的数量已经超过了阈值,那么在服务a执行其主逻辑之前,quota服务应该有助于阻止新请求。通过这样做,配额服务有助于为保护资源(如CPU、内存、数据库、网络及其下游服务)提供服务。为了跟踪服务端点上的全局请求计数,通常使用集中的数据存储(如Redis或Dynamo)来进行聚合和决策制定。此外,如果每个请求都需要调用速率限制服务(即来决定是否应该限制请求。如果是这样,速率限制服务将位于每个请求的关键路径上,这将是服务的主要关注点。这是我们在设计限额服务时绝对希望避免的场景。
设计配额
配额确保Grab内部服务可以通过限制向它们发出的“过多”API请求来保证它们的服务水平协议(SLA),从而避免级联失败。通过尽早通过节流拒绝这些调用,可以防止服务耗尽关键资源,如数据库、计算资源等。
配额的两个主要目标是:
- 帮助客户服务及时地控制过多的API请求。
- 最小化对客户服务的延迟影响。,客户端服务在API响应时间上的延迟增加应该可以忽略不计。
我们遵循以下设计准则:
- 提供瘦客户机实现。配额服务应该将大部分处理逻辑保留在服务端。一旦我们发布了客户端SDK,就很难跟踪谁在使用哪个版本,并使用新的客户端SDK版本来更新每个客户端服务。而且,更复杂的客户端逻辑增加了引入bug的机会。
- 为了支持限额服务的扩展,我们使用异步处理管道而不是同步处理管道(即,客户端服务对每个API请求进行调用配额)。通过异步处理事件,客户端服务可以立即决定是否在API请求传入时对其进行限制,而不会过多地延迟响应。
- 允许通过配置更改进行水平扩展。这是非常重要的,因为目标是机上所有的内部服务。
图1是配额的客户端和服务器端交互的高级系统图。Kafka是系统设计的核心。Kafka是Apache许可下的一个开源分布式流媒体平台,被业界广泛采用(https://kafka.apache.org/intro)。Kafka在配额系统设计中用于以下目的:
客户服务(即通过专用的Kafka主题发送API使用信息,而quota service将使用事件并执行其业务逻辑。
quota service通过特定于应用程序的Kafka主题发送限制速率的决策,并且在客户机服务实例上运行的quota客户机sdk使用限制速率的事件并更新本地内存缓存以进行限制速率的决策。例如,配额服务对服务B的利率限制决策使用“rate-limit -service- B”之类的主题名称,对服务C使用“rate-limit -service- C”之类的主题名称。
一个归档器正在与Kafka一起运行,以便将事件归档到AWS S3桶中进行额外的分析。
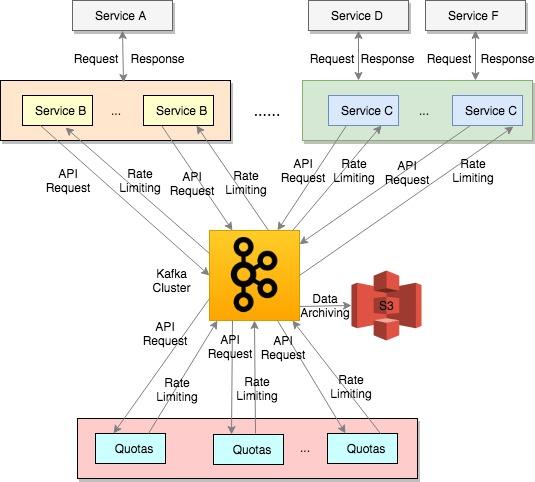
图2以服务B为例显示了quota客户端逻辑的详细信息。正如它所显示的,当一个请求进入(例如,来自服务a)时,服务B将执行以下逻辑:
- 运行服务B的配额中间件
- 拦截请求并调用配额客户端SDK,根据API和客户端信息进行速率限制决策。
- 如果它对请求进行了节流,服务B将返回一个响应代码,表明对请求进行了节流。
- 如果不限制请求,服务B将使用其正常的业务逻辑来处理它。
- 异步地将API请求信息发送到Kafka主题进行处理。
- 拦截请求并调用配额客户端SDK,根据API和客户端信息进行速率限制决策。
- 配额客户端SDK运行与服务B
- 使用特定于应用程序的速率限制Kafka流,并更新其本地内存缓存以执行新的速率限制决策。例如,如果前面的决定是正确的(即,强制执行速率限制),来自Kafka流的新决策是错误的,本地内存缓存将被更新以反映更改。之后,如果一个新的请求来自服务a,它将被允许通过服务B提供服务。
- 提供一个单一的公共API来读取基于API和客户端信息的速率限制决策。这个公共API从它的本地内存缓存中读取决策。
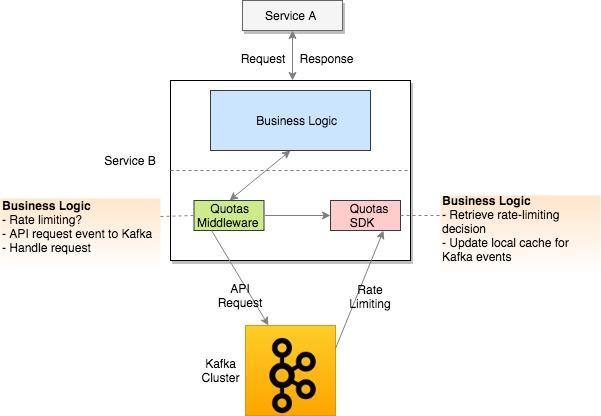
图3显示了限额服务器端逻辑的详细信息。它执行以下业务逻辑:
- 使用Kafka流主题获取API请求信息
- 对API用法执行聚合
- 定期将统计信息存储在Redis集群中
- 定期做出限价决定
- 将速率限制决策发送到特定于应用程序的Kafka流
- 定期将统计信息发送到DataDog进行监视和警报
此外,服务所有者还可以使用一个管理UI来更新阈值,并且可以立即对即将进行的速率限制决策进行更改。
实现决策和优化
在客户端服务端(上图中的服务B),在初始化服务B实例时初始化配额客户端SDK。quota client SDK是一个包装器,它使用Kafka速率限制事件并读写内存中的缓存。它提供一个API来检查客户端上给定API方法的速率限制决策。另外,服务B与配额中间件连接,以拦截API请求。在内部,它调用quota client SDK API来确定是否应该在实际业务逻辑之前允许/拒绝请求。目前,限额中间件同时支持gRPC和REST协议。
配额为Kafka流的生产者和消费者实现使用一个全公司范围的流解决方案,称为洒水器。它提供了构建在sarama (Apache Kafka的mit许可Go库)之上的流sdk,提供异步事件发送/使用、重试和断路功能。
配额在1秒和5秒级别上提供基于滑动窗口算法的节流功能。为了支持极高的TPS需求,大多数配额中间操作都是异步完成的。内部基准测试显示,执行限速决策的延迟可达200毫秒。通过结合1秒和5秒级别设置,客户端服务可以更有效地控制请求。
在系统实现期间,我们发现如果quota实例每次从Kafka API使用流接收事件时都对Redis集群进行调用,那么由于计算量的增加,Redis集群将很快成为瓶颈。通过在内存中本地聚合API使用统计数据并定期调用Redis实例(即,我们可以显著减少Redis的使用,同时仍然将总体决策延迟保持在一个相对较低的水平。此外,我们设计散列键的方式是确保请求均匀地分布在Redis实例中。
评估和基准
我们在启动限额之前和之后进行了多轮负载测试,以评估其性能并找到潜在的扩展瓶颈。经过优化之后,限额现在可以很好地处理200k的峰值生产TPS。更重要的是,配额的应用服务器、Redis和Kafka的关键系统资源使用仍然处于相对较低的水平,这表明在需要扩展之前,配额可以支持更高的TPS。
目前的生产设置为:
- 12 c5.2xlarge (8 vCPU, 16GB) AWS EC2实例
- 6 cache.m4。大型(2 vCPU, 6.42GB,主从级)AWS弹性缓存
- 与其他应用程序主题共享Kafka集群
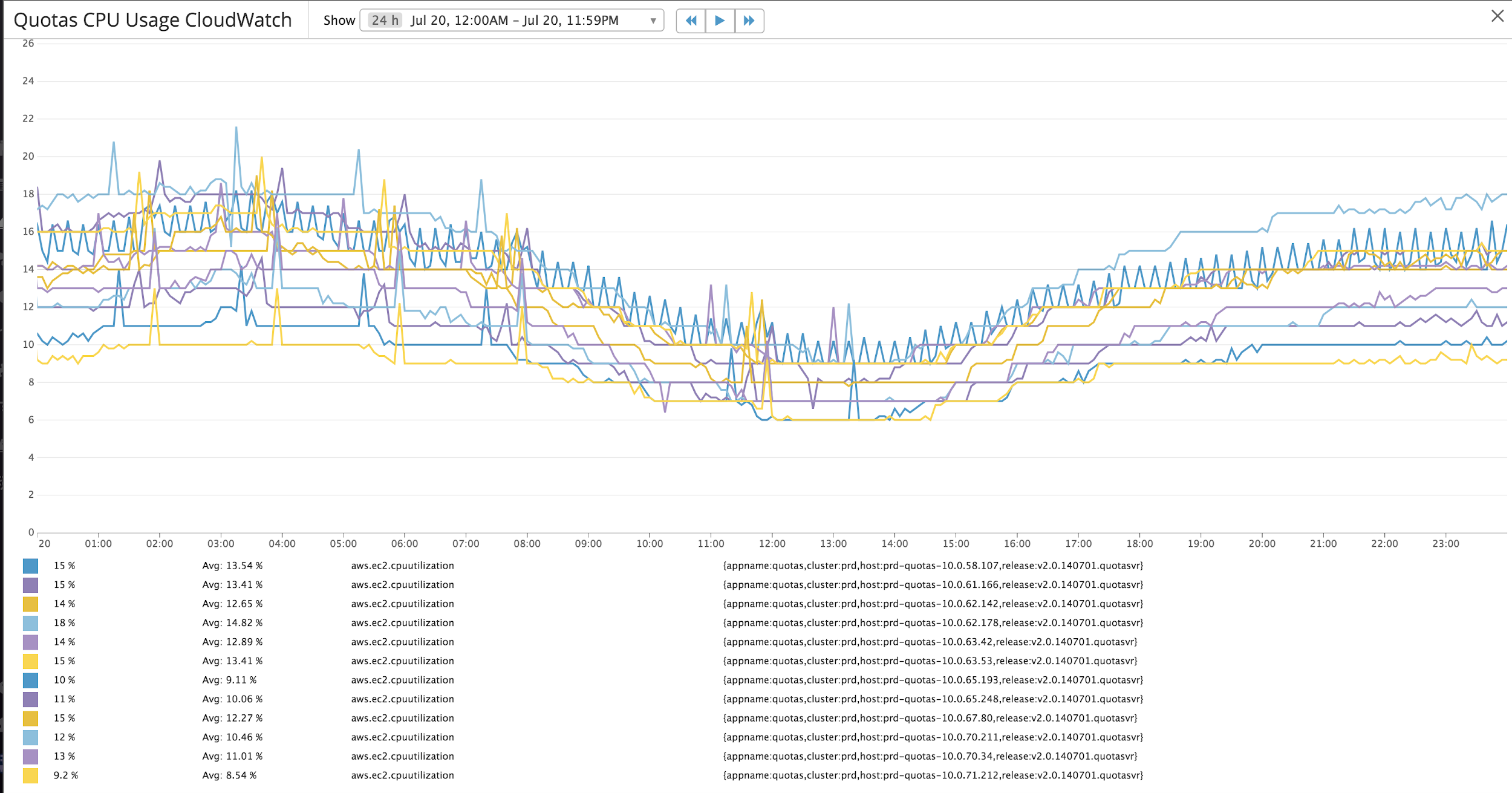
图4和图5分别显示了配额应用程序服务器和Redis缓存的典型的CPU使用情况。对于200k峰值TPS,限额处理负载,峰值应用服务器CPU使用率约为20%,而Redis CPU使用率为15%。由于配额数据使用的性质,Redis缓存中存储的大多数数据都是时间敏感的,并使用生存时间(time-to-live, TTL)值存储。
但是,由于Redis expires密钥(https://redis.io/commands/expire)和Redis中对时间敏感的数据配额的数量,我们实现了一个专有的cron作业来主动垃圾收集过期的Redis密钥。通过每15分钟运行一次cron作业,限额将Redis内存使用量保持在较低的水平。
我们进行了负载测试,以确定扩展限额的潜在问题。测试表明,我们可以横向扩展配额来支持极高的TPS,只需配置更改:
- Kafka以高吞吐量、低延迟和高可伸缩性而闻名。通过增加配额API使用主题上的分区数量或添加更多Kafka节点,系统可以均匀地分配和处理额外的负载。
- 所有的配额应用服务器组成一个消费者组(CG)来使用Kafka API使用主题(根据实例期望的数量进行分区)。无论何时实例启动或脱机,主题分区都会在应用服务器之间重新分布。这允许平衡主题分区消耗,从而在一定程度上均匀分布应用服务器CPU和内存使用。
- 我们还实现了一个一致的基于哈希的算法来支持多个Redis实例。它支持通过配置更改轻松添加或删除Redis实例。使用精心选择的散列键,负载可以均匀地分布到Redis实例。
通过上述设计和实现,当在Kafka、application server或Redis级别出现瓶颈时,可以轻松地扩展所有关键配额组件。
配额路线图
目前有十几个内部Grab服务使用限额,很快所有的Grab内部服务都会使用限额。
配额制是全公司ServiceMesh工作的一部分,该工作致力于跨所有Grab服务一致地处理服务发现、负载平衡、断路器、重试、健康监控、速率限制、安全性等。
原文:https://engineering.grab.com/quotas-service
本文:https://pub.intelligentx.net/node/790
讨论:请加入支持星球或者小红圈【首席架构师圈】
- 登录 发表评论
- 197 次浏览
最新内容
- 9 hours ago
- 1 month 2 weeks ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago