
category
参数高效微调——LoRA、QLoRA——概念
在本博客中,我们将了解参数有效微调(PEFT)背后的思想,并探索LoRA和QLoRA这两种最重要的PEFT方法。我们将了解如何使用PEFT以最低的成本和最小的基础设施来微调特定领域任务的模型。
动机
在不断发展的人工智能和自然语言处理(NLP)世界中,大型语言模型和生成人工智能已成为各种应用的强大工具。从这些模型中获得所需的结果涉及不同的方法,这些方法大致可分为三类:即时工程、微调和创建新模型。随着我们从一个层次发展到另一个层次,资源和成本方面的需求显著增加。
在这篇博客文章中,我们将探索这些方法,并专注于一种名为参数高效微调(PEFT)的高效技术,该技术使我们能够在保持高性能的同时,用最小的基础结构对模型进行微调。
使用现有模型进行即时工程
在基本层面上,实现大型语言模型的预期结果需要仔细的提示工程。这个过程包括精心制作合适的提示和输入,以从模型中获得所需的响应。对于各种用例来说,即时工程是一种必不可少的技术,尤其是当一般响应足够时。
创建新模型
在最高级别上,创建新模型需要从头开始训练模型,专门为特定任务或领域量身定制。这种方法提供了最高级别的定制,但它需要大量的计算能力、大量的数据和时间。
微调现有模型
在处理需要模型调整的特定领域用例时,精细调整变得至关重要。微调使我们能够利用现有的预训练基础模型,并使其适应特定的任务或领域。通过在特定领域的数据上训练模型,我们可以对其进行调整,使其在目标任务中表现良好。
然而,这一过程可能是资源密集型的,成本高昂,因为作为培训的一部分,我们将修改所有的参数。微调模型需要大量的训练数据、庞大的基础设施和精力。
在LLM的完全微调过程中,存在灾难性遗忘的风险,先前从预训练中获得的知识会丢失。
对不同领域特定任务的单个模型进行完全微调,通常会导致创建针对特定任务的大型模型,缺乏模块性。我们需要的是一种模块化的方法,它可以避免更改所有参数,同时要求更少的基础设施资源和更少的数据。
有各种技术,如参数有效微调(PEFT),提供了一种以最佳资源和成本执行模块化微调的方法。
参数有效微调(PEFT)
PEFT是一种旨在微调模型的技术,同时最大限度地减少对大量资源和成本的需求。当处理需要模型自适应的特定领域任务时,PEFT是一个很好的选择。通过使用PEFT,我们可以在保留预先训练的模型中的宝贵知识和用较少的参数将其有效地适应目标任务之间取得平衡。有多种方法可以实现参数高效微调。低秩参数或LoRA&QLoRA是最广泛使用和有效的。
低阶参数(Low-Rank Parameters)
这是最广泛使用的方法之一,其中一组参数以较低的维空间模块化地添加到网络中。不是修改整个网络,而是只修改这些模块化的低秩网络,以达到目的。
让我们深入了解最流行的技术之一,即LoRA和QLoRA
低阶自适应【Low-Rank Adaptation (LoRA)】(LoRA)
低秩自适应提供了模块化方法来微调特定领域任务的模型,并提供了迁移学习的能力。LoRA技术可以用更少的资源来实现并且是存储器高效的。
在下图中,您可以看到维度/秩分解,这大大减少了内存占用。
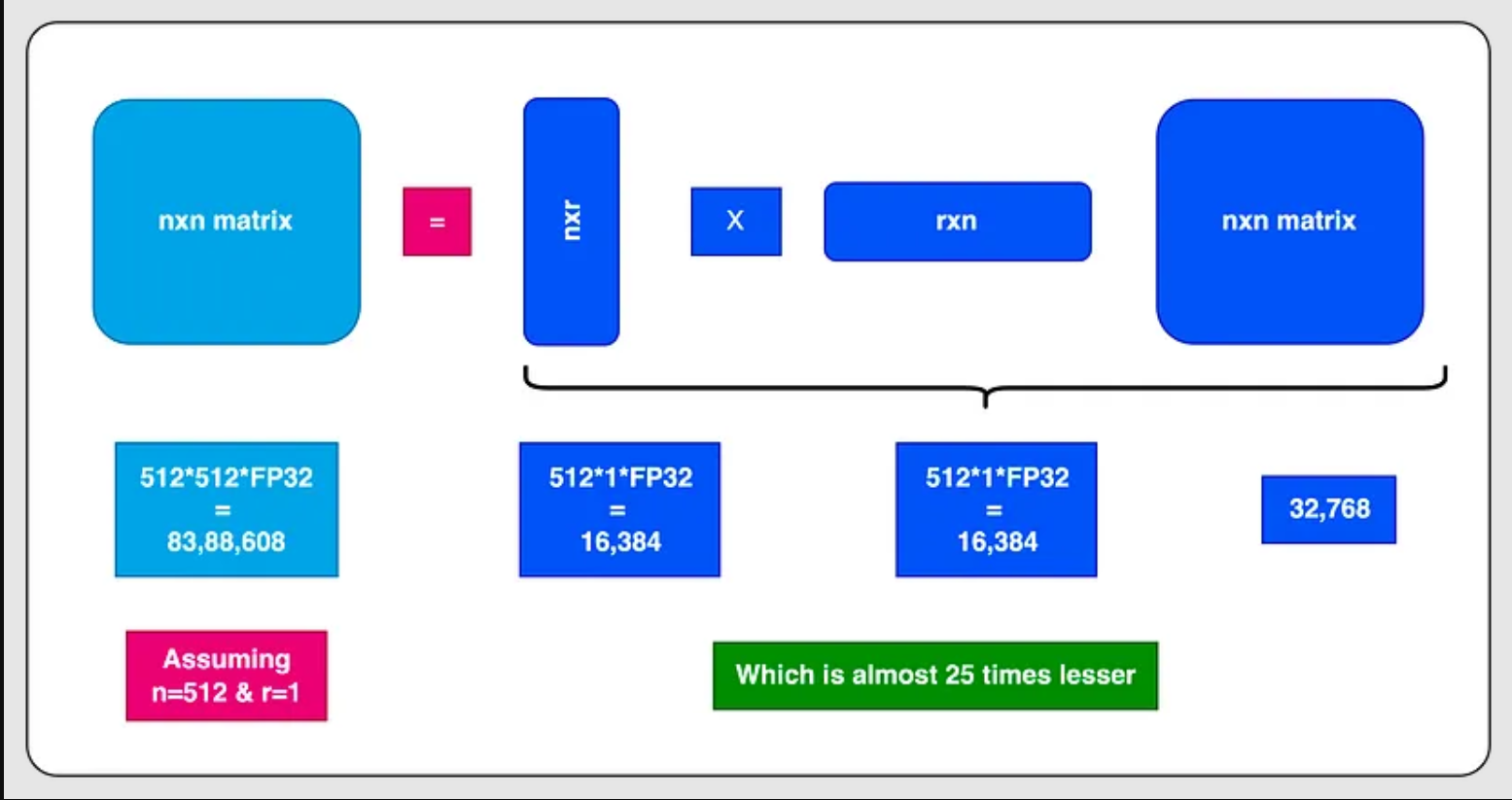
我们将通过将LoRA适配器扩展到现有的前馈网络来实现这一点。我们将冻结原始的前馈网络,并将使用LoRA网络进行训练。有关更多详细信息,请参阅下图。
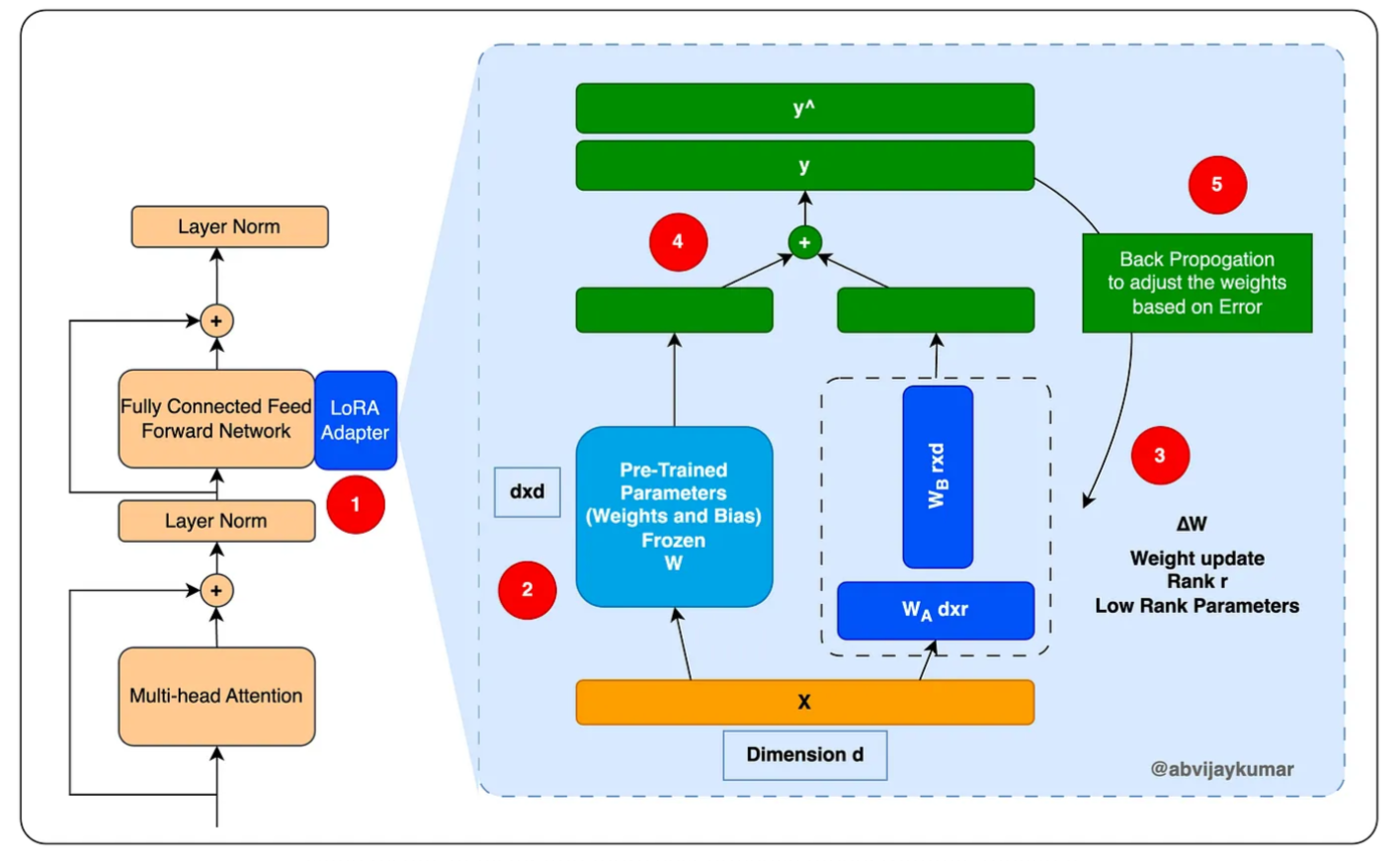
- LoRA 可以作为适配器来实现,旨在增强和扩展现有的神经网络层。它引入了额外的可训练参数(权重)层,同时将原始参数保持在冻结状态。与原始网络的维度相比,这些可训练参数的秩(维度)大大降低。 LoRa 通过这种机制简化并加快了针对特定领域任务调整原始模型的过程。现在,让我们仔细看看 LORA 适配器网络中的组件。
- 原始模型(W)的预训练参数被冻结。在训练期间,这些权重不会被修改。
- 一组新的参数同时添加到网络 WA 和 WB 中。这些网络利用低秩权重向量,其中这些向量的维度表示为 dxr 和 rxd。这里,“d”代表原始冻结网络参数向量的维度,而“r”表示所选的低秩或更低维度。 “r”的值总是越小,“r”越小,模型训练过程就越加速和简化。确定“r”的适当值是 LoRA 中的关键决策。选择较低的值会导致更快且更具成本效益的模型训练,尽管它可能不会产生最佳结果。相反,为“r”选择较高的值会延长训练时间和成本,但会增强模型处理更复杂任务的能力。
- 将原始网络和低秩网络的结果进行点积计算,得到一个n维的权重矩阵,用于生成结果。
- 然后将该结果与预期结果(训练期间)进行比较,以计算损失函数,并根据损失函数调整 WA 和 WB 权重,作为像标准神经网络一样的反向传播的一部分。
让我们探讨一下这种方法如何有助于减少内存占用并最大限度地减少基础设施要求。考虑这样一个场景,前馈网络中有一个 512x512 参数矩阵,总共有 262,144 个参数需要接受训练。如果我们选择在训练过程中冻结这些参数并引入等级为2的LoRA适配器,则结果如下:WA将有512*2个参数,WB也将有512*2个参数,总共有512*2个参数。 2,048 个参数。这些是使用特定领域数据进行训练的特定参数。这代表了计算效率的显着提高,大大减少了反向传播过程中所需的计算数量。该机制对于实现加速培训至关重要。
这种方法最有利的方面是经过训练的 LoRA 适配器可以独立保存并作为不同的模块使用。通过以这种方式构建特定领域的模块,我们有效地实现了高水平的模块化。此外,通过不改变原始权重,我们成功地规避了灾难性遗忘的问题。
现在,让我们深入研究可以在 LoRA 上实现的进一步增强功能,特别是通过使用 QLoRA,以便将优化提升到一个新的水平。
量化低阶适应[Quantized Low-Ranking Adaptation](QLoRA)
QLoRA 扩展了 LoRA,通过量化原始网络的权重值来提高效率,从高分辨率数据类型(如 Float32)到较低分辨率数据类型(如 int4)。这会减少内存需求并加快计算速度。
QLoRA 在 LoRA 的基础上带来了 3 个关键优化,这使得 QLoRA 成为最好的 PEFT 方法之一。
4 位 NF4 量化
4 位 NormalFloat4 是一种优化的数据类型,可用于存储权重,从而大大减少内存占用。 4 位 NormalFloat4 量化是一个 3 步过程
归一化和量化:作为归一化和量化步骤的一部分,权重被调整为零均值和恒定的单位方差。 4 位数据类型只能存储 16 个数字。作为归一化的一部分,权重被映射到这 16 个数字,以零为中心分布,并且不存储权重,而是存储最近的位置。这是一个例子
假设我们有一个 FP32 权重,值为 0.2121。 -1 到 1 之间的 4 位分割将是以下数字位置。

0.2121 最接近 0.1997,即第 10 位。我们不保存 FP32 0.2121,而是存储 10。
典型公式
int4Tensor = roundedValue(totalNumberOfPositions/absmax(inputXTensor))
* FP32WeightsTensor
In the above example
totalNumberOfPositions = 16
值totalNumberOfPositions/absmax(inputXTensor) 称为量化常数
显然,当我们从高分辨率数据类型 FP32 转换为低分辨率数据类型时,进行标准化和量化时会丢失数据。损失并不大,只要输入张量中不存在异常值,这可能会影响absmax()并最终扰乱分布。为了避免这个问题,我们通常通过较小的块独立量化权重,这将使异常值标准化。
反量化:为了对值进行反量化,我们正好相反。
dequantizedTensor = int4Tensor
/roundedValue(totalNumberOfPositions/absmax(inputXTensor))
In the above example
totalNumberOfPositions = 16
4 位 NormalFloat 量化应用于原始模型的权重,LoRA 适配器权重将为 FP32,因为所有训练都将在这些权重上进行。一旦所有训练完成,原始权重将被去量化。

双量化
双量化,通过量化量化常数,进一步减少内存占用。在前面的 4 位 FP4 量化步骤中,我们计算了量化常数。即使这样也可以进行量化以获得更高的效率,这就是我们在双量化中所做的。
由于量化是在块中完成的,为了避免异常值,通常 1 个块中有 64 个权重,我们将有 1 个量化常数。这些量化常数可以进一步量化,以减少内存占用。
假设我们为每个块分组了 64 个参数/权重,每个量化常数占用 32 位,因为它是 FP32。它平均每个参数增加 0.5 位,这意味着我们所说的典型 100 万参数模型至少需要 500,000 位。
通过双量化,我们对这些量化常数应用量化,这将进一步优化我们的内存使用。我们可以采用一组 256 个量化值,并应用 8 位量化。我们可以实现每个参数大约 0.127 位,这使得 1Mil 参数模型的值降至 125,000 位。
计算如下:我们在 256 个块中有 64 个权重,均为 32 位,即 32/(64*256),即 0.001953125
我们有 8 位代表 64 个权重,即 8/64 0.125
如果我们把它加起来 0.125+0.001953125 大约是 0.127
统一内存分页
与上述技术相结合,QLoRA 还利用了 nVidia 统一内存功能,当 GPU 内存不足时,该功能允许 GPU->CPU 无缝页面传输,从而管理 GPU 中突然出现的内存峰值,并帮助解决内存溢出/超限问题。
LoRA 和 QLoRA 是参数高效微调的两种最新兴和最广泛使用的技术。
在下一部分中,我们将实现 QLoRA,在那之前,享受 LLM 的乐趣
希望这有用,留下您的评论和反馈...
暂时再见...
References
- 登录 发表评论
- 557 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago