
简介:为了满足快速增长的需求,Orange Connex于2022年正式引入了Apache Doris,并与Apache Doris构建了新的数据仓库架构。在此过程中,对服务稳定性、查询稳定性和数据同步等各个方面进行了优化。同时,建立了一个基于Apache Doris的数据平台。同时,在使用和优化方面积累了很多经验,我将与大家分享。
作者|付帅| Orange Connex大数据部首席开发者。
背景
简介:为了满足快速增长的需求,Orange Connex于2022年正式引入了Apache Doris,并与Apache Doris构建了新的数据仓库架构。在此过程中,对服务稳定性、查询稳定性和数据同步等各个方面进行了优化。同时,建立了一个基于Apache Doris的数据平台。同时,在使用和优化方面积累了很多经验,我将与大家分享。
Orange Connex(新三板:870366)是一家服务于全球电子商务的科技公司。致力于通过市场分析、系统研发和资源整合,为客户提供物流、金融、大数据等服务产品,提供高质量、全方位的解决方案。作为易趣的合作伙伴,Orange Connex的易趣履行提供了一种特殊的交付方式,包括次日交付、当天处理和延迟截止时间。
随着公司业务的发展,早期基于MySQL的传统数据仓库架构已经无法应对公司数据的快速增长。业务和决策对数据仓库的数据及时性和实时性有着强烈的要求。为了满足快速增长的需求,Orange Connex于2022年正式引入了Apache Doris,并与Apache Doris构建了新的数据仓库架构。在此过程中,对服务稳定性、查询稳定性、数据同步等方面进行了优化。同时,已经建立了一个以Apache Doris为核心的数据平台,并积累了大量的使用和优化经验,我将与大家分享。
数据架构演进
|早期数据仓库架构
公司刚起步时,业务规模相对较小,只有少数数据团队成员。对数据的需求仅限于少量的T+1定制报告。因此,早期的数据仓库架构相当简单。如下图所示,MySQL直接用于构建DM(Data Mart),以开发需要来自需求侧的T+1数据的报告。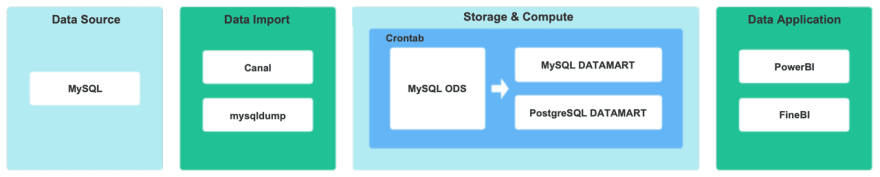
存在的问题
使用MySQL进行数据分析越来越无法满足公司扩张、数据量爆发和数据及时性的要求。
没有数据仓库的划分。烟囱式开发模型数据可重用性差,开发成本高,不能快速响应业务需求。
缺乏对数据质量和元数据管理的控制。
|新的数据仓库基础架构
为了解决旧架构日益突出的问题,适应快速增长的数据和业务需求,Apache Doris于今年正式推出,用于构建新的数据仓库基础设施。
选择Apache Doris的原因:
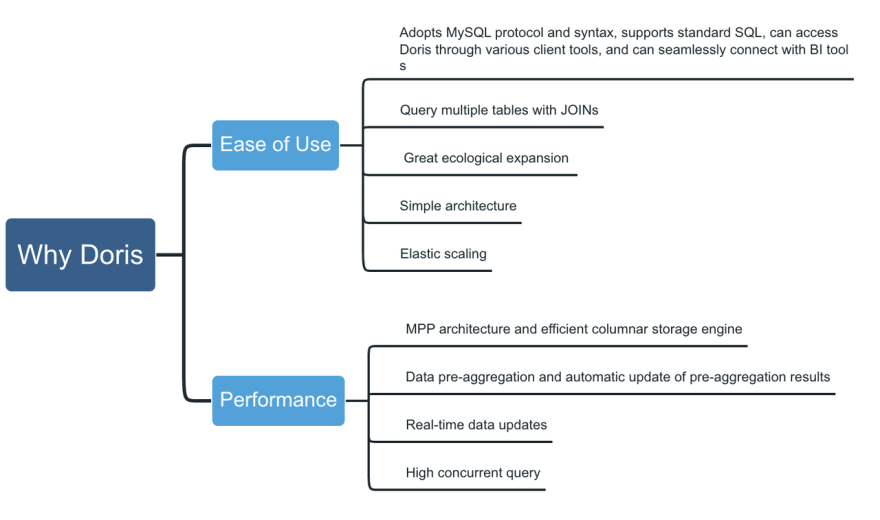
- 易用性-在当前的应用程序中,新技术的引入将面临大量的迁移问题,因此必须考虑产品的可用性问题。Apache Doris对新用户非常友好,迁移成本和维护成本都很低:
- 它采用MySQL协议和语法,支持标准SQL,可以通过各种客户端工具访问Doris,并可以与BI工具无缝连接
- 它可以使用JOIN查询多个表,并在不同的场景中为JOIN提供各种优化
- 生态扩张是巨大的。它既可以有效地批量导入离线数据,也可以实时导入在线流数据。
- 与业界其他流行的OLAP数据库相比,Apache Doris的架构更简单,只有FE(前端)和BE(后端)两个进程。而且它不依赖于任何第三方系统或工具。
它支持弹性伸缩,对部署、操作和维护非常友好。
性能-多表中有很多JOIN操作,对多表JOIN操作和实时查询的查询性能要求极高。Apache Doris基于MPP架构实现,并配有高效的柱状存储引擎,可支持:
- 数据预聚合和预聚合结果的自动更新
- 实时更新数据
- 高并发查询基于上述原因,我们最终选择使用ApacheDoris构建一个新的数据仓库。
架构简介

Apache Doris的数据仓库架构非常简单,不依赖Hadoop组件,并且建设和维护成本较低。
如上面的架构图所示,我们有4种类型的数据源:业务数据MySQL、文件系统CSV、事件跟踪数据和第三方系统API;对于不同的需求,使用了不同的数据导入方法,例如:我们使用Doris Stream Load进行文件数据导入;我们使用DataX Doriswriter进行数据初始化;我们使用Flink Doris连接器进行实时数据同步;在数据存储和计算层,我们使用Doris。当我们为Doris设计层时,我们采用ODS(操作数据存储数据,也称为源层)、细节层DWD、中间层DWM、服务层DWS、应用层ADS作为我们的层设计思想。ODS之后的分层数据通过Dolphin Scheduler调度Doris SQL进行增量和完整的数据更新。最后,上层数据应用程序使用一站式数据服务平台,该平台可以与Apache Doris无缝连接,提供自助分析报告、自助数据检索、数据dashbord和用户行为分析等数据应用服务。
基于Apache Doris的数据仓库架构解决方案可以支持离线和实时应用场景,实时Apache Doris数据仓库可以覆盖80%以上的业务场景。这种架构大大降低了研发成本,提高了开发效率。
当然,在建筑施工过程中也存在一些问题和挑战,我们已经对这些问题进行了相应的优化。
Apache Doris元数据管理和数据行实现方案
在没有元数据管理和数据沿袭之前,我们经常会遇到一些问题。例如,我们想找到一个指标,但不知道指标在哪个表中。我们只能找到相关的开发人员来确认。当然,也有一些开发人员忘记了指标。位置和逻辑案例。因此,只能通过层层筛选来确认,这是非常耗时的。
以前,我们将表格的层次划分、指标和负责人等信息放在Excel表格中。这种维护方法很难保证其完整性,同时也很难维护。当数据仓库需要优化时,无法确认哪些表可以重用,哪些表可以合并。当需要更改表结构或修改指标的逻辑时,无法确定更改是否会影响下游表。
我们经常收到用户的投诉。接下来,我们将介绍如何通过元数据管理和数据沿袭分析解决方案来解决这些问题。
|解决方案
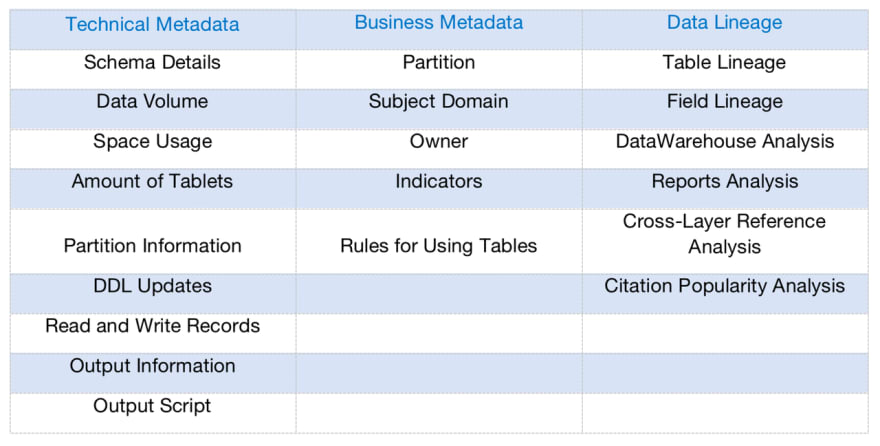
元数据管理和数据沿袭围绕ApacheDoris展开,同时集成DolphinSchedur的元数据。在上图中,右表是技术元数据业务,可以提供元数据指标和数据沿袭分析的数据服务。
我们将元数据分为两类:技术元数据和业务元数据:
- ·技术元数据维护表的属性信息和调度信息
- ·业务元数据维护数据应用过程中约定的口径和规范信息
- 数据沿袭实现了表级沿袭和字段级沿袭:
- ·表级沿袭支持粗略的表关系和跨层引用分析
- ·字段级沿袭支持细粒度影响分析
接下来,我们将介绍元数据管理和数据沿袭的架构和工作原理。
|架构
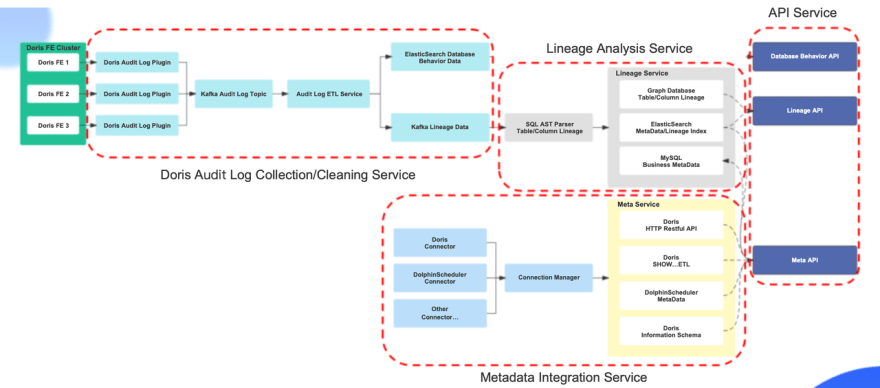
元数据管理和数据行实现解决方案
- ·数据收集:使用Apache Doris提供的审计日志插件Doris audit Plugin进行数据收集
- ·数据存储:定制开发审计日志插件,使用Kafka存储Doris审计日志数据
- ·血统解析:使用Druid进行Doris SQL解析
- ·血缘关系存储:使用星云图存储血统数据
- ·业务元数据:由于业务元数据经常发生CRUD,MySQL用于存储业务元数据信息
- ·搜索数据:使用ElasticSearch存储数据沿袭查询索引和表的搜索索引数据
接下来,我们将介绍该架构的四个组件:审计日志收集和清理服务、数据沿袭分析服务、元数据信息集成服务和应用程序接口服务。
Apache Doris审核日志的收集/清理服务
考虑到如果将数据清理逻辑放在审计日志插件中,当数据清理逻辑发生变化时,可能会出现数据遗漏,从而影响血统分析和元数据管理。因此,我们将审计日志插件的数据收集和数据清理过程解耦。转换后,审计日志插件可以格式化审计日志数据,并将数据发送给Kafka。数据清理服务首先在清理逻辑中添加数据重排逻辑,并对多个审计日志插件发送的数据进行重新排序,以解决数据无序的问题。其次,将非标准SQL转换为标准SQL。尽管Apache Doris支持MySQL协议和标准SQL语法,但仍有一些表构建语句和SQL查询语法与标准SQL不同。因此,我们将非标准SQL转换为MySQL标准语句。最后,数据可以发送到ES和Kafka。
数据谱系分析服务
数据沿袭分析服务使用Druid解析DorisSQL,并通过Druid抽象语法树逐层递归地获取表和字段之间的数据。最后,数据谱系被封装并发送到图形数据库,线性分析查询索引被发送到ES。在分析过程中,技术元数据和业务元数据被发送到相应的存储位置。
元数据信息集成服务
元数据信息集成服务借鉴了Metacat的架构实现。
- ·连接器管理器负责在Apache Doris和Dolphin Scheduler之间创建元数据链接,并支持其他类型数据源访问的后续扩展。
- ·元数据服务负责元数据信息获取的具体实现。Apache Doris元数据信息主要从信息Schema库、Restful API和SHOW SQL的查询结果中获取。DolphinSchedur的工作流元数据信息和调度记录信息是从DolphinSheedur元数据库中获得的。
API服务
我们提供3种类型的API,数据沿袭API、元数据API和数据行为API。
- ·数据沿袭API为表、字段、数据行和影响分析提供查询服务。
- ·元数据API提供元数据查询和字段搜索服务。
- ·数据行为分析API为表结构更改记录、数据读写记录和输出信息提供查询服务。
以上是元数据管理和数据谱系分析架构总体方案的全部内容介绍。
总结
今年,我们使用Apache Doris完成了实时数据仓库的构建。经过半年的使用和优化,Apache Doris已经变得稳定,可以满足我们的生产要求。
新的实时数据仓库极大地提高了数据计算效率和数据及时性。以准时交付业务场景为例,要计算1000w单轨节点的老化变化,在使用Apache Doris之前需要2个多小时的计算,并且计算消耗了大量资源。非峰值计算只能在空闲时段期间执行;Doris之后,只需3分钟即可完成计算。每周更新一次的全链路物流时效表,现在可以每10分钟更新一次最新数据,实现数据实时时效。
得益于Apache Doris的标准化SQL,入门难度小,学习成本低,所有员工都可以参与表的迁移。原始表格是使用PowerBI开发的,这需要对PowerBI有非常深入的了解。学习成本很高,而且开发周期非常长。此外,PowerBI不使用标准SQL,代码可读性差;现在它是基于Doris SQL和自主开发的拖放。表的开发成本直线下降,大多数需求的开发周期从几周下降到几天。
未来计划
未来,我们还将继续推进基于Apache Doris的数据平台建设,并继续优化元数据管理和数据谱系的解析率。考虑到数据沿袭是每个人都想要的应用程序,我们将考虑在优化后将其贡献给社区。
与此同时,我们正在开始构建一个用户行为分析平台,我们也在考虑使用Apache Doris作为核心存储和计算引擎。目前,Apache Doris在一些分析场景中支持的功能还不够丰富。例如,在有序窗口漏斗分析场景中,尽管Apache Doris支持window_funnel函数,但尚未支持计算每一层漏斗变换所需的Array相关计算函数。幸运的是,即将推出的Apache Doris 1.2版本将包括Array类型和相关功能。相信Apache Doris将在未来越来越多的分析场景中实现。
作者简介:傅帅,Orange Connex(中国)有限公司有限公司数字团队大数据研发经理,负责数字团队的数据平台和OLAP引擎的应用。
最新内容
- 1 day 2 hours ago
- 1 week 2 days ago
- 1 week 6 days ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago