
什么是DataHub?
DataHub由LinkedIn构建,是一个元数据驱动的平台,可帮助您为业务实现数据编目、发现、可观察性和治理。它为您提供了所有技术和逻辑元数据的360º视图,使您能够查找和使用您所掌握的所有数据。
领英为什么要建立DataHub?
领英在构建、扩展和开源工具和技术方面有着良好的记录,如Kafka, Pinot, Rest.li, Gobblin,以及最近的 Venice等。
在DataHub之前的几年,LinkedIn open-sourced WhereHows,这是他们“大数据生态系统的数据发现和谱系平台”。在大规模构建和使用WhereHows的过程中,领英决定创建DataHub。
随着资源和数据资产的增加,可能会出现更大程度的混乱,尤其是当您有复杂的数据管道和作业时。为了防止这种混乱,并确保他们的所有数据都是可搜索、可发现和可理解的,领英需要有一个具有新架构的全面数据目录
- 具有模块化、面向服务的设计
- 支持元数据接收的推送和拉取选项
- 能够与现代数据堆栈中的工具进行深度集成
- 能够通过全文搜索支持搜索和发现
- 集成了端到端细粒度数据谱系
- 具有数据隐私和安全方面的数据治理能力
DataHub的一些功能是什么?
DataHub主要是LinkedIn的数据目录,用于搜索和发现用例。除了核心数据编目功能外,DataHub还提供了细粒度数据沿袭、联邦数据治理等功能。让我们来谈谈领英的数据编目工具DataHub的一些功能。
- 搜索和发现
- 端到端数据沿袭
- 数据治理
搜索和发现
DataHub的搜索和发现功能由全文搜索引擎支持,该引擎对从基本技术元数据到逻辑元数据(如标签和分类)的所有内容进行索引。
该搜索引擎由Elasticsearch支持,它将所有数据存储在文档中,然后将这些文档作为反向索引进行索引,以实现超快的搜索体验。对于编程访问,DataHub还通过GraphQL提供对全文搜索、跨实体搜索和跨沿袭搜索的访问。
DataHub中的搜索功能可通过直观的UI访问,您可以使用该UI搜索DataHub的所有数据资产,包括资产名称、描述、所有权信息、细粒度属性等。
想要更结构化的搜索和发现方法的用户可以使用筛选器和高级(自定义)筛选器来细化全文搜索的结果。为了获得更高级的搜索查询体验,您可以混合使用模式匹配、逻辑表达式和筛选。
端到端数据沿袭
DataHub使用基于 file-based lineage来存储和接收来自各种平台、数据集、管道、图表和仪表板的数据沿袭信息。您需要以规定的基于YAML的沿袭文件格式存储沿袭信息。
下面是一个沿袭YAML文件的示例,该文件包含多个数据资产的沿袭信息。DataHub允许像dbt和Superset这样的集成自动将沿袭数据摄取到系统中。您还可以使用Airflow的沿袭API来摄取DataHub中的沿袭数据。
当对代码进行更改时,了解数据沿袭是非常关键的,这些更改可能会破坏上游或下游的脚本、作业、DAG等。DataHub社区多次投票支持的一个功能是列级数据沿袭,这对于业务用户了解数据在进入消费层的过程中是如何变化和转换的非常重要。
随着其最新版本的发布,DataHub已开始支持列级数据沿袭。有关更多信息,请参阅细粒度沿袭的文档。
数据治理
领英已经考虑了一些关于模式保存、进化和注释的关键问题。领英使用PDL(飞马定义语言)和Avro的组合,这两种语言可以用于它们之间的无损转换,也可以用于存储和流媒体目的。
许多其他数据定义语言,如基于SQL的DDL、Thrift和Protobuf,也可以进行修改,以支持高级注释和无损转换。尽管如此,领英之所以选择这两个项目,可能是因为之前在Rest.li、Avro2TF和Kafka等其他项目上的经验。
这种选择不仅有助于更好地进行数据编目,而且有助于提高数据沿袭和治理能力,具有以下功能:
- 基于角色的访问控制
- 标签、词汇表术语和域
- 行动框架
基于角色的访问控制
DataHub允许一种相对细粒度的方法,使用RBAC和存储在DataHub系统中的元数据的组合来控制对数据资产的访问。
对于身份验证和授权,DataHub支持基于角色的访问控制机制(已经实现了初始RFC的部分内容)。您可以强制执行不同类型的策略,以便对不同的资源类型提供不同的权限集。您可以将这些策略附加到用户或组。
标签、词汇表术语和域
在数据治理的业务方面,DataHub允许您将资产分配给所有者并使用特定于业务的元数据,如标签、词汇表术语和域,从而实现更好的数据治理。
行动框架
DataHub的Actions Framework使您能够出于可观察性的目的触发外部工作流,从而增强您的数据治理体验。
了解DataHub体系结构
领英工程博客上的一篇博客文章解释了三代元数据应用程序。它解释了WhereHows如何来自第一代元数据应用程序架构,以及DataHub如何成为由细粒度微服务定义的第三代架构的少数实现之一,其中事件和日志为元数据的获取和消费提供了动力。
三代元数据平台架构
以下是领英定义的三代元数据平台的摘要:
- 第一代架构-基于爬网的元数据系统,平台中的所有内容都由一个包含前端、后端、搜索、关系等的整体提供服务。例如Amundsen和Airbnb Data Portal。
- 第二代体系结构——SOA(面向服务的体系结构),具有一个基于推送的元数据服务层,与其他内容分开,但可以通过API访问。例如马尔克斯。
- 第三代架构-更细粒度的服务设计,元数据来源于数据源的事件和日志,并支持流式传输和基于推送的API。示例包括DataHub, Apache Atlas, and Egeria.
现在让我们更详细地了解一下DataHub的体系结构。
DataHub体系结构概述
根据第三代元数据平台架构规范的规定,DataHub使用不同的服务来获取和服务元数据。
所有服务都集成了GraphQL、RESTAPI和Kafka等技术。为了服务于搜索、发现和治理等不同的用例,DataHub需要在内部支持不同的数据访问模式,而这反过来又需要专门构建的数据库,如MySQL、Elasticsearch和neo4j。
这三个数据源构成DataHub的服务层,并满足来自前端、API集成和其他下游应用程序的所有请求。
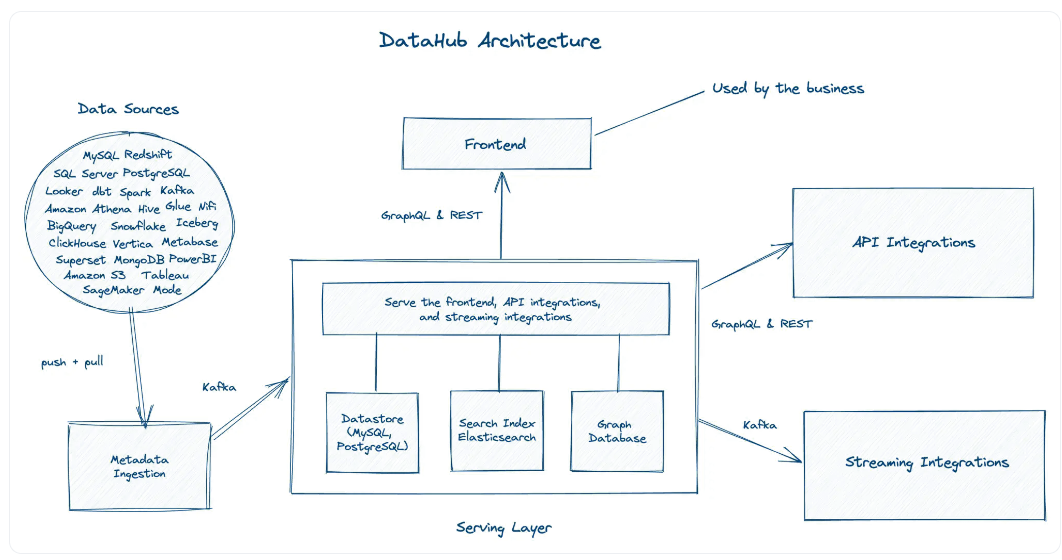
High level understanding of DataHub architecture. Image source: Atlan
在上图中,您可以看到DataHub有三个范围广泛的层,即来源层、服务层和消费层。源层从一个或多个数据源中获取数据。
来自这些源的数据被提取并推送到元数据接收,然后由Kafka提取,以便与服务层中专门构建的数据存储共享。该层将请求引导到正确类型的数据存储,以确保最快的响应时间。
消费层包括业务、通过前端应用程序消费元数据,以及使用GraphQL、REST API和Kafka消费数据的其他系统集成。
如何安装DataHub
安装DataHub进行尝试非常简单。您可以从官方Docker镜像安装DataHub,并在几分钟内启动并运行。如果你想在生产中部署DataHub,你可以在任何云平台上部署它,比如AWS或带有Docker和Kubernetes的谷歌云。以下是关于如何开始使用DataHub的详细教程:
Docker上的DataHub入门
DataHub替代方案
DataHub还有其他几种开源替代方案。有些人采取了非常不同的方法来解决相同的搜索、发现和治理问题。 Lyft’s Amundsen和优步的Databook启发的OpenMetadata 就是这样两种开源数据编目工具。我们花了一些时间对这些工具进行了全面的比较。查看以下文章:
Linkedin DataHub: Related reads
- Explore LinkedIn DataHub: A hosted demo environment with pre-populated sample data
- DataHub tutorial: We will guide you through the steps required to configure and install LinkedIn DataHub.
- Amundsen vs DataHub: What is the difference? Which data discovery tool should you choose?
- Open-source data catalog software: 5 popular tools to consider in 2023
- Enterprise metadata management and its importance in the modern data stack
最新内容
- 8 hours ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago