
在Lakehouse上使用数据仓库和星形模式
lakehouse是一种新的数据平台范式,它结合了数据湖和数据仓库的最佳功能。它被设计为一个大型企业级数据平台,可以容纳许多用例和数据产品。它可以作为一个统一的企业数据存储库,用于您的所有:
- 数据域,
- 实时流式传输用例,
- 数据集市,
- 不同的数据仓库,
- 数据科学功能存储和数据科学沙盒,以及
- 部门自助服务分析沙盒。
考虑到用例的多样性,不同的数据组织原则和建模技术可能适用于lakehouse上的不同项目。从技术上讲,Databricks Lakehouse平台可以支持许多不同的数据建模风格。在本文中,我们旨在解释lakehouse的青铜/白银/黄金数据组织原则的实现,以及不同的数据建模技术如何适用于每一层。
什么是Data Vault?
与Kimball和Inmon方法相比,Data Vault是一种更新的数据建模设计模式,用于构建用于企业规模分析的数据仓库。
数据仓库将数据组织为三种不同类型:集线器、链路和卫星。集线器代表核心业务实体,链接代表集线器之间的关系,卫星存储有关集线器或链接的属性。
Data Vault专注于敏捷数据仓库开发,其中可扩展性、数据集成/ETL和开发速度非常重要。大多数客户都有一个着陆区、Vault区和一个数据集市区,这些区域对应于青铜层、银层和金层的Databricks组织模式。集线器、链接和卫星表的Data Vault建模风格通常非常适合Databricks Lakehouse的Silver层。
在Data Vault Alliance了解有关Data Vault建模的更多信息。
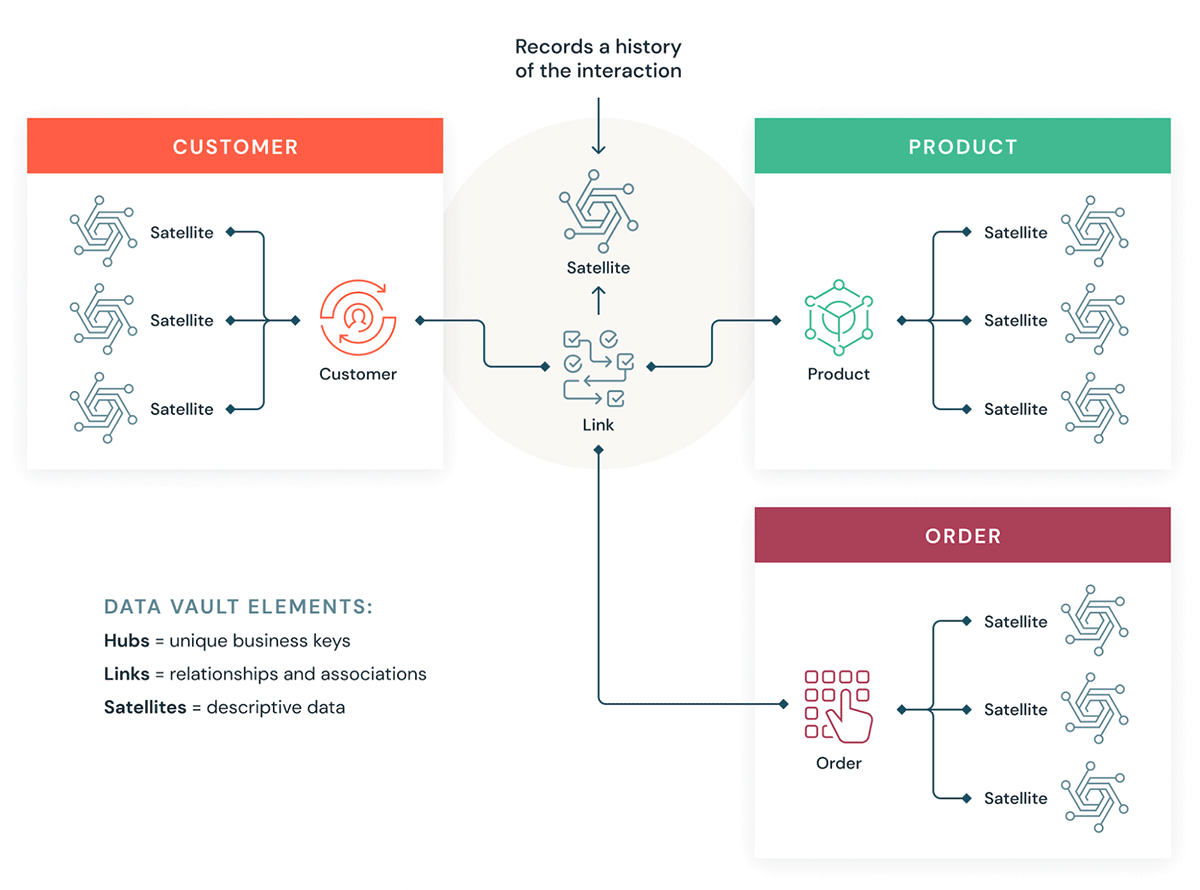
A diagram showing how Data Vault modeling works, with hubs, links, and satellites connecting to one another.
什么是维度建模?
维度建模是一种自下而上的方法,用于设计数据仓库,以便对其进行分析优化。维度模型用于将业务数据反规范化为维度(如时间和产品)和事实(如金额和数量的交易),不同的主题领域通过一致的维度连接,以导航到不同的事实表。
最常见的维度建模形式是星形模式。星型模式是一种多维数据模型,用于组织数据,使其易于理解和分析,并且运行报告非常简单直观。Kimball风格的星型模式或维度模型几乎是数据仓库和数据集市中表示层的黄金标准,甚至是语义层和报告层。星型模式设计针对查询大型数据集进行了优化。
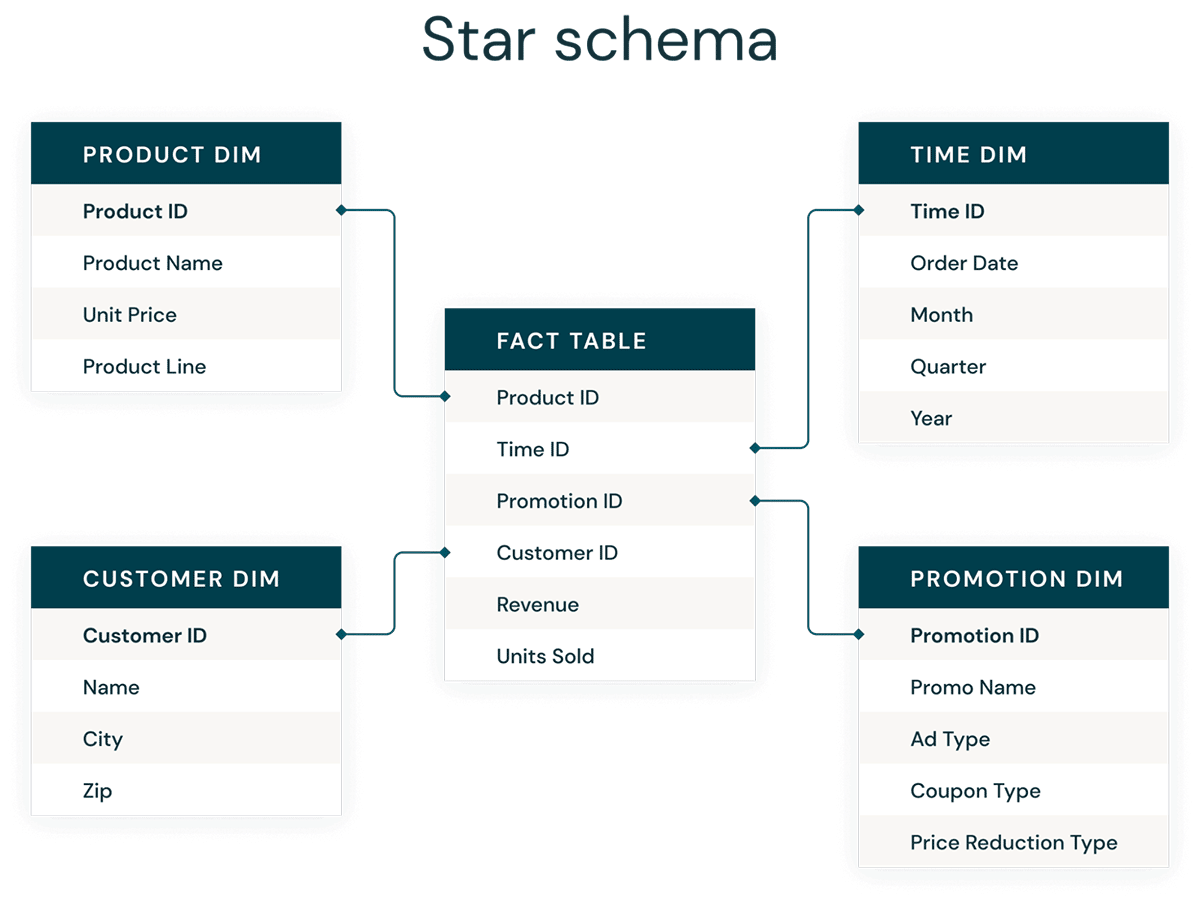
A star schema example
规范化Data Vault(写优化)和非规范化标注模型(读优化)数据建模样式都在Databricks Lakehouse中占有一席之地。Data Vault在Silver层中的集线器和附属节点用于加载星形模式中的维度,Data Vault的链接表成为加载维度模型中事实数据表的关键驱动表。从Kimball Group了解有关维度建模的更多信息。
Lakehouse各层的数据组织原则
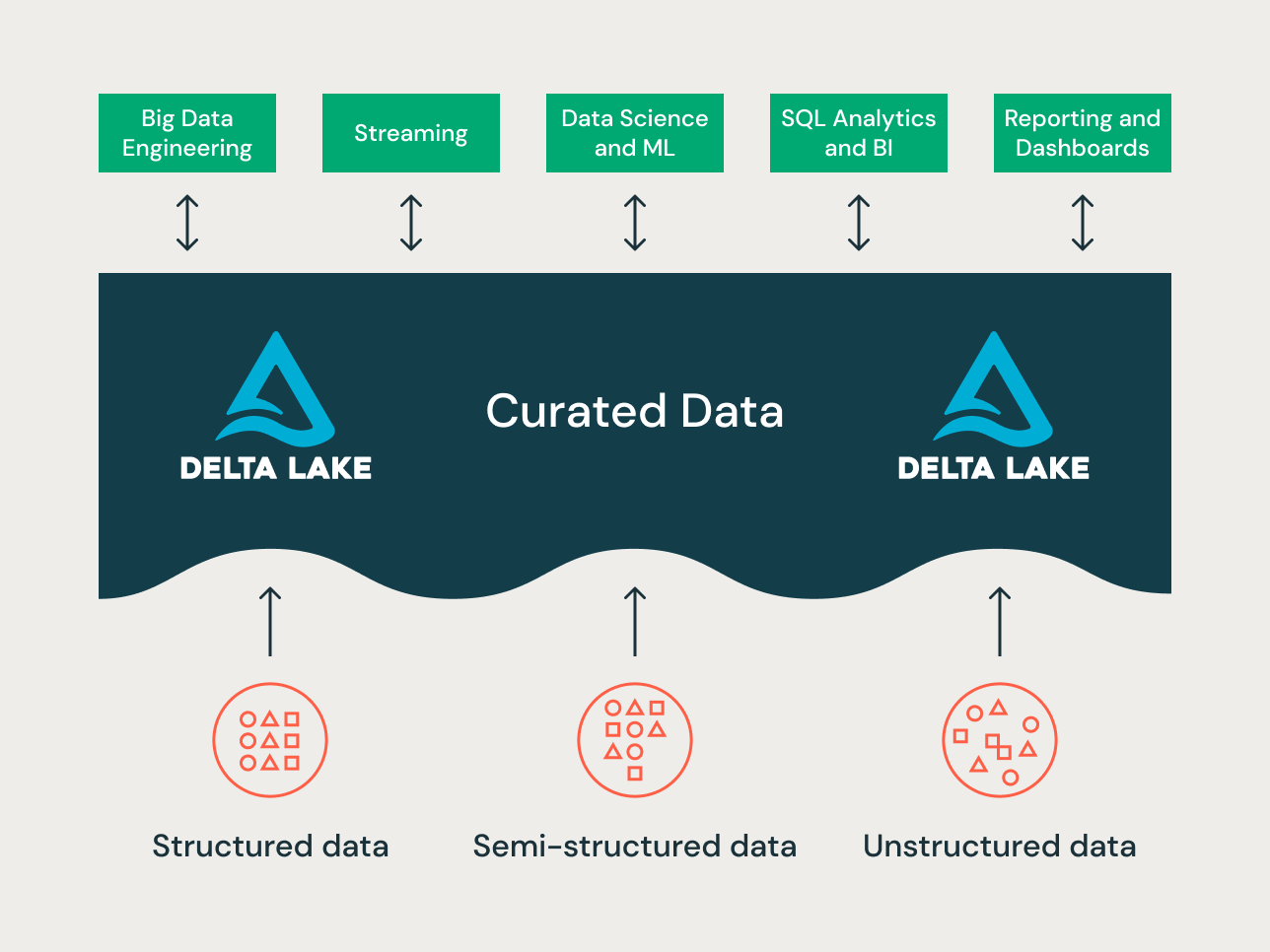
现代lakehouse是一个包罗万象的企业级数据平台。它具有高度的可扩展性和性能,适用于各种不同的用例,如ETL、BI、数据科学和流式传输,这些用例可能需要不同的数据建模方法。让我们看看一个典型的湖屋是如何组织的:
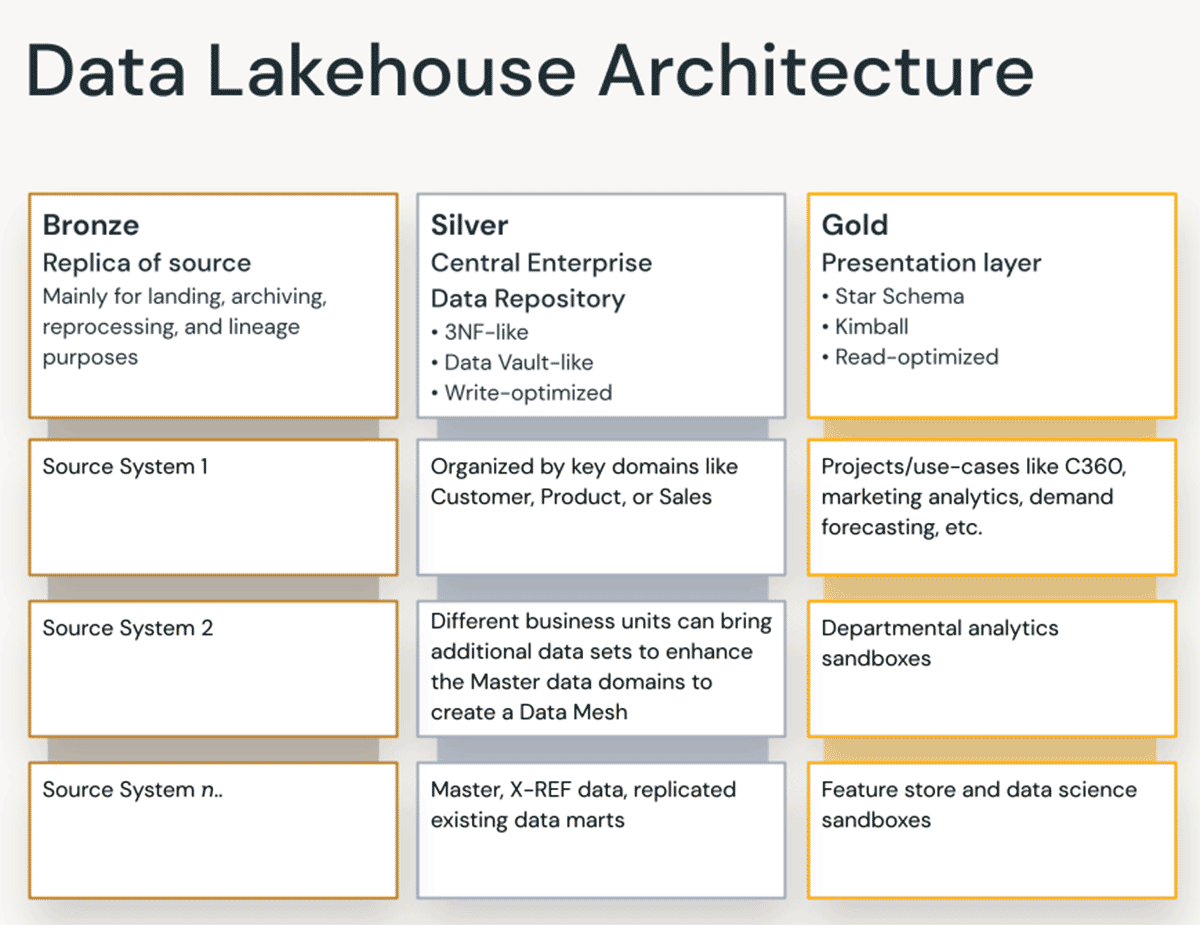
A diagram showing characteristics of the Bronze, Silver, and Gold layers of the Data Lakehouse Architecture
青铜层——登陆区
青铜层是我们从源系统获取所有数据的地方。除了可以添加以捕获加载日期/时间、进程ID等的可选元数据列之外,该层中的表结构“原样”对应于源系统表结构。该层的重点是更改数据捕获(CDC),以及提供源数据历史档案(冷存储)、数据沿袭、可审核性,并在需要时进行再处理,而无需重新读取源系统中的数据。
在大多数情况下,最好将Bronze层中的数据保持为德尔塔格式,以便后续从Bronze层读取ETL具有性能,并且您可以在Bronze中进行更新以写入CDC更改。有时,当数据以JSON或XML格式到达时,我们确实会看到客户将其以原始源数据格式着陆,然后将其更改为Delta格式。因此,有时,我们会看到客户将逻辑青铜层显示为物理着陆和集结区。
在着陆区中以原始源数据格式存储原始数据也有助于保持一致性,即通过不支持Delta作为本地汇点的接收工具接收数据,或者源系统将数据直接转储到对象存储中。这种模式也与自动加载器摄取框架非常一致,其中源将数据降落在原始文件的着陆区,然后Databricks自动加载器将数据转换为增量格式的暂存层。
银层--企业中央存储库
在Lakehouse的银层中,来自青铜层的数据被匹配、合并、一致和清理(“刚好”),这样银层就可以提供其所有关键业务实体、概念和交易的“企业视图”。这类似于企业运营数据存储(ODS)或数据网格的中央存储库或数据域(例如主客户、产品、非重复事务和交叉引用表)。该企业视图将来自不同来源的数据汇集在一起,并为特别报告、高级分析和ML提供自助分析。它还可作为部门分析师、数据工程师和数据科学家的来源,通过企业和部门数据项目在黄金层中进一步创建数据项目和分析,以解决业务问题。
在Lakehouse数据工程范例中,与传统的提取-转换-加载(ETL)相比,通常遵循(提取-加载-转换)ELT方法。ELT方法意味着在加载Silver层时只应用最小或“刚好足够”的转换和数据清理规则。所有“企业级”规则都应用于银层,而项目特定的转换规则则应用于金层。在Lakehouse中获取和交付数据的速度和灵活性在这里是优先考虑的。
从数据建模的角度来看,Silver Layer有更多类似于第三范式的数据模型。类似Data Vault的写性能数据体系结构和数据模型可以在该层中使用。如果使用Data Vault方法,原始Data Vault和Business Vault都将适合湖的逻辑Silver层,时间点(PIT)表示视图或物化视图将显示在Gold层中。
黄金层——展示层
在黄金层中,可以根据维度建模/金博尔方法构建多个数据集市或仓库。如前所述,与银层相比,金层用于报告,并使用更多的非规范化和读取优化数据模型,连接更少。有时,黄金层中的表可以完全非规范化,通常是如果数据科学家希望以这种方式为特征工程提供算法的话。
将数据从银层转换为金层时,将应用“特定于项目”的ETL和数据质量规则。最终展示层,如数据仓库、数据集市或数据产品,如客户分析、产品/质量分析、库存分析、客户细分、产品推荐、营销/销售分析等,都在该层中交付。Kimball风格的基于星模式的数据模型或Inmon风格的数据集市适合Lakehouse的这一黄金层。用于自助分析的数据科学实验室和部门沙盒也属于黄金层。
Lakehouse数据组织范式
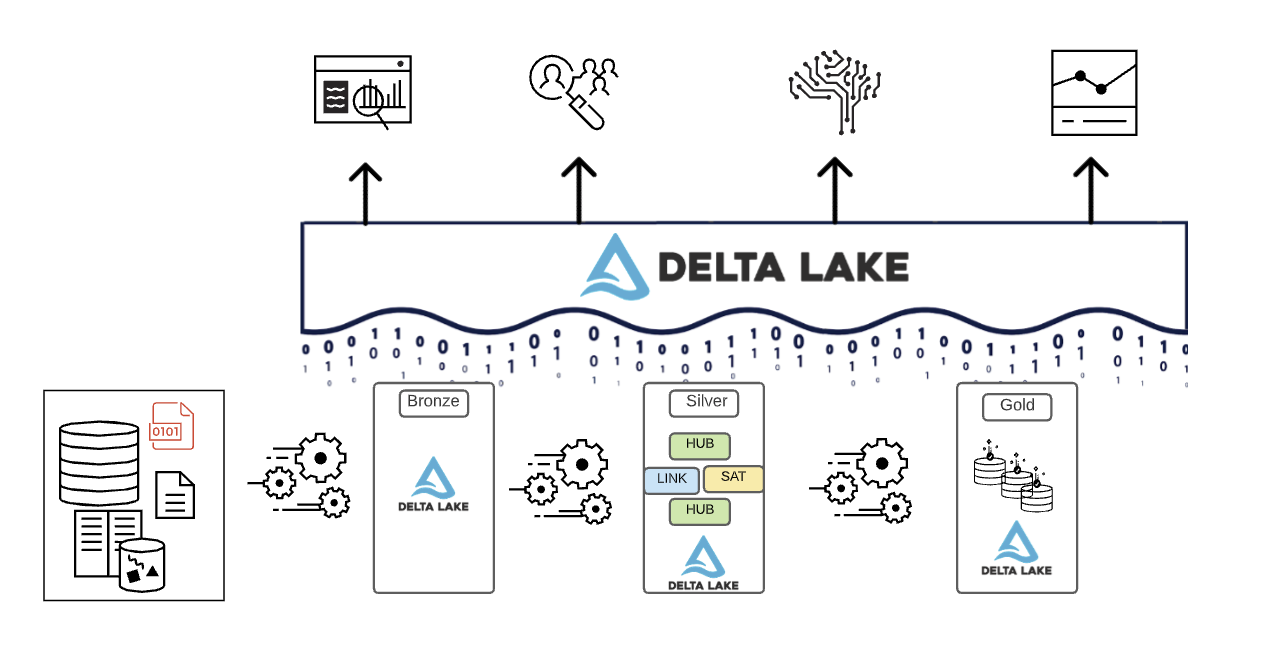
总之,数据是在Lakehouse的不同层中移动时进行整理的。
- 青铜层使用源系统的数据模型。如果数据以原始格式着陆,则在该层中将其转换为DeltaLake格式。
- Silver层首次将来自不同来源的数据汇集在一起,并对其进行整合,以创建数据的企业视图——通常使用更规范化、写优化的数据模型,这些模型通常类似于第三范式或类似于data Vault。
- 金层是比银层具有更多非规范化或扁平化数据模型的表示层,通常使用Kimball风格的维度模型或星形模式。黄金层还包含部门和数据科学沙盒,以实现整个企业的自助分析和数据科学。提供这些沙盒和它们自己独立的计算集群可以防止业务团队在Lakehouse之外创建自己的数据副本。
这种Lakehouse数据组织方法旨在打破数据孤岛,将团队聚集在一起,并使他们能够在一个平台上通过适当的治理进行ETL、流媒体、BI和AI。中央数据团队应该是组织创新的推动者,加快新的自助服务用户的加入,以及并行开发许多数据项目,而不是数据建模过程成为瓶颈。Databricks Unity目录在Lakehouse上提供搜索和发现、治理和沿袭,以确保良好的数据治理节奏。
现在就用Databricks SQL构建您的数据仓库和星型模式数据仓库。
Further reading:
- Five Simple Steps for Implementing a Star Schema in Databricks With Delta Lake
- Best practices to implement a Data Vault model in Databricks Lakehouse
- Dimensional Modeling Best practice & Implementation on Modern Lakehouse
- Identity Columns to Generate Surrogate Keys Are Now Available in a Lakehouse Near You!
- Load an EDW Dimensional Model in Real Time With Databricks Lakehouse
最新内容
- 1 day 19 hours ago
- 2 weeks 1 day ago
- 3 weeks 2 days ago
- 3 weeks 6 days ago
- 2 months 2 weeks ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago