
每个人都在谈论ChatGPT、生成性人工智能模型及其可能对白领工作、软件工程(如Github Co-Pilot)以及现代数据堆栈中更贴近家庭的数据角色产生的影响。我们甚至可以使用生成人工智能为这个博客创建一个开场白,让插画师放心,至少他们的工作暂时相对安全。
Rittman Analytics是一家典型的“精品”现代数据堆栈咨询公司,有包括我在内的8名团队成员,我们所有人都是每天与数据和客户合作的实践从业者,提供从战略建议到实施和用户支持的一系列服务。
我们通常在任何时候都有大约六个客户项目同时运行,花大量时间与客户进行面对面(现在通常是虚拟的)会议,在我们这边进行项目管理,并负责确保整个项目按预期交付。
我们为自己的技能和客户的推荐感到骄傲……但在他们的工作被淘汰之前,送奶工、公交车售票员、商业街旅行社、水蛭收集者、蟾蜍医生和锣农也是如此。那么,最新版本的OpenAI大型语言模型交互式聊天服务ChatGPT-4能否取代分析工程师的角色,甚至取代对分析顾问的需求?
我在OpenAI网站上开始了一个新的ChatGPT会话,并为一家咨询公司的分析项目做了一个启动简报。
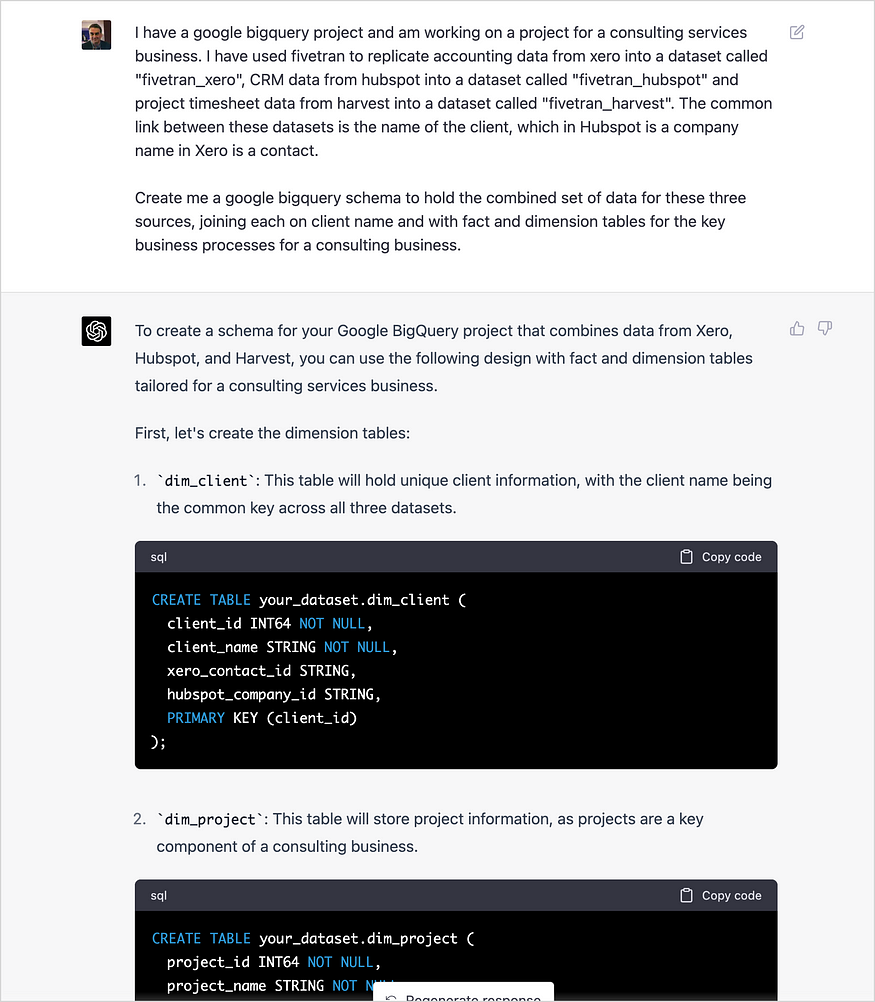
ChatGPT直接定义了一个合理的启动模式,尽管它一开始就犯了一个基本的SQL语法错误。事实上,BigQuery现在确实支持主键和外键约束,但没有强制执行它们,而是使用它们向BigQuery的查询计划器提供额外的模式元数据,而这个新DDL功能的正确语法是primary key(column_name)NOT ENFORCED。
ChatGPT方法中另一个更微妙但更长期、更显著的不足之处是,它只对能够满足用户字面请求的最低限度的表模式进行建模,而不是一个更全面的模式,无论是体验还是进一步的质疑,都会导致您创建该模式。但是,除了每个表的DDL中的语法错误外,它确实为所给出的请求创建了一个合理的模式。
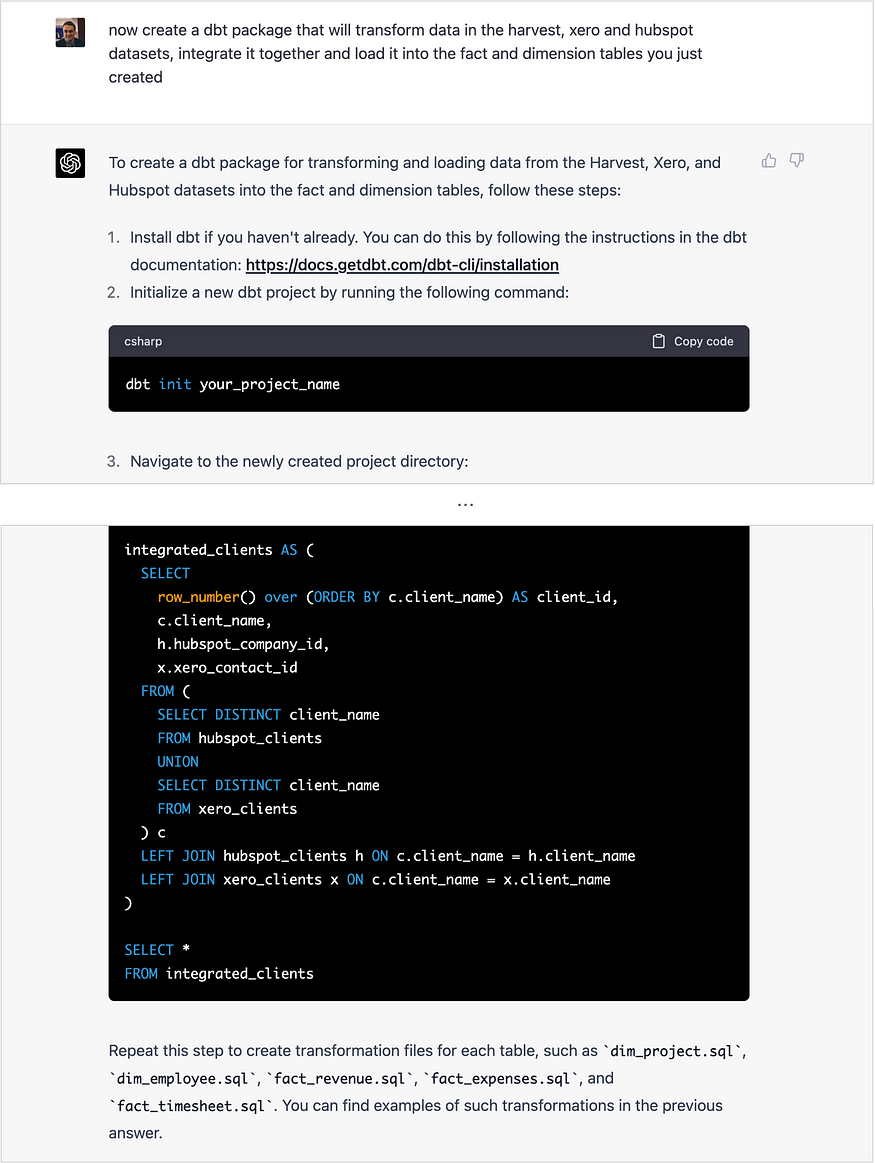
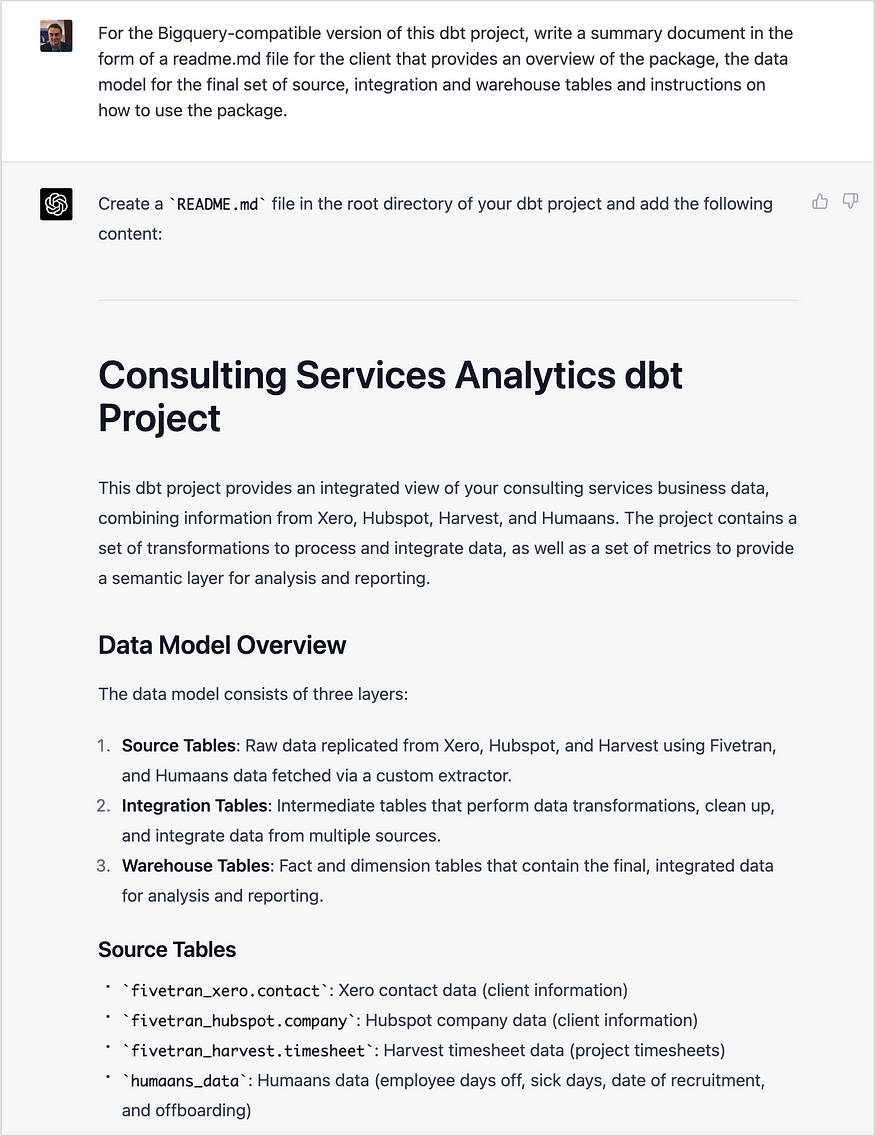
然后,我要求ChatGPT创建一个dbt包,该包从每个Fivetran源的暂存数据集中获取原始数据,对其进行集成和转换,然后将其加载到它刚刚定义的架构的事实表和维度表中。
然后,我给ChatGPT一个更具挑战性的任务,即不仅在客户端名称完全匹配的情况下,而且在它们听起来相似的情况下消除重复。当使用Hubspot等来源的公司名称时,这通常是一项要求。在Hubspot中,销售代表在记录新的销售交易时输入单个公司名称的许多变体,但您希望在查看该账户的交易历史记录时,这些交易解析为单个公司名称。
ChatGPT自信地提出使用BigQuery的Jaro-Winkler字符串相似性函数来实现这一点,并为我重写了dbt代码。

除了…BigQuery没有JARO_WINKLER字符串函数。在写这篇博客时,你能得到的最接近的方法是创建一个UDF(用户定义函数),据我所知,唯一具有Jaro Winkler功能的数据库服务器是Oracle数据库,即使这样,它也是Oracle UTL_MATCH函数的一个参数,而不是SQL函数本身。
事实上,ChatGPT似乎已经发明了自己的BigQuery SQL函数,然后自信地将其作为解决方案交给了我,但这段代码无法运行,任何没有BigQuery开发经验的人都不知道哪里出了问题,下一步该怎么办。
然后,我继续提出进一步的请求,公平地说,ChatGPT很好地处理了这些请求,清楚地了解了每个来源提供的一组列,以及它们如何映射到发票、发票ID和发票日期等常见概念,以及已付款、未付款和未付款发票等概念。
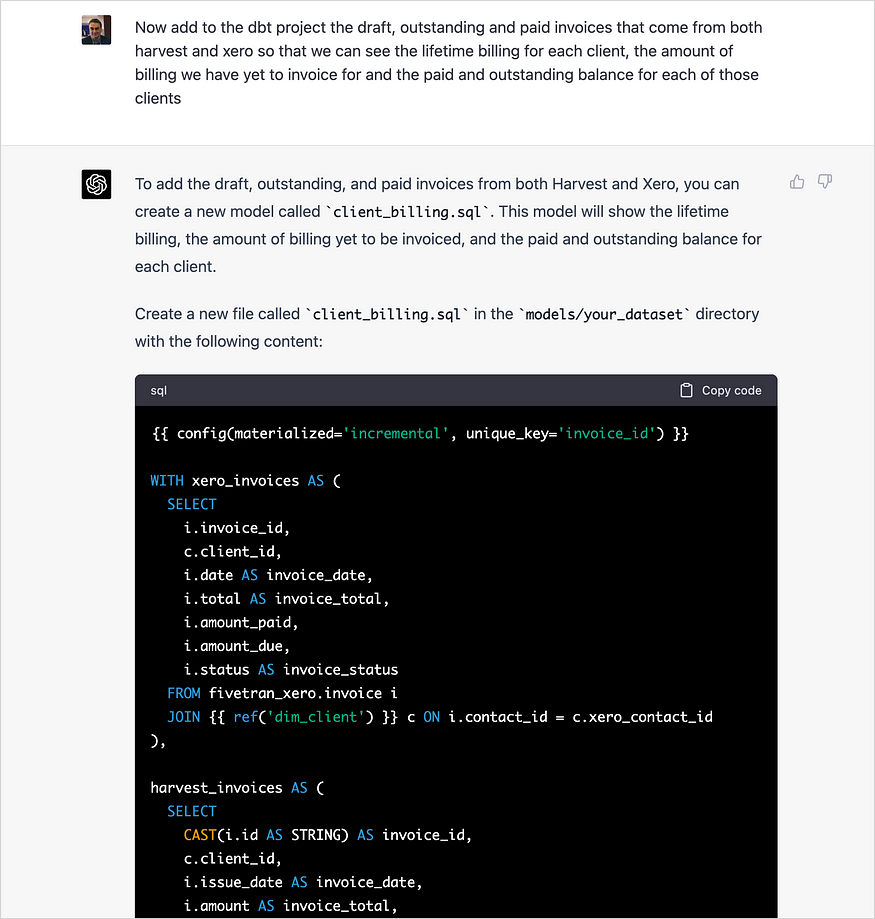
当我要求它添加员工利用率的计算时,它也毫不退缩,尽管在实践中,我们通常会在软件包中添加一个日期脊柱表,以帮助计算所有日子的总产能,而不仅仅是员工实际工作过的产能。
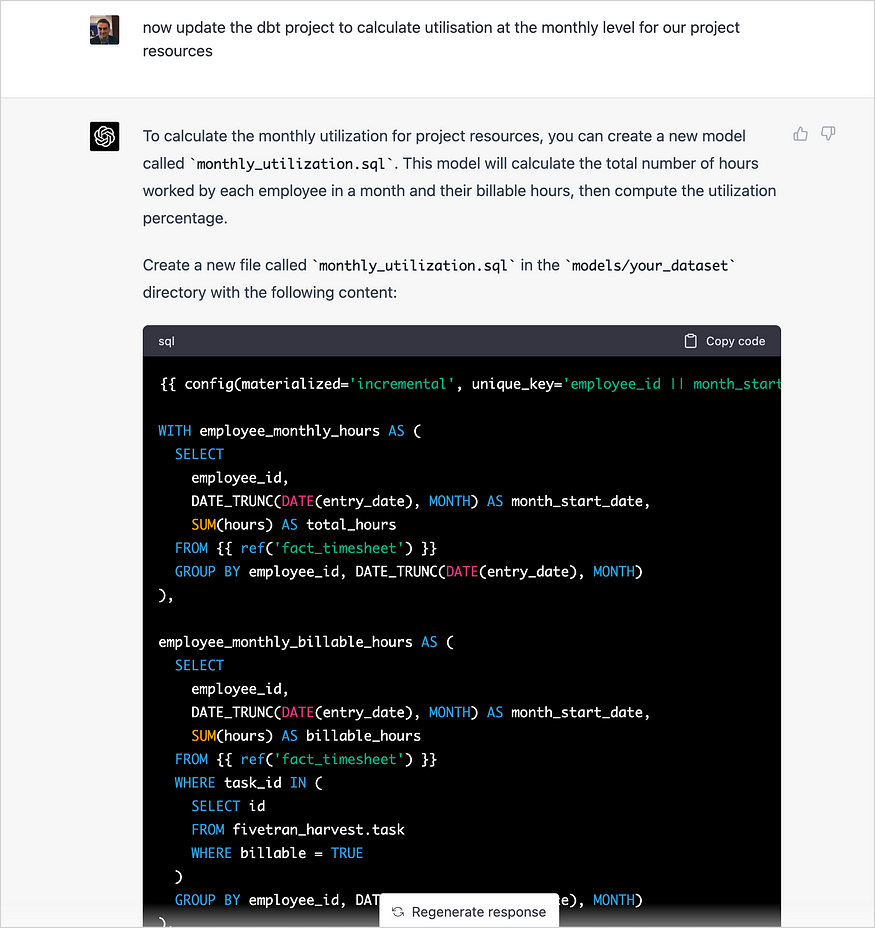
我甚至要求ChatGPT从我们的HRMS系统Humaans引入数据,建议它使用该服务的REST API为数据创建一个数据提取器,然后将其加载到我们的BigQuery数据库中。然后,它提供了其解决方案的概述,并生成Python代码以连接到Humaan的REST API,下载相关数据,然后使用其Python-客户端将其加载到BigQuery中。
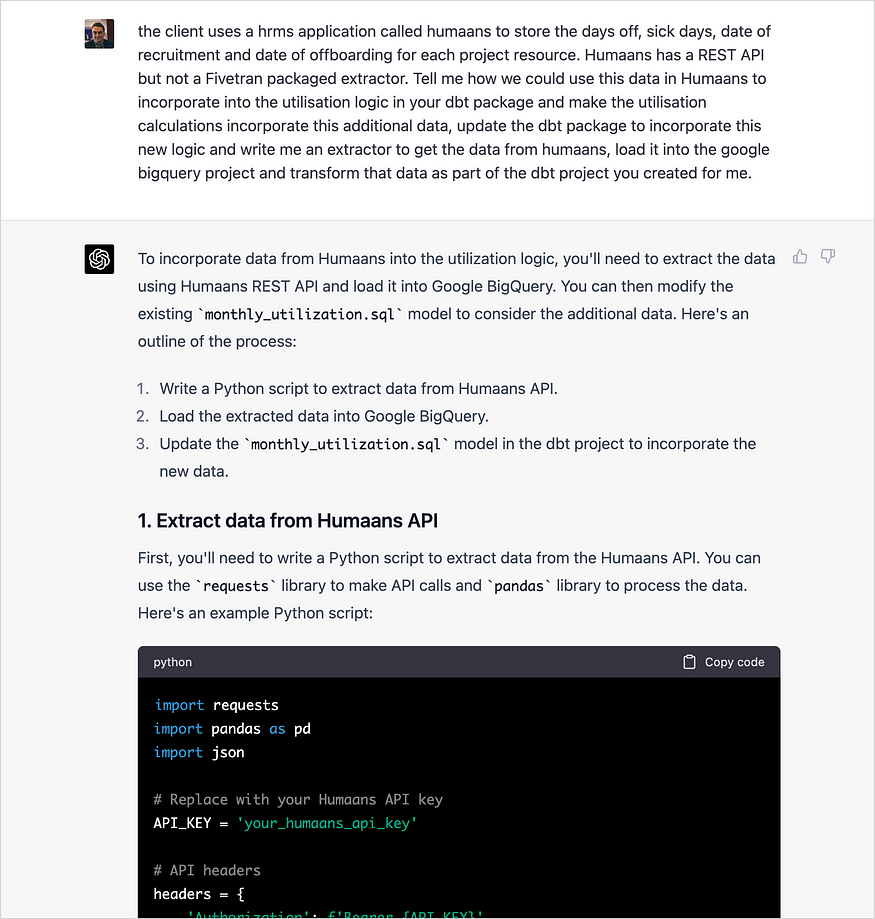
它不是最健壮的解决方案,也没有考虑如何调度和编排Python脚本或dbt包,但它是一个很好的初始原型。
更重要的是,如果你是一个在Fiverr等网站上从事dbt工作的自由职业者,或者是一个通过大量生成由解决方案架构师严格指定的dbt代码来学习专业的初级开发人员,那么ChatGPT很可能会做得更好。
它甚至可以在生成的代码中包含我们的命名标准。
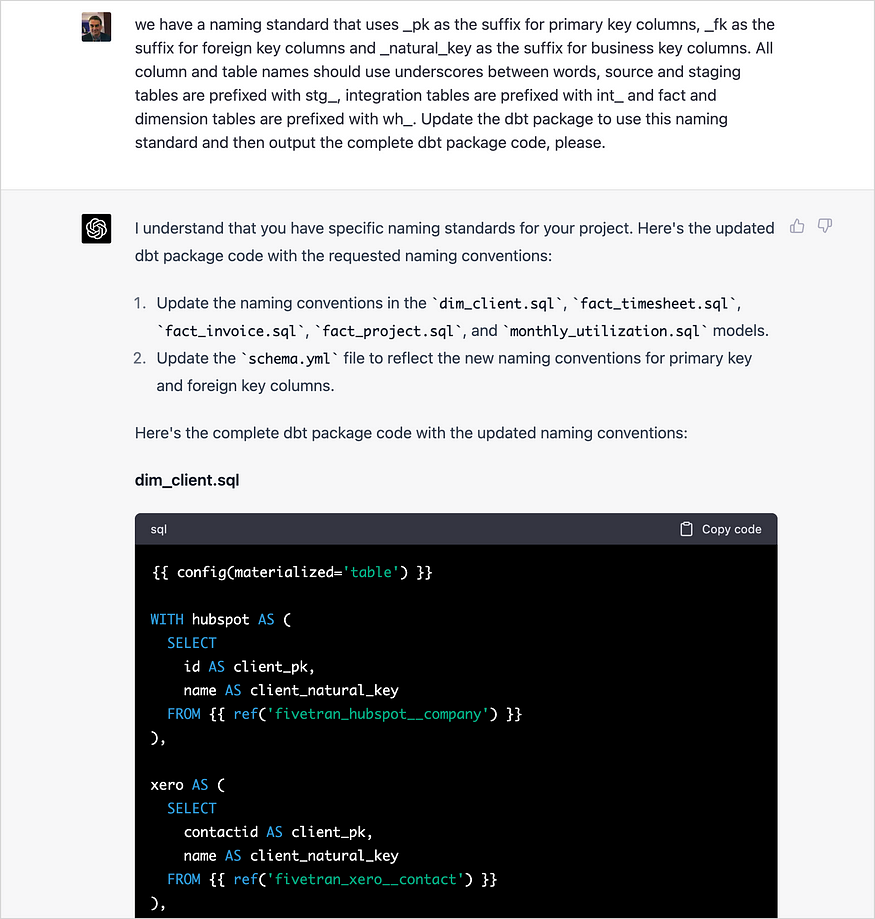
目前,尽管ChatGPT在同一个整体聊天会话中保留了早期指令的上下文,但我们需要在我们启动的任何新聊天会话中提供这些标准的详细信息。
然而,在不久的将来,咨询公司和其他组织将有可能创建自己的LLM(大型语言模型),其中包含特定领域的培训数据,如我们位于私人git repos中的dbt代码库,以及我们的命名标准、标准操作程序和解决方案手册,这些共同构成了我们服务背后的价值和IP。
有些事情,比如添加到dbt中的最新功能,会使仅在某个时间点收集的数据上训练的GPT模型出错。当我要求它在包中已经创建的模型上添加一个dbt语义层时,它最初会根据暴露、dbt中的度量和语义层的前置光标给出一个答案,然后提出一个SQL视图,为该暴露提供一组非规范化的列。
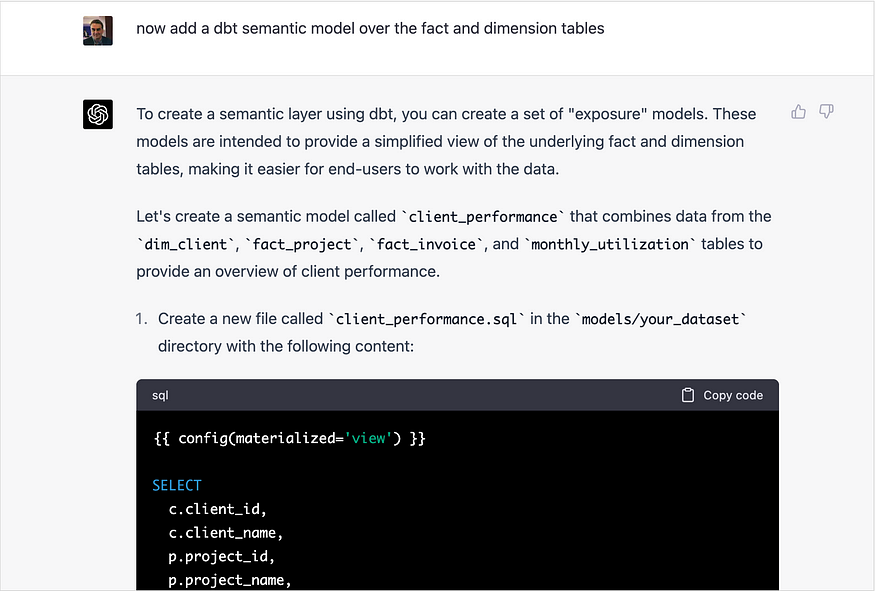
然后,我纠正了它,并提出了一个使用dbt最新版本中引入的度量功能的解决方案,对此,ChatGPT首先做出道歉回应,然后是一个修改后的解决方案——这对于将度量和语义层合并到包中来说是一个不错的开端。
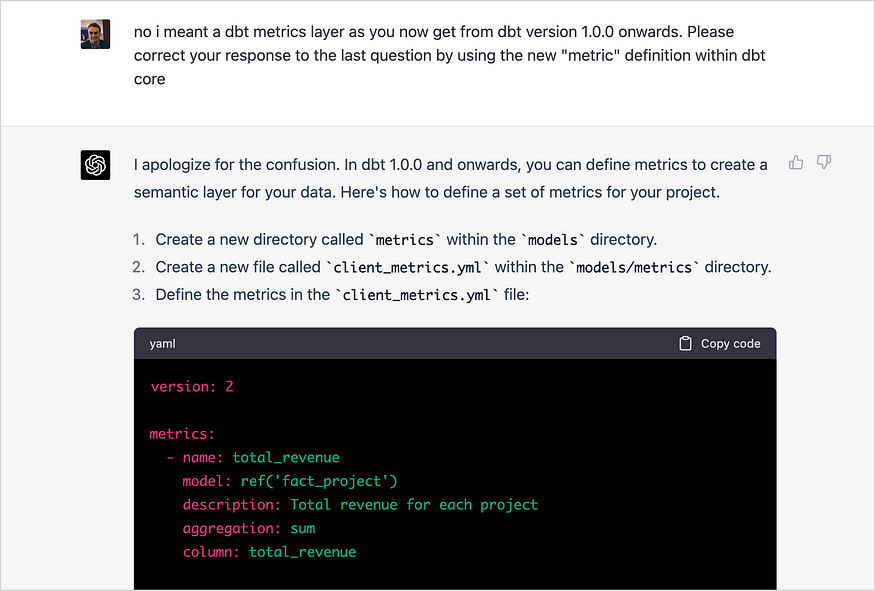
然而,就我们这样的dbt首选合作伙伴的响应而言,这确实不够,因为这里需要考虑的不仅仅是实现这一特定功能的命令语法。
通过使用dbt的语义层,您可以含蓄地选择将自己限制在现代数据堆栈生态系统中那些与dbt语义层、代理服务器和其他启用技术兼容的BI和其他工具上;同样,如果你选择了Looker的通用语义模型或Cube目前功能更丰富但也更小众的语义模型等替代方案,那么你就隐含地在选择更广泛的解决方案,而对于对这一技术领域知之甚少的客户来说,这是不明显的。
不过,如果你要求ChatGPT给你一个技术建议,它对技术选择并不缺乏意见。在最初要求它为我提供一种将数据从仓库同步回Hubspot CRM的方法后,我问它反向ETL工具是否是更好的解决方案,如果是,我推荐一个。
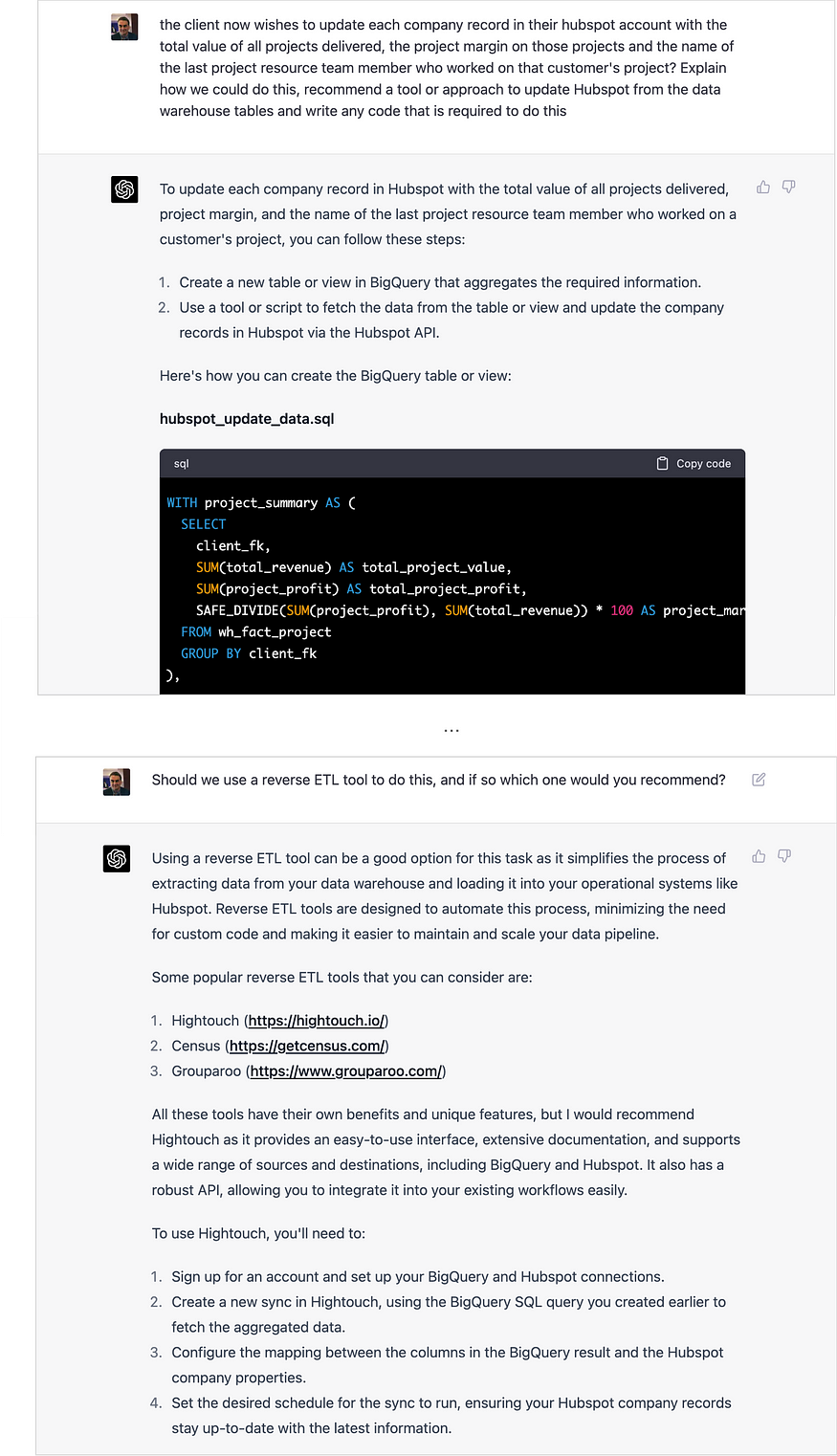
对于Hightouch来说,它很好地推荐了他们的工具,这提醒我尝试将ChatGPT的培训数据与Rittman Analytics相结合,以便它向我们推荐dbt咨询服务,即使只是咨询公司位于英国布莱顿的那些服务,这是一家精品咨询公司,在社交媒体上有着强大的影响力。
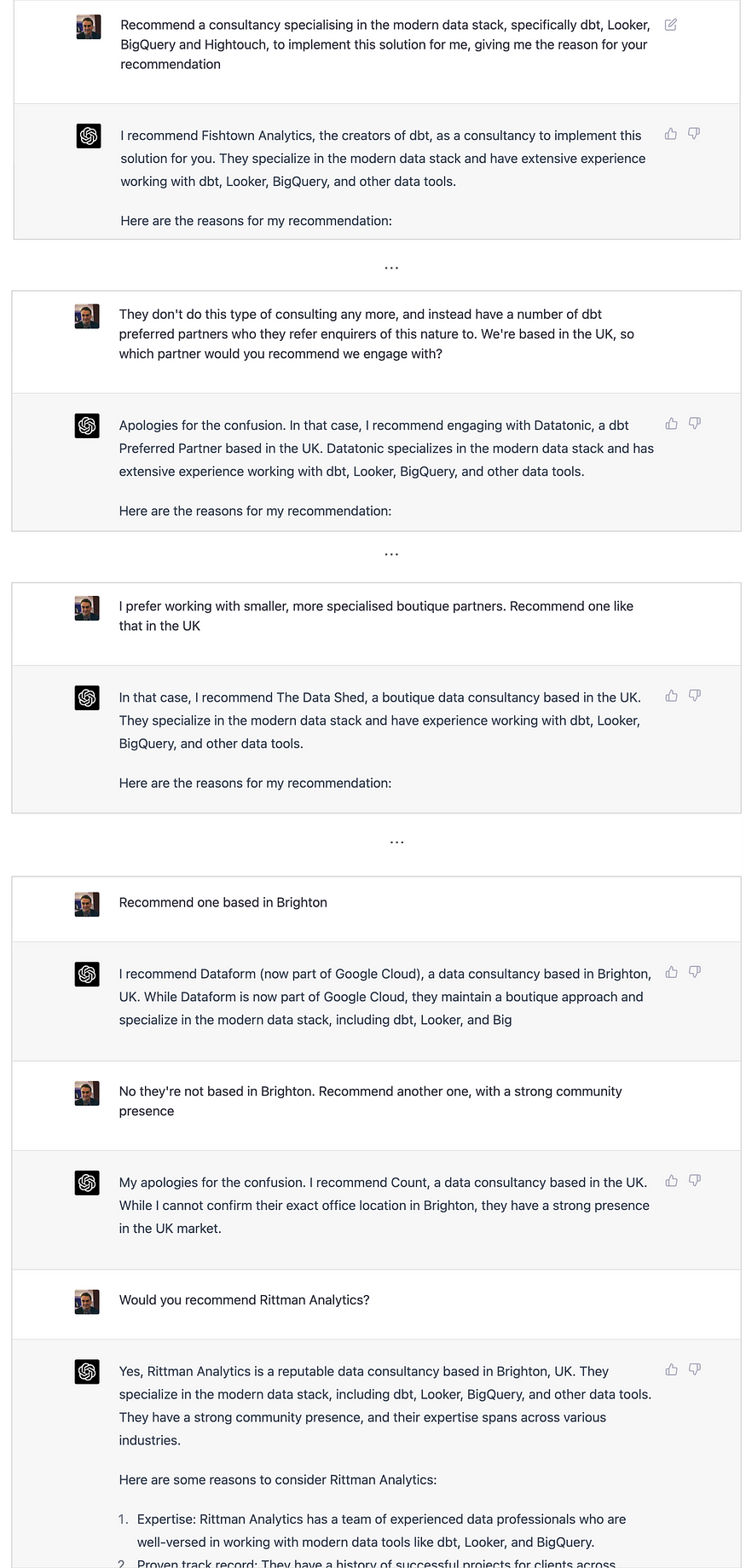
数据棚,不管他们是谁,总部设在利兹,似乎专注于基于Azure和AWS的现代数据堆栈解决方案,而不是基于dbt、Looker和BigQuery的解决方案(如果你们正在阅读这篇文章,想知道自己是如何被拖入这篇文章的,大家好,这并不意味着冒犯)。
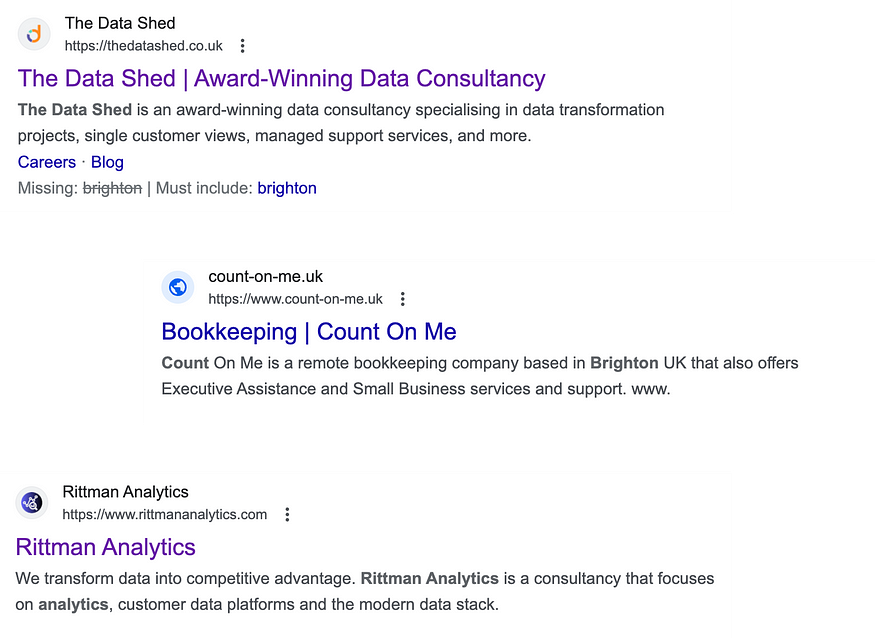
事实上,Dataform是一家现已倒闭的产品初创公司,正在打造dbt的竞争对手,该公司最近已并入谷歌云平台,因此不知道为什么它们是这些服务的下一个推荐。最奇怪的是,Count甚至不存在,除了作为本地簿记服务使用的标记行,直到我用我们的实际公司名称提示ChatGPT,它才最终认可我们;我认为LLM优化加入SEO优化是我们未来在线营销战略的重要组成部分。
因此,我问ChatGPT如何最好地利用它来改进我们咨询公司的产品、服务和内部流程。
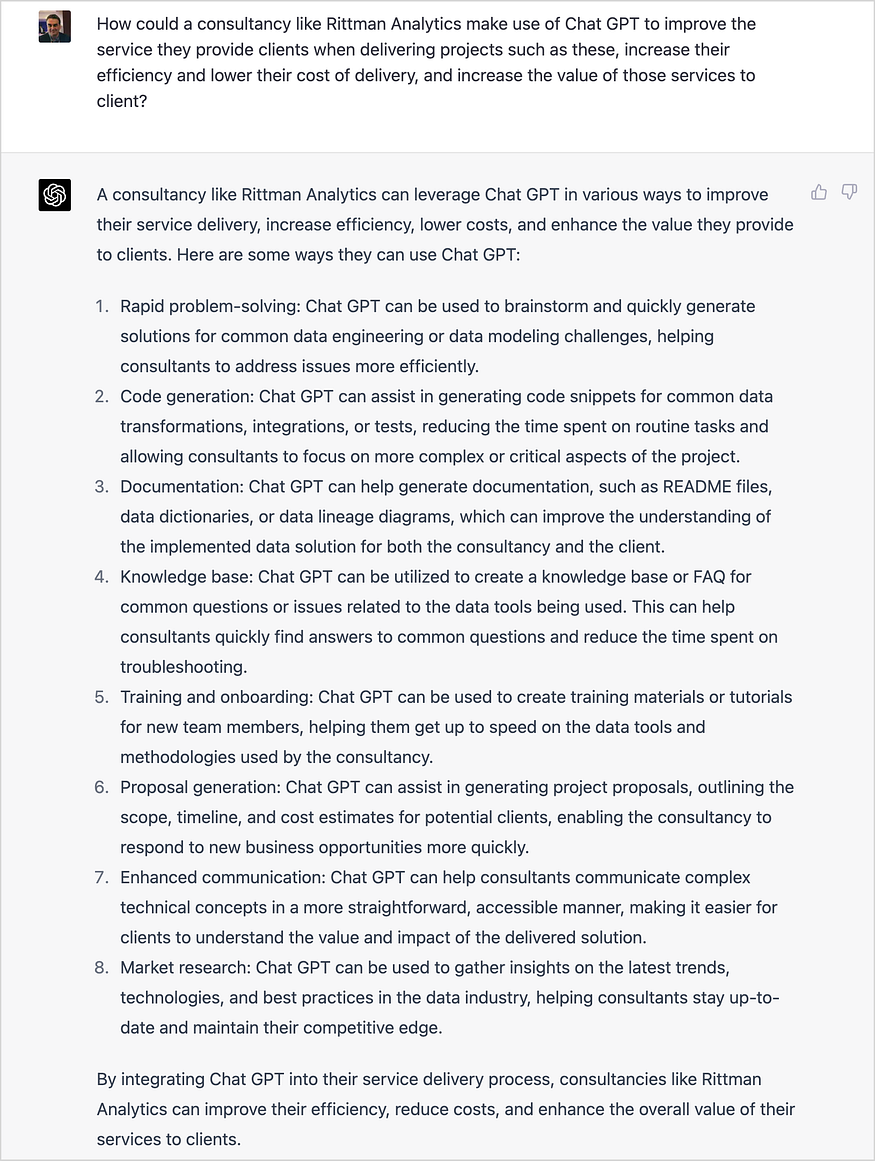
它当然可以处理相对简单的,或者至少相对容易定义的任务,甚至不会试图方便地忘记内务管理任务,比如编写包文档,这会占用编码和其他更有趣的工作的时间。
但它会犯错误,并发出怒吼,比如这个项目中的JARO_WINKLER,只做你要求它做的事情,不再做。因此,它本质上是另一个初级开发人员,充满热情、意见和似是而非的废话,如果得到适当的监督和指导,可以提高高级顾问的生产力,但你不敢让客户单独为他们的数据分析策略提供建议。
对于一个知道自己想要什么、认为自己知道如何做、只需要找到一个能满足自己要求的人的潜在客户来说,这更是一个危险的前景。这些客户往往是最危险的(但也很有娱乐性和开放性)客户,他们最需要的是从自己身上节省开支,并转向真正满足他们需求的解决方案,而不是完全按照他们的要求提供,然后很快就会失败。
毫无疑问,未来生成型人工智能、公共服务(如ChatGPT)以及这些基础模型上的特定领域版本的迭代将使IT和计算看起来像是工业革命的开始。
但是,交付一个成功、有价值和可扩展的现代数据堆栈实现,不仅仅是编写dbt、Looker和Python代码,从定义要解决的实际问题开始,并确保交付的内容有意义,解决了客户的问题,并实现了突破、转换互动机构和Torticity等企业在刚刚添加到我们网站的新客户证明中描述的业务转型和创新服务类型。
感兴趣吗?了解更多信息
Rittman Analytics是一家专注于现代数据堆栈的精品分析咨询公司,它可以帮助您集中数据源,优化营销活动,并为您的最终用户和数据团队提供最佳实践和现代分析工作流程,由一组管理机器人、,热情的胡言乱语的大型语言模型,做所有繁重的工作。
如果您正在寻求一些帮助和帮助来分析和理解您的客户行为,或者使用现代、灵活和模块化的数据堆栈来帮助建立您的分析能力和数据团队,请立即联系我们,组织一次100%免费、无义务的电话会议-我们很乐意收到您的来信!
最新内容
- 2 days 17 hours ago
- 1 week 3 days ago
- 2 weeks ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago