

想要为特定业务构建个性化的聊天机器人,但数据很少,或者没有时间为意图分类和命名实体识别等任务创建业务特定数据的麻烦?这个博客就是一个解决方案!
让机器完全理解人类查询某事的多种方式,并能够以人类的自然语言做出回应!对我来说,这感觉就像我们想要通过 NLP 实现的几乎所有事情。因此,这是我一直很感兴趣的一个应用程序。
几周前,我终于着手设计我的第一个 NLP 聊天机器人!当然,我已经考虑过(和自己一起,哈哈)这个聊天机器人的性质——我做出了一个深刻的决定(我的脸上塞满了食物,我正在寻找可以在线订购的甜点)我的聊天机器人将为一家餐厅服务通过聊天和协助顾客。
聊天机器人的功能:
- 迎接
- 显示菜单
- 显示可用的优惠
- 仅显示素食选项(如果有)
- 显示素食选项(如果有)
- 详细解释任何特定食品,提供其制备和成分的详细信息
- 向顾客保证餐厅遵循的 COVID 协议和卫生情况
- 告诉餐厅的营业时间
- 检查表是否可用
- 预订餐桌(如果有)并为客户提供唯一的预订 ID
- 建议点什么
- 如果被问及他们是机器人还是人类,请回答
- 提供餐厅的联系方式
- 提供餐厅地址
- 采取积极的反馈,做出相应的回应,并将其存储起来供餐厅管理人员检查
- 接受负面反馈,做出相应的回应,并将其存储起来以供餐厅管理人员检查
- 回复一些一般性消息
- 告别
最终结果:
请点击全屏按钮,并将质量从标清更改为高清,以便清楚地看到它。
概述:
Embedded_dataset.json 的创建:
首先,我们嵌入我们的数据集,该数据集将用作聊天机器人的输入。 这是一次性的工作。

整体架构概述:
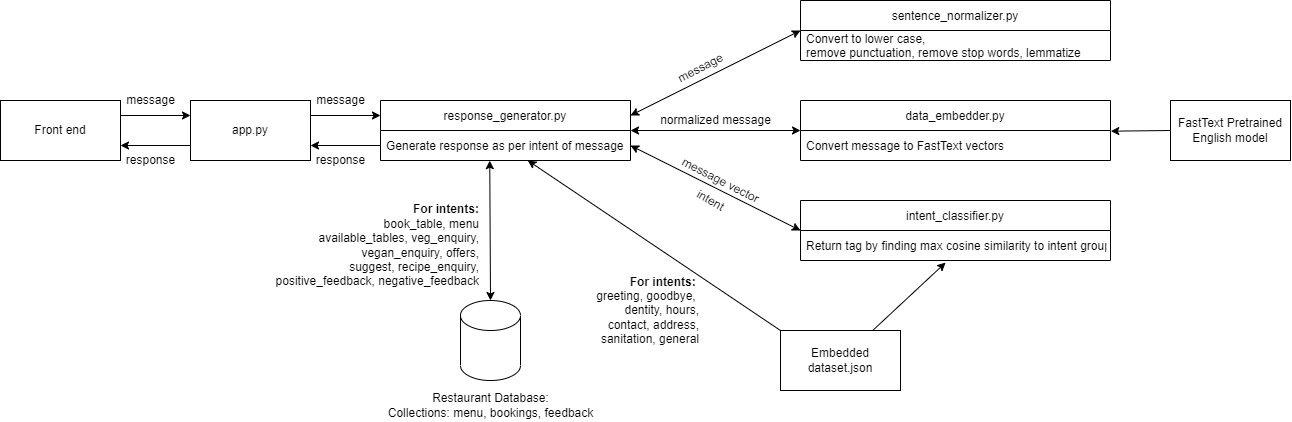
如何设置和运行项目?
这只是为了让项目启动并运行,我将在博客中一一解释:)
1.安装先决条件
我的 python 版本是 3.6.13。
要安装所有必需的库,请下载/克隆我的 GitHub 存储库,然后在文件夹中打开 CMD 并输入:
> pip install -r requirements.txt
这是 requirements.txt 文件的内容。
numpy nltk tensorflow tflearn flask sklearn pymongo fasttext tsne
2.下载预训练的FastText英文模型
从这里下载 cc.en.300.bin.gz。解压到下载 cc.en.300.bin,代码是我的 Github repo 中的帮助脚本。
3.准备数据集
运行 data_embedder.py 这将获取 dataset.json 文件并将所有句子转换为 FastText 向量。
> python data_embedder.py
4.在localhost上设置Mongo Db
安装 MongoDb Compass
创建 3 个collections:菜单、预订、反馈(menu, bookings, feedback)
菜单必须是硬编码的,因为它是餐厅特有的东西,用餐馆提供的食物、价格等填充它。它包括项目、成本、素食、蔬菜、关于、提供。我用数据制作了一个小的 JSON 文件,并将其导入 MongoDb Compass 以填充菜单集合。你可以在这里找到我的菜单数据。
菜单中的一个示例文档:

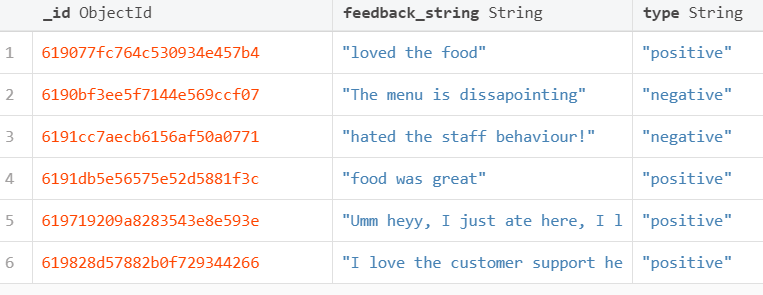
当用户提供反馈时,将插入反馈文档,以便餐厅管理人员可以阅读它们并采取必要的措施。
反馈集合中的示例文档:
预订集合写入唯一的预订ID和预订的时间戳,以便客户在接待处出示ID时,可以验证预订。

5. 运行 Flask
这将在 localhost 上启动 Web 应用程序
> export FLASK_APP=app > export FLASK_ENV=development > flask run
执行:
我们友好的小机器人工作有两个主要部分:
- 意图分类 了解消息的意图,即客户查询什么
- 对话设计设计对话的方式,根据意图响应消息,使用对话设计。
例如,
用户发送消息:“Please show me the vegetarian items on the menu?”
聊天机器人将意图识别为“veg_enquiry”
然后聊天机器人相应地采取行动,即向餐厅 Db 查询素食项目,并将其传达给用户。
现在,让我们一步一步来。
1. 构建数据集
数据集是一个 JSON 文件,包含三个字段:标签、模式、响应,我们在其中记录一些具有该意图的可能消息,以及一些可能的响应。对于某些意图,响应为空,因为它们需要进一步的操作来确定响应。例如,对于一个查询,“是否有任何优惠正在进行?”如果有任何报价处于活动状态,机器人首先必须检查数据库,然后做出相应的响应。
数据集如下所示:
{"intents": [
{"tag": "greeting",
"patterns": ["Hi", "Good morning!", "Hey! Good morning", "Hello there",
"Greetings to you"],
"responses": ["Hello I'm Restrobot! How can I help you?",
"Hi! I'm Restrobot. How may I assist you today?"]
},
{"tag": "book_table",
"patterns": ["Can I book a table?","I want to book a seat",
"Can I book a seat?", "Could you help me book a table", "Can I reserve a seat?",
"I need a reservation"],
"responses": [""]
},
{"tag": "goodbye",
"patterns": ["I will leave now","See you later", "Goodbye",
"Leaving now, Bye", "Take care"],
"responses": ["It's been my pleasure serving you!",
"Hope to see you again soon! Goodbye!"]
},
.
.
.
.2. 规范化消息
- 第一步是规范化消息。在自然语言中,人类可能会以多种方式说同样的话。当我们对文本进行规范化时,以减少其随机性,使其更接近预定义的“标准”。这有助于我们减少计算机必须处理的不同信息的数量,从而提高效率。我们采取以下步骤来规范所有文本,包括我们数据集上的消息和客户发送的消息:
- 全部转换为小写
- 删除标点符号
- 删除停用词:由于数据集很小,使用 NLTK 停用词会删除许多对这个上下文很重要的词。所以我写了一个小脚本来获取整个文档中的单词及其频率,并手动选择无关紧要的单词来制作这个列表
词形还原:指使用词汇和词形分析正确地做事,去除屈折词尾,只返回词的基本形式或字典形式。
from nltk.tokenize import RegexpTokenizer
from nltk.stem.wordnet import WordNetLemmatizer
'''
Since the dataset is small, using NLTK stop words stripped it o
ff many words that were important for this context
So I wrote a small script to get words and their frequencies
in the whole document, and manually selected
inconsequential words to make this list
'''
stop_words = ['the', 'you', 'i', 'are', 'is', 'a', 'me', 'to', 'can',
'this', 'your', 'have', 'any', 'of', 'we', 'very',
'could', 'please', 'it', 'with', 'here', 'if', 'my', 'am']
def lemmatize_sentence(tokens):
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(word) for word in tokens]
return lemmatized_tokens
def tokenize_and_remove_punctuation(sentence):
tokenizer = RegexpTokenizer(r'\w+')
tokens = tokenizer.tokenize(sentence)
return tokens
def remove_stopwords(word_tokens):
filtered_tokens = []
for w in word_tokens:
if w not in stop_words:
filtered_tokens.append(w)
return filtered_tokens
'''
Convert to lower case,
remove punctuation
lemmatize
'''
def preprocess_main(sent):
sent = sent.lower()
tokens = tokenize_and_remove_punctuation(sent)
lemmatized_tokens = lemmatize_sentence(tokens)
orig = lemmatized_tokens
filtered_tokens = remove_stopwords(lemmatized_tokens)
if len(filtered_tokens) == 0:
# if stop word removal removes everything, don't do it
filtered_tokens = orig
normalized_sent = " ".join(filtered_tokens)
return normalized_sent
3. 句子嵌入:
我们使用 FastText 预训练的英文模型 cc.en.300.bin.gz,从这里下载。我们使用了由 fasttext 库带来的函数 get_sentence_vector()。它的工作原理是,将句子中的每个单词转换为 FastText 单词向量,每个向量除以其范数(L2 范数),然后仅取具有正 L2 范数值的向量的平均值。
将句子嵌入数据集中后,我将它们写回到名为 Embedded_dataset.json 的 json 文件中,并保留它以供以后在运行聊天机器人时使用。
3.意图分类:
意图分类的含义是能够理解消息的意图,或者客户基本查询的内容,即给定一个句子/消息,机器人应该能够将其装入预定义的意图之一。
意图:
在我们的例子中,我们有 18 个意图,需要 18 种不同类型的响应。
现在要通过机器学习或深度学习技术实现这一点,我们需要大量的句子,并用相应的意图标签进行注释。然而,我很难用定制的 18 个标签生成如此庞大的意图注释数据集,专门针对餐厅的要求。所以我想出了我自己的解决方案。
我制作了一个小型数据集,其中包含 18 个意图中的每一个的一些示例消息。直观地说,所有这些消息,当转换为带有词嵌入模型的向量时(我使用了预训练的 FastText 英语模型),并在二维空间上表示,应该彼此靠近。
为了验证我的直觉,我选取了 6 组这样的句子,将它们绘制成 TSNE 图。在这里,我使用了 K-means 无监督聚类,正如预期的那样,句子被清晰地映射到向量空间中的 6 个不同的组中:
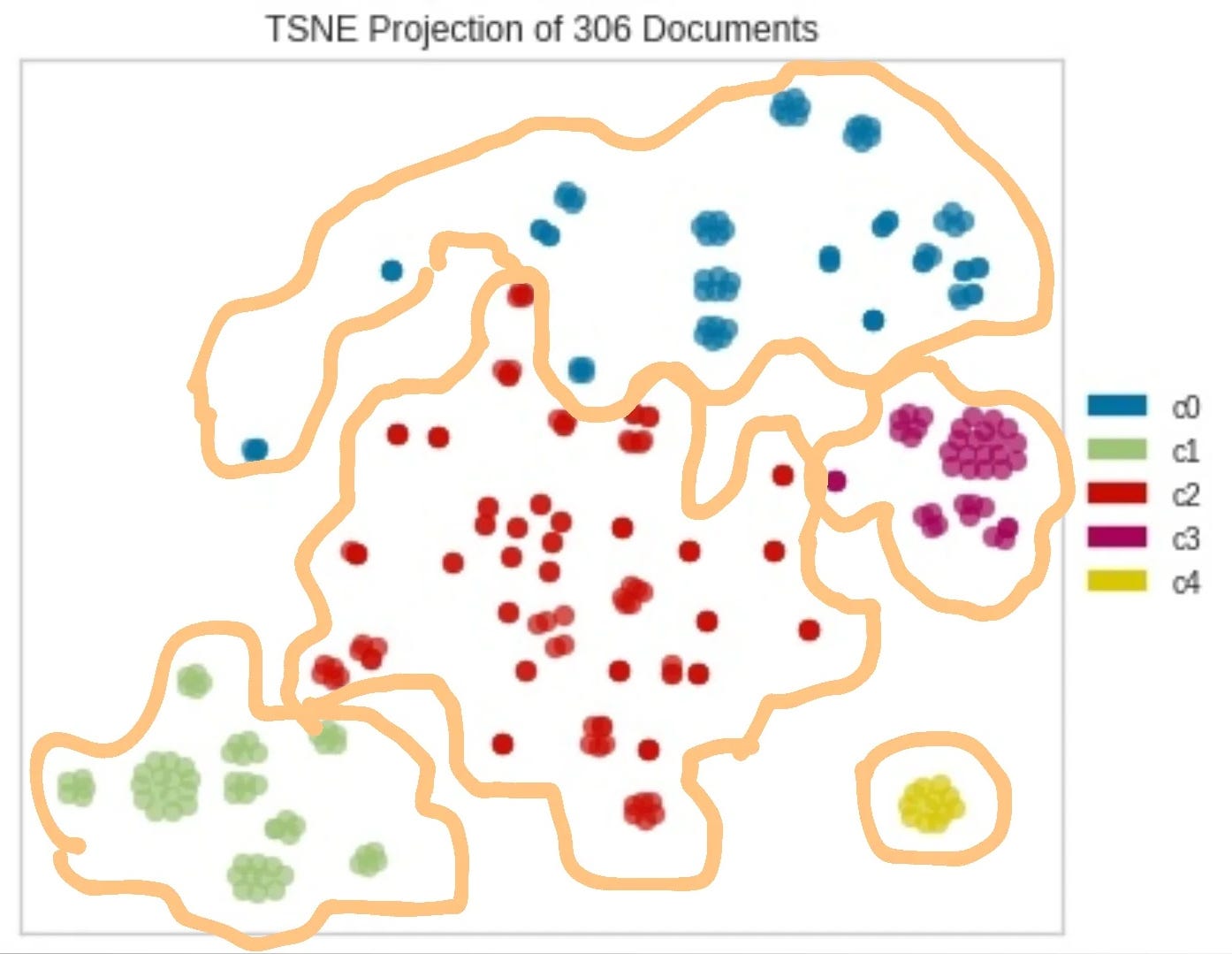
TSNE句子可视化的代码就在这里,本文不再赘述。
实现意图分类:
给定一条消息,我们需要确定它最接近哪个意图(句子簇)。 我们发现与余弦相似性的接近性。
余弦相似度是用于衡量文档(句子/消息)的相似程度的指标,无论其大小如何。 在数学上,它测量投影在多维空间中的两个向量之间夹角的余弦值。 余弦相似度是有利的,因为即使两个相似的文档相距很远欧几里得距离(由于文档的大小),它们仍然可能更靠近在一起。 角度越小,余弦相似度越高。
在 detect_intent() 函数的注释中解释了最终确定意图的逻辑:
"""
Developed by Aindriya Barua in November, 2021
"""
import codecs
import json
import numpy as np
import data_embedder
import sentence_normalizer
obj_text = codecs.open('embedded_data.json', 'r', encoding='utf-8').read()
data = json.loads(obj_text)
ft_model = data_embedder.load_embedding_model()
def normalize(vec):
norm = np.linalg.norm(vec)
return norm
def cosine_similarity(A, B):
normA = normalize(A)
normB = normalize(B)
sim = np.dot(A, B) / (normA * normB)
return sim
def detect_intent(data, input_vec):
max_sim_score = -1
max_sim_intent = ''
max_score_avg = -1
break_flag = 0
for intent in data['intents']:
scores = []
intent_flag = 0
tie_flag = 0
for pattern in intent['patterns']:
pattern = np.array(pattern)
similarity = cosine_similarity(pattern, input_vec)
similarity = round(similarity, 6)
scores.append(similarity)
# if exact match is found, then no need to check any further
if similarity == 1.000000:
intent_flag = 1
break_flag = 1
# no need to check any more sentences in this intent
break
elif similarity > max_sim_score:
max_sim_score = similarity
intent_flag = 1
# if a sentence in this intent has same similarity as the max and
#this max is from a previous intent,
# that means there is a tie between this intent and some previous intent
elif similarity == max_sim_score and intent_flag == 0:
tie_flag = 1
'''
If tie occurs check which intent has max top 4 average
top 4 is taken because even without same intent there are often
different ways of expressing the same intent,
which are vector-wise less similar to each other.
Taking an average of all of them, reduced the score of those clusters
'''
if tie_flag == 1:
scores.sort()
top = scores[:min(4, len(scores))]
intent_score_avg = np.mean(top)
if intent_score_avg > max_score_avg:
max_score_avg = intent_score_avg
intent_flag = 1
if intent_flag == 1:
max_sim_intent = intent['tag']
# if exact match was found in this intent, then break
'cause we don't have to iterate through anymore intents
if break_flag == 1:
break
if break_flag != 1 and ((tie_flag == 1 and intent_flag == 1
and max_score_avg < 0.06) or (intent_flag == 1 and max_sim_score < 0.6)):
max_sim_intent = ""
return max_sim_intent
def classify(input):
input = sentence_normalizer.preprocess_main(input)
input_vec = data_embedder.embed_sentence(input, ft_model)
output_intent = detect_intent(data, input_vec)
return output_intent
if __name__ == '__main__':
input = sentence_normalizer.preprocess_main("hmm")
input_vec = data_embedder.embed_sentence(input, ft_model)
output_intent = detect_intent(data, input_vec)
print(output_intent)
input = sentence_normalizer.preprocess_main("nice food")
input_vec = data_embedder.embed_sentence(input, ft_model)
output_intent = detect_intent(data, input_vec)
print(output_intent)4. 保存餐厅信息的数据库
这里我们使用 pymongo 来存储餐厅的信息。 我创建了三个集合:
1. 菜单有列:item, cost, vegan, veg, about, offer -> app.py 查询到它
2. 反馈有列:feedback_string, type -> docs被app.py插入其中
3. bookings: booking_id, booking_time -> docs由app.py插入其中
5.根据消息生成响应并采取行动
在我们的 dataset.json 中,我们已经为一些意图保留了一个响应列表,在这些意图的情况下,我们只是从列表中随机选择响应。 但是在许多意图中,我们将响应留空,在这些情况下,我们必须生成响应或根据意图执行某些操作,方法是从数据库中查询信息,为预订创建唯一 ID,检查食谱 一个项目等
"""
Developed by Aindriya Barua in November, 2021
"""
import json
import random
import datetime
import pymongo
import uuid
import intent_classifier
seat_count = 50
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["restaurant"]
menu_collection = db["menu"]
feedback_collection = db["feedback"]
bookings_collection = db["bookings"]
with open("dataset.json") as file:
data = json.load(file)
def get_intent(message):
tag = intent_classifier.classify(message)
return tag
'''
Reduce seat_count variable by 1
Generate and give customer a unique booking ID if seats available
Write the booking_id and time of booking into Collection named bookings
in restaurant database
'''
def book_table():
global seat_count
seat_count = seat_count - 1
booking_id = str(uuid.uuid4())
now = datetime.datetime.now()
booking_time = now.strftime("%Y-%m-%d %H:%M:%S")
booking_doc = {"booking_id": booking_id, "booking_time": booking_time}
bookings_collection.insert_one(booking_doc)
return booking_id
def vegan_menu():
query = {"vegan": "Y"}
vegan_doc = menu_collection.find(query)
if vegan_doc.count() > 0:
response = "Vegan options are: "
for x in vegan_doc:
response = response + str(x.get("item")) + " for Rs. " +
str(x.get("cost")) + "; "
response = response[:-2] # to remove the last ;
else:
response = "Sorry no vegan options are available"
return response
def veg_menu():
query = {"veg": "Y"}
vegan_doc = menu_collection.find(query)
if vegan_doc.count() > 0:
response = "Vegetarian options are: "
for x in vegan_doc:
response = response + str(x.get("item")) + " for Rs. " +
str(x.get("cost")) + "; "
response = response[:-2] # to remove the last ;
else:
response = "Sorry no vegetarian options are available"
return response
def offers():
all_offers = menu_collection.distinct('offer')
if len(all_offers)>0:
response = "The SPECIAL OFFERS are: "
for ofr in all_offers:
docs = menu_collection.find({"offer": ofr})
response = response + ' ' + ofr.upper() + " On: "
for x in docs:
response = response + str(x.get("item")) + " - Rs. " +
str(x.get("cost")) + "; "
response = response[:-2] # to remove the last ;
else:
response = "Sorry there are no offers available now."
return response
def suggest():
day = datetime.datetime.now()
day = day.strftime("%A")
if day == "Monday":
response = "Chef recommends: Paneer Grilled Roll, Jade Chicken"
elif day == "Tuesday":
response = "Chef recommends: Tofu Cutlet, Chicken A La King"
elif day == "Wednesday":
response = "Chef recommends: Mexican Stuffed Bhetki Fish, Crispy corn"
elif day == "Thursday":
response = "Chef recommends: Mushroom Pepper Skewers, Chicken cheese balls"
elif day == "Friday":
response = "Chef recommends: Veggie Steak, White Sauce Veggie Extravaganza"
elif day == "Saturday":
response = "Chef recommends: Tofu Cutlet, Veggie Steak"
elif day == "Sunday":
response = "Chef recommends: Chicken Cheese Balls, Butter Garlic Jumbo Prawn"
return response
def recipe_enquiry(message):
all_foods = menu_collection.distinct('item')
response = ""
for food in all_foods:
query = {"item": food}
food_doc = menu_collection.find(query)[0]
if food.lower() in message.lower():
response = food_doc.get("about")
break
if "" == response:
response = "Sorry please try again with exact spelling of the food item!"
return response
def record_feedback(message, type):
feedback_doc = {"feedback_string": message, "type": type}
feedback_collection.insert_one(feedback_doc)
def get_specific_response(tag):
for intent in data['intents']:
if intent['tag'] == tag:
responses = intent['responses']
response = random.choice(responses)
return response
def show_menu():
all_items = menu_collection.distinct('item')
response = ', '.join(all_items)
return response
def generate_response(message):
global seat_count
tag = get_intent(message)
response = ""
if tag != "":
if tag == "book_table":
if seat_count > 0:
booking_id = book_table()
response = "Your table has been booked successfully.
Please show this Booking ID at the counter: " + str(
booking_id)
else:
response = "Sorry we are sold out now!"
elif tag == "available_tables":
response = "There are " + str(seat_count) + " table(s)
available at the moment."
elif tag == "veg_enquiry":
response = veg_menu()
elif tag == "vegan_enquiry":
response = vegan_menu()
elif tag == "offers":
response = offers()
elif tag == "suggest":
response = suggest()
elif tag == "recipe_enquiry":
response = recipe_enquiry(message)
elif tag == "menu":
response = show_menu()
elif tag == "positive_feedback":
record_feedback(message, "positive")
response = "Thank you so much for your valuable feedback.
We look forward to serving you again!"
elif "negative_response" == tag:
record_feedback(message, "negative")
response = "Thank you so much for your valuable feedback.
We deeply regret the inconvenience. We have " \
"forwarded your concerns to the authority and
hope to satisfy you better the next time! "
# for other intents with pre-defined responses that can be pulled from dataset
else:
response = get_specific_response(tag)
else:
response = "Sorry! I didn't get it, please try to be more precise."
return response6.最后,与Flask集成
我们将使用 AJAX 进行数据的异步传输,即您不必每次向模型发送输入时都重新加载网页。 Web 应用程序将无缝响应您的输入。 让我们看一下 HTML 文件。
最新的 Flask 默认是线程化的,所以如果不同的用户同时聊天,唯一的 ID 在所有实例中都是唯一的,并且像 seat_count 这样的公共变量将被共享。
在 JavaScript 部分,我们从用户那里获取输入,将其发送到我们生成响应的“app.py”文件,然后接收输出以将其显示在应用程序上。
<!DOCTYPE html>
<html>
<title>Restaurant Chatbot</title>
<head>
<link rel="icon" href="">
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.2.1/jquery.min.js">
</script>
<style>
body {
font-family: monospace;
background-position: center;
background-repeat: no-repeat;
background-size: cover;
background-attachment: fixed;
}
h2 {
background-color: white;
border: 2px solid black;
border-radius: 5px;
color: #03989E;
display: inline-block;Helvetica
margin: 5px;
padding: 5px;
}
h4{
position: center;
}
#chatbox {
margin-top: 10px;
margin-bottom: 60px;
margin-left: auto;
margin-right: auto;
width: 40%;
height: 40%
position:fixed;
}
#userInput {
margin-left: auto;
margin-right: auto;
width: 40%;
margin-top: 60px;
}
#textInput {
width: 90%;
border: none;
border-bottom: 3px solid black;
font-family: 'Helvetica';
font-size: 17px;
}
.userText {
width:fit-content; width:-webkit-fit-content; width:-moz-fit-content;
color: white;
background-color: #FF9351;
font-family: 'Helvetica';
font-size: 12px;
margin-left: auto;
margin-right: 0;
line-height: 20px;
border-radius: 5px;
text-align: left;
}
.userText span {
padding:10px;
border-radius: 5px;
}
.botText {
margin-left: 0;
margin-right: auto;
width:fit-content; width:-webkit-fit-content; width:-moz-fit-content;
color: white;
background-color: #00C2CB;
font-family: 'Helvetica';
font-size: 12px;
line-height: 20px;
text-align: left;
border-radius: 5px;
}
.botText span {
padding: 10px;
border-radius: 5px;
}
.boxed {
margin-left: auto;
margin-right: auto;
width: 100%;
border-radius: 5px;
}
input[type=text] {
bottom: 0;
width: 40%;
padding: 12px 20px;
margin: 8px 0;
box-sizing: border-box;
position: fixed;
border-radius: 5px;
}
</style>
</head>
<body background="{{ url_for('static', filename='images/slider.jpg') }}">
<img />
<center>
<h2>
Welcome to Aindri's Restro
</h2>
<h4>
You are chatting with our customer support bot!
</h4>
</center>
<div class="boxed">
<div>
<div id="chatbox">
</div>
</div>
<div id="userInput">
<input id="nameInput" type="text" name="msg" placeholder="Ask me anything..." />
</div>
<script>
function getBotResponse() {
var rawText = $("#nameInput").val();
var userHtml = '<p class="userText"><span><b>' + "You : " + '</b>'
+ rawText + "</span></p>";
$("#nameInput").val("");
$("#chatbox").append(userHtml);
document
.getElementById("userInput")
.scrollIntoView({ block: "start", behavior: "smooth" });
$.get("/get", { msg: rawText }).done(function(data) {
var botHtml = '<p class="botText"><span><b>' + "Restrobot : " + '</b>' +
data + "</span></p>";
$("#chatbox").append(botHtml);
document
.getElementById("userInput")
.scrollIntoView({ block: "start", behavior: "smooth" });
});
}
$("#nameInput").keypress(function(e) {
if (e.which == 13) {
getBotResponse();
}
});
</script>
</div>
</body>
</html>
from flask import Flask, render_template, request, jsonify
import response_generator
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/get')
def get_bot_response():
message = request.args.get('msg')
response = ""
if message:
response = response_generator.generate_response(message)
return str(response)
else:
return "Missing Data!"
if __name__ == "__main__":
app.run()我们刚刚构建的这种美丽的一些快照:



结论
这就是我们如何用非常有限的数据构建一个简单的 NLP 聊天机器人! 这显然可以通过添加各种极端情况得到很大改善,并在现实生活中变得更加有用。 所有代码都在我的 Github repo 上开源。 如果您想出对此项目的改进,请随时打开一个问题并做出贡献。 我很乐意审查和合并您的功能增强并关注我的 Github 上的任何问题!
原文:https://medium.com/@barua.aindriya/building-a-nlp-chatbot-for-a-restaur…