
软件开发中的生产力一直很难衡量。与其他行业不同,编程行为并不容易并行化。开发过程的独特之处在于,它需要技术和沟通技能的多样化组合,这需要一套专门的DevOps指标来跟踪团队的生命体征。
软件开发的脉搏
并非所有指标都是平等的。根据上下文的不同,有些比其他更有用。我们选择衡量的东西可以帮助我们发现问题,或者在无关数据和非生产性目标背后掩盖问题。
在决定跟踪哪些DevOps指标时,我们应该考虑以下几点:
- 当人们感到被观察时,他们的行为就不一样了。这被称为霍桑效应,它会产生过度的压力。最好尽可能保持指标的非个人性和匿名性。
- 第一点还意味着,指标只能用于跟踪团队随时间的进展,而不能用于比较团队或个人。
- 过多地强调达到任意数字会产生与系统博弈的动机。Dave Farley和Jez Humble在这个问题上有这样的看法:
“测量代码行,开发人员将编写许多短代码行。测量修复的缺陷数量,测试人员将记录可以通过与开发人员快速讨论修复的错误。”
--持续交付:通过构建、测试和部署自动化实现可靠的软件发布
因此,在选择要用于跟踪团队进度的指标之前,每个人都应该知道,他们的唯一目的是跟踪进度并识别问题。它们不是为了表扬或惩罚个人。
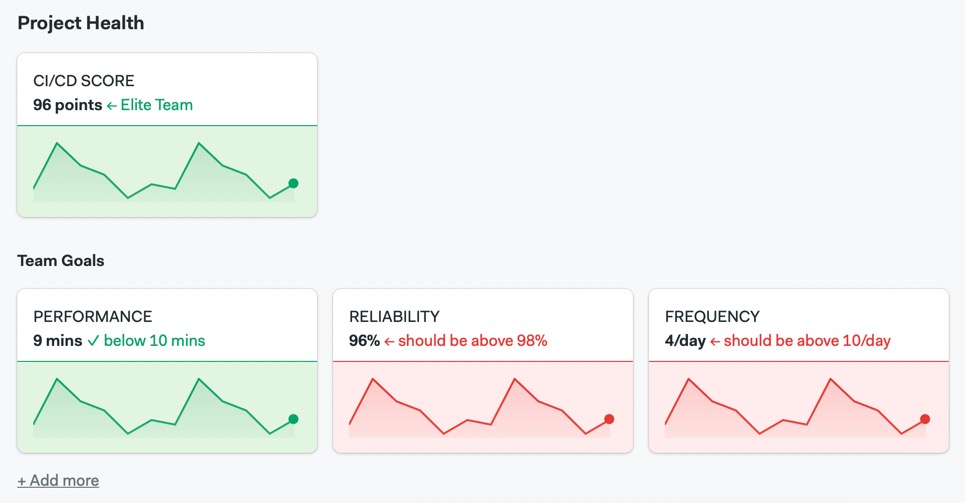
A dashboard with all the chosen DevOps metrics should be created, and it should be visible to everyone on the team.
四个DORA指标
DORA度量是我们衡量软件开发的主要工具。它们包括四个基准:
- 部署频率(DF):组织向用户成功发布产品或将其部署到生产中的频率。
- 变更交付周期(LT):承诺达到生产或发布所需的时间。
- 平均恢复服务时间(MTTR):组织从生产故障中恢复所需的时间。
- 变更失败率(CFR):导致生产失败的发布或部署的百分比。
开发团队可以分为四个级别之一:低、中、高和精英。
| Metric | Low | Medium | High | Elite |
|---|---|---|---|---|
| DF | fewer than 1 per 6 months | 1 per month to 1 per 6 months | 1 per week to 1 per month | On demand (multiple deploys per day) |
| LT | more than 6 months | 1 month to 6 months | 1 day to 1 week | Less than 1 hour |
| MTTR | more than 6 months | 1 day to 1 week | Less than a day | Less than 1 hour |
| CFR | 16 to 30% | 16 to 30% | 16 to 30% | 0 to 15% |
年复一年,DORA研究团队已经证明,高DORA分数是高绩效的可预测指标。因此,它们应该包含在任何涉及软件开发的度量策略中。
循环时间(Cycle time)
与DORA一样,循环时间也是生产力的另一个主要指标。它被定义为从我们决定添加功能到将其部署或发布给公众或客户之间的平均时间。
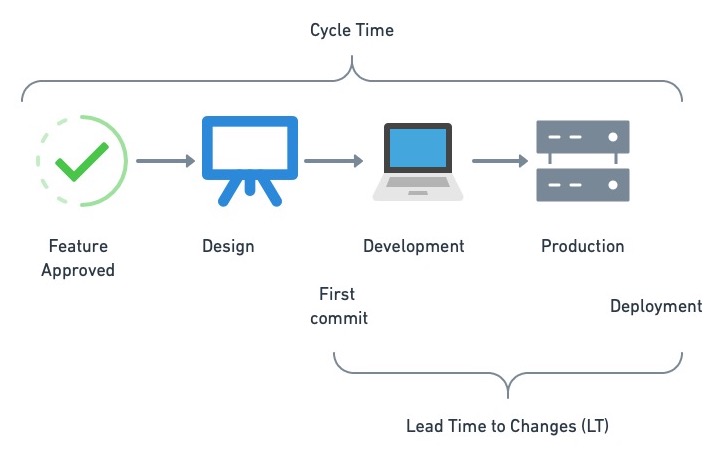
Cycle time spans the entirety of feature development; from inception to reality. Lead time to changes begins ticking when the first line of code for a feature is committed.
快速的周期时间意味着团队能够以持续的速度始终如一地提供功能。
质量(Quality)
质量对不同的人意味着不同的东西。虽然一些团队强调遵守风格规则,但其他团队可能更关心安全风险或保持愉快的用户体验。重要的是,团队就他们的素质达成了一致。
我们可以使用混合参数来估计代码的质量。不满足预定质量条的情况应该导致CI管道失败。一些有价值的指标包括:
- 漏洞数量。
- 违反风格准则。
- 代码覆盖范围。
- 陈旧分支的数量。
- 循环复杂性。
- 破坏的架构约束。例如,确保一个模块中的代码不引用另一个模块的类。
客户反馈
客户的反馈可以有多种形式,例如打开的门票、使用模式、社交媒体上的提及,以及从净促销分数(NPS)调查中收集的信息。具体情况因业务和产品而异,但我们必须以某种具体形式代表客户的声音,因为归根结底,他们会买单。
员工满意度
我们必须关注的不仅仅是我们的用户和客户。开发人员、测试人员、质量和业务分析师、产品经理和经理也至关重要,因为我们需要他们来制造一个伟大的产品。最好的想法来自乐观、自信和休息良好的头脑。
员工满意度受到多种因素的影响,我们应该以某种方式衡量这些因素:
- 文件的全面性和更新程度如何?
- 加入一个新的开发人员有多容易?
- 员工是否觉得自己的声音被听到了?
- 工作/生活的平衡如何?有人精疲力竭吗?
- 工作场所是一个安全的环境,可以冒险和试验吗?
- 员工是否有正确的工具来完成他们的工作?
- 他们觉得自己可以安全地提出建设性的批评吗?
平均CI持续时间
软件开发是一种实验性的练习——我们做一些小的改变,看看它们是如何运作的。来自CI流水线的反馈最终确定了改变是否停留在代码库中。
当CI/CD过程缓慢时,以小增量工作会变得痛苦,因为开发人员要么等待看到结果,要么继续前进,并试图记住在结果出来时返回管道。无论哪种情况,都很难保持创意流。

CI管道的平均持续时间应以分钟为单位。我们的目标应该是不到10分钟,以保持开发人员的参与和代码的流动。如果你的管道太长,请查看Semaphore的测试优化指南。
CI每天运行次数
这是每天执行CI管道的次数。我们希望将这个数字保持在较高水平——每个活跃的开发人员至少运行4或5次——因为这意味着开发人员信任并依赖CI/CD过程。
当每天运行的CI减少时,可能是由于CI/CD系统使用缓慢或不方便造成的。
CI平均恢复时间(MTTR)
当构建不起作用时,我们无法进行测试、发布或部署。在这种情况下,每个人都应该停止他们正在做的事情,专注于恢复构建。平均恢复时间衡量一个团队修复损坏的CI构建平均需要多长时间。在衡量这个指标时,我们通常只关注主分支。
较长的恢复时间表明,我们需要努力使CI/CD过程更加稳健。我们还必须确保优先修复CI构建的习惯在团队文化中根深蒂固。
CI测试失败率
衡量CI管道因测试失败而失败的频率。测试是一个安全网,所以失败没有错。尽管如此,开发人员在提交代码之前应该在他们的机器上运行测试。如果失败率太高,这可能表明开发人员发现很难在本地运行测试。

CI test failure rate formula
CI成功率
CI成功率是成功的CI运行次数除以总运行次数。成功率低表明CI/CD过程很脆弱,需要更多的维护,或者开发人员过于频繁地合并未经测试的代码。

CI success rate
片状(Flakiness)
片状表示CI管道有多脆弱。片状构建在没有明显原因的情况下随机失败或成功。片状是由片状测试或不可靠的CI/CD平台引起的。缺陷测试会对CI运行时间、成功率和恢复时间产生负面影响。
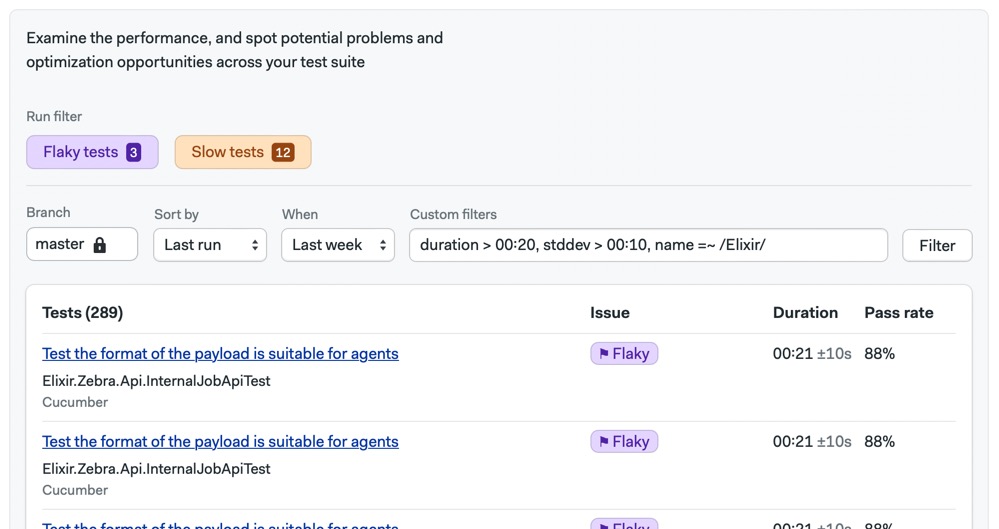
The Test Summary tab shows flaky and slow tests.
覆盖范围
代码覆盖率是测试套件覆盖的代码的百分比。这有点争议,因为众所周知,这是一个经常被滥用的指标。例如,要求100%的覆盖率并不能提高质量,相反,它会导致对琐碎代码进行不必要的测试。
和其他任何东西一样,适度使用覆盖率是有用的。例如,一个覆盖率为5%的项目无疑是测试不足,以至于测试结果没有向我们展示太多。
缺陷逃逸率
测量CI/CD进程未检测到的错误数。高值意味着测试不充分。在这种情况下,我们应该检查覆盖率值,然后重新评估测试套件的结构。我们的测试套件中可能需要更多类型的测试。

Defect Escape Ratio
正常运行时间
Uptime是应用程序可用时间的百分比。它越高,特定时期内的停机次数就越少。例如,99.9%的正常运行时间相当于每年8小时45分钟的停机时间。这个运营DevOps指标应该始终是我们衡量标准的一部分,因为每次站点或应用程序停机时,我们都有失去客户的风险。
正常运行时间值低表明基础结构、代码和/或部署过程中存在问题。
| Uptime | Total Yearly Downtime |
|---|---|
| 99.9 % | 8h 45m 56s |
| 99.99 % | 52m 35s |
| 99.999 % | 5m 15s |
| 99.9999 % | 31s |
服务水平指示器
签署服务级别协议(SLA)的企业必须注意正常运行时间,以避免罚款或其他处罚。服务级别指示器(SLI)将实际应用程序性能或正常运行时间与预定标准进行对比。
即使SLA没有生效,公司也可以建立内部服务水平目标(SLO),以实现相同的功能。
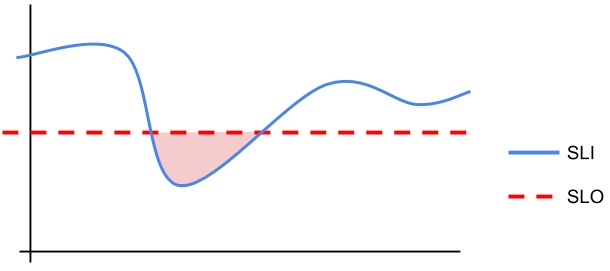
SLI shows reality versus SLA or SLO.
平均检测时间(Mean time to detection)
这是在发现问题并将其分配给相应团队之前,问题在生产中持续存在的平均时间。我们可以将其衡量为从问题开始到提出问题或罚单的时间。平均检测时间与监控的全面程度和通知的有效性直接相关。
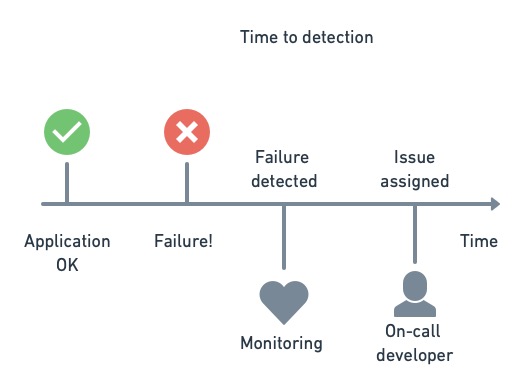
平均无故障时间(Mean time between failures)
衡量系统或子系统的平均故障频率。这是一个适用于衡量应用程序子组件稳定性的指标。它可以帮助我们确定哪些部分需要重构。
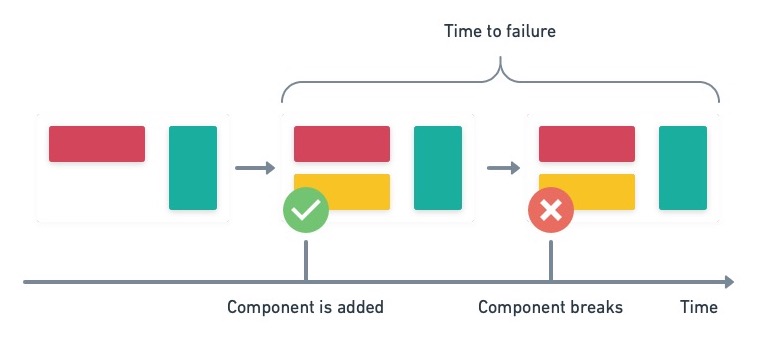
Time between failures.
Devops指标只是衡量症状
指标是项目的重要标志。一个糟糕的指标是一种症状,而不是疾病。他们指出了问题的存在,但没有明确说明根本原因。虽然通过“管理”指标下的变量来解决问题可能很诱人,但这样做类似于自我治疗——它只会成功地隐藏症状。像任何一位好医生一样,一位好的工程师会进行调查,提出解决方案,并通过检查指标是否有所改进来确认其有效性。
最新内容
- 5 days 7 hours ago
- 1 week 6 days ago
- 2 weeks 3 days ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago