
自2021年初以来,我们优选网络(PFN)正处于从HDFS转向Ozone的过程中。我们的Ozone集群已经被我们的ML/DL项目所采用,集群的使用量正在迅速增长,在过去两年中,我们已经多次扩大了集群。然而,随着集群的逐渐扩展,磁盘使用不平衡成为了一个问题。例如,将完全空的数据节点添加到所有现有磁盘已满80%的Ozone集群中,将导致集群使用率严重失衡。将数据移动到新添加的空服务器称为再平衡,但它的具体工作方式并不明显。在HDFS中,有平衡器,它在每个节点的指定阈值内均匀地移动块,还有磁盘平衡器,它将块在单个数据节点内的磁盘之间对齐。另一方面,Ozone有一个容器平衡器,起初再平衡在Ozone.2.0中似乎不起作用,因为它仍然是一个年轻的功能。因此,当我们最近添加新的数据节点时,我们决定执行手动再平衡作为紧急维护。在这篇文章中,我们从背景开始展示我们的全部故事。
(有关建立Ozone集群的更多信息,请阅读2021年的博客文章“与Apache Ozone共度一年”。)
存储系统在PFN的计算基础设施中的作用是提供一个地方来保存我们的ML/DL研究活动所需的数据,并在需要时高速读取数据。“所需数据”包括各种内容,如数据集、程序执行结果和作业检查点文件。最近,公司中通过使用CG和模拟进行计算来生成数据的用例[1][2][3][4]的数量有所增加,而且数据不断从无到有。我们一直在通过根据磁盘使用统计数据预测需求来购买和构建服务器,但最近很难估计,而且磁盘的填充速度比预期的要快。
通过购买服务器和磁盘设备来扩展集群实际上需要花费大量时间。如果我们在可用空间较低的阶段购买服务器,我们将无法跟上数据增长的步伐。我们购买并添加了新的服务器,同时收缩了HDFS集群,并多次将退役的HDFS数据节点重新部署为新的Ozone数据节点。值得庆幸的是,HDFS和Ozone都支持扩展和删除数据节点。然而,如上所述,由于采购条件和使用预测的困难,我们的集群扩展进展很小。图1显示了过去一年中我们集群的系统容量(橙色)和实际使用量(蓝色)的发展情况,这表明使用量的增长速度快于容量,而我们一直在重复添加服务器。我们计划进行系统扩展,以将数据使用率保持在80%以下,但最近几个月,使用率已达到这一极限。
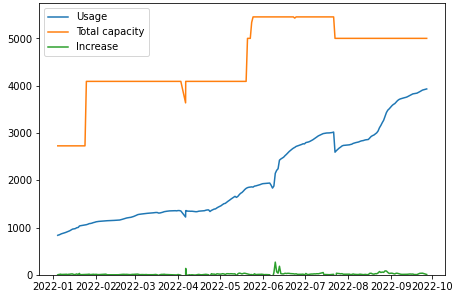
Fig. 1: Physical system capacity and actual usage of the Ozone cluster (Unit: TB)
增量群集扩展导致磁盘失衡
虽然整个集群的可用空间即将耗尽,但数据节点之间的磁盘使用不平衡也是一个问题。图2显示了每个数据节点的物理磁盘使用情况。在该图中,磁盘使用率高的数据节点是旧节点,而新添加的节点可以观察到磁盘使用率低。这种分布是不可取的,因为为了实现I/O负载平衡,磁盘使用应该尽可能均匀。此外,磁盘使用率高的节点会引起对磁盘已满的担忧。
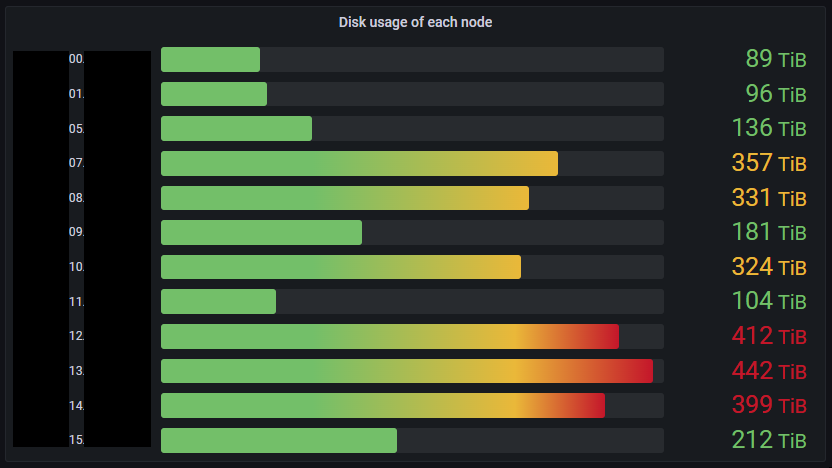
数据节点配置如表1所示,图2中各服务器的数据节点配置如下:
| Software | Apache Ozone 1.2.0 based custom version |
| CPU | Intel(R) Xeon(R) Silver 4114 x1 20c |
| RAM | 32GB DDR4 x16 |
| HDD | 14TB SATA 6GB/s 7200rpm x36 |
| Network | Mellanox ConnectX-6 (100GbE) x2 |
在Apache Ozone和Hadoop中,没有自动磁盘使用平衡的功能。对于HDFS,有一个Node Reblancer,它在启动时在数据节点之间移动数据,以实现磁盘使用均衡。Ozone有一个名为Container Balancer的组件,它可以在数据节点之间重新平衡数据,类似于HDFS,但不幸的是,Ozone 1.2中不支持它,因此我们还无法使用它。
在此期间,数据节点保持不平衡状态,并以相同的速度在所有节点上填充,无论是高使用率还是低使用率。一些数据节点的磁盘利用率超过90%,接近100%。当时,我们对Datanodes的磁盘将满时的行为一无所知。为了避免出现不可预测的状态,我们决定尝试停用接近磁盘满状态的Datanode。停用是一种从集群中安全删除数据节点、将数据节点上的所有数据复制到其他数据节点并将其从集群中删除的操作。如果我们有额外的空间,停用高利用率的数据节点不仅会防止磁盘满,而且我们可以期望数据统一写入其他数据节点。
由于每个数据节点的磁盘容量为每个硬盘14TB,并且线速足够快,因此我们开始停用时假设拷贝可以在几天内完成,即使考虑到它是一个硬盘。然而,它并没有像最初预期的那样在期限内结束,两个月过去了,节点状态仍处于“断开”状态。由于用于检查停用进度的CLI尚未实现,我们不得不直接在SCM中读取Replication Manager日志,我们发现停用在某个时候被卡住了。就在那时,我们放弃了通过删除节点重新定位和重新平衡数据的想法。
出现满磁盘节点
虽然我们尝试了容器平衡器和停用,但不幸的是,它对我们不起作用,时间一天天过去了,集群中的一些节点最终变成了磁盘满状态。在达到100%使用率的磁盘上,容器无法打开,如图3所示。容器[5]是Ozone的一个管理单元,它将最多5 GB的区块分组[6]。Ozone不像HDFS那样直接管理块,但它决定了容器单元中的数据放置和复制计数。
Ozone在打开容器时总是以写入模式打开RocksDB以读取元数据,并且似乎未能写入打开RocksDB.所需的日志[7]。对于这些情况,磁盘已满的节点上的容器将无法读取。
2022-09-07 15:36:24,555 [grpc-default-executor-8298] ERROR org.apache.hadoop.ozone.container.common.utils.ContainerCache: Error opening DB. Container:150916 ContainerPath:/data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db
java.io.IOException: Failed init RocksDB, db path : /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db, exception :org.rocksdb.RocksDBException While appending to file: /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db/MANIFEST-001861: No space left on device; status : IOError(NoSpace); message : While appending to file: /data/21/ozone/hdds/CID-xxx/current/containerDir38/150916/metadata/150916-dn-container.db/MANIFEST-001861: No space left on device
Fig. 3: Failure when opening RocksDB
即使某些数据节点的磁盘已满,唯一的影响是这些节点上的副本变得不可读,因此读取其他副本和写入不会受到影响。在PFN,尽管一些数据节点的磁盘已经满了,但每天都会生成大量数据并写入Ozone集群。几天后,更多的数据节点变为磁盘已满状态。如果复制集的副本计数不满足所需的复制因子,则无法读取此集中的数据。发生这种情况时,集群用户报告集群中的某些数据不可读。9月12日,集群中12个数据节点中有5个数据节点的磁盘已满。这意味着集群中超过一半的数据节点的磁盘已满。如果我们能够等待Ozone1.3.0的发布,容器平衡器可能会帮助我们,但我们需要尽快修复磁盘已满的数据节点,以最大限度地减少对我们研究活动的负面影响。
“手动”重新平衡的一种选择
通常,对于有状态的应用程序(如文件系统和数据库系统),应避免手动操作。这是因为系统应该保持一致性,而手动干预很容易由于简单的人为错误而破坏系统保证的完整性。基本上,管理所需的所有功能都应该以管理工具的形式提供。这是一个确保统一维护质量并提前避免一些意外操作错误的框架。
然而,由于Ozone目前的标准功能无法解决磁盘满的问题,而且预计手动再平衡将解决这个问题,而不是寻求现有功能的解决方案,因此我们决定尝试使用手动再平衡来恢复集群。
我们熟悉Ozone的内部数据结构,并有可能手动操作它。曾经有一段时间,我们定期聚集在一起阅读Ozone的源代码,如果有任何可疑或不清楚的地方,我们会检查当前工作版本的源代码。这一次对我们有所帮助。在接下来的部分中,我们将简要解释如何通过手动重新平衡来实际传输数据。
Ozone1.2.0的内部数据结构遵循容器布局V2,如图4所示。容器布局V2是一种格式,每个容器包含一个目录,称为容器目录。容器目录由元数据(RocksDB和YAML)和块(Blob)组成。
Ozone数据节点具有hddsVolumes,每个卷都将容器(由Ozone SCM管理)存储为由容器id标识的容器目录。容器id由SCM按顺序编号。
在PFN中,Ozone数据节点是以JBOD方式设置的,每个HDD对应一个hddsVolume。从理论上讲,容器只是文件系统中的一个目录,我们认为,如果我们能够在保持目录结构的同时将它们移动到其他数据节点,那么我们可能可以做与复制或容器再平衡相同的事情。

Fig. 4: HddsVolume structure in Container Layout V2
人工再平衡还有一个问题。如果我们可以手动移动容器位置,那么容器位置元数据的一致性是否存在问题?当数据节点启动时,它会扫描本地磁盘中的所有数据,然后将收集到的有关现有和可读容器的信息作为ContainerReport发送给SCM。这相当于HDFS中的BlockReport。如果我们完全停止Ozone,我们认为在数据节点之间移动容器是安全的,我们实际上通过一个小的测试案例证实了在停止一些数据节点的同时移动容器是成功的。
由于我们用小型测试用例确认了计划的操作,我们决定使用上述内部数据结构手动重新平衡磁盘使用情况。同时,由于我们可以通过缩小HDFS集群来添加七个新的数据节点,我们还决定通过添加数据节点来扩展Ozone集群。我们的手动再平衡政策是:
- 准备具有相同配置(相同数量的磁盘、相同容量)的数据节点
- 选择磁盘使用率高的(旧的)数据节点,并将一半的容器复制到新的数据节点
- 我们将数据节点(旧的)和数据节点(新的)配对,并且这些对是独占的和唯一标识的(为了简化和避免容器副本之间的冲突)
- 维护目录结构,使其在新旧之间遵循Container Layout V2,包括SCM ID和Container ID迁移
- 复制完成后从旧数据节点中删除容器
- 完全停止Ozone集群只是为了维护
- 停止服务是一个合理的选择,因为群集中超过一半的数据节点由于磁盘已满而无法为文件提供服务
- 向用户清楚地解释,在维护期间,存储服务将完全不可用,这是一项非常重要的维护
由于此次维护需要停止服务,我们决定制定更具体的时间表和详细的任务清单。
离线维护:计划和行动
进度计划
离线维护的注意事项包括:
- 确保有足够的操作时间
- 最小化维护周期,因为离线维护将暂停我们的研究活动
- 提供足够长的准备期
- 更长的时间允许用户为数据迁移做准备,并允许管理员验证维护说明
- 这是一种权衡,因为较短的周期可能会避免即将出现的其他与磁盘相关的意外问题
- 由于9月中旬有连续假期,增加了更多的宽限期(日本“白银周”)
- 在我们的工作时间内进行维护,为用户和管理员留出空间,以便快速处理一些意外问题
- 确保缓冲日
至于操作所需的时间,假设复制过程具有足够的并行性,我们可以估计维护时间相当于在每个数据节点中复制一半物理HDD卷大小的时间(14 TB/2=7 TB)。每个数据节点都通过100GbE网络相互连接,因此我们最初估计复制将在一天内完成。此外,我们还分配了一天作为缓冲区,并最终决定停止集群最多两天。为了确保有足够的准备时间,我们决定从维护公告到复制操作之间至少需要两周的宽限期。
抢救重要数据
由于我们将两周设置为修复该问题的准备时间,因此我们需要为那些希望立即使用由于磁盘满问题而当前不可用的文件的群集用户提供另一个选项。我们从集群中抢救了一些文件,直到维护完成,方法是从OM中获取元数据,从SCM中获取块的位置以识别数据节点,然后从数据节点上的容器中收集块以恢复原始文件。对于数据抢救,我们准备了读取Ozone元数据、下载块和重建块等操作,并使这些功能在集群之外普遍可用。实际上,手动执行这些操作很复杂,所以我们将它们作为自动化脚本来实现。
手动重新平衡的准备
手动再平衡说明的初步示意图为:
- 停止所有与Ozone有关的过程
- 准备新的数据节点并将其添加到集群中
- 将数据节点(旧)的一半数据复制到数据节点(新)
- 从数据节点删除完全传输的数据(旧)
- 启动Ozone
对于复制容器,因为实际上这些副本只是服务器之间的简单目录传输,所以我们决定使用rsync。这一次,由于我们只希望Datanode中有一半的容器,所以我们使用偶数容器ID传输容器。接受列表格式的传输目标作为其参数也是我们使用rsync的原因之一。图5显示了使用rsync传输容器的示例。在实践中,我们在一个Datanode中有36个HDD,因此我们对磁盘和服务器的数量重复此命令,但由于它可以充分并行化,因此传输时间相当于一个磁盘。
 Fig. 5: An example of filtering target containers and transferring them with rsync
Fig. 5: An example of filtering target containers and transferring them with rsync
由于这种维护需要停止Ozone集群,我们希望提前确保数据传输时间在维护窗口内合理。因此,我们发现,单个数据节点的完整拷贝仅拷贝7 TB就需要长达五天的时间。数据节点包含许多目录和条目,这会导致低吞吐量。为了最大限度地减少停机时间,我们使用了差异副本作为维护的前期工作。最后,维修说明如下:
- 预备:列出要复制的目标容器
- 预备:将目标数据的完整副本从数据节点(旧)复制到数据节点(新)
- 在窗口中:停止所有与Ozone有关的过程
- 在窗口中:在数据节点之间获取目标数据的差异副本
- 在窗口中:从Datanode(旧)中删除已完成的容器
- 在窗口中:从Datanode中删除步骤2中完整复制后删除的容器(新)
- 在窗口中:启动Ozone
当我们等待两周的平稳期时,又出现了两个磁盘已满的节点,现在有八个节点处于这种状态。图6显示了当时Datanode的磁盘使用情况。由于我们要添加七个节点,因此在实践中需要将维护过程更改为将两个数据节点中的容器合并为一个。
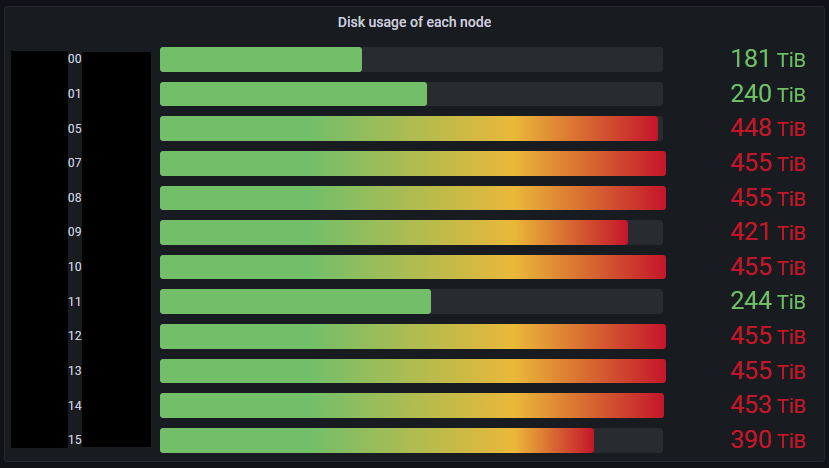 Fig. 6: Disk usage of Datanodes at the before the maintenance day
Fig. 6: Disk usage of Datanodes at the before the maintenance day
维护日
尽管我们不得不处理一些比预期更多的新的满磁盘节点,但由于作为前期工作执行的完整拷贝已经成功完成,直到维护日,我们停止了集群,并按计划执行了差异拷贝。对于差异复制,rsync有两种模式:比较时间戳和在文件之间进行校验和。我们没有使用校验和模式来加快速度。使用校验和模式需要计算所有目标文件的校验和,在这种情况下吞吐量很低。
最终,我们按时完成了维修工作。在这个维护日,我们通过手动重新平衡,从8个磁盘已满的数据节点减少到零,通过添加新的数据节点,整个集群的磁盘使用率也从85%减少到69%。图7显示了维护后集群的磁盘使用情况报告。与Ozone相关的磁盘使用率指示绿色条,这些条在集群之间几乎重新平衡,最终没有磁盘满的数据节点。
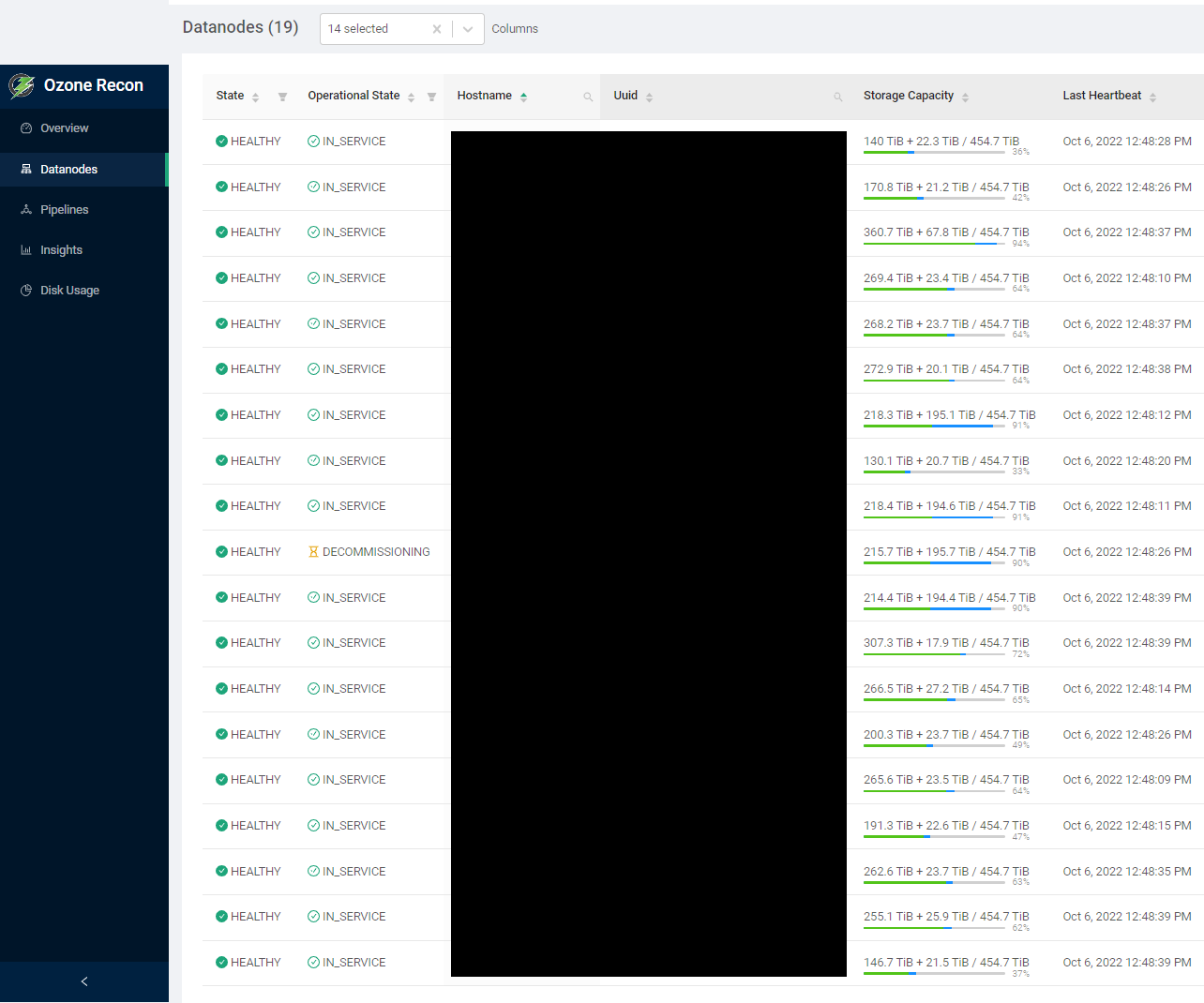
Fig. 7: The disk usage report after the maintenance
手动重新平衡,一个月后
9月22日进行了手动再平衡。截至目前,我们还没有因手动再平衡工作而引起的任何问题。此外,我们还修复了集群的其他一些配置问题。
已修复:某些复制已停止
我们注意到Datanodes在维护后使用的证书已过期。这些证书由数据节点之间的特定复制过程使用,并在第一次启动数据节点时自动初始化。Ozone RPC使用Kerberos进行身份验证,但一些复制操作依赖于SCM使用自签名CA颁发的此证书。实际上,有效期为一年,但Ozone 1.2.0中没有实现续订证书的功能。由于我们的集群具有长时间运行的Datanodes,因此节点中的一些证书已经过期。
这次我们手动续订了证书,这使复制工作正常。虽然更新后退役仍在进行中,但我们最初遇到的退役停滞的原因可能是证书过期。
已修复:修改的ContainerPlacementPolicy
我们仍然看到数据增长的不平衡。我们将尝试更改ContainerPlacementPolicy、PipelineChoosingPolicy和LeaderChoosePolicy等政策来改善这种情况。特别是,我们将用于选择数据节点作为容器放置的ContainerPlacementPolicy更改为用于选择最空闲数据节点的容量感知策略。由于该政策在Ozone 1.2.0中确实存在问题(由HDDS-5804修复),我们为内部分发备份了一个补丁。
未来的工作
Ozone仍然是一个年轻的软件,但社区非常活跃。虽然我们这次面临的问题包含在1.2.0版本中,但这些问题中的大多数都是为即将发布或未来的版本修复的,因此我们介绍以下内容。在PFN中,我们正在运行Ozone 1.2.x集群和主HEAD集群,以预测即将发布的1.3.0版本。从现在起,如果有必要,我们将在后台移植最新补丁的同时操作集群。
自动证书续订(HDDS-7453)
社区建议自动续订证书。这使我们能够通过手动更新来节省劳动。
退役可观测性改进(HDDS-2642)
退役进度现在作为指标导出。目前,我们需要读取SCM日志和Datanode状态,这是检查退役进度的唯一方法。这一建议使我们能够提高退役的可观察性。
保留卷空间(HDDS-6577和HDDS-6901)
HddsVolume现在可以在数据节点中声明一些保留空间。通过此更改,可以将磁盘空间限制为磁盘的某些边距,并防止磁盘已满,从而减少元数据故障。
容器平衡器(HDDS-4656)
现在我们有了Ozone容器平衡器。这就消除了像我们所做的那样手动重新平衡工作的必要性。这是我们运营集群的一个重要特征,我们将仔细评估我们的集群。
结论
由于集群的增量扩展,我们遇到了磁盘使用不平衡的情况,而且一些数据节点达到了磁盘已满的状态。这种情况使我们无法从这些节点读取数据。在这篇文章中,我们分享了我们的背景以及为什么我们做出手动再平衡的决定,并通过介绍Ozone数据节点的内部数据结构来分享我们的维护操作。我们决定通过停止集群来进行离线维护,因为超过一半的数据节点处于降级状态,并且精心设计了计划以最大限度地减少停机时间。
为了进行维护,一开始我们向Ozone集群添加了七个新的数据节点,然后手动将一半的容器从旧的数据节点移动到新的数据结点。虽然这次的维护需要对Ozone执行情况及其内部数据结构有深入的了解,但幸运的是,我们完成了维护,没有遇到任何问题,一个月后集群仍然健康。
参考文献
- [1] Development of Universal Neural Network for Materials Discovery, PFN Tech Blog, 2022
- [2] A Research for Geophysical Exploration Methods using a Deep Learning Technology (深層学習を用いた物理探査技術の研究開発; written in Japanese), PFN Tech Blog, 2021
- [3] An Analysis of Earthquake Wave with Machine Learning (機械学習を用いた地震波解析; written in Japanese), PFN Tech Blog, 2022
- [4] Learning Time Evolution Dynamics in Low-Dimensional Latent Spaces of Numerical Simulation Data (数値シミュレーションデータの低次元潜在空間における時間発展ダイナミクスの学習; written in Japanese), 2022
- [5] Containers, Documentations for Apache Ozone, 2021
- [6] Storage Container Manager, Documentations for Apache Ozone, 2021
- [7] MANIFEST, RocksDB Wiki, 2022
Tags
最新内容
- 20 hours 24 minutes ago
- 3 days 10 hours ago
- 1 month 3 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago