
为什么选择Apache Ozone?
为了解决首选网络PFN中不断增长的数据需求和新的使用案例,我们一直在寻找一种可以伪无限扩展的新存储系统。由于对模拟和人工智能的战略关注[1],数据使用量的增长远远超过预期,这使得存储系统比以往任何时候都更加重要。
尽管我们的文章(ja) Hadoop in Preferred Networks Hadoop – Preferred Networks Research 中描述的基本要求没有太大变化,而且自那时以来仍然对我们至关重要[2],但我们目前运行的Hadoop(HDFS)集群存在几个操作问题。例如,我们最大的Hadoop集群,其容量约为10PB,仍在Ubuntu 16.04上运行。由于我们对大型集群的就地升级(包括操作系统的升级)没有任何知识或经验,并且Ubuntu 16.04的生命周期已经延长[3],我们已经放弃了系统升级,并一直在寻找新的软件来取代HDFS。我们制定了选择替代存储软件、建立新集群以及逐步迁移数据的计划。
升级底层操作系统只是我们面临的问题之一。我们的用例中还有其他几个不适合典型的HDFS用法。然而,由于其稳定性和操作方便性,我们妥协并绕过了它们。以下是列表:
- 小文件问题[4]:文件数量的增加会导致元数据的增加。NameNode的负载取决于元数据、一组文件和文件的块位置列表。如果平均文件大小小于标准块大小,则文件数量增加得更快。特别是,在NameNode重新启动后从磁盘加载元数据需要花费大量时间。
为了解决这个问题,我们将一组小文件存储到HDFS上的一个大型ZIP档案中,并使用PFIO等库直接从ZIP读取文件(而不压缩档案)。
- 高密度磁盘服务器(HDD):当单个节点中包含更多硬盘驱动器时,每个磁盘容量的性价比会变得更好。另一方面,数据节点中完整块报告(FBR)的时间较长会影响数据的持久性和可用性。例如,最受欢迎的Hadoop分发提供商之一Cloudera不支持容量超过100TB的DataNodes和容量超过8TB的硬盘驱动器。相比之下,我们在PFN的一些数据节点配备了36个硬盘,容量为14TB。
- 与Python运行时更好的亲和力:从Python访问HDFS的标准方法是使用libhdfs2通过JNI中的Java Hadoop客户端读取和写入数据。复杂的软件堆栈施加了各种限制,使HDFS难以使用。最难的例子是PyTorch DataLoader,它并行分叉许多进程以更快地加载数据。为了在不使用JVM的情况下正确运行DataLoader,代码中需要非常小心,通过仅在分叉之后启动JVM来防止分叉已启动的JVM。
- 经典身份验证:尽管基于Kerberos的身份验证系统可靠且成熟,但其通过kinit(1)获取令牌的身份验证方法并不适合在Kubernetes Pods中执行,因为它需要额外的身份验证工具。在PFN中,我们通常在运行主容器之前在initContainer中运行kinit,使用存储为Kubernetes机密的keytab文件。更简单的身份验证方法,例如仅在初步环境变量中要求机密,会使我们的清单更加简单。
- NameNode可扩展性:为了扩展HDFS中的元数据管理,已经发布了许多系统,如HDFS Federation。它们主要涉及名称节点数量的增加,例如系统中更多的移动部件,这增加了整个系统管理的复杂性。
虽然这些问题一直让管理员感到非常疲惫,但它们也是系统用户抱怨的根源。Hadoop开发人员肯定已经意识到了这一点,因此Apache Ozone是从Hadoop中派生出来的,以解决这些问题。Apache Ozone如何解决这些问题如下:
- 小文件问题:在Ozone中,管理过去属于NameNode的元数据和块位置的职责分别分配给Ozone Manager(OM)和Storage Container Manager(SCM)。定义了一个称为“容器”的新块单元集,SCM只管理容器及其复制和位置。这种拆分还使得元数据的增加仅与文件数量成比例,并且仅影响OM中文件表的内存大小。目录树访问变得更快,因为文件表存储在更高效的数据库RocksDB中。
- 高密度磁盘服务器:由于设计的改变,FBR变得更快。DataNodes只需要向SCM报告容器。一个容器最多可以存储2^64个块——通过控制容器中块的平均数量,我们可以控制SCM的总体负载。
- 与Python运行时更好的相关性:添加了新的API端点。它与AWS S3兼容。它的生态系统如此庞大,以至于不仅它的SDK以各种语言提供,而且许多软件都有一个AWS S3(以及兼容的对象存储系统)的抽象来读取
- NameNode可扩展性:由于NameNode的职责被划分并转移到OM和SCM,底层数据存储被迁移到RocksDB,元数据扫描和更新的性能得到了很大的提高。我们不能说我们不再需要像HDFS联邦这样的扩展噱头,但一个相当大的集群可以通过当前的设计进行管理。Cloudera测试了插入100亿个物体的Ozone [5]。
就在我去年发表了这篇博客文章[2]之后,我们开始测试Apache Ozone作为下一代对象存储系统,并且已经运行了几个月。
虽然在测试过程中,我发现并报告了CVE-2020-17517[6],但没有任何严重或关键的问题值得使用阻断剂。我们将该服务作为阿尔法服务向内部用户开放,并继续不断添加知识。API的覆盖范围远不是AWS S3的全部功能,但我们认为我们可以为社区贡献重要的功能和修复,因为社区一直非常活跃。
群集配置和设置
我们在MN-2中的一台管理服务器上安装了OM和SCM,在4台存储服务器上安装DataNode[7]。它们的物理规格如表1和表2所示。表1适用于DataNode;36个硬盘驱动器都被格式化为ext4分区(每1个驱动器1个分区),并被Ozone用作JBOD。
表1:DataNode的服务器规范
| Type | Amount | |
| CPU | Intel(R) Xeon(R) Silver 4114 | 1 |
| Memory | 32GB DDR4 | 12 ※1 |
| HDD | 14TB SATA 6GB/s 7200rpm | 36 |
| Network | Mellanox ConnectX-6 (100GbE) | 2 |
表2是运行OM和SCM的管理服务器的规范。为了持久保存元数据,它配备了四个15TB NVMe SSD,这些SSD捆绑为raidz分区。我们选择ZFS是因为我们在OpenZFS方面有一些经验,而且它有一组简单一致的CLI,很容易理解。在该分区中,OM和SCM存储它们的元数据。这种配置在SSD出现单次故障时仍然有效。
表2:Ozone 管理器和存储容器管理器的服务器规格
| Type | Amount | |
| CPU | Intel(R) Xeon(R) Silver 4114 | 1 |
| Memory | 32GB DDR4 | 12 ※1 |
| NVMe | 15TB PCIe Gen3 | 4 |
| Network | Mellanox ConnectX-6 (100GbE) | 2 |
※1稍后,通过添加四个32GB棒,每个节点的内存将扩展到512GB。
操作系统是Ubuntu 18.04,它是我们在MN-2集群中设置物理服务器时安装的。由于之前在另一台服务器中有NVMe SSD管理的经验,我们在元数据服务器上安装了Linux 5.4.0 HWE内核。我们重新使用了构建MN-2集群时安装的Oracle JDK 8u162。
我们使用Apache Ozone 1.0.0从这些服务器构建了一个安全的集群。
图1描述了Ozone 集群的简单配置。在存储服务器中,DataNode和S3Gateway正在运行。在元数据服务器中,OM和SCM正在运行。S3Gateway是一个网关过程,它将S3 API访问转换为Ozone 原生API。S3Gateway进程公开为HTTP API服务器。来自客户端的访问通过DNS循环分布在网关进程中。我们没有使用HAProxy之类的反向代理进程来消除HDD到客户端进程内存空间的任何潜在瓶颈。在Ozone 1.0.0中,OM已经具有通常可用的高可用性(HA)功能,但它会引入一些操作复杂性,并且由于SCM没有HA,无法删除SPoF(单点故障)。因此,我们没有使用OM的HA功能。
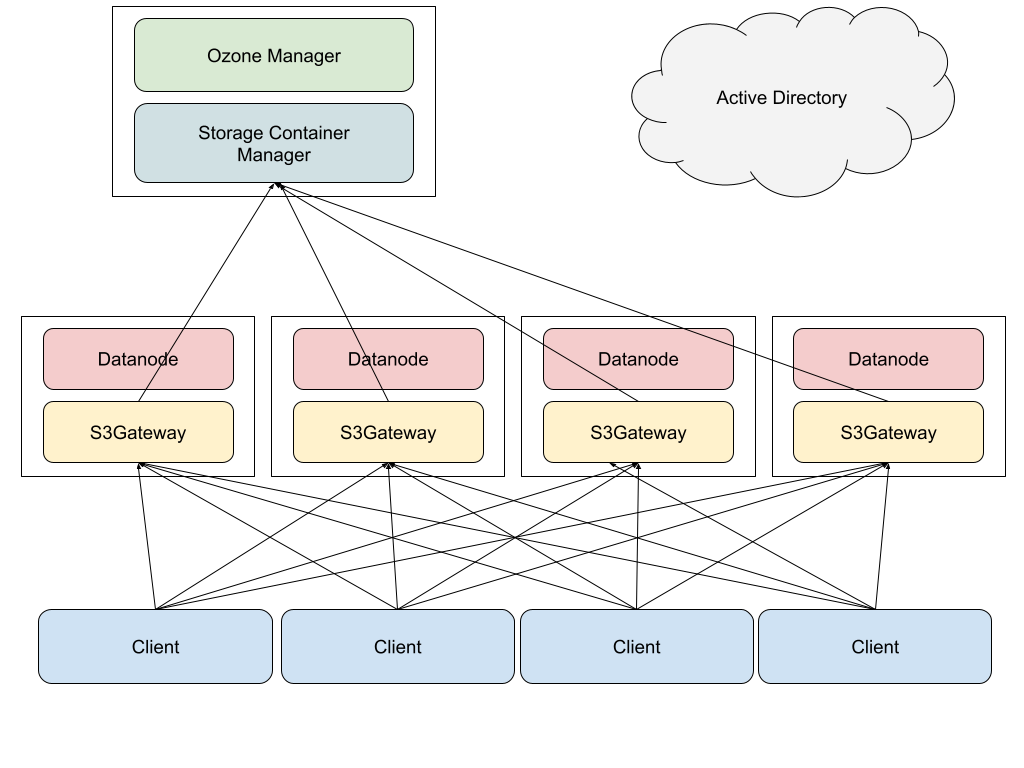 Figure 1: simplified picture of processes
Figure 1: simplified picture of processes
我们运行了一个访问大小约为200GB的文件的简单基准测试。我们构建了一个并行读取的基准脚本,将其部署为Kubernetes集群中的几个客户端Pod,并在更改并发量的同时测量其性能。图2显示了所有客户端的总吞吐量。当并发量为128时,最大吞吐量略低于4GB/s。潜在的最大吞吐量将通过64和256之间的客户端中的某个并行点来获得。目标数据的大小小于磁盘缓存总容量的大小,我们有4个节点有20个核心CPU(总共80个核心处理来自所有客户端的请求),以及DataNodes的总CPU使用率饱和在100%左右,这表明瓶颈在服务器端。

Figure 2: performance of parallel download of a blob file
在这个基准测试之后,我们开放了该服务供内部使用。几个月后,我们现在有几个内部用例,例如机器学习和备份。起初,我想我可以在这里详细分享其中的一些,但事实证明,它们中的大多数与深度学习中的标准工作负载没有太大区别。
历史和当前状态
在我们于2021年初建立集群后,Ozone 1.1.0于4月发布。我们在发布后立即升级了集群。
不是因为新版本,而是集群的管道(多Raft实例的单元)分布不平衡。我们期望4个节点和36个硬盘驱动器——期望SCM创建36*4/3=48个管道。但它没有起作用;SCM只创建了36个管道,我们没有充分利用144个HDD,只有108个存储了数据。后来,我们添加了另外两个存储服务器作为DataNodes,总共在6个DataNodes中创建了72个管道,最后我们充分利用了所有的HDD。如果你想了解更多关于管道的信息,请参阅Cloudera的博客文章[8]。
我们已经运行Apache Ozone好几个月了。它拥有所有具有HTTPS侦听/prom端点的组件,并以Prometheus Exposition格式公开了各种度量。我们使用普罗米修斯收集这些指标,并使用格拉法纳进行可视化。此外,我们还设置了Alertmanager,以便在出现某些异常情况时获得通知。截至今天,它拥有3000多万件物品和400多个水桶。图3描述了最近数据量的增加。
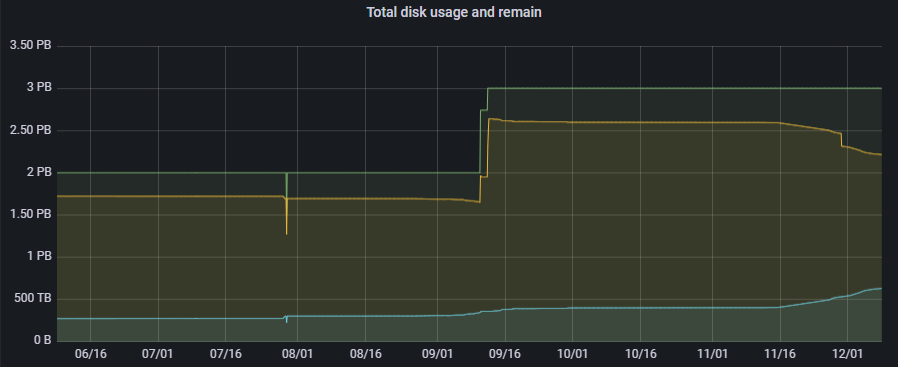
Figure 3: Historical and total disk usage and capacity of our Ozone cluster (physical)
设置后,我们做了一些上游贡献,以解决操作过程中发现的问题。我们已经报告了1.1的CVE-2020-17517。1.2的主要贡献如下:
- HDDS-5197(修补程序)
- HDDS-5620(修补程序)
- HDDS-5893(修补程序)
- HDDS-4856(报告)
- HDDS-5005(报告)
- HDDS-5393(报告)
还有几个其他贡献合并到1.3.0或仍在进行中。对这些问题的描述将很长,并将在单独的博客文章中介绍。除了上游贡献外,我们精心挑选了HDDS-5472,并于9月将其应用于集群。这个补丁极大地提高了OM的性能,集群变得非常稳定。10月,我们切换到了OpenJDK 1.8.0。Ubuntu 18.04提供了补丁级别1.8.0-292,其中包括服务器端的TLS处理性能。
11月,1.2.0发布,并针对过去版本中的漏洞进行了多次修复。我们在发布后立即进行了升级,进展非常顺利,没有出现任何重大问题。毫无疑问,我们未来还有很多工作要做,分为三大类。。
OM和SCM中的高可用性
在当前设置中,OM和SCM中的元数据使用ZFS在多个磁盘上复制。但我们在服务本身仍有几个单点故障。例如,如果运行OM和SCM的机器出现故障,这些进程肯定会停止,因此服务将全部停止。Ozone 1.2.0具有通过Raft复制这些服务的HA功能,Raft运行三个复制的进程,并允许在单节点故障的情况下进行服务故障切换。该服务的可用性将大大提高,并降低在PFN中更广泛的实际工作负载用例中采用Apache Ozone的门槛。
Ozone 的集群扩展与HDFS的迁移
截至目前,HDFS集群总共存储约9PB的数据,而Ozone 中的数据量仍在200TB左右。基本上,我们希望HDFS中的所有数据都迁移到Ozone 层。此外,我们的业务工作量产生的新数据将新存储在Ozone 中。绝对需要更多的容量——随着数据迁移的进展,我们确实计划逐步将HDFS数据节点转移到Ozone,但在全面迁移真正开始之前,我们对可以从HDFS移动多少节点的前景很渺茫。我确实记得,过去一些存储系统中的数据量甚至在其使用寿命结束之前都没有减少,我们只能无奈地手动清理这些数据。
有几种方法和路径可以迁移数据。在具有相同KDC(Kerberos的密钥分发中心,我们有多个)的集群之间,我们将能够在它们之间运行distcp。在使用不同KDC的情况下,distcp可以使用s3a协议,并且似乎是可行的。但有一个问题是HDFS对文件大小没有限制,S3 API的最大文件大小为5TB。我们在HDFS中确实有几个超过5TB的文件。
新特点与上游贡献
没有一个软件是完美的,因此,当我们继续使用它时,我们可能会发现一些缺点。我们不仅会等待社区改进或解决这些缺点,还会尝试自己去做。我们将继续努力发送补丁。我们已经有了其中的一些;一些重要补丁和建议如下:
- HDDS-5656–多部分上传优化
- HDDS-5905–潜在的数据丢失
- HDDS-5975–ListObjects错误修复
结论
在PFN中,从Apache Hadoop到Apache Ozone的迁移一直在进行中。我们介绍了它的背景、实际设置和基准。我们预计数据将持续增加,我们将扩大我们的集群。我们还努力在行动期间不断向社区发送我们的反馈和贡献。
参考
- [1] 《日経Robotics》AIによるシミュレーションの進化 :PFN岡野原氏連載 第56回
- [2] Preferred Networks におけるHadoop – Preferred Networks Research
- [3] Ubuntu 14.04 and 16.04 lifecycle extended to ten years
- [4] The Small Files Problem
- [5] Future of Data Meetup: Apache Ozone – Breaking the 10 billion object barrier
- [6] NVD – CVE-2020-17517
- [7] PFN’s Supercomputers – Preferred Networks
- [8] Multi-Raft – Boost up write performance for Apache Hadoop-Ozone
- [9] HDFS | CDP Private Cloud
Tags
最新内容
- 1 day 7 hours ago
- 5 days 7 hours ago
- 1 month 3 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago