
介绍
推荐系统是数据科学家工具箱中的一个重要工具。目标很简单,给定客户和他们购买的商品的数据,自动推荐他们喜欢的其他产品。你可以在很多网站(比如亚马逊)上看到这些系统在运行,它不仅限于实体产品,还可以用于任何客户交互。推荐系统在以前的剑桥火花教程中介绍过。
在本教程中,我们希望通过向您展示如何使用尖端算法在python中构建推荐系统来扩展上一篇文章。许多传统的推荐系统训练方法由于一个被称为过度拟合的过程而不善于进行预测。在推荐系统的上下文中过度拟合意味着我们的模型将很好地拟合我们拥有的数据,但不擅长向客户推荐新产品(考虑到这是他们的目的,这并不理想)。这是因为丢失的信息太多了。在进入代码之前,我们将详细介绍推荐系统,为什么会有这么多信息丢失,以及它的解决方案。
推荐系统与矩阵分解
推荐系统的数据输入可以看作是一个大矩阵,行表示客户的条目,列表示特定项的条目。我们把这个叫做矩阵。然后输入????????????将包含客户对产品????的评分。例如,如果是一个评论,那么它可以是1-5之间的数字,或者它可能只是0-1,表示用户是否购买了某个商品。这个矩阵包含了很多丢失的信息,客户不太可能在亚马逊上购买每一件商品!推荐系统的目标是通过预测客户对缺少评分的项目的评分来填写缺少的信息。然后推荐系统将向客户推荐得分最高的项目。下图给出了矩阵????的一个典型示例,其中的条目是从1到5的评审值。
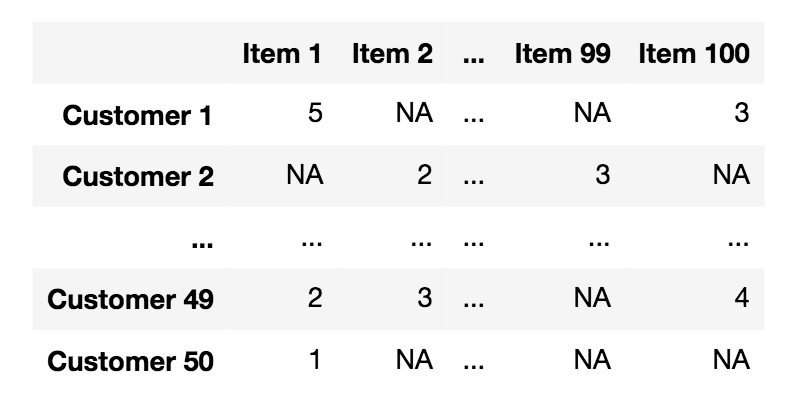
Netflix挑战赛是一场旨在为推荐系统寻找最佳算法的竞赛。它是由Netflix使用他们的电影数据运行的。在这次挑战中,有一种算法以其优异的性能脱颖而出,并一直广受欢迎。它被称为矩阵分解。该方法通过尝试将矩阵????分解为两个低维矩阵????和????,从而使????=????74880;????。
假设R具有维度????××????,那么U将具有维度????××????,V将具有维度????××????。这里的????是由用户选择的,它需要足够大,以编码????的细微差别,但使其过大会使性能变慢,并可能导致过度拟合。????的典型尺寸是20。
虽然乍一看,这种分解似乎很容易,但由于所有缺失的数据,它变得更加困难。输入数据可能有用,但这使方法非常缓慢。相反,大多数流行的方法只关注已知的矩阵项,并拟合因子分解以最小化这些已知项的误差。但这样做的一个问题是,预测会因为过度拟合而变得糟糕。这些方法通过使用一种称为正则化的过程来解决这个问题,正则化是一种减少过度拟合的常见方法。有关方法工作的更多细节,请参阅本文末尾的进一步阅读。
开发包
在本教程中,我们将使用surprise package,这是一个在Python中构建推荐系统的流行包。Mac和Linux用户可以通过打开终端并运行pip install surprise来安装此软件包。Windows用户可以使用conda conda install-c conda forge scikit surprise安装它。然后可以用标准的方式导入包,

数据集
在本教程中,我们将使用librec FilmTrust数据集,该数据集最初是为特定的推荐系统文件整理的。该数据集包含来自FilmTrust平台不同用户的35497个电影分级。我们选择这个数据集是因为它相对较小,所以示例应该运行得很快。包惊喜内置了许多数据集,但是我们选择了这个,因为它允许我们演示如何将自定义数据集加载到包中。通常,推荐系统会使用比这更大的数据集,因此对于更具挑战性的数据集,我们建议调查grouplens网站,该网站有各种可用的免费数据集。
首先,我们将从web下载数据集,并作为pandas数据帧加载到数据文件中。我们可以使用以下命令

正如您所看到的,这个数据集并不像矩阵RR。这是因为丢失的值太多,所以以稀疏格式保存文件要容易得多。在稀疏格式中,第一列是矩阵ii的行号;第二列是矩阵jj的列号;第三行是矩阵条目RijRij。对于这个数据集,第一列是用户ID,第二列是他们评论过的电影的ID,第三列是他们的评论分数。这种稀疏格式也是矩阵分解方法需要的输入,而不是完整的矩阵RR,这是因为它们只使用不丢失的矩阵项。
模型拟合
现在是时候开始使用这个包了。首先,我们需要将数据集加载到包惊奇中,这是使用Reader类完成的。Reader类的主要功能是指定评论的范围。我们先检查一下这个数据集的评论范围。

所以我们的审查范围从0.5到4,这有点不标准(惊奇的默认值是1-5)。因此,当我们加载到数据集中时,需要更改此设置,如下所示:

我们将使用SVD++方法,它是Netflix挑战赛中表现最好的方法之一,现在已经成为一种适合推荐系统的流行方法。如前所述,该方法仅通过优化已知项和执行正则化来扩展普通SVD算法,如前一篇博客文章中所述(请注意,令人惊讶的是,该方法SVD比普通SVD复杂得多,并且更类似于SVD++)。关于方法细节的更多细节可以在进一步的阅读中找到。使用SVD++构建的简单推荐系统可以编码如下:

现在我们只是在整个数据集上训练了模型,这不是很好的实践,但是我们这样做只是为了让您了解模型和预测是如何工作的。稍后我们将介绍正确的测试和评估;以及用于最大化性能的超参数调整。
现在我们已经拟合了模型,我们可以使用预测方法来检查例如,音乐艺术家52上的用户50的预测分数。

所以在这个例子中,估计是3分。但是为了向用户推荐最好的产品,我们需要找到n个预测得分最高的项目。我们将在下一节中这样做。
提出推荐
让我们向特定用户提出建议。让我们关注uid 50并找到一个推荐它们的项目。首先,我们需要找到用户50没有评分的电影ID,因为我们不想向他们推荐他们已经看过的电影!

接下来,我们要预测用户50没有评分的每个电影id的得分,并找到最好的一个。为此,我们必须创建另一个数据集,其中包含我们希望以稀疏格式预测的iid,与之前一样:uid,iid,rating。我们将任意地将这个测试集的所有评分设置为4,因为它们是不需要的。让我们这样做,然后输出第一个预测。

从输出中可以看到,每个预测都是一个特殊的对象。为了找到最好的,我们将把这个对象转换成一个预测评级的数组。然后我们会用这个来找到预测评分最好的iid。

当你实现你自己的推荐系统时,你通常会有元数据,允许你从iid代码中获取,例如电影的名字。不幸的是,此数据集不包含此信息,但许多其他较大的数据集也包含此信息,例如movielens数据集。
类似地,您可以获得用户50的前n个项,只需根据这个stackoverflow问题将argmax()方法替换为argpartition()方法。
调整和评估模型
正如您可能已经知道的,在整个数据集上拟合一个模型而不检查其性能和调整影响拟合的参数是一种糟糕的做法。因此,在本教程的其余部分中,我们将向您展示如何优化SVD++的参数并评估该方法的性能。SVD++方法以及大多数其他矩阵分解算法将取决于一些主要的调整常数:影响UU和VV大小的维度DD;影响优化步骤性能的学习速率;影响模型过度拟合的正则化项;以及阶段数,它决定了优化的迭代次数。
在本教程中,我们将调整学习率和正规化术语。SVD++有多个学习率和正则化项。但是惊奇可以为所有的学习率值设置一个固定值,为所有的正则化项设置一个固定值,所以我们将为速度设置一个固定值。令人惊讶的是,调优是使用一个名为GridSearchCV的函数来执行的,该函数选择在预测延迟测试集方面性能最好的常量。这意味着需要预定义要尝试的常量值。
首先,让我们定义要检查的常量值列表,通常学习率是介于0和1之间的一个小值。在理论上,正则化参数可以是任何正实值,但在实践中它是有限的,因为设置得太小会导致过度拟合,而设置得太大会导致性能不佳;因此尝试一个合理的值列表应该是很好的。然后可以使用GridSearchCV函数通过交叉验证来确定性能最佳的参数值。我们选择了一个非常有限的列表,因为这段代码可能需要一段时间才能运行,因为它必须适合具有不同参数的多个模型。

输出输出输出打印在保持测试集上获得最佳RMSE的参数组合,RMSE是测量预测误差的一种方法。在这种情况下,我们只检查了一些调整常量值,因为这些过程可能需要一段时间才能运行。但通常情况下,您会尝试尽可能多的值以获得最佳性能。
可以使用交叉验证来评估您选择的特定模型的性能。例如,这可以用来比较许多方法,或者只是检查方法是否正常执行。这可以通过运行以下命令来完成:

进一步阅读
现在,您知道了如何使用Python包suppent来适应高性能推荐系统,以及如何使用它为用户生成预测,以及如何优化系统以获得最大性能。我建议您查看文档以获得惊喜,从而帮助您真正了解该包,也许可以使用调整常量了解如何最大限度地提高推荐系统的性能,以及使用更复杂或更大的数据集来尝试该包。
对于那些想了解更多的人,这里列出一些推荐阅读:
- Get the top 10 scoring items for each user: package FAQ for
surprise - Review paper of matrix factorisation methods for recommender systems
- Repository of matrix factorisation datasets at Grouplens
- Another article on matrix factorisation which has more detail on the underlying maths
原文:https://blog.cambridgespark.com/tutorial-practical-introduction-to-recommender-systems-dbe22848392b
本文:http://jiagoushi.pro/node/949
讨论:请加入知识星球或者微信圈子【首席架构师圈】
- 登录 发表评论
- 94 次浏览
Tags
最新内容
- 5 hours 45 minutes ago
- 1 month 2 weeks ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago