
category
人工智能机器学习正在解锁在线产品推荐、图像分类、聊天机器人、预测和制造质量检查等领域的突破性应用。人工智能有两个部分:训练和推理。
- 推理是人工智能的生产阶段。训练好的模型和相关代码部署在数据中心或公共云中,或者部署在边缘进行预测。这一过程被称为推理服务,由于以下原因而变得复杂:
- 多种模型框架:数据科学家和研究人员使用不同的人工智能和深度学习框架,如TensorFlow、PyTorch、TensorRT、ONNX Runtime或纯Python来构建模型。这些框架中的每一个都需要一个执行后端来在生产中运行模型。
不同的推理查询类型:推理服务需要处理不同类型的推理查询,如实时在线预测、离线批量、流式数据和多个模型的复杂管道。每一个都需要特殊的推理处理。 - 不断发展的模型:根据新数据和新算法不断对模型进行再培训和更新。因此,生产中的模型需要不断更新,而无需重新启动服务器或任何停机时间。一个给定的应用程序可以使用许多不同的模型,并且会使规模复杂化。
- 多样化的CPU和GPU:这些模型可以在CPU或GPU上执行,并且有不同类型的GPU和CPU。
通常,组织最终会有多个不同的推理服务解决方案,每个模型、每个框架或每个应用程序。
NVIDIA Triton推理服务器是一款开源推理服务软件,通过解决上述复杂性,简化了组织的推理服务。Triton提供了一个单一的标准化推理平台,可以支持在多框架模型上、在CPU和GPU上以及在数据中心、云、嵌入式设备和虚拟化环境等不同部署环境中运行推理。
它本机支持多个框架后端,如TensorFlow、PyTorch、ONNX Runtime、Python,甚至自定义后端。它通过高级批处理和调度算法支持不同类型的推理查询,支持实时模型更新,并在CPU和GPU上运行模型。Triton还旨在通过并行模型执行和动态批处理最大限度地提高硬件利用率,从而提高推理性能。并发执行允许您在同一GPU上并行运行一个模型的多个副本和多个不同的模型。通过动态批处理,Triton可以在服务器端动态地将推理请求分组在一起,以最大限度地提高性能。
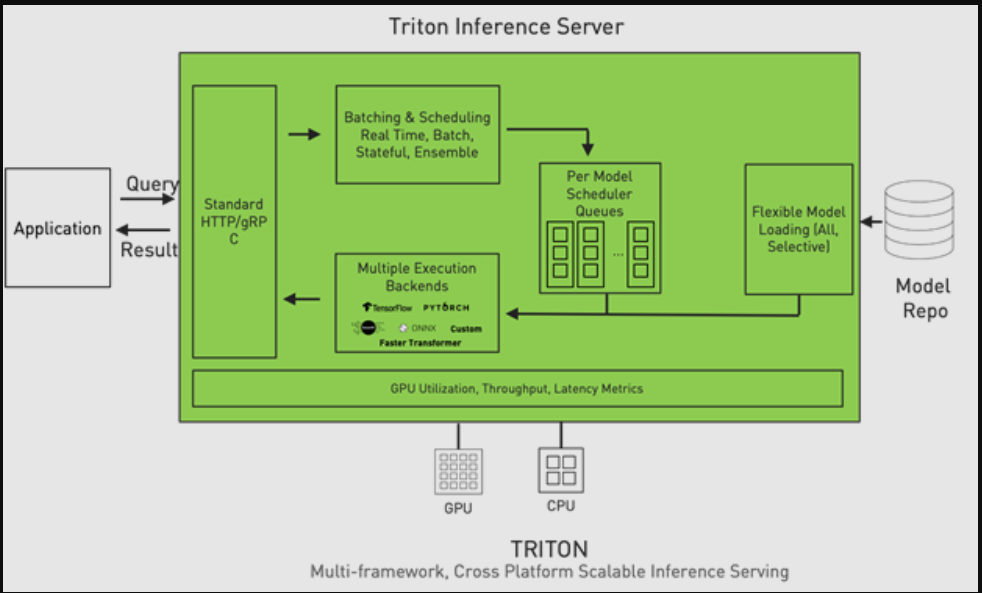
Figure 1. Triton Inference Server architecture.
自动模型转换和部署
为了进一步简化在生产中部署模型的过程,2.9版本引入了一套新的功能。经过训练的模型通常不会针对生产中的部署进行优化。您必须针对特定的目标环境进行一系列转换和优化。以下过程显示了在GPU上使用Triton的TensorRT部署。这适用于任何推理框架,无论它是部署在CPU还是GPU上。
- 将不同框架(TensorFlow、PyTorch)的模型转换为TensorRT以获得最佳性能。
- 检查优化,例如精度。
- 生成优化的模型。
- 验证转换后模型的准确性。
- 手动测试不同的模型配置,以找到最大化性能的配置,例如批量大小、每个GPU的并发模型实例数。
- 准备Triton的模型配置和存储库。
- (可选)为在Kubernetes上部署Triton准备Helm图。
正如您所看到的,这个过程可能需要花费大量的时间和精力。
您可以在Triton中使用新的模型导航器来自动化这一过程。作为阿尔法版本提供,它可以将输入模型从任何框架(本版本支持TensorFlow和PyTorch)转换为TensorRT,验证转换的正确性,自动找到并创建最优化的模型配置,并为模型部署生成回购结构。现在,每种类型的模型可能需要几天的时间才能完成。
优化模型性能
为了高效的推理服务,您必须确定最佳的模型配置,例如批量大小和并发模型的数量。现在,您必须手动尝试不同的组合,以最终找到适合您的吞吐量、延迟和内存利用率要求的最佳配置。
Triton Model Analyzer是另一个优化工具,它通过自动为模型找到最佳配置来获得最高性能,从而自动为您进行选择。您可以指定性能要求,如延迟限制、吞吐量目标或内存占用。模型分析器搜索不同的模型配置,并找到在您的限制下提供最佳性能的配置。为了帮助可视化顶级配置的性能,它输出一个摘要报告,其中包括图表(图2)。
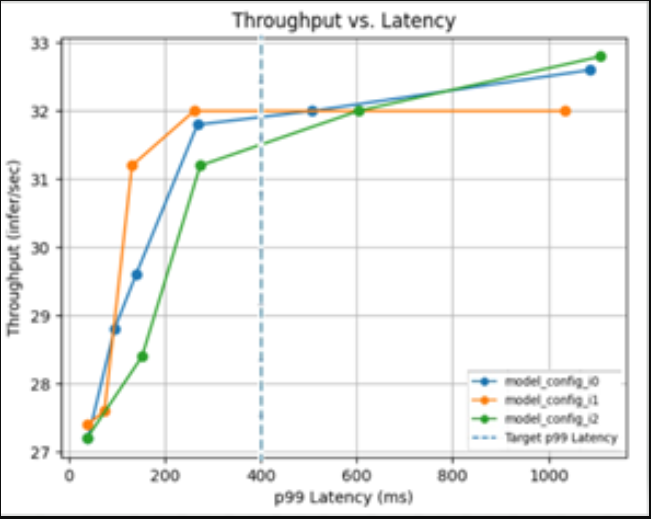
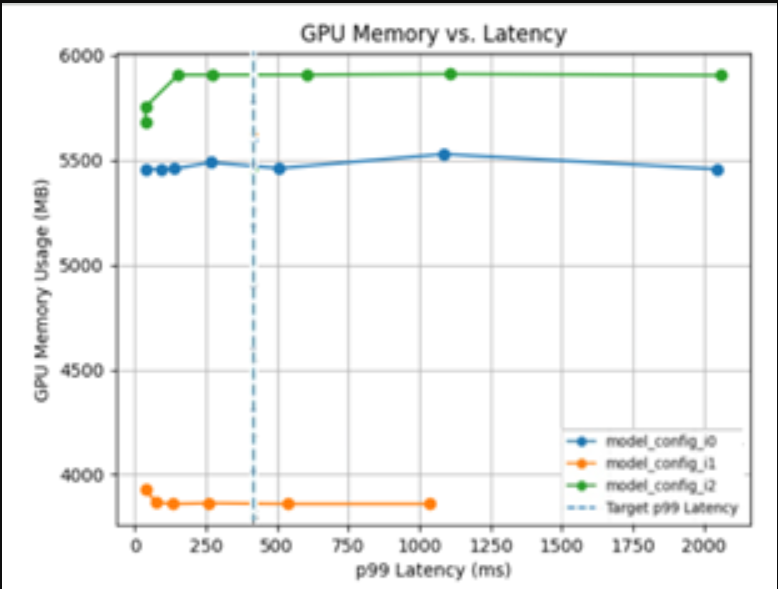
Figure 2. Choosing optimal configuration with Triton Model Analyzer.
您不必满足于优化程度较低的推理服务,因为获得优化模型的固有复杂性。您可以使用Triton轻松获得最有效的推断。
Triton一巨型模型推断
模型正在迅速发展,尤其是在自然语言处理领域。例如,考虑GPT-3模型。其全部能力仍在探索之中。它已被证明在阅读理解和文本摘要、问答、类人聊天机器人和软件代码生成等用例中是有效的。
在这篇文章中,我们不深入研究模型。相反,我们关注的是这种巨大模型的成本效益推断。GPU自然是这些工作负载的正确计算资源,但这些模型太大,无法安装在单个GPU上。有关在多GPU、多节点系统上训练巨型模型的框架的更多信息,请参阅使用威震天将语言模型训练扩展到万亿参数。
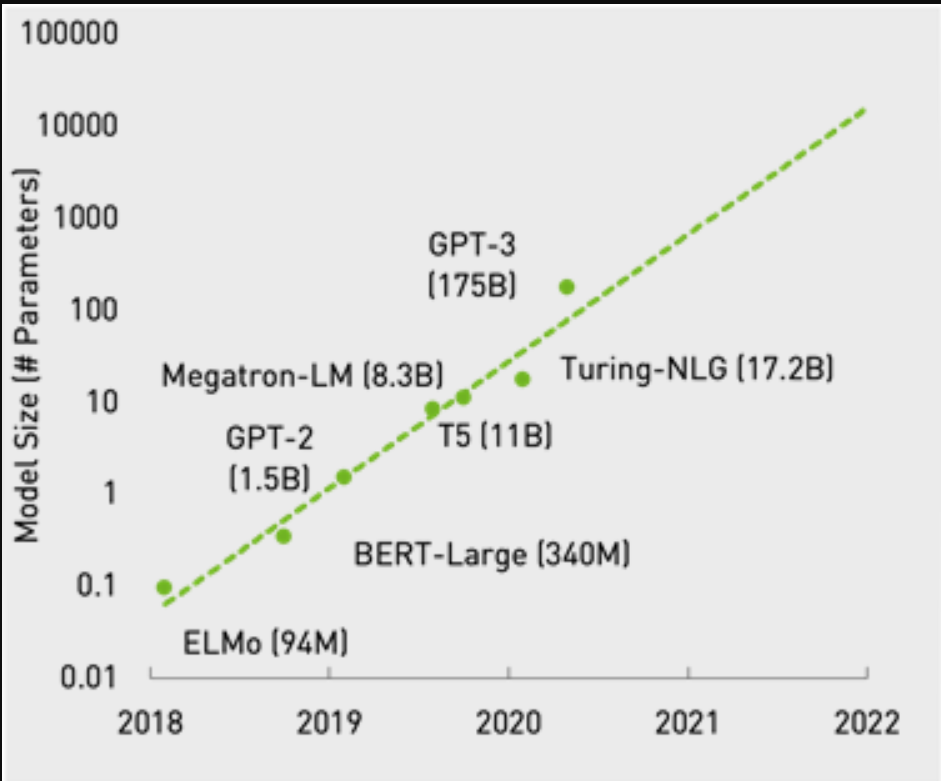
Figure 3. Exponential growth in the size of language models.
为了进行推理,必须将模型拆分为多个较小的文件,并将每个文件加载到单独的GPU上。拆分模型通常有两种方法:
- 管道并行性跨层边界垂直拆分模型,并在管道中的多个GPU上运行这些层。
- 张量并行性横向切割网络,并在GPU之间分割各个层。
Triton自定义后端功能可用于运行多GPU、多节点后端。此外,Triton还具有可用于管道并行的模型集成功能。
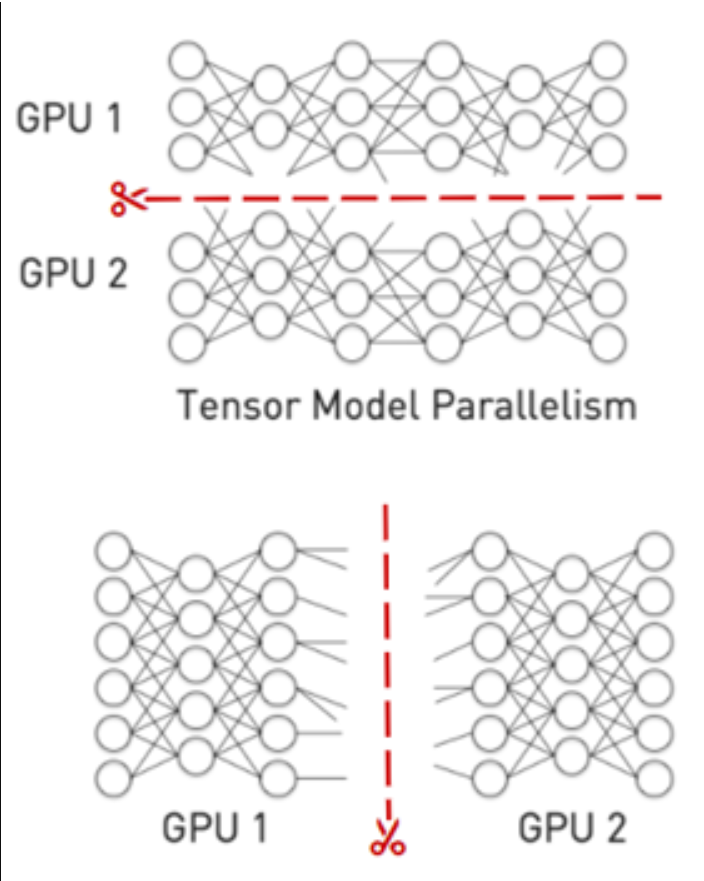
Figure 4. Tensor model and pipeline parallelism.
巨型模型仍处于起步阶段,但用不了多久,你就会看到生产人工智能为不同的用例运行多个巨型模型。
生态系统集成
推理服务是一种生产活动,可能需要与许多生态系统软件和工具集成。Triton与多个集成,并定期添加新的集成。
- 框架后端:Triton开箱即用地支持所有主要的深度学习框架执行后端,如TensorFlow、PyTorch和ONNX-RT。它允许C++和Python中的自定义后端轻松集成。作为21.03版本的一部分,Triton中OpenVINO后端的测试版可用于英特尔平台上的高性能CPU推理。
- Kubernetes生态系统:Triton是按规模设计的。它与云上的主要Kubernetes平台(如AKS、EKS和GKE)以及包括Red Hat OpenShift在内的内部部署实现集成。它也是Kubeflow项目的一部分。
- 云人工智能平台和MLOP软件:MLOPs是一个为人工智能开发和部署工作流程带来自动化和治理的过程。Triton集成在Azure ML等云人工智能平台中,可以作为自定义容器部署在Google CAIP和Amazon SageMaker中。它还集成了KFServing、Seldon Core和Allegro ClearML。
客户案例研究
大客户和小客户都使用Triton为所有类型的应用程序(如计算机视觉、自然语言处理和金融服务)的生产模型提供服务。以下是不同用例中的几个示例:
计算机视觉
- USPS:在192个USPS配送中心的微服务架构中使用Triton进行包分析。多个图像模型每年使用Triton处理数十亿个包。有关更多信息,请参阅“大规模部署最先进的机器学习算法:案例研究”(由埃森哲联邦服务公司主办)GTC会议。
- 大众智能实验室:将Triton集成到其大众计算机视觉工作台中,这样用户就可以为Model Zoo做出贡献,而无需担心它们是基于ONNX、PyTorch还是TensorFlow框架。Bormann在他的GTC会议“用NVIDIA Triton驯服计算机视觉动物园”中表示,Triton简化了模型管理和部署,这是大众在新的有趣环境中提供人工智能模型的关键。
自然语言处理
- Salesforce:使用Triton开发最先进的变压器模型。有关更多信息,请参阅基准测试Triton推理服务器GTC 21会话。
- LivePerson:使用Triton作为标准化平台,在聊天机器人应用程序的CPU上为来自不同框架的NLP模型提供服务。
金融服务
- 智能语音:使用Triton部署语音和语言模型,用于情绪分析和欺诈检测。有关更多信息,请参阅GPU驱动的会话AI检测欺骗和应对保险欺诈(由智能语音GTC 21会议提供)。
- 蚂蚁集团:使用Triton作为标准化平台,为不同应用程序提供模型服务,如AntChain、版权管理平台、欺诈检测等。
有关客户在生产部署中使用Triton的更多信息,请参阅NVIDIA Triton驯服AI推理的海洋。
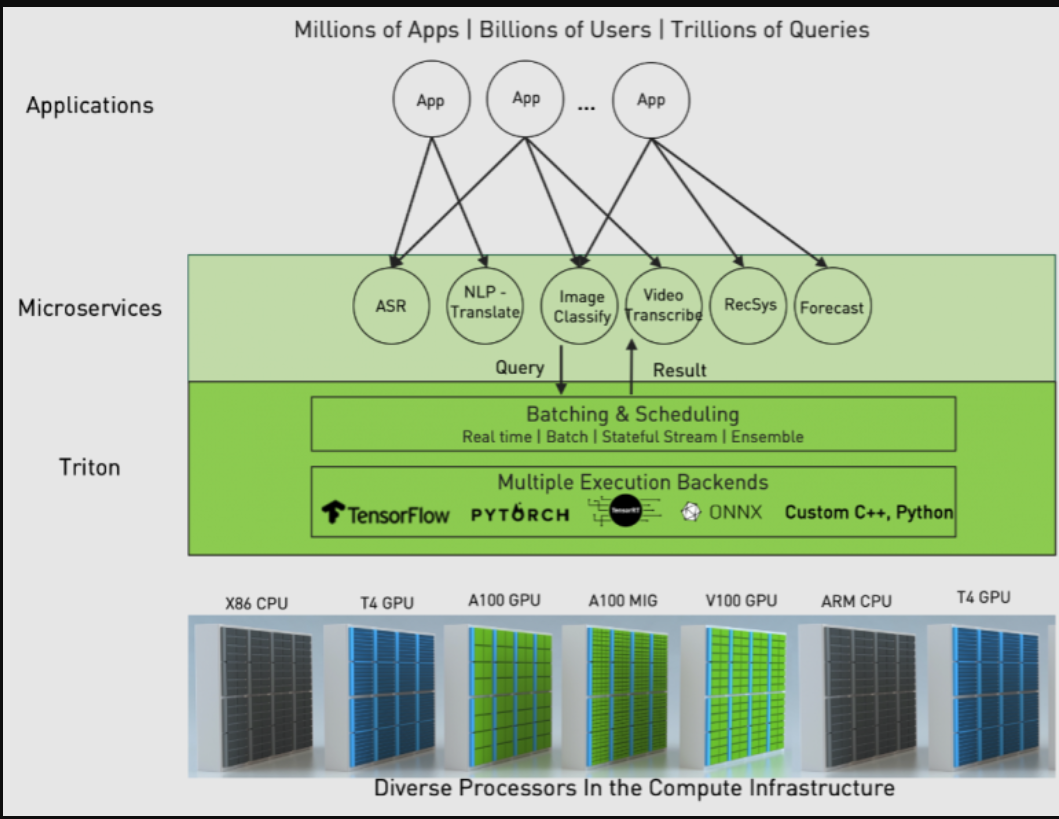
Figure 5. Triton for standardized AI deployment across the data center.
结论
Triton帮助在每个数据中心、云和嵌入式设备中实现标准化的可扩展生产AI。它支持多个框架,在CPU和GPU上运行模型,处理不同类型的推理查询,并与Kubernetes和MLOP平台集成。
立即从NGC下载Triton作为Docker容器,并在Triton推理服务器GitHub repo中找到文档。有关更多信息,请参阅NVIDIA Triton推理服务器产品页。
相关资源
- DLI course: Deploying a Model for Inference at Production Scale
- GTC session: Deploying, Optimizing, and Benchmarking Large Language Models With Triton Inference Server
- GTC session: Powering Ad Delivery Systems With AI at Enterprise Scale
- SDK: Triton Inference Server
- SDK: Triton Management Service
- Webinar: Technical Overview of GPU Inference Pipeline
- 登录 发表评论
- 80 次浏览