
category
实现现代数据体系结构提供了一种可扩展的方法来集成来自不同来源的数据。通过按业务域而不是基础结构组织数据,每个域都可以选择适合其需求的工具。组织可以通过生成的人工智能解决方案,在不断创新的同时,最大限度地实现其现代数据架构的价值。
自然语言功能允许非技术用户通过英语会话而不是复杂的SQL查询数据。然而,要实现全部利益,就需要克服一些挑战。人工智能和语言模型必须识别适当的数据源,生成有效的SQL查询,并产生具有大规模嵌入结果的连贯响应。他们还需要一个自然语言问题的用户界面。
总的来说,使用AWS实现现代数据架构和生成人工智能技术是一种很有前途的方法,可以在企业规模上从多样化、广泛的数据中收集和传播关键见解。AWS为生成人工智能提供的最新产品是Amazon Bedrock,这是一项完全管理的服务,也是使用基础模型构建和扩展生成人工智能应用程序的最简单方法。AWS还通过AmazonSageMaker JumpStart作为AmazonSage Maker端点提供基础模型。大型语言模型(LLM)的组合,包括Amazon Bedrock提供的易于集成的功能,以及可扩展的、面向领域的数据基础设施,使其成为一种利用各种分析数据库和数据湖中丰富信息的智能方法。
在这篇文章中,我们展示了一个场景,其中一家公司部署了一个现代数据架构,数据驻留在多个数据库和API上,如亚马逊简单存储服务(Amazon S3)上的法律数据、亚马逊关系数据库服务(Amazon RDS)上的人力资源、亚马逊Redshift上的销售和营销、Snowflake上第三方数据仓库解决方案上的金融市场数据,以及作为API的产品数据。此实施旨在提高企业业务分析、产品所有者和业务领域专家的生产力。所有这些都是通过在该领域网格架构中使用生成人工智能实现的,这使公司能够更有效地实现其业务目标。此解决方案可以选择将JumpStart的LLM作为SageMaker端点以及第三方模型包括在内。我们为企业用户提供了一种在不具备数据通道基本知识的情况下提出基于事实的问题的媒介,从而抽象了编写简单到复杂的SQL查询的复杂性。
解决方案概述
AWS上的现代数据架构应用人工智能和自然语言处理来查询多个分析数据库。通过使用Amazon Redshift、Amazon RDS、Snowflake、Amazon Athena和AWS Glue等服务,它创建了一个可扩展的解决方案来集成来自各种来源的数据。使用LangChain,一个强大的LLM库,包括亚马逊Bedrock和亚马逊SageMaker Studio笔记本电脑中的JumpStart的基础模型,构建了一个系统,用户可以用自然英语提出商业问题,并从相关数据库中获取数据。
下图说明了体系结构。
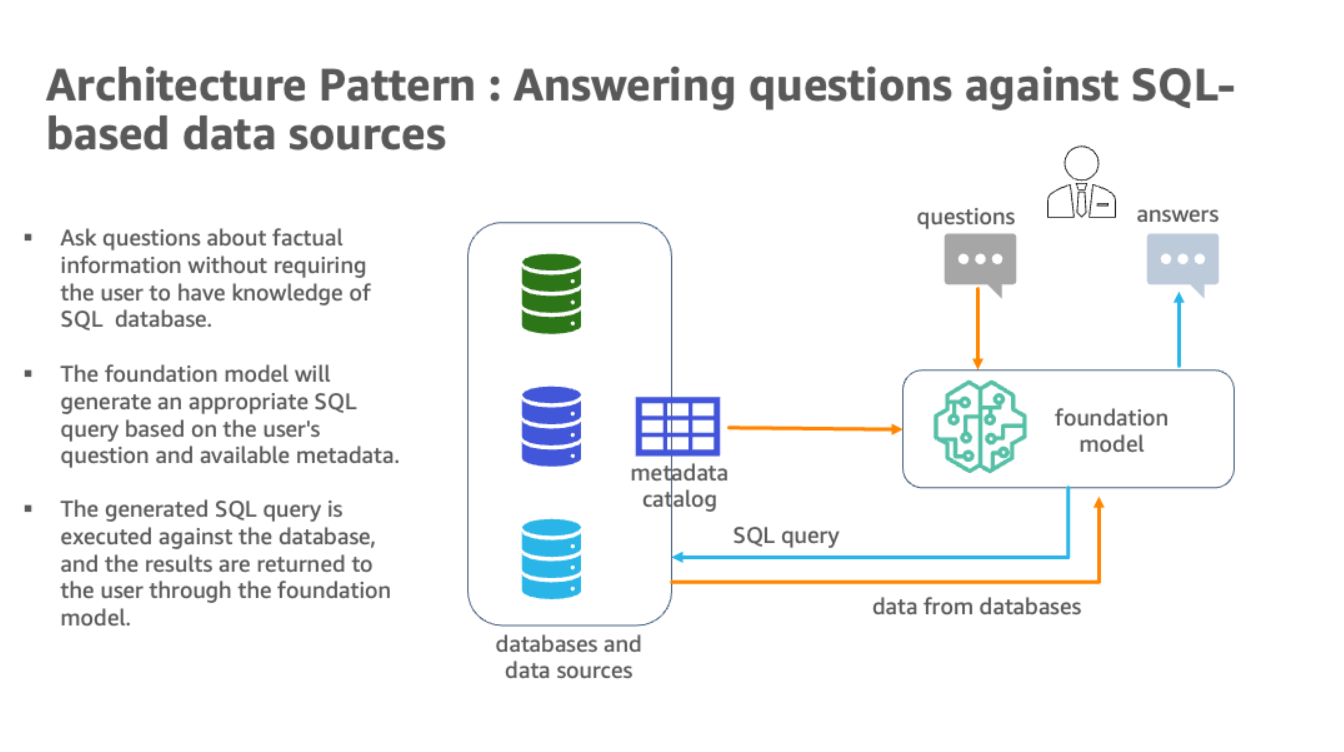
该混合体系结构使用多个数据库和LLM,以及Amazon Bedrock和JumpStart的基础模型,用于数据源识别、SQL生成和带结果的文本生成。
下图说明了我们解决方案的具体工作流程步骤。
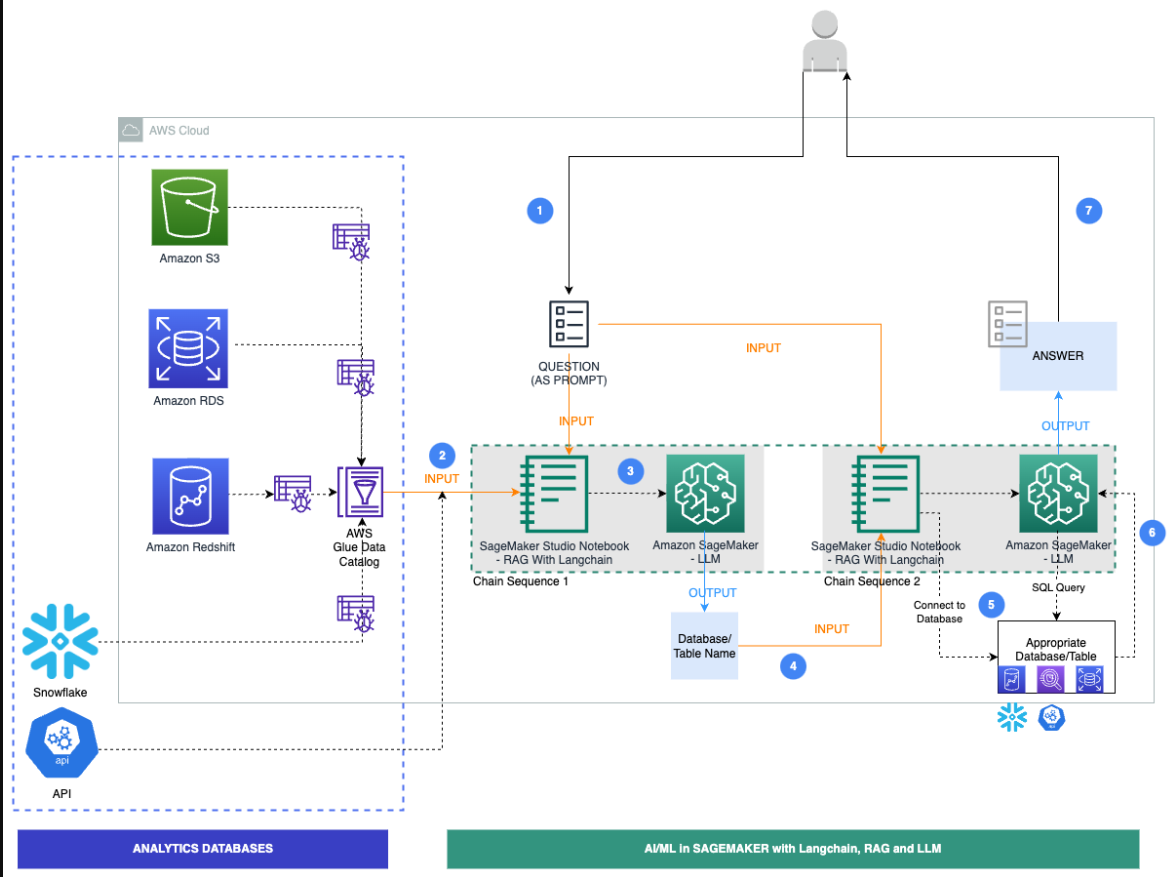
步骤如下:
- 业务用户提供英语问题提示。
- AWS Glue爬网程序计划以频繁的间隔运行,以从数据库中提取元数据并在AWS Glue数据目录中创建表定义。数据目录被输入到链序列1(参见上图)。
- LangChain是一种用于LLM和提示的工具,在Studio笔记本中使用。LangChain要求定义LLM。作为Chain Sequence 1的一部分,提示和数据目录元数据被传递到托管在SageMaker端点上的LLM,以使用LangChain识别相关数据库和表。
- 提示和识别的数据库和表被传递到链序列2。
- LangChain建立与数据库的连接,并运行SQL查询以获取结果。
- 结果被传递给LLM,以生成带有数据的英语答案。
- 用户在查询不同数据库中的数据时,会收到提示的英文答案。
以下各节将用相关代码解释一些关键步骤。要深入了解此处显示的所有步骤的解决方案和代码,请参阅GitHub repo。下图显示了以下步骤的顺序:

先决条件
您可以使用任何与SQLAlchemy兼容的数据库来从LLM和LangChain生成响应。但是,这些数据库的元数据必须在AWS Glue数据目录中注册。此外,您还需要通过JumpStart或API键访问LLM。
使用SQLAlchemy连接到数据库
LangChain使用SQLAlchemy连接到SQL数据库。我们通过创建引擎并为每个数据源建立连接来初始化LangChain的SQLDatabase函数。以下是如何连接到Amazon Aurora MySQL Compatible Edition无服务器数据库并仅包括employees表的示例:
#connect to AWS Aurora MySQL
cluster_arn = <cluster_arn>
secret_arn = <secret_arn>
engine_rds=create_engine('mysql+auroradataapi://:@/employees',echo=True,
connect_args=dict(aurora_cluster_arn=cluster_arn, secret_arn=secret_arn))
dbrds = SQLDatabase(engine_rds, include_tables=['employees'])
接下来,我们构建Chain Sequence 1使用的提示,以根据用户问题识别数据库和表名。
生成动态提示模板
我们使用旨在存储和管理元数据信息的AWS Glue Data Catalog来识别用户查询的数据源,并为Chain Sequence 1构建提示,具体步骤如下:
- 我们通过使用演示中使用的JDBC连接对多个数据源的元数据进行爬网来构建数据目录。
- 使用Boto3库,我们可以从多个数据源构建数据目录的合并视图。以下是关于如何从Aurora MySQL数据库的数据目录中获取employees表的元数据的示例:
#retrieve metadata from glue data catalog
glue_tables_rds = glue_client.get_tables(DatabaseName=<database_name>, MaxResults=1000)
for table in glue_tables_rds['TableList']:
for column in table['StorageDescriptor']['Columns']:
columns_str=columns_str+'\n'
('rdsmysql|employees|'+table['Name']+"|"+column['Name'])
合并的数据目录包含有关数据源的详细信息,如架构、表名和列名。以下是合并数据目录的输出示例:
database|schema|table|column_names
redshift|tickit|tickit_sales|listid
rdsmysql|employees|employees|emp_no
....
s3|none|claims|policy_id
我们将合并后的数据目录传递给提示模板,并定义LangChain使用的提示:
prompt_template = """
From the table below, find the database (in column database) which
will contain the data (in corresponding column_names) to answer
the question {query} \n
"""+glue_catalog +""" Give your answer as database ==
\n Also,give your answer as database.table =="""
链序列1:使用LangChain和LLM检测用户查询的源元数据
我们将上一步中生成的提示模板与用户查询一起传递给LangChain模型,以找到回答问题的最佳数据源。LangChain使用我们选择的LLM模型来检测源元数据。
使用以下代码可以使用JumpStart或第三方模型中的LLM:
#define your LLM model here
llm = <LLM>
#pass prompt template and user query to the prompt
PROMPT = PromptTemplate(template=prompt_template,
input_variables=["query"])
# define llm chain
llm_chain = LLMChain(prompt=PROMPT, llm=llm)
#run the query and save to generated texts
generated_texts = llm_chain.run(query)
生成的文本包含运行用户查询所依据的数据库和表名等信息。例如,对于用户查询“Name all employees with birthdate this month”,generated_text具有信息database==rdsmysql和database.table==rdsmysql.eemployes。
接下来,我们将人力资源域、Aurora MySQL数据库和员工表的详细信息传递给Chain Sequence 2。
链序列2:从数据源检索响应以回答用户查询
接下来,我们运行LangChain的SQL数据库链,将文本转换为SQL,并对数据库隐式运行生成的SQL,以简单可读的语言检索数据库结果。
我们首先定义一个提示模板,该模板指示LLM以语法正确的方言生成SQL,然后在数据库中运行:
_DEFAULT_TEMPLATE = """Given an input question, first
create a syntactically correct {dialect} query to run,
then look at the results of
the query and return the answer.
Only use the following tables:
{table_info}
If someone asks for the sales, they really mean the
tickit.sales table.
Question: {input}"""
#define the prompt
PROMPT = PromptTemplate( input_variables=["input",
"table_info", "dialect"], template=_DEFAULT_TEMPLATE)
最后,我们将LLM、数据库连接和提示传递给SQL数据库链,并运行SQL查询:
db_chain = SQLDatabaseChain.from_llm(llm, db, prompt=PROMPT)
response=db_chain.run(query)
例如,对于用户查询“Name all employees with birthdate this month”,答案如下:
Question: Name all employees with birth date this month
SELECT * FROM employees WHERE MONTH(birth_date) =
MONTH(CURRENT_DATE());
User Response:
The employees with birthdays this month are:
Christian Koblick
Tzvetan Zielinski
清理
在使用生成人工智能运行现代数据架构后,请确保清理任何不会被利用的资源。关闭并删除使用的数据库(Amazon Redshift、Amazon RDS、Snowflake)。此外,删除AmazonS3中的数据并停止任何Studio笔记本实例,以免产生任何进一步的费用。如果您使用JumpStart将LLM部署为SageMaker实时端点,请通过SageMaker控制台或Studio删除端点。
结论
在这篇文章中,我们将现代数据架构与SageMaker中的生成人工智能和LLM集成在一起。此解决方案使用JumpStart的各种文本到文本基础模型以及第三方模型。这种混合方法识别数据源,编写SQL查询,并使用查询结果生成响应。它使用Amazon Redshift、Amazon RDS、Snowflake和LLM。为了改进解决方案,您可以添加更多的数据库、用于英语查询的UI、提示工程和数据工具。这可能成为一种从多个数据存储中获取见解的智能、统一的方式。要深入了解解决方案和本文中显示的代码,请查看GitHub repo 此外,有关生成人工智能、基础模型和大型语言模型的用例,请参阅Amazon Bedrock。
Appendix
Example prompts
| Domain | Database/API | Prompt | SQL (Generated by LLM) | Output |
| Sales & Marketing | Amazon RedShift | How many ticket sales are there? | SELECT COUNT(*) AS total_salesFROM tickit.sales; |
There are 172,456 ticket sales. |
| Sales & Marketing | Amazon RedShift | What was the total commission for the ticket sales in the year 2008? | SELECT SUM(commission) AS total_commissionFROM tickit.salesWHERE EXTRACT(YEAR FROM saletime) = 2008 |
The total commission for ticket sales in the year 2008 was $16,614,814.65. |
| Legal | S3 | How many frauds happened in the year 2023? | SELECT count(*)FROM claimsWHERE extract(year from write_time) = 2023 AND fraud = 1; |
There were 164 fraud claims in 2023. |
| Legal | S3 | How many policies were claimed this year? | SELECT count(*)FROM claims; |
There were 5000 claims made this year. |
| Human Resources | Amazon Aurora MySQL | Name all employees with birth date this month | SELECT * FROM employeesWHERE MONTH(birth_date) = MONTH(CURRENT_DATE()); |
The employees with birthdays this month are:Christian KoblickTzvetan ZielinskiKazuhito CappellettiYinghua Dredge |
| Human Resources | Amazon Aurora MySQL | How many employees were hired before 1990? | SELECT COUNT(*) AS 'Number of employees hired before 1990'FROM employeesWHERE hire_date < '1990-01-01' |
29 employees were hired before 1990. |
| Finance and Investments | Snowflake | Which stock performed the best and the worst in May of 2013? | SELECT name, MAX(close) AS max_close, MIN(close) AS min_closeFROM all_stocks_5yrWHERE date BETWEEN '2013-05-01' AND '2013-05-31'GROUP BY nameORDER BY max_close DESC, min_close ASC |
The stock that performed the best in May 2013 was AnySock1 (ASTOCK1) with a maximum closing price of $842.50. The stock that performed the worst was AnySock2 (ASTOCK2) with a minimum closing price of $3.22. |
| Finance and Investments | Snowflake | What is the average volume stocks traded in July of 2013? | SELECT AVG(volume) AS average_volumeFROM all_stocks_5yrWHERE date BETWEEN '2013-07-01' AND '2013-07-31' |
The average volume of stocks traded in July 2013 was 4,374,177 |
| Product – Weather | API | What is the weather like right now in New York City in degrees Fahrenheit? |
- 登录 发表评论
- 87 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago