
category
在为特定任务建立语言模型时,通常会采用两种关键方法:检索增强生成(RAG)和微调。每种方法都有其独特的优势,选择正确的方法对于模型在目标环境中的性能至关重要。
在本文中,我们将详细探讨RAG和微调。我们将了解每种方法的基本原理,检查它们在各种条件下的性能,并确定每种方法最适合解决哪些类型的挑战。在本次讨论结束时,您将更好地了解哪种方法可能更适合您的人工智能项目,特别是如果您的优先事项包括速度、准确性或适应性。
什么是检索增强生成(RAG)?
检索增强生成(RAG)是一种方法,其中语言模型与搜索引擎协同工作,在处理查询时实时提取相关信息。本质上,它在数据库或文档集合中搜索,以查找添加上下文并帮助模型制作响应的信息。
RAG有四个主要组成部分:
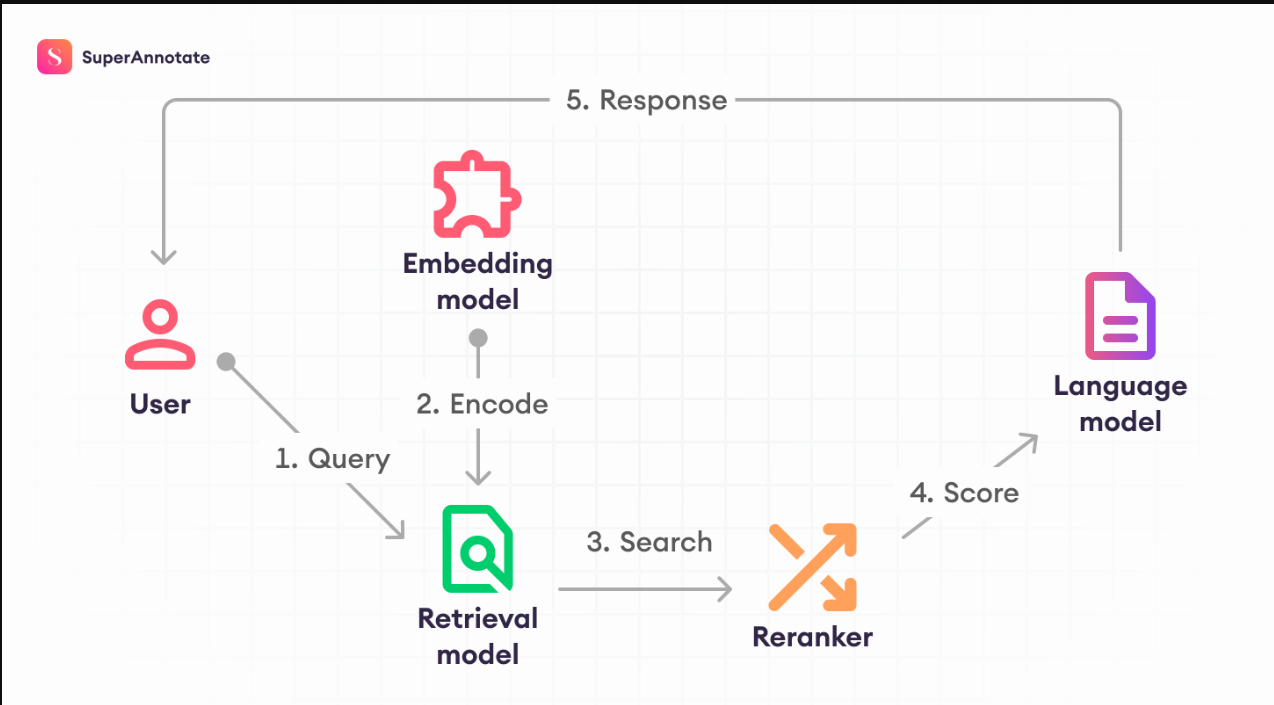
抹布主要部件
- 嵌入模型:当用户提交问题时,会使用向量嵌入(数据的数值表示)进行处理。
- 检索器:检索器在这些嵌入中搜索,以从矢量数据库中找到最相关的文档。
- 重新排序器(可选):重新排序器然后评估这些文档,以对其与查询的相关性进行评分,确保信息与用户的需求紧密一致。
- 语言模型:语言模型获取检索到的(可能重新排序的)文档,将其与查询相结合,并生成精确的答案。
RAG优点
- 最新和相关的答案:与可能给出过时或无关答案的标准模型不同,RAG使用来自各种来源的最新信息。
- 减少幻觉:通过定期更新数据库,RAG有助于防止模型根据旧数据或不完整数据给出错误答案。
- 来源:RAG显示了其信息的来源,这有助于建立信任,并允许用户在愿意的情况下进一步探索主题。
- 低维护:一旦设置完成,RAG就会用新数据进行自我更新,从而减少开发人员的工作量。
- 创新功能:RAG可以在产品中实现新功能,改善用户体验和参与度。
RAG缺点
- 需要预处理数据:RAG需要一个大型的预处理数据数据库,这可能需要大量的资源投入。
- 系统之间的复杂交互:设置和维护这些数据库涉及复杂的交互,并可能带来系统之间的额外延迟。
何时使用RAG?
RAG最适合检索任务,特别是当您需要最新和精确的信息时。特别是,您可能需要RAG用于:
- 更好的细节和准确性:当你需要详细和正确的答案时,RAG真的很出色。它在生成响应的同时查找相关信息,确保答案既聪明又具体。这在医学研究或法律文件审查等领域特别有用,因为准确性至关重要。
- 处理复杂问题:如果你正在处理需要大量知识或检查不同事实的棘手问题,RAG可以通过搜索大量数据来找到正确的答案。这种能力非常适合语言翻译或教育工具等应用程序,在这些应用程序中,理解上下文是关键。
- 保持信息一致:在法律或医疗保健等领域,保持信息一致性很重要,RAG通过使用可信文档来提供帮助。这确保了答案的可靠性和准确性,这对于客户服务中的聊天机器人至关重要,在客户服务中保持一致的品牌声音和准确的信息至关重要。
- 最新回复:如果您需要答案中的最新信息,RAG非常有用,因为它会根据找到的最新数据不断更新其回复。这一功能在需要跟上最新发展的领域尤其有益,比如医学研究。
- 量身定制的答案:您可以设置RAG从特定位置查找信息,使其非常适合需要非常准确和相关答案的领域。这确保了模型给出的响应不仅正确,而且对您的特定情况也非常有用,例如在个性化学习体验至关重要的教育工具中。
什么是微调?
LLM微调是将预先训练好的语言模型在较小的专业数据集上进行进一步训练的过程。这种方法旨在通过调整模型的参数来反映目标领域的细微差别,从而使模型的一般能力适应特定的任务或行业。
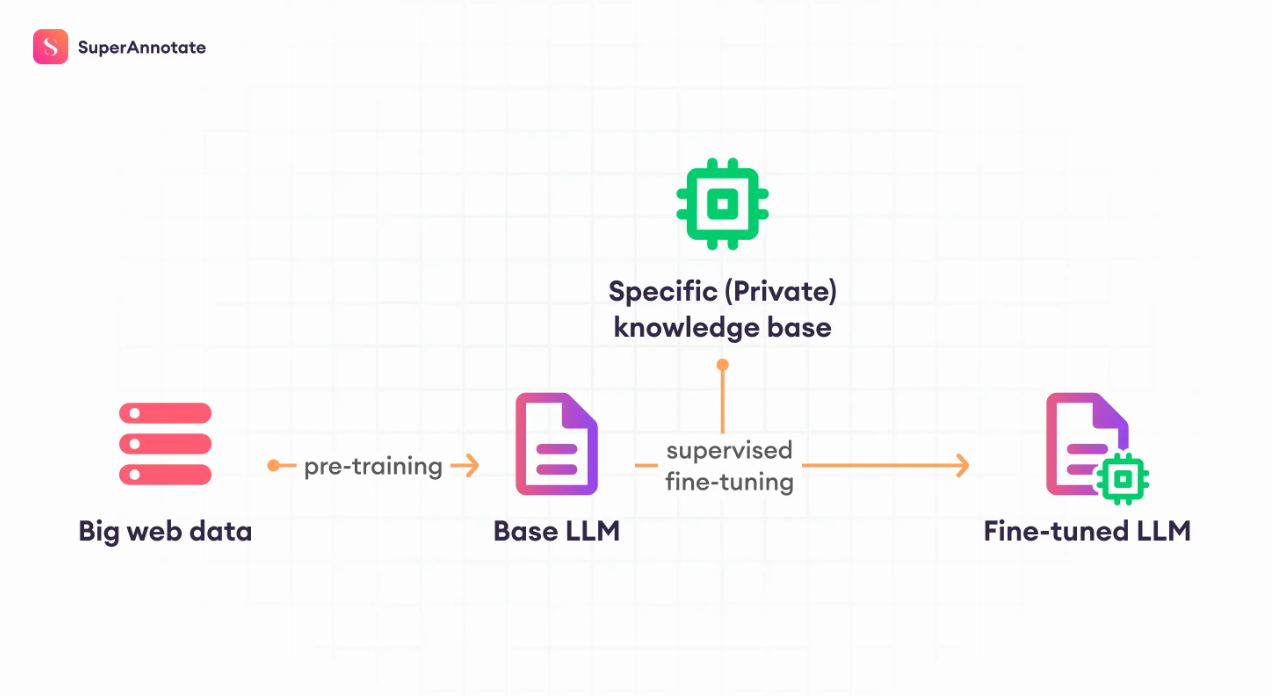
如何进行微调
微调优点
- 定制:它允许高度定制,使模型与特定任务更相关。
- 减少令牌使用:您的上下文窗口不会被巨大的提示填满。
- 提高特定任务的性能:针对数据集的特性,增强模型在特定应用程序中的性能。
微调缺点
- 资源密集型:它可能既昂贵又及时,因为它需要大量的计算能力和数据。
- 过度拟合:模型可能会对训练数据学习得太好,在新的、看不见的数据上表现不佳。
- 数据依赖性:结果在很大程度上取决于用于培训的数据的质量和相关性。
- 维护:您需要不断更新和监控模型,以确保它在数据和需求发生变化时保持有效。
何时使用微调
如果您需要使模型与您的业务特定需求、语调、写作风格等保持一致,则必须进行微调:
- 领域适应:LLM知识渊博,这要归功于他们广泛的培训,但他们可能不知道你所在行业的独特语言或细节。微调有助于模型更好地理解和生成符合您特定业务需求的内容。
- 精确度和准确度:准确性在商业中至关重要,即使是很小的错误也会产生重大后果。通过使用特定于业务的数据训练模型,您可以大大提高其精度,确保输出与您的期望紧密一致。
- 定制用户交互:对于涉及直接客户交互的角色,如聊天机器人,微调允许您调整模型以反映品牌的声音和指导方针,确保一致和吸引人的客户体验。
- 数据控制:一般模型可能会使用可公开访问的数据,如果涉及敏感信息,则会带来风险。微调允许您限制模型使用的数据,增强内容安全性并防止无意中的数据泄漏。
- 特殊情况:每个企业都面临着独特的、关键的情况,受过广泛训练的模型可能无法很好地解决这些情况。微调确保模型能够更有效地处理这些利基场景。
关于微调的很多内容似乎在RAG中很常见,但我们将在后面的章节中深入探讨这些差异。
LLM幻觉:为什么你需要RAG和微调?
有很多事情你绝对不希望你的聊天机器人做,包括引起LLM幻觉、产生有毒输出、发表仇恨言论或泄露公司的私人数据。还记得加拿大航空的聊天机器人在实际收取全价的同时虚假承诺退款吗?或者当DPD包裹递送的聊天机器人对客户咒骂时?
如果你的聊天机器人产生了幻觉,或者你在评估LLM时发现了错误,这清楚地表明你需要对系统进行微调或使用RAG。这可确保您的模型符合您的偏好。LLM应用程序构建者还使用一种称为LLM红队的技术来发现系统中的漏洞并加以解决。
现在,让我们来谈谈核心问题:什么时候应该使用RAG而不是微调?
RAG与微调:选择哪一个?
正如我们所了解到的,RAG和微调都是让你的法学硕士在某些方面做得更好的方法。他们有相同的大目标,但工作方式不同。为了找出哪一个最适合你的项目,这里有一些RAG和.fine-tuning的功能比较。
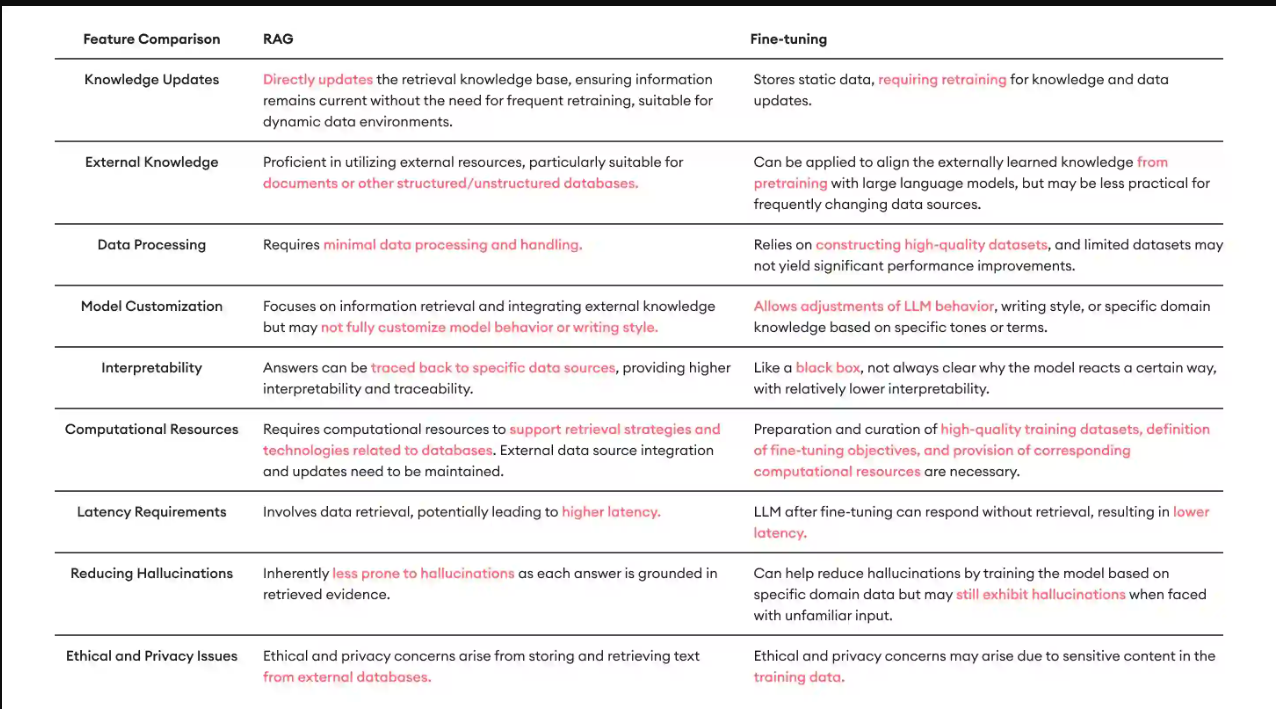
- 知识更新:RAG就像你随时更新的人工智能助手,无需频繁再培训即可整合最新信息。这使其成为保持最新状态至关重要的行业的理想选择。另一方面,微调更像是为特定工作培训的专家。它在其领域内表现出色,但需要定期更新和重新培训以跟上新信息。
- 数据集成:RAG是一只数据变色龙,擅长将大量外部信息无缝地融入其响应中。它可以轻松处理结构化和非结构化数据。然而,微调更倾向于其数据准备充分和完善,依靠高质量的数据集有效运行。
- 减少幻觉:RAG的答案植根于现实,这要归功于其直接的数据获取,它最大限度地减少了虚假或不正确的信息。微调虽然通常是可靠的,但偶尔会产生不正确或富有想象力的答案,尤其是在训练数据中没有涵盖的复杂或不寻常的查询中。
- 定制功能:RAG坚持脚本,但可能无法完全针对模型行为或写作风格进行定制。相比之下,微调可以定制到最精细的细节,包括写作风格和特定领域的术语,使其能够满足给定场景的确切需求。
- 可解释性因素:使用RAG,您可以轻松地追踪它是如何从一个问题到另一个答案的,使其在可解释性方面成为一本开放的书。微调虽然能够产生令人印象深刻的结果,但有时就像一个聪明的魔术师——令人惊叹,但并不总是清楚结果是如何实现的。
- 延迟:RAG涉及大量的数据检索,这使得它很彻底,但有时很慢,导致更高的延迟。微调更快,因为它不需要检索数据,并且几乎可以立即提供答案,尽管它最初需要大量的设置。
- 伦理和隐私考虑:RAG广泛的数据覆盖范围意味着必须谨慎处理以保护隐私。微调侧重于特定的数据集,在确保从中学习的数据得到负责任的使用方面也存在挑战。
- 可扩展性:RAG可以轻松扩展以处理来自多个来源的大量数据。微调需要仔细的数据管理和模型训练,当扩展到更大的数据集时,这可能会占用更多的资源。
混合方法:RAG+微调
在某些情况下,将RAG和微调相结合可以产生最佳结果。
- 检索增强微调(RAFT):例如,使用RAG检索相关信息,然后对该数据上的模型进行微调(RAVT),可以获得更准确和量身定制的输出。
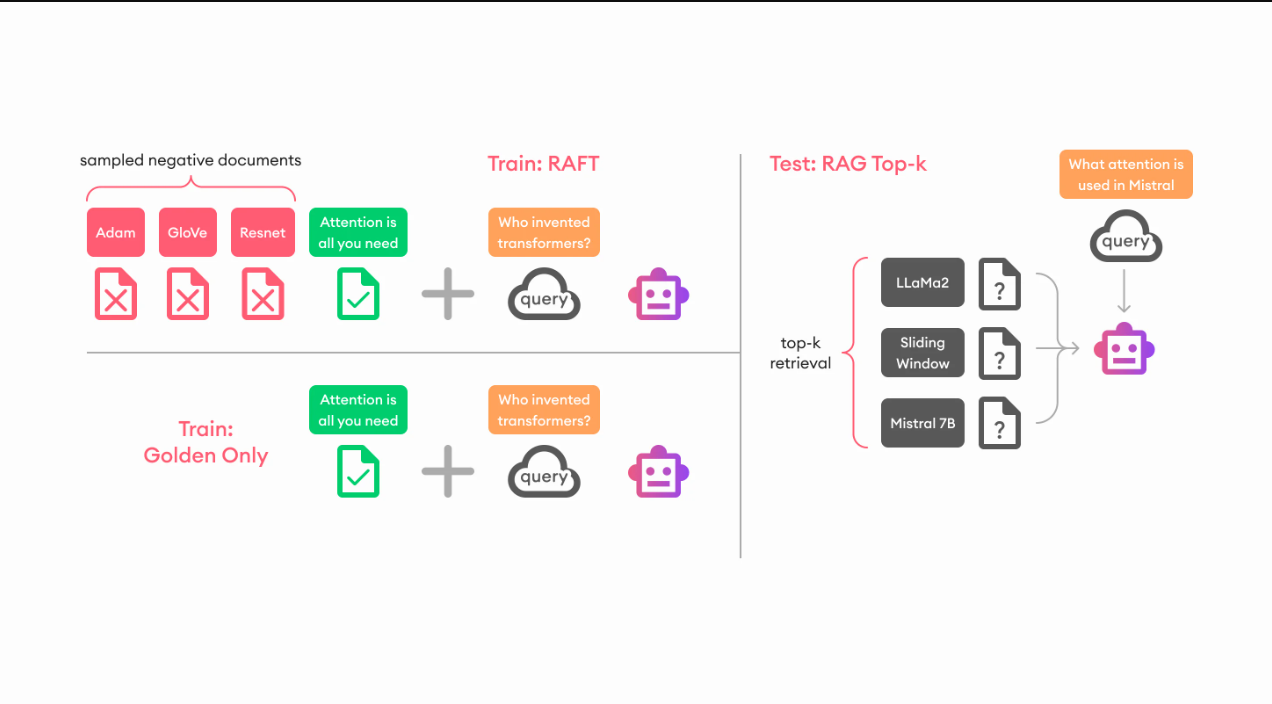
- 微调RAG组件:如果你想改进你的RAG系统,你可以找到有缺陷的组件并单独进行微调。
最后的想法
在为您的项目选择RAG和微调时,请考虑您的具体需求。如果你需要你的模型保持最新状态并处理广泛的数据,RAG是一个很好的选择。在快速变化的环境中,准确和及时的信息至关重要,这尤其有用。
另一方面,微调最适合需要专门、精确响应的任务。它非常适合您的模型需要遵循特定指导方针或在稳定、一致的数据中运行的情况。
最后,你的选择取决于你是优先考虑适应性和广泛知识(RAG)还是专业领域的准确性(微调)。有时,两种方法的结合可能是平衡保持最新状态和准确性的最佳方式。考虑你的项目的独特需求、你拥有的资源和你的长期目标,做出最佳决策。
- 登录 发表评论
- 64 次浏览
最新内容
- 1 day 13 hours ago
- 1 month 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago
- 5 months 2 weeks ago