
category
这个客户项目帮助一家财富500强食品公司改进了其需求预测。该公司将产品直接运送到多个零售店。这一改进帮助他们优化了美国多个地区不同商店的产品库存。为了实现这一目标,微软的商业软件工程(CSE)团队与客户的数据科学家合作进行了一项试点研究,为选定的地区开发定制的机器学习模型。这些模型考虑到:
- 购物者人口统计
- 历史和预测天气
- 过去发货
- 产品退货
- 特殊活动
优化库存的目标是该项目的一个主要组成部分,客户在早期的实地试验中实现了显著的销售额提升。此外,与历史平均基线模型相比,该团队发现预测平均绝对百分比误差(MAPE)减少了40%。
该项目的一个关键部分是弄清楚如何将数据科学工作流程从试点研究扩展到生产层面。此生产级工作流程要求CSE团队:
- 为许多地区开发模型。
- 不断更新和监控模型的性能。
- 促进数据和工程团队之间的协作。
如今,典型的数据科学工作流程更接近于一次性实验室环境,而不是生产工作流程。数据科学家的环境必须适合他们:
- 准备数据。
- 用不同的模型进行实验。
- 调整超参数。
- 创建一个构建-测试-评估-细化周期。
用于这些任务的大多数工具都有特定的用途,不太适合自动化。在生产级机器学习操作中,必须更多地考虑应用程序生命周期管理和DevOps。
CSE团队帮助客户将运营规模扩大到生产水平。他们实现了持续集成和持续交付(CI/CD)功能的各个方面,并解决了可观察性和与Azure功能的集成等问题。在实施过程中,该团队发现了现有MLOps指南中的漏洞。需要填补这些空白,以便更好地理解和大规模应用MLOps。
了解MLOps实践有助于组织确保系统生成的机器学习模型是提高业务性能的生产质量模型。当实施MLOps时,组织不再需要将大量时间花在与基础设施和工程工作相关的低级细节上,这些细节是开发和运行生产级操作的机器学习模型所需的。实施MLOps也有助于数据科学和软件工程社区学会合作,提供一个可供生产的系统。
CSE团队利用该项目通过解决诸如开发MLOps成熟度模型之类的问题来满足机器学习社区的需求。这些努力旨在通过了解MLOps过程中关键参与者的典型挑战来提高MLOps的采用率。
参与和技术场景
参与场景讨论了CSE团队必须解决的现实挑战。技术场景定义了创建MLOps生命周期的需求,该生命周期与已建立的DevOps生命期一样可靠。
参与场景
客户定期将产品直接送到零售市场网点。每个零售店的产品使用模式各不相同,因此每周交付的产品库存需要有所不同。客户使用的需求预测方法的目标是最大限度地提高销售额,最大限度地减少产品退货和失去的销售机会。该项目的重点是使用机器学习来改进预测。
CSE团队将项目分为两个阶段。第一阶段的重点是开发机器学习模型,以支持对选定销售区域的机器学习预测有效性进行实地试点研究。第一阶段的成功导致了第二阶段,在第二阶段中,团队将最初的试点研究从支持单个地理区域的最小模型组扩大到针对客户所有销售区域的一组可持续生产水平模型。扩大解决方案的主要考虑因素是需要适应大量的地理区域及其当地零售网点。该团队将机器学习模型专门用于每个地区的大型和小型零售店。
第一阶段试点研究确定,一个专门针对一个地区零售店的模型可以利用当地销售历史、当地人口统计、天气和特殊事件来优化该地区门店的需求预测。四个集成的机器学习预测模型为单个地区的市场提供服务。模型每周分批处理数据。此外,该团队还利用历史数据开发了两个基线模型进行比较。
对于扩大规模的第二阶段解决方案的第一个版本,CSE团队选择了14个地理区域参与,包括小型和大型市场网点。他们使用了50多个机器学习预测模型。该团队期待着系统的进一步发展和机器学习模型的不断完善。很快就清楚了,只有基于DevOps针对机器学习环境的最佳实践原则,这种更大规模的机器学习解决方案才是可持续的。
| Environment | Market Region | Format | Models | Model Subdivision | Model Description |
|---|---|---|---|---|---|
| Dev environment | Each geographic market/region (for example North Texas) | Large format stores (supermarkets, big box stores, and so on) | Two ensemble models | Slow moving products | Slow and fast both have an ensemble of a least absolute shrinkage and selection operator (LASSO) linear regression model and a neural network with categorical embeddings |
| Fast moving products | Slow and fast both have an ensemble of a LASSO linear regression model and a neural network with categorical embeddings | ||||
| One ensemble model | N/A | Historical average | |||
| Small format stores (pharmacies, convenience stores, and so on) | Two ensemble models | Slow moving products | Slow and fast both have an ensemble of a LASSO linear regression model and a neural network with categorical embeddings | ||
| Fast moving products | Slow and both have an ensemble of a LASSO linear regression model and a neural network with categorical embeddings | ||||
| One ensemble model | N/A | Historical average | |||
| Same as above for an additional 13 geographic regions | |||||
| Same as above for the prod environment |
MLOps过程为扩大规模的系统提供了一个框架,解决了机器学习模型的整个生命周期。该框架包括开发、测试、部署、操作和监控。它满足了经典CI/CD流程的需求。然而,与DevOps相比,由于其相对不成熟,现有的MLOps指南显然存在差距。项目团队努力填补其中的一些空白。他们希望提供一个功能过程模型,以确保扩大规模的机器学习解决方案的可行性。
该项目开发的MLOps流程在现实世界中迈出了重要的一步,将MLOps提升到更高的成熟度和生存能力。新流程直接适用于其他机器学习项目。CSE团队利用他们学到的知识构建了MLOps成熟度模型的草案,任何人都可以将其应用于其他机器学习项目。
技术场景
MLOps,也称为机器学习的DevOps,是一个总括性术语,包括与在生产环境中实现机器学习生命周期相关的哲学、实践和技术。这仍然是一个相对较新的概念。已经有很多人试图定义什么是MLOps,许多人质疑MLOps是否可以涵盖从数据科学家如何准备数据到他们最终如何交付、监控和评估机器学习结果的所有内容。虽然DevOps有多年的时间来开发一套基本实践,但MLOps仍处于早期开发阶段。随着它的发展,我们发现将两个通常具有不同技能和优先级的学科结合在一起的挑战:软件/操作工程和数据科学。
在真实的生产环境中实施MLOps具有必须克服的独特挑战。团队可以使用Azure来支持MLOps模式。Azure还可以为客户端提供资产管理和编排服务,以有效管理机器学习生命周期。Azure服务是我们在本文中描述的MLOps解决方案的基础。
机器学习模型要求
第一阶段试点现场研究期间的大部分工作都是创建机器学习模型,CSE团队将其应用于单个地区的大型和小型零售店。模型的显著要求包括:
- Azure机器学习服务的使用。
- 在Jupyter笔记本电脑中开发并在Python中实现的初始实验模型。
笔记
团队对大型和小型商店使用相同的机器学习方法,但训练和评分数据取决于商店的规模。
- 需要为模型消耗做准备的数据。
- 以批处理方式而非实时处理的数据。
- 每当代码或数据发生更改,或者模型过时时,都要重新训练模型。
- 在Power BI仪表板中查看模型性能。
- 与历史平均基线模型相比,当MAPE<=45%时,模型在评分方面的表现被认为是显著的。
MLOps要求
该团队必须满足几个关键要求,才能扩大第一阶段试点现场研究的解决方案,在该研究中,仅为单个销售区域开发了少数型号。阶段2为多个地区实现了自定义的机器学习模型。实施包括:
- 每周对每个地区的大型和小型商店进行批处理,以使用新的数据集重新训练模型。
- 不断完善机器学习模型。
- 在类似DevOps的MLOps处理环境中集成CI/CD通用的开发/测试/包/测试/部署过程。
笔记
这代表着数据科学家和数据工程师过去的工作方式发生了转变。
- 一个独特的模型,根据商店历史、人口统计和其他关键变量代表大商店和小商店的每个地区。该模型必须处理整个数据集,以最大限度地降低处理错误的风险。
- 最初扩展到支持14个销售区域的能力,并计划进一步扩展。
- 为区域和其他商店集群的长期预测制定额外模型的计划。
机器学习模型解决方案
机器学习生命周期,也称为数据科学生命周期,大致符合以下高级流程:
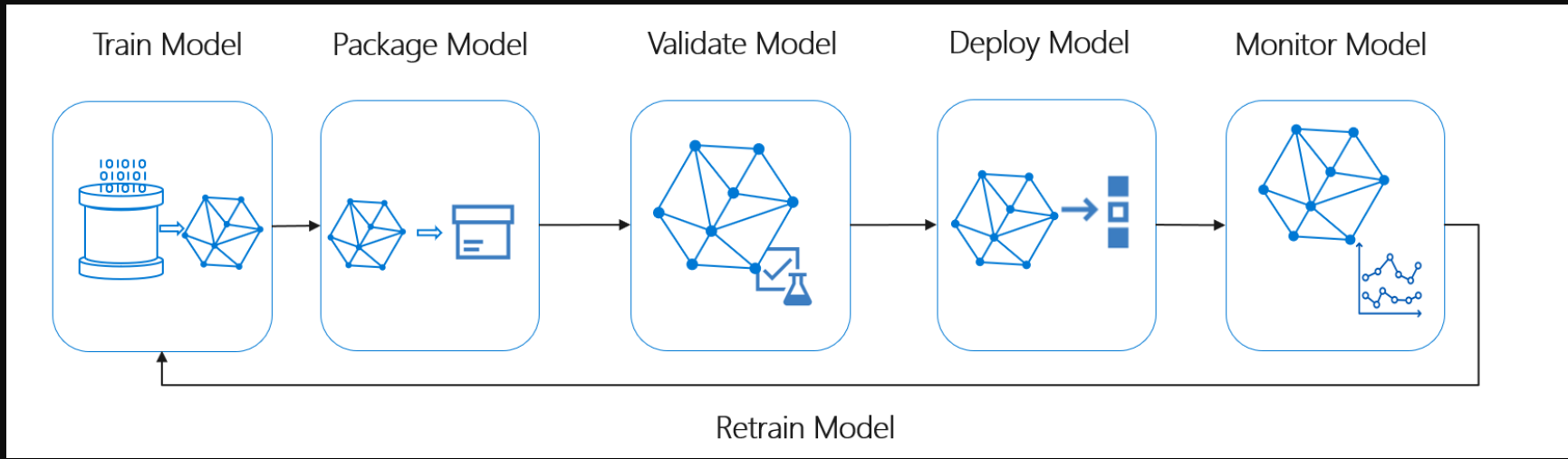
数据科学生命周期模型过程流
这里的Deploy Model可以表示已验证的机器学习模型的任何操作用途。与DevOps相比,MLOps提出了将机器学习生命周期集成到典型的CI/CD过程中的额外挑战。
数据科学生命周期并不遵循典型的软件开发生命周期。它包括使用Azure机器学习来训练和评分模型,因此这些步骤必须包含在CI/CD自动化中。
数据的批处理是体系结构的基础。两个Azure机器学习管道是该过程的核心,一个用于培训,另一个用于评分。此图显示了客户端项目初始阶段使用的数据科学方法:

第一阶段数据科学方法论
该团队测试了几种算法。他们最终选择了LASSO线性回归模型和具有分类嵌入的神经网络的集成设计。该团队对大型和小型商店使用了相同的模型,该模型由客户可以在现场存储的产品级别定义。该团队进一步将该模型细分为快速移动和慢速移动产品。
当团队发布新代码和新数据可用时,数据科学家对机器学习模型进行训练。训练通常每周进行一次。因此,每次处理运行都涉及大量的数据。由于该团队以不同的格式从许多来源收集数据,因此在数据科学家能够处理数据之前,需要对数据进行处理,以将其转换为可消费的格式。数据处理需要大量的手动工作,CSE团队将其确定为自动化的主要候选者。
如前所述,数据科学家开发了实验性Azure机器学习模型,并将其应用于第一阶段试点领域研究中的单个销售区域,以评估这种预测方法的有用性。CSE团队判断,试点研究中商店的销售额提升是显著的。这一成功证明了在第二阶段将解决方案应用于完整的生产级别是合理的,从14个地理区域和数千家商店开始。然后,团队可以使用相同的模式来添加其他区域。
试点模型是扩大解决方案的基础,但CSE团队知道,该模型需要持续改进,以提高其性能。
MLOps解决方案
随着MLOps概念的成熟,团队经常发现将数据科学和DevOps学科结合在一起的挑战。原因是该学科的主要参与者,软件工程师和数据科学家,使用不同的技能和优先级。
但也有相似之处。MLOps和DevOps一样,是一个由工具链实现的开发过程。MLOps工具链包括以下内容:
- 版本控制
- 代码分析
- 构建自动化
- 持续集成
- 测试框架和自动化
- 集成到CI/CD管道中的法规遵从性策略
- 部署自动化
- 监控
- 灾难恢复和高可用性
- 包装和容器管理
如上所述,该解决方案利用了现有的DevOps指南,但进行了扩展,以创建一个更成熟的MLOps实现,满足客户和数据科学社区的需求。MLOps建立在DevOps指导的基础上,并提出以下附加要求:
- 数据和模型版本控制与代码版本控制不同:随着架构和原始数据的变化,必须对数据集进行版本控制。
- 数字审计跟踪要求:在处理代码和客户端数据时跟踪所有更改。
- 泛化:模型不同于重用代码,因为数据科学家必须根据输入数据和场景调整模型。要为新场景重用模型,您可能需要对其进行微调/转移/学习。您需要培训管道。
- 过时的模型:模型往往会随着时间的推移而衰退,您需要根据需要对其进行再培训,以确保它们在生产中保持相关性。
MLOps挑战
不成熟的MLOps标准
MLOps的标准模式仍在发展中。解决方案通常是从头开始构建的,并适合特定客户或用户的需求。CSE团队认识到了这一差距,并寻求在该项目中使用DevOps最佳实践。他们扩充了DevOps流程,以满足MLOps的额外需求。团队开发的流程是MLOps标准模式应该是什么样子的一个可行的例子。
技能方面的差异
软件工程师和数据科学家为团队带来了独特的技能。这些不同的技能组合可能会使找到适合每个人需求的解决方案变得困难。为从实验到生产的模型交付构建一个易于理解的工作流非常重要。团队成员必须共同理解如何在不破坏MLOps流程的情况下将更改集成到系统中。
管理多个模型
通常需要多个模型来解决困难的机器学习场景。MLOps的挑战之一是管理这些模型,包括:
- 具有一致的版本控制方案。
- 持续评估和监控所有模型。
还需要代码和数据的可跟踪沿袭来诊断模型问题并创建可复制的模型。自定义仪表板可以了解已部署模型的执行情况,并指示何时进行干预。该团队为此项目创建了这样的仪表板。
需要数据调节
这些模型使用的数据来自许多私人和公共来源。由于原始数据杂乱无章,机器学习模型不可能在原始状态下使用这些数据。数据科学家必须将数据调整为机器学习模型消费的标准格式。
大部分试点现场测试都集中在调整原始数据,以便机器学习模型能够处理这些数据。在MLOps系统中,团队应该自动化这一过程,并跟踪输出。
MLOps成熟度模型
MLOps成熟度模型的目的是澄清原则和实践,并确定MLOps实施中的差距。这也是向客户展示如何逐步提高MLOps能力的一种方式,而不是试图一次完成所有任务。客户应将其作为指南:
- 估计项目的工作范围。
- 建立成功标准。
- 确定可交付成果。
MLOps成熟度模型定义了五个级别的技术能力:
| Level | Description |
|---|---|
| 0 | No Ops |
| 1 | DevOps but no MLOps |
| 2 | Automated training |
| 3 | Automated model deployment |
| 4 | Automated operations (full MLOps) |
有关MLOps成熟度模型的当前版本,请参阅MLOps的成熟度模型文章。
MLOps过程定义
MLOps包括从获取原始数据到交付模型输出的所有活动,也称为评分:
- 数据调节
- 模特培训
- 模型测试和评估
- 构建定义和管道
- 释放管道
- 部署
- 评分
基本的机器学习过程
基本的机器学习过程类似于传统的软件开发,但存在显著差异。此图说明了机器学习过程中的主要步骤:
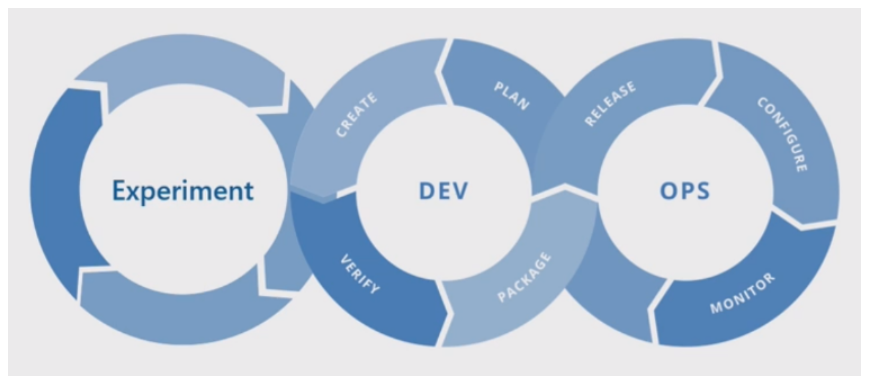
基本机器学习过程流程图。
实验阶段是数据科学生命周期中特有的阶段,它反映了数据科学家传统上的工作方式。它与代码开发人员的工作方式不同。下图更详细地说明了这个生命周期。
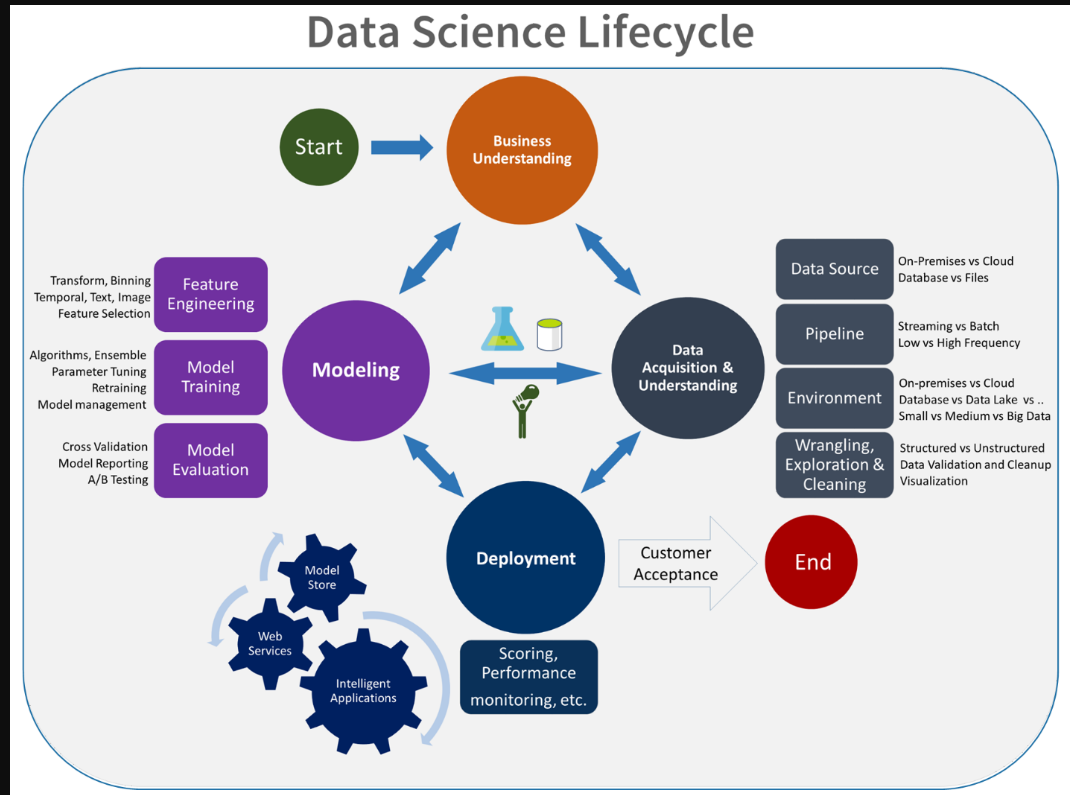
数据科学生命周期图。
将此数据开发过程集成到MLOps中是一个挑战。在这里,您可以看到团队用于将流程集成到MLOps可以支持的形式中的模式:

集成数据开发过程和MLOps的模式图。
MLOps的作用是创建一个协调的过程,该过程可以有效地支持生产级系统中常见的大规模CI/CD环境。从概念上讲,MLOps模型必须包括从实验到评分的所有过程需求。
CSE团队完善了MLOps流程,以满足客户的特定需求。最显著的需求是批处理,而不是实时处理。随着团队开发扩大规模的系统,他们发现并解决了一些缺点。这些缺点中最重要的一个导致了Azure数据工厂和Azure机器学习之间的桥梁的开发,该团队通过使用Azure数据工厂中的内置连接器来实现。他们创建了这个组件集,以便于触发和状态监控,从而使流程自动化工作。
另一个根本性的变化是,数据科学家需要将Jupyter笔记本中的实验代码导出到MLOps部署过程中,而不是直接触发训练和评分。
以下是MLOps过程模型的最终概念:

最终MLOps模型概念图。
重要的
得分是最后一步。该过程运行机器学习模型进行预测。这解决了需求预测的基本业务用例需求。该团队使用MAPE对预测质量进行评级,MAPE是统计预测方法预测准确性的衡量标准,也是机器学习中回归问题的损失函数。在这个项目中,团队认为MAPE<=45%是显著的。
MLOps流程
下图描述了如何将CI/CD开发和发布工作流应用于机器学习生命周期:
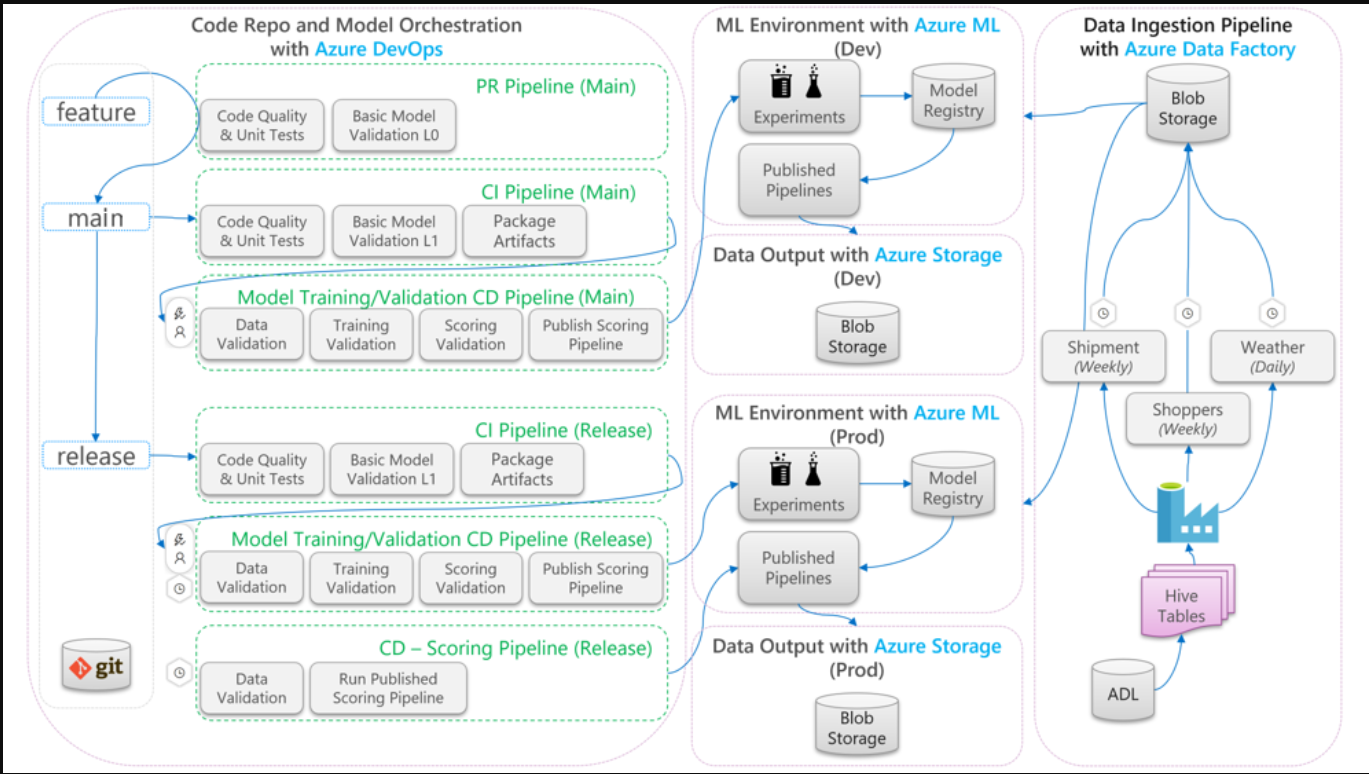
MLOps流程原型图
- 当从功能分支创建拉取请求(PR)时,管道运行代码验证测试,通过单元测试和代码质量测试来验证代码的质量。为了验证上游的质量,该管道还运行基本的模型验证测试,用一组模拟数据样本验证端到端的训练和评分步骤。
- 当PR合并到主分支中时,CI管道将运行相同的代码验证测试和基本模型验证测试,并增加epoch。然后,管道将打包工件,其中包括代码和二进制文件,以便在机器学习环境中运行。
- 工件可用后,将触发一个模型验证CD管道。它在开发机器学习环境上运行端到端验证。发布了评分机制。对于批量评分场景,评分管道被发布到机器学习环境中,并被触发以产生结果。如果你想使用实时评分场景,你可以发布一个网络应用程序或部署一个容器。
- 一旦创建了里程碑并将其合并到发布分支中,就会触发相同的CI管道和模型验证CD管道。这一次,它们是根据发布分支的代码运行的。
您可以将上面显示的MLOps流程数据流视为做出类似体系结构选择的项目的原型框架。
代码验证测试
机器学习的代码验证测试侧重于验证代码库的质量。这与任何具有代码质量测试(linting)、单元测试和代码覆盖率测量的工程项目都是相同的概念。
基本模型验证测试
模型验证通常是指验证生成有效的机器学习模型所需的完整的端到端过程步骤。它包括以下步骤:
- 数据验证:确保输入数据有效。
- 训练验证:确保模型能够成功训练。
- 评分验证:确保团队能够成功使用经过训练的模型与输入数据进行评分。
在机器学习环境中运行这一整套步骤既昂贵又耗时。因此,该团队在开发机器上本地进行了基本的模型验证测试。它运行了上面的步骤,并使用了以下内容:
- 本地测试数据集:一个小数据集,通常是一个模糊的数据集,它被检入到存储库并用作输入数据源。
- 本地标志:模型代码中的标志或参数,指示代码打算在本地运行数据集。标志告诉代码绕过对机器学习环境的任何调用。
这些验证测试的目的不是评估训练模型的性能。相反,它是为了验证端到端流程的代码是否具有良好的质量。它确保了向上游推送的代码的质量,比如在PR和CI构建中加入模型验证测试。它还使工程师和数据科学家可以将断点放入代码中进行调试。
模型验证CD管道
模型验证管道的目标是用实际数据验证机器学习环境中的端到端模型训练和评分步骤。生产的任何经过训练的模型都将被添加到模型注册中心并进行标记,以便在验证完成后等待升级。对于批量预测,推广可以是发布使用此版本模型的评分管道。对于实时评分,可以对模型进行标记以指示其已被提升。
评分CD管道
评分CD管道适用于批量推理场景,其中用于模型验证的同一模型协调器触发发布的评分管道。
开发与生产环境
将开发(dev)环境与生产(prod)环境分离是一种很好的做法。分离允许系统在不同的时间表上触发模型验证CD管道和评分CD管道。对于所描述的MLOps流,以主分支为目标的管道在dev环境中运行,以发布分支为目的的管道在prod环境中运行。
代码更改与数据更改
前几节主要讨论如何处理从开发到发布的代码更改。然而,数据更改应该遵循与代码更改相同的严格性,以在生产中提供相同的验证质量和一致性。通过数据更改触发器或计时器触发器,系统可以从模型协调器触发模型验证CD管道和评分CD管道,以运行与发布分支产品环境中针对代码更改运行的过程相同的过程。
MLOps人物角色
任何MLOps流程的一个关键要求是它满足流程中许多用户的需求。出于设计目的,将这些用户视为个人角色。对于这个项目,团队确定了以下人物角色:
- 数据科学家:创建机器学习模型及其算法。
- 工程师
- 数据工程师:处理数据调节。
- 软件工程师:负责将模型集成到资产包和CI/CD工作流中。
- 运维或IT:监督系统操作。
- 业务利益相关者:关注机器学习模型所做的预测以及它们如何帮助业务。
- 数据最终用户:以某种方式使用模型输出,这有助于做出业务决策。
该团队必须解决人物角色研究的三个关键发现:
- 数据科学家和工程师在工作中的方法和技能不匹配。使数据科学家和工程人员易于合作是MLOps流程设计的主要考虑因素。它需要所有团队成员获得新的技能。
有必要在不疏远任何人的情况下统一所有主要人物角色。一种方法是:- 确保他们理解MLOps的概念模型。
- 就将共同工作的团队成员达成一致。
- 制定工作准则以实现共同目标。
- 如果业务利益相关者和数据最终用户需要一种与模型输出的数据交互的方式,那么用户友好的UI就是标准解决方案。
其他团队肯定会在其他机器学习项目中遇到类似的问题,因为他们正在扩大生产规模。
MLOps解决方案架构
逻辑体系结构
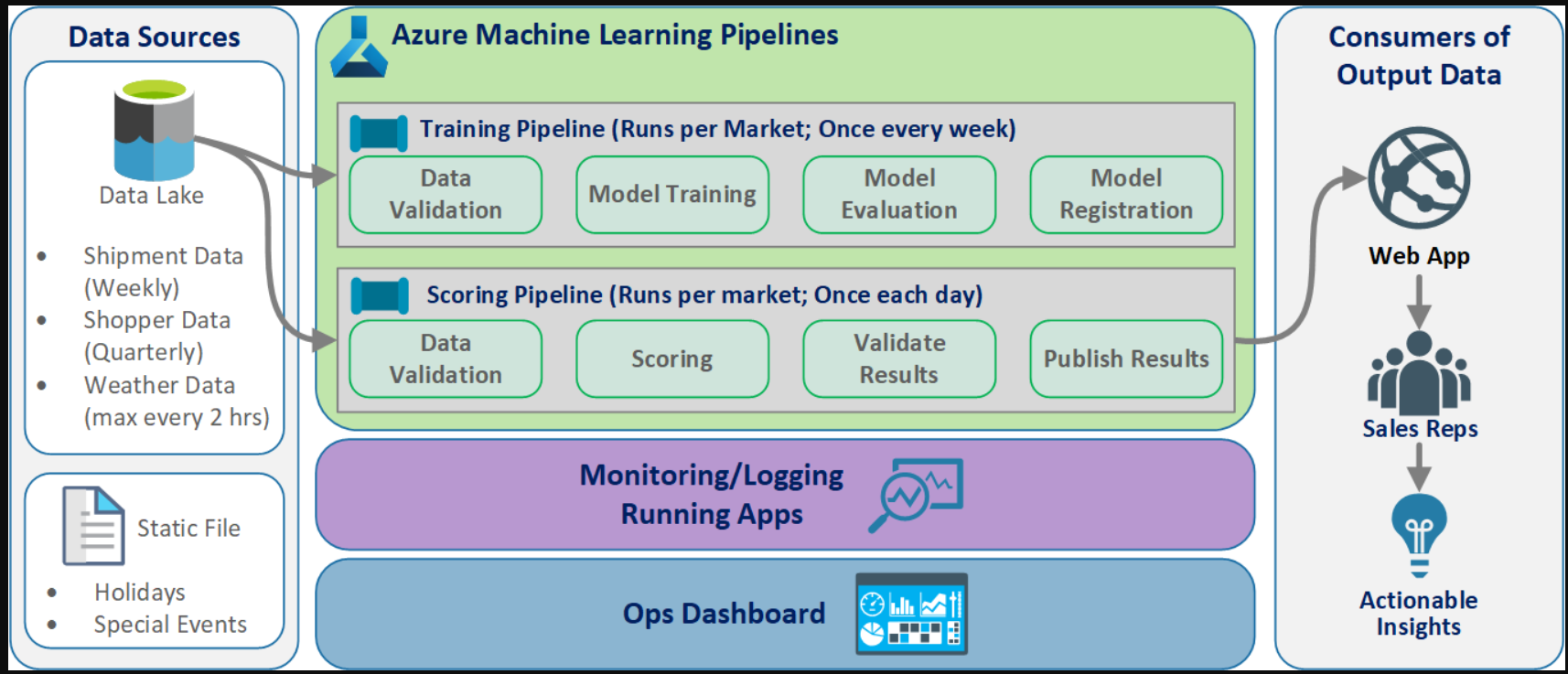
逻辑MLOps架构图。
数据来自许多不同格式的来源,因此在插入数据湖之前对其进行了调节。调节是通过使用作为Azure功能运行的微服务来完成的。客户定制微服务以适应数据源,并将其转换为标准化的csv格式,供培训和评分管道使用。
系统架构
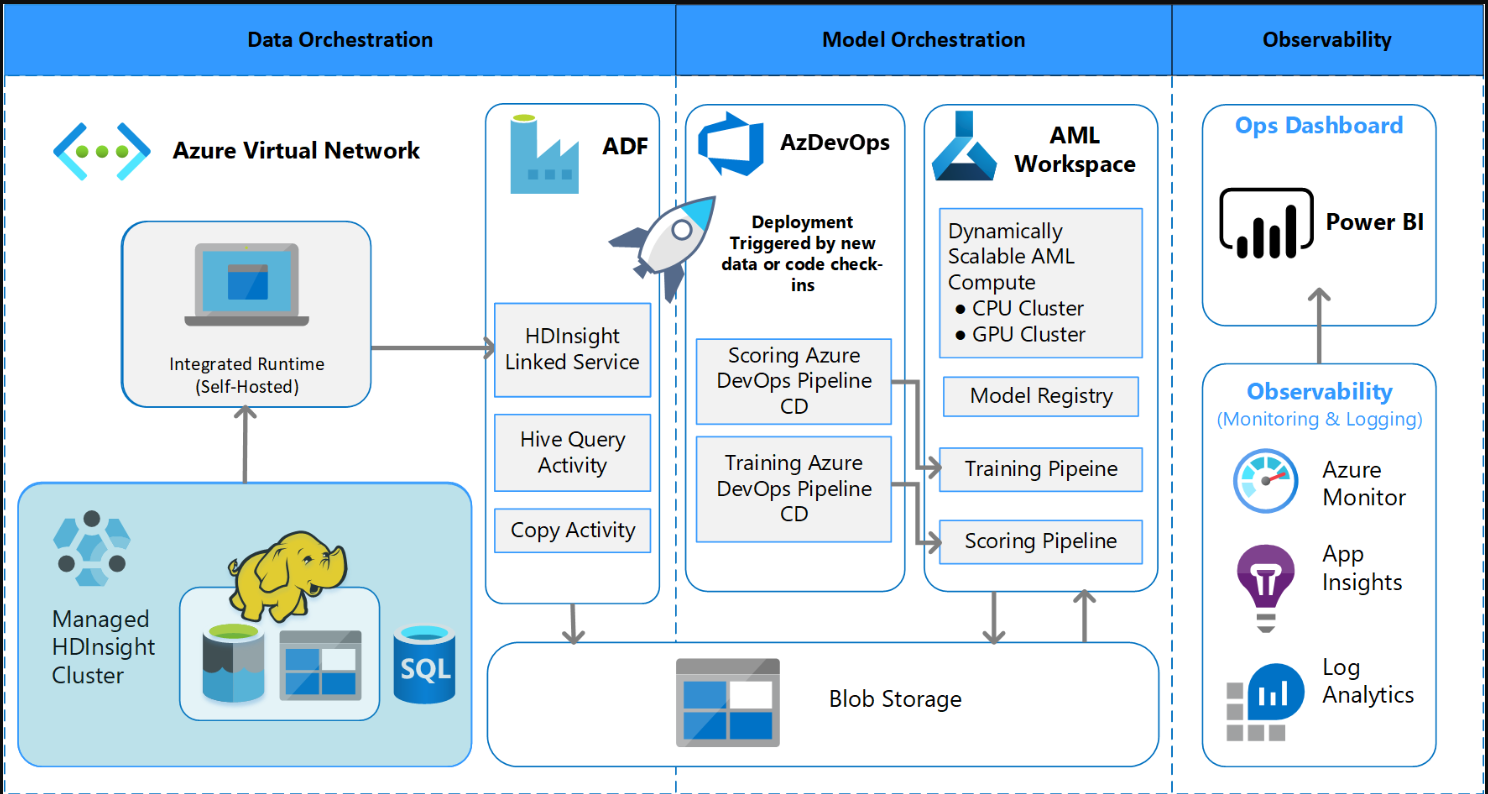
MLOps支持的系统架构图
批处理架构
该团队设计了支持批量数据处理方案的架构设计。有其他选择,但无论使用什么,都必须支持MLOps流程。充分使用可用的Azure服务是一项设计要求。下图显示了体系结构:

批处理体系结构的示意图。
解决方案概述
Azure数据工厂执行以下操作:
- 触发Azure函数以启动数据接收和Azure机器学习管道的运行。
- 启动一个持久功能以轮询Azure机器学习管道以完成。
Power BI中的自定义仪表板显示结果。通过OpenCensus Python SDK连接到Azure SQL、Azure Monitor和App Insights的其他Azure仪表板跟踪Azure资源。这些仪表板提供有关机器学习系统运行状况的信息。它们还生成客户用于产品订单预测的数据。
模型编排
模型编排遵循以下步骤:
- 当提交PR时,DevOps会触发一个代码验证管道。
- 管道运行单元测试、代码质量测试和模型验证测试。
- 当合并到主分支中时,会运行相同的代码验证测试,DevOps会打包工件。
- DevOps收集工件触发Azure机器学习:
- 数据验证。
- 培训验证。
- 评分验证。
- 验证完成后,运行最终评分管道。
- 更改数据并提交新的PR会再次触发验证管道,然后是最终的评分管道。
启用实验
如前所述,传统的数据科学机器学习生命周期不支持未经修改的MLOps过程。它使用了不同种类的手动工具和实验、验证、打包和模型切换,这些都是有效的CI/CD过程所无法轻易扩展的。MLOps需要高水平的流程自动化。无论是正在开发一个新的机器学习模型,还是修改一个旧的模型,都有必要自动化机器学习模型的生命周期。在第二阶段项目中,该团队使用Azure DevOps来编排和重新发布用于培训任务的Azure机器学习管道。长期运行的主分支执行模型的基本测试,并通过长期运行的发布分支推送稳定的发布。
源头控制成为这一过程的重要组成部分。Git是用于跟踪笔记本和模型代码的版本控制系统。它还支持流程自动化。为源代码管理实现的基本工作流程应用以下原则:
- 对代码和数据集使用正式的版本控制。
- 使用分支进行新代码开发,直到代码完全开发和验证。
- 验证新代码后,可以将其合并到主分支中。
- 对于发行版,将创建一个与主分支分离的永久版本化分支。
- 对已进行训练或消耗的数据集使用版本和源代码管理,以便保持每个数据集的完整性。
- 使用源代码管理来跟踪您的Jupyter Notebook实验。
与数据源集成
数据科学家使用许多原始数据源和经过处理的数据集来实验不同的机器学习模型。生产环境中的数据量可能是巨大的。为了让数据科学家对不同的模型进行实验,他们需要使用Azure data Lake等管理工具。形式识别和版本控制的要求适用于所有原始数据、准备好的数据集和机器学习模型。
在该项目中,数据科学家对以下数据进行了调节,以输入到模型中:
- 自2017年1月以来的历史每周发货数据
- 每个邮政编码的历史和预测每日天气数据
- 每个店铺ID的购物者数据
与源代码管理集成
为了让数据科学家应用工程最佳实践,有必要方便地将他们使用的工具与GitHub等源代码控制系统集成。这种做法允许机器学习模型版本控制、团队成员之间的协作,以及在团队出现数据丢失或系统中断时进行灾难恢复。
模型集成【ensemble】支持
该项目中的模型设计是一个整体模型。也就是说,数据科学家在最终的模型设计中使用了许多算法。在这种情况下,模型使用了相同的基本算法设计。唯一的区别是他们使用了不同的训练数据和得分数据。这些模型使用了LASSO线性回归算法和神经网络的组合。
该团队探索了一种将流程推进到支持在生产中运行许多实时模型以满足给定请求的选项,但没有实现。此选项可以适应在A/B测试和交错实验中使用集成模型。
最终用户界面
该团队开发了用于可观察性、监控和仪器的最终用户UI。如前所述,仪表板直观地显示机器学习模型数据。这些仪表板以用户友好的格式显示以下数据:
- 流水线步骤,包括预处理输入数据。
- 要监控机器学习模型处理的运行状况,请执行以下操作:
- 您从部署的模型中收集了哪些指标?
- MAPE:平均绝对百分比误差,是跟踪整体性能的关键指标。(每个模型的目标MAPE值<=0.45。)
- RMSE 0:实际目标值=0时的均方根误差(RMSE)。
- RMSE全部:整个数据集上的RMSE。
- 您如何评估您的模型在生产中的表现是否如预期?
- 有没有办法判断生产数据是否与预期值偏离过大?
- 你的模型在生产中表现不佳吗?
- 您有故障转移状态吗?
- 您从部署的模型中收集了哪些指标?
- 跟踪已处理数据的质量。
- 显示机器学习模型产生的评分/预测。
应用程序根据数据的性质以及处理和分析数据的方式填充仪表板。因此,团队必须为每个用例设计准确的仪表板布局。以下是两个示例面板:
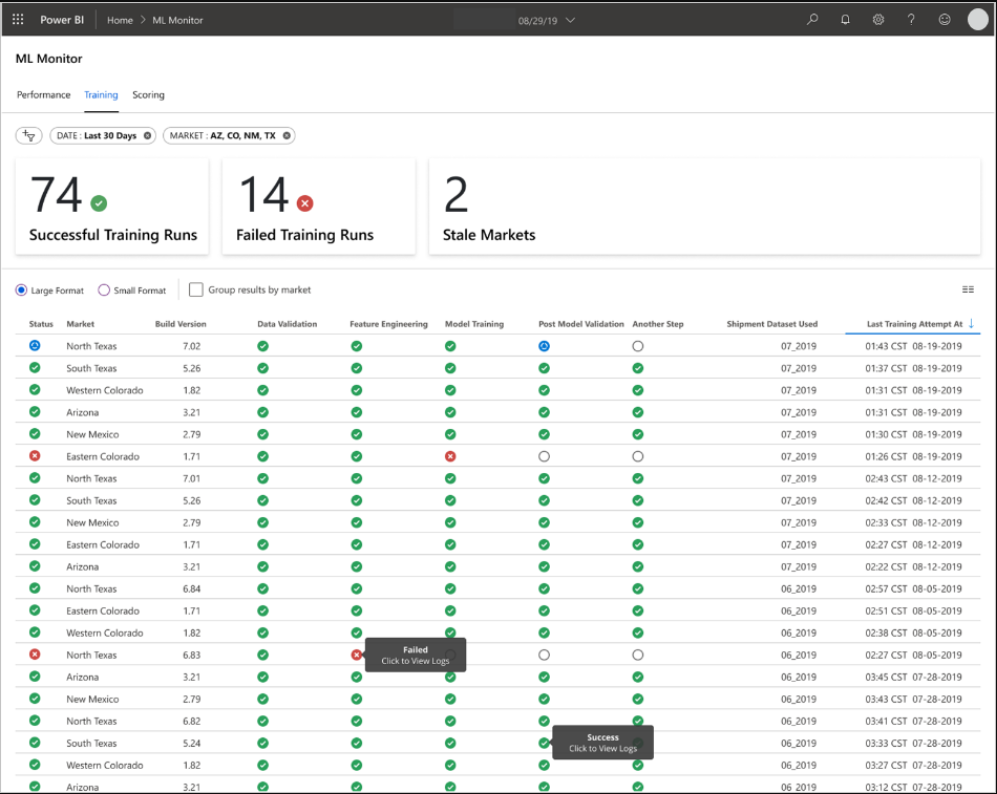
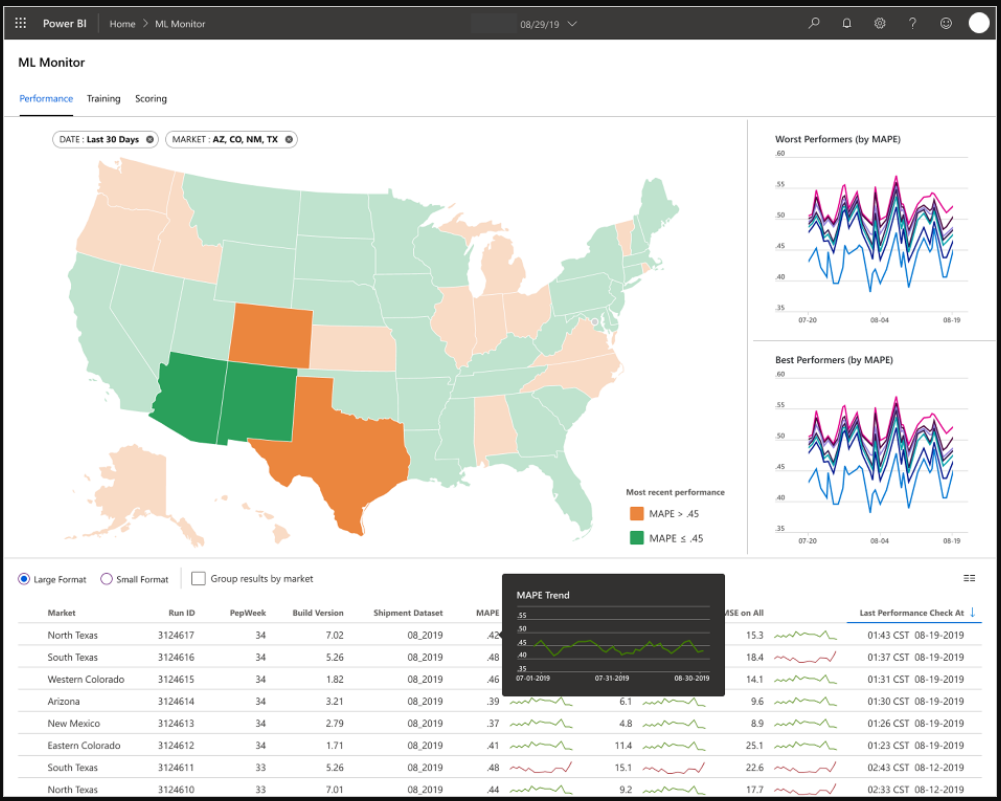
仪表板旨在为机器学习模型预测的最终用户提供易于使用的信息。
笔记
过时的模型是指数据科学家训练的模型,该模型用于从得分开始60多天后的得分。ML Monitor仪表板的Scoring(评分)页面显示此健康指标。
组件
- Azure Machine Learning Compute
- Azure Machine Learning Pipelines
- Azure Machine Learning Model Registry
- Azure Blob Storage
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Azure Functions for Python
- Azure Monitor
- Azure SQL Database
- Azure Dashboards
- Power BI
注意事项
在这里,您可以找到一个需要探索的注意事项列表。它们基于CSE团队在项目中吸取的经验教训。
环境注意事项
- 数据科学家通过使用Python开发他们的大多数机器学习模型,通常从Jupyter笔记本电脑开始。将这些笔记本电脑实现为生产代码可能是一项挑战。Jupyter笔记本更像是一种实验工具,而Python脚本更适合生产。团队通常需要花费时间将模型创建代码重构为Python脚本。
- 让刚接触DevOps和机器学习的客户意识到,实验和生产需要不同的严格性,因此将两者分开是一种很好的做法。
- Azure机器学习可视化设计器或AutoML等工具可以有效地启动基本模型,同时客户端可以逐步采用标准DevOps实践来应用于解决方案的其余部分。
- Azure DevOps具有可以与Azure机器学习集成的插件,以帮助触发管道步骤。MLOpsPython回购有几个这样的管道示例。
- 机器学习通常需要强大的图形处理单元(GPU)机器进行训练。如果客户端还没有这样的硬件可用,Azure机器学习计算集群可以提供一条有效的路径,快速提供具有成本效益的强大硬件,并自动扩展。如果客户端具有高级安全或监控需求,则还有其他选项,如标准VM、Databricks或本地计算。
- 为了让客户取得成功,他们的模型构建团队(数据科学家)和部署团队(DevOps工程师)需要有一个强大的沟通渠道。他们可以通过每天的单口相声会议或正式的在线聊天服务来实现这一点。这两种方法都有助于将它们的开发工作集成到MLOps框架中。
数据准备注意事项
- 使用Azure机器学习最简单的解决方案是将数据存储在支持的数据存储解决方案中。Azure数据工厂等工具对于按计划将数据传送到这些位置和从这些位置传送数据是有效的。
- 对于客户来说,经常获取额外的再培训数据以保持其模型的最新状态非常重要。如果他们还没有数据管道,那么创建一个数据管道将是整个解决方案的重要组成部分。使用Azure机器学习中的数据集等解决方案可以帮助对数据进行版本控制,以帮助实现模型的可追溯性。
模型培训和评估注意事项
- 对于一个刚刚开始机器学习之旅的客户来说,尝试实现完整的MLOps管道是非常困难的。如有必要,他们可以通过使用Azure机器学习来跟踪实验运行,并将Azure机器学习计算作为训练目标来轻松使用。这些选项可能会创建一个较低的进入门槛解决方案,以开始集成Azure服务。
- 对于许多数据科学家来说,从笔记本实验到可重复的脚本是一个艰难的转变。你越早让他们用Python脚本编写训练代码,他们就越容易开始对训练代码进行版本控制并启用再培训。
- 这不是唯一可能的方法。Databricks支持将笔记本计划为作业。但是,根据当前的客户体验,由于测试的局限性,这种方法很难与完整的DevOps实践相结合。
- 同样重要的是,要了解使用哪些指标来衡量模型是否成功。仅凭准确性往往不足以确定一个模型与另一个模型的整体性能。
计算注意事项
- 客户应该考虑使用容器来标准化他们的计算环境。几乎所有Azure机器学习计算目标都支持使用Docker。让容器处理依赖关系可以显著减少摩擦,尤其是在团队使用许多计算目标的情况下。
模型服务注意事项
- Azure机器学习SDK提供了一个选项,可以从注册模型直接部署到Azure Kubernetes服务(AKS),从而对现有的安全性/指标进行限制。您可以尝试为客户端找到一个更简单的解决方案来测试他们的模型,但最好为生产工作负载开发一个更健壮的AKS部署。
Next steps
Related resources
- 登录 发表评论
- 115 次浏览
最新内容
- 1 week 2 days ago
- 2 weeks 3 days ago
- 3 weeks ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago