
category
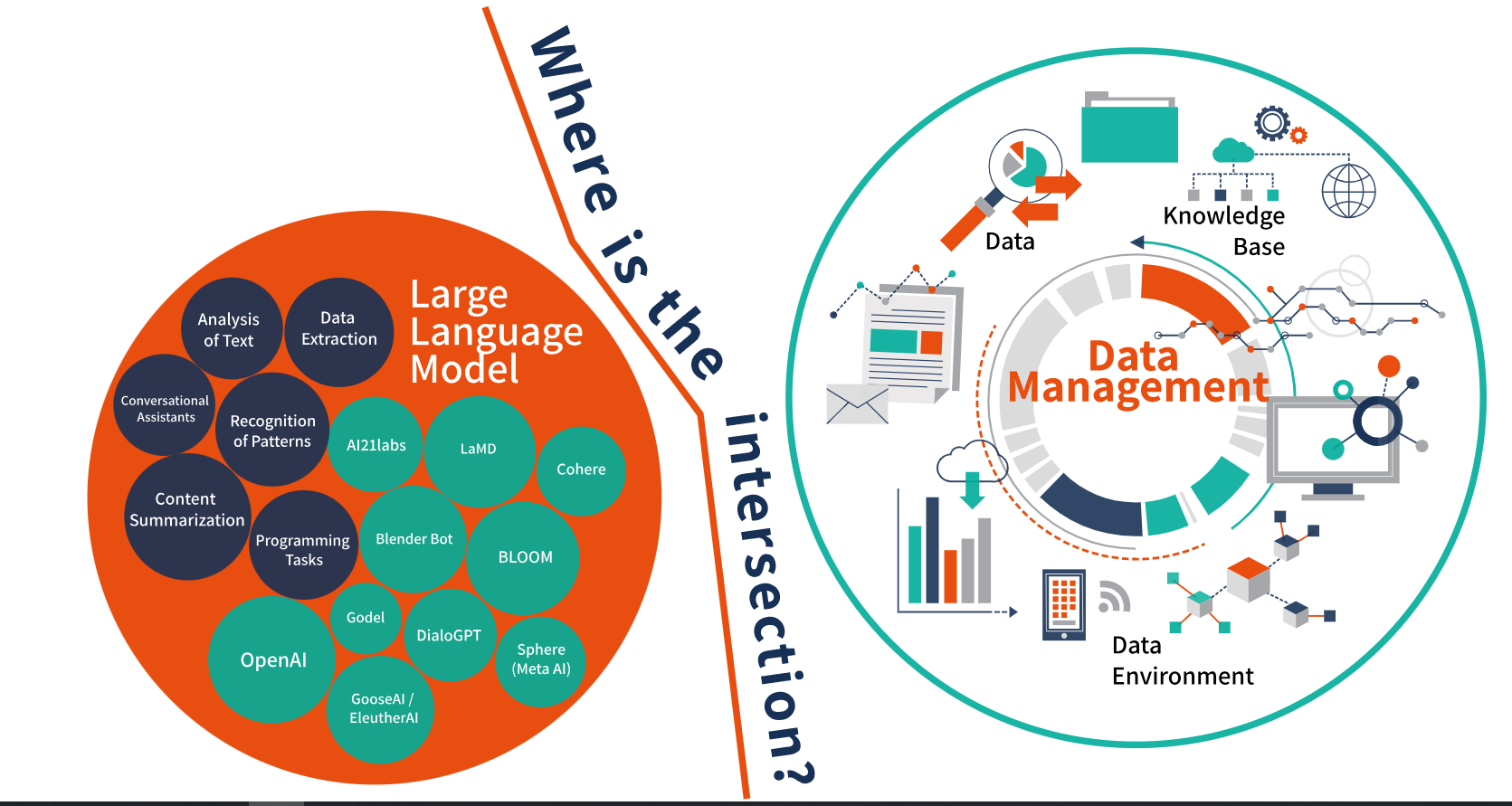
我做了一些研究,因为我想创建一个关于大型语言模型(LLM)和数据管理之间交叉的基本框架。我首先要说的是,我相信LLM有很大的前景。但也有许多其他问题(和注意事项)需要考虑。这项技术是非常新的,人们还不太了解。大多数应用程序仍处于探索阶段。很少有产品在生产中,而且这个主题很快就从研究转向了应用。
LLM在设计上就是一种语言模型。因此,逻辑应用程序是与文本分析和模式识别相关联的应用程序。这些类型的应用程序包括内容摘要、编程任务、数据提取和会话助手(聊天机器人)。随着技术的成熟,我相信一些更有价值的应用将是与血统和出处相关的应用,比如使用LLM来促进连接库存的开发并增强数字孪生能力。

数据意义至关重要
需要注意的是,LLM只是“文本预测代理”这意味着它们高度依赖于用作输入的知识库(数据)的质量。我敦促早期采用者将此视为他们现有努力的扩展,以在您的组织中定义、管理和治理数据和相关流程。
对于考虑如何利用该技术的公司,我建议最好的方法是从一个执行良好和“受控”的数据环境开始,包括良好的体系结构模式(即分类法、本体论、内部数据结构)。实现这一核心数据管理功能(最好使用语义标准)应被视为充分利用LLM功能的先决条件。数据的含义是最重要的组成部分,因为数据模型正在成为一种商品。有人多次强调,LLM只有与数据源一样好。
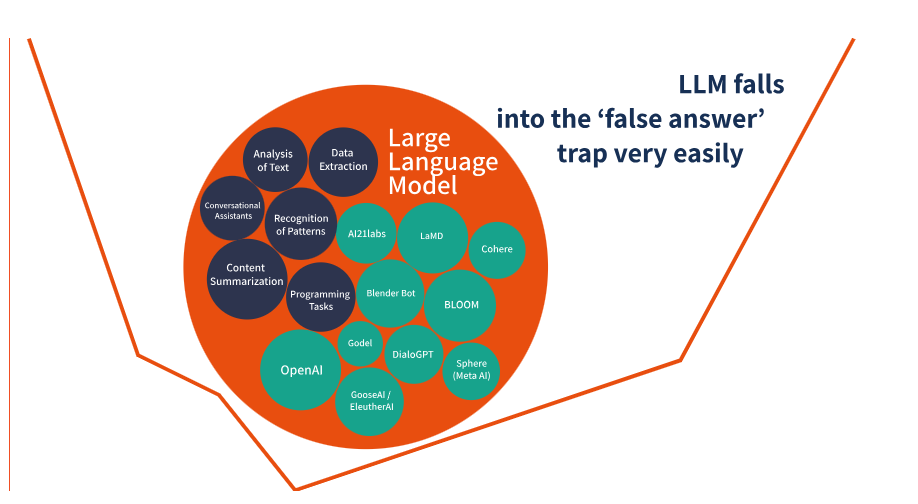
几个注意事项
LLM引用了大量的数据来实现真正的功能,这使得训练模型变得非常昂贵和耗时。超级计算机(和基础设施的其他组件)以及数据体系结构的新方法(具有数十亿个参数)都是必要的。
另一个问题与“数据约束”的定义有关连接到经过预训练的LLM是基于API的。但接口过于简单,用户必须考虑如何在共享LLM上强制执行数据策略。出于安全原因,建议LLM访问所有内部API时要小心。管理访问权限和授权权限(以及它们的存储位置)至关重要,而且可能存在问题。
要利用现有的LLM,您必须同意公开您的数据。在这种环境下,所有的秘密都会暴露出来,所有的操作方面都必须考虑在内。所有数据都必须通过一个中心位置,这可能有风险、昂贵且难以保护。出于隐私考虑,一些公司禁止使用它们。
质量问题
大多数LLM都是根据互联网上的数据进行培训的,这意味着质量可能存在偏差。在质量方面,LLM很容易陷入“错误答案”的陷阱。他们接受没有意义的词语。LLM把所有的事情都表现得好像它们是真的一样。如果存在重复(冲突)的信息,LLM并不在乎——它只是根据现有信息来编造答案。在经过事实核查之前,任何事情都不应被视为决定性的。
培训LLM需要建立强大的数据管道,这些管道既高度优化又足够灵活,可以轻松地包括公共和专有数据的新来源。在您自己的云环境上运行LLM可以提供更多的安全性和更高的上下文准确性,但很少有实验室可以训练LLM,使用您自己的规则进行自我训练是可能的,尽管代价高昂。
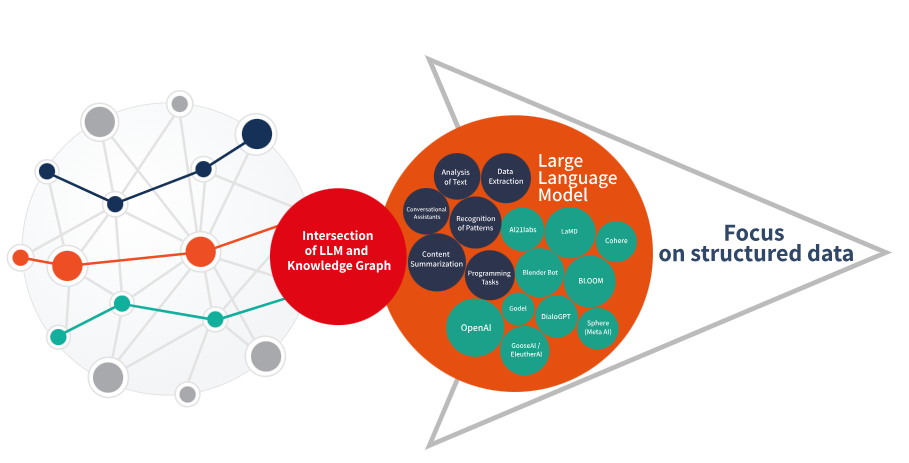
从结构化数据开始
实验LLM功能的理想方式是一开始就关注结构化数据。清理、完善数据并使其与共享的意义相一致是正确的战略方法。LLM可以从结构化内容中学习,这使您能够利用其他领域的内容重用,同时继续为知识库增加深度和广度。
换言之,掌握好基本知识——专注于通过IRI实现身份解析的领域,即通过结构化本体和使用SHACL的可执行业务规则进行解析。预先定义您的用例,并基于这些用例构建您的本体。投资一个“即时工程师”,可以通过组织的API将LLM链接到其他数据。提示是一个迭代过程,它依赖于LLM所训练的模型。没有本体,LLM就无法学习。如果没有这些规则,他们就无法保护您的敏感数据。如果没有管理得当的数据管理办公室的监督,他们就无法保证质量。
可能很难抗拒直接进入LLM池的诱惑——但请记住,LLM作为一种自助服务功能仍在成熟。尽管人们对LLM将迅速成熟抱有很高的期望,但大多数活动和应用仍处于实验阶段。我个人对LLM和语义标准(知识图)的交叉点感到兴奋。最有效地使用LLM的先决条件是获得你的数据体系结构和工程。尝试吧——但要小心,你不会被炒到炒作曲线的顶端。
- 登录 发表评论
- 126 次浏览
最新内容
- 1 week ago
- 2 weeks 1 day ago
- 2 weeks 5 days ago
- 2 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago