
category
了解如何设置安全的Azure Databricks架构以保护数据泄露的详细信息
在上一篇博客中,我们讨论了如何使用虚拟网络服务端点或专用链接从Azure Databricks安全访问Azure数据服务。
这里是一个快速回顾:
- 服务原则:使用Azure AD服务原则进行安全身份验证。
- 托管身份:利用托管身份进行安全访问,而无需处理凭据。
- Azure密钥库:使用Azure密钥库安全地存储和管理机密。
- Direct3D和专用端点:确保使用ExpressRoute注入和专用链接进行安全网络连接。
在本文中,我们将详细介绍如何从网络安全的角度加强Azure Databricks部署,以防止数据泄露。
根据维基百科:当恶意软件和/或恶意行为者从计算机进行未经授权的数据传输时,就会发生数据泄露。它也常被称为数据挤出或数据导出。数据泄露也被认为是一种数据盗窃。自2000年以来,许多数据泄露行为严重损害了消费者信心、企业估值、企业知识产权和世界各国政府的国家安全。随着企业开始使用公共云服务存储和处理敏感数据(PII、PHI或战略机密),这个问题变得更加重要。
如果PaaS服务要求您与他们一起存储数据,或者在服务提供商的网络中处理数据,那么解决数据泄露可能会成为一个无法管理的问题。但是,使用Azure Databricks,我们的客户可以将所有数据保存在他们的Azure订阅中,并在他们自己的托管私有虚拟网络中处理,同时保留Azure上增长最快的数据和人工智能服务之一的PaaS性质。我们已经为平台提出了一个安全的部署架构,同时与一些最具安全意识的客户合作,现在是我们广泛分享它的时候了。
Databricks Deployment Options
从网络的角度来看,有三种不同风格的Rancher工作区部署。
- 在Microsoft管理的虚拟网络(ExpressRoute)中部署工作区
- 在客户管理的虚拟网络中部署工作区(ExpressRoute注入)
- 使用Private Link在客户管理的虚拟网络中部署工作区
- Deploy workspace in a Microsoft managed virtual network(VNet)
- Deploy workspace in a Customer managed virtual network (VNet injection)
- Deploy workspace in a Customer managed virtual network with Private Link
请注意,无论您选择什么选项,Rancher使用的虚拟网络都将驻留在您的Azure订阅中。本文的其余部分是围绕选项3构建的,即在具有安全集群连接和专用链接的客户管理的虚拟网络中部署工作区。
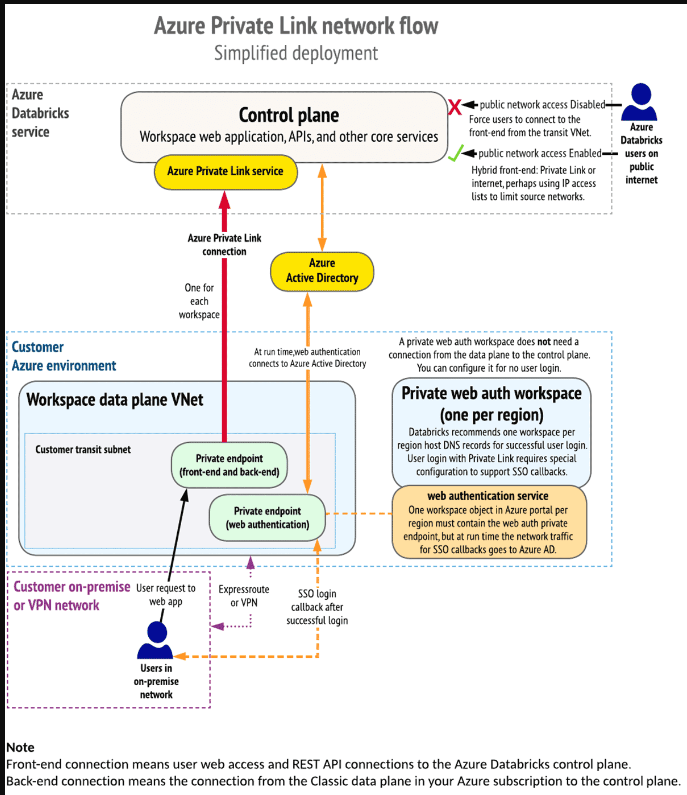
选择标准部署或简化部署
从这里开始:Azure Databricks支持两种类型的私有链接部署,您必须选择一种:
- 标准部署(推荐):为了提高安全性,Databricks 建议您从单独的传输Contoso为前端连接使用单独的私有端点。您可以实现前端和后端专用链接连接,也可以只实现后端连接。使用单独的Contoso封装用户访问,与您在经典数据平面中用于计算资源的ExpressRoute分开。为后端和前端访问创建单独的专用链接端点。按照“启用Azure专用链接作为标准部署”中的说明进行操作。

- 简化部署:由于各种网络策略原因,一些组织无法使用标准部署,例如不允许多个私有端点或不鼓励单独的传输。您也可以选择使用Private Link简化部署。没有单独的Contoso将用户访问与您在经典数据平面中用于计算资源的ExpressRoute分开。相反,数据平面ExpressRoute中的传输子网用于用户访问。只有一个专用链接端点。通常,前端和后端连接都已配置。您可以选择只配置前端连接。您不能选择在此部署类型中仅使用后端连接。按照“启用Azure专用链接作为简化部署”中的说明进行操作。
高级数据过滤保护架构
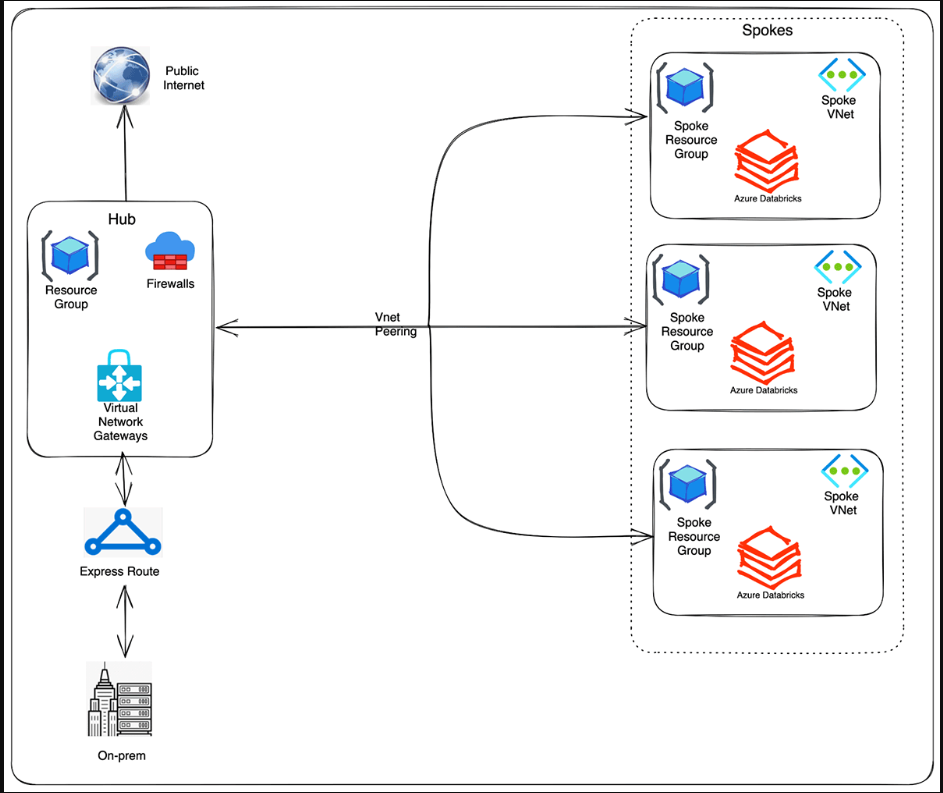
我们推荐一种中心辐射拓扑风格的参考架构。集线器虚拟网络容纳了连接到经过验证的源以及可选地连接到本地环境所需的共享基础设施。辐条虚拟网络与中心对等,同时为不同的业务部门或隔离的团队提供隔离的Azure Databricks工作区。
这种中心辐射式架构允许为不同的目的和团队创建多个辐射式VNET。也可以通过在大型连续虚拟网络中为不同团队创建单独的子网来实现隔离。在这种情况下,完全可以在他们自己的子网对中设置多个隔离的Azure Databricks工作区,并在同一虚拟网络中的另一个子网中部署Azure防火墙。
高级视图:
部署安全Azure Databricks部署的步骤:
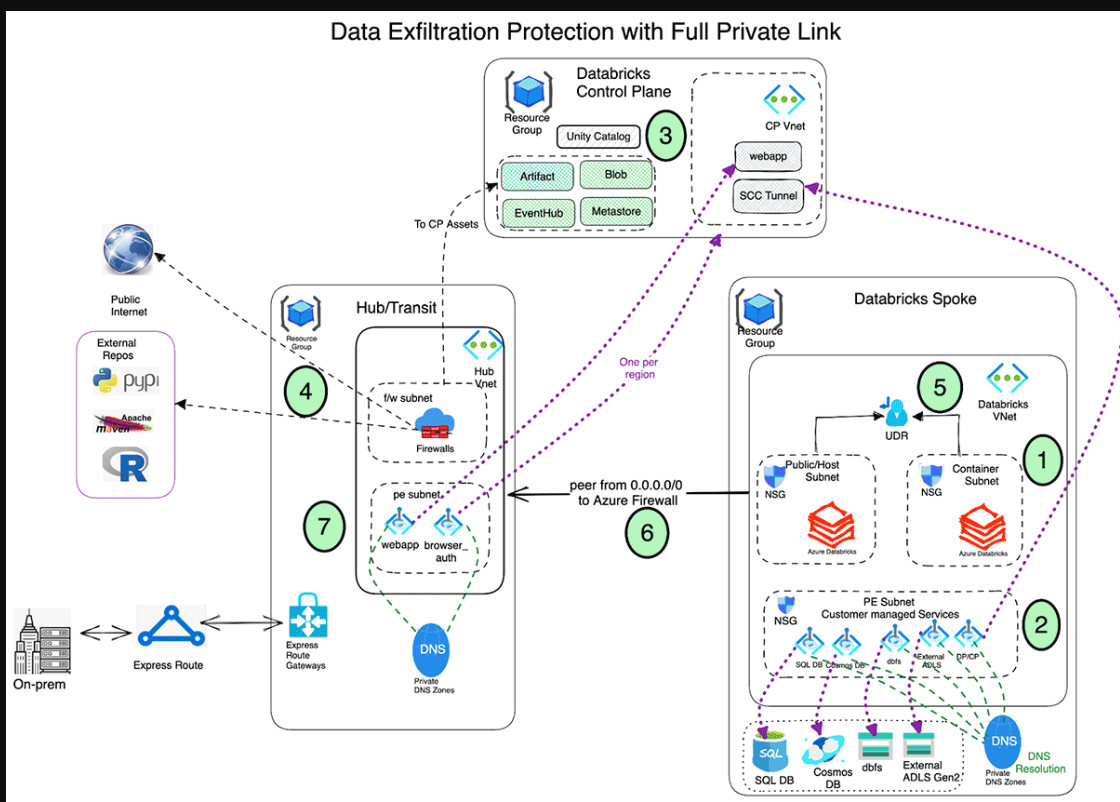
- 在辐条式虚拟网络中,使用ExpressRoute注入和Private link部署启用了安全集群连接(SCC)的Azure Databricks。
- 将Azure数据服务(存储帐户、Eventhub、SQL数据库等)的专用链接终结点设置在Azure Databricks speak虚拟网络中的单独子网中。这将确保所有工作负载数据都能通过Azure骨干网安全访问,并具有默认的数据泄露保护(有关更多详细信息,请参阅本博客)。此外,一般来说,将这些端点部署在另一个虚拟网络中是完全可以的,该虚拟网络与托管Azure Databricks工作区的虚拟网络相连接。请注意,专用端点会产生额外的成本,可以利用(基于您组织的安全策略)服务端点而不是专用端点来访问Azure数据服务。
- 利用Azure Databricks Unity Catalog实现统一治理解决方案。
- 在集线器虚拟网络中部署Azure防火墙(或其他网络虚拟设备)使用Azure防火墙,您可以配置:
- 定义可通过防火墙访问的完全限定域名(FQDN)的应用程序规则。可以使用应用程序规则将某些Azure Databricks所需的流量列入白名单。
- 为无法使用FQDN配置的端点定义IP地址、端口和协议的网络规则。需要使用网络规则将一些所需的Azure Databricks流量列入白名单。
如果你碰巧使用第三方防火墙设备而不是Azure防火墙,那也可以。不过请注意,每种产品都有自己的细微差别,最好让相关的产品支持和网络安全团队来解决任何相关问题。
- 创建一个用户定义的路由表,使我们能够将来自数据块使用的子网的所有流量转发到Azure防火墙等出口设备。或者,出口流量也可以通过用户定义的路由表(并添加服务标签规则)路由到控制平面资产,这可以避免与网络虚拟设备相关的节流和额外的数据传输成本。请注意,这将允许访问整个地区的存储帐户和服务,而不仅仅是您希望访问的帐户和服务。在设计安全架构时,需要仔细考虑这一点。
- 配置Azure Databricks辐条和Azure防火墙集线器虚拟网络之间的虚拟网络对等。
- 在集线器Vnet(专用端点子网)上为前端和浏览器身份验证(用于SSO)部署专用端点
安全Azure Databricks部署详细信息
在开始之前:
- 为什么每个工作区需要两个子网?
一个工作区需要两个子网,通常称为“主机”(又名“公共”)和“容器”(亦称“私有”)子网。每个子网都为主机(Azure VM)和在VM内运行的容器(Rancher runtime,又名dbr)提供一个ip地址。 - 公用子网或主机子网是否有公用ip?
不,当您使用安全集群连接(即SCC)创建工作区时,没有一个子网具有公共IP地址。只是主机子网的默认名称是公用子网。SCC确保没有来自网络外部的网络流量(例如SSH)进入其中一个copula工作区计算实例。 - 部署后是否可以调整/更改子网大小?
是的,部署后可以调整或更改子网大小。无法更改虚拟网络或更改子网名称。请联系Azure支持,提交调整子网大小的支持案例。
预备知识
| Item | Details |
|---|---|
| Virtual Network | Virtual network to deploy Azure Databricks Dataplane (a.k.a VNet Injection). Make sure to choose the right CIDR blocks. |
| Subnets | Three subnets Host (Public), Container (Private) and Private endpoint Subnet (to hold private endpoints for the storage, dbfs and other azure services that you may use) |
| Route Tables | Channel Egress traffic from the Databricks Subnets to network appliance, Internet or On-prem data sources |
| Azure Firewall | Inspect any egress traffic and take actions according to allow / deny policies |
| Private DNS Zones | Provide reliable, secure DNS service to manage and resolve domain names in a virtual network (can be automatically created as part of the deployment if not available) |
| Azure Key Vault | Stores the CMK for encrypting DBFS, Managed Disk and Managed Services. |
| Azure Databricks Access Connector | Required if enabling Unity Catalog. To connect managed identities to an Azure Databricks account for the purpose of accessing data registered in Unity Catalog |
| List of Azure Databricks services to allow list on Firewall | Please follow this public doc and make a list of all the ip’s and domain names relevant to your databricks deployment |
在虚拟网络中部署Azure Databricks
步骤1:在您的虚拟网络中部署Azure Databricks Workspace
Azure Databricks的默认部署会在Rancher管理的资源组中创建一个新的虚拟网络(有两个子网)。为了对安全部署进行必要的自定义,工作区数据平面应该部署在您自己的虚拟网络中,也就是使用NPIP注入vnet的工作区。此部署可以使用Azure门户或All-in-one ARM模板或使用Azure Databricks Terraform Provider完成。
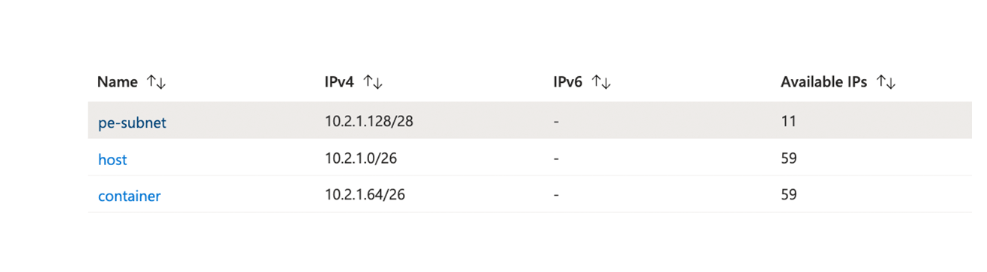
在具有3个子网(主机/公共、容器/私有和pe)的资源组中创建虚拟网络。请注意,子网pe用于私有端点,以确保所有应用程序数据都能通过Azure骨干网安全访问。在部署工作区之前,需要根据用例确定主机(公共)和容器(私有)子网。一旦部署了copula工作区,就无法调整/更改copula网络子网的大小。
从Azure门户部署Azure Databricks
从Azure门户使用Vnet注入和无公共IP(SCC)创建Azure Databricks工作区


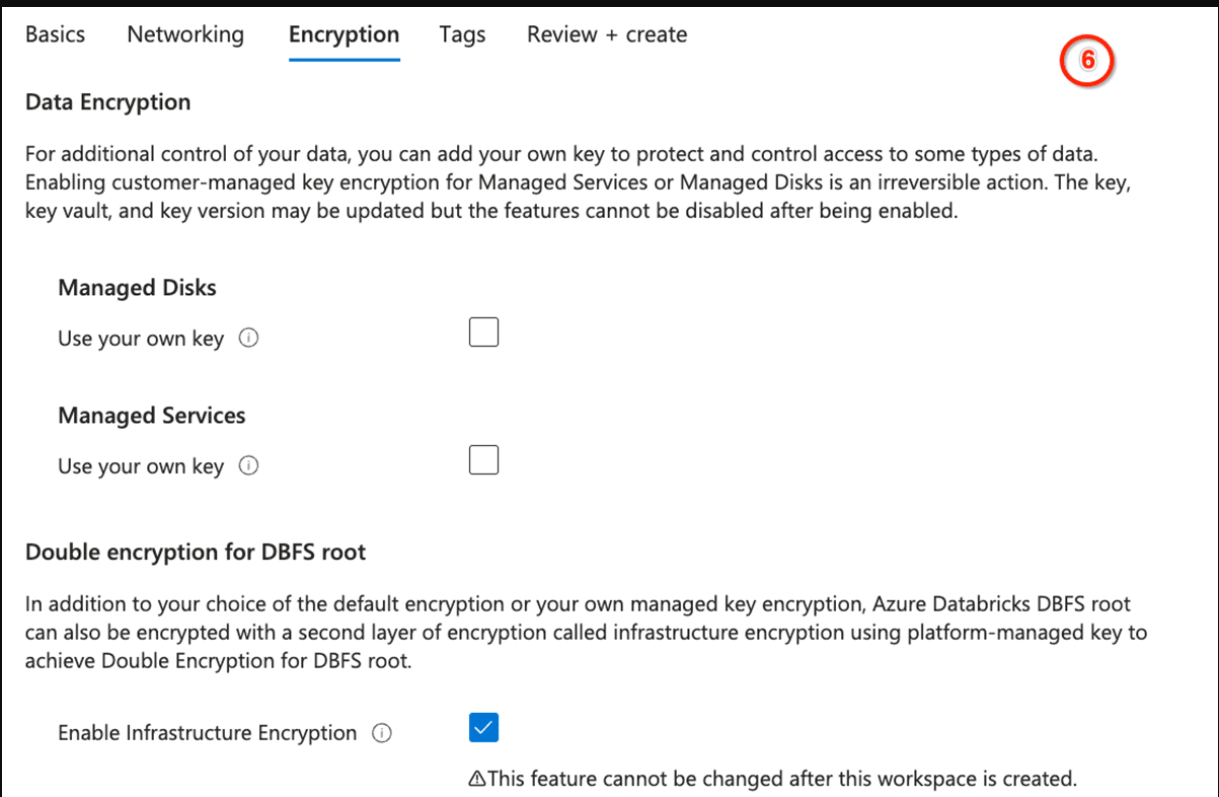
单击“查看和创建”。有几件事需要注意:
- 选择SCC/NPIP和ExpressRoute注入选项。
- 选择要部署Azure DatabricksWorkspace的虚拟网络。
- 虚拟网络必须包括两个子网,分别专用于每个Azure Databricks工作区:一个子网和一个子网(可以使用不同的命名法)。
- 公共子网是每个群集节点的主机VM的私有IP的来源。私有子网是部署在每个集群节点上的Rancher Runtime容器的私有IP的来源。这表明每个集群节点今天都有两个私有IP地址。
- 每个工作区子网大小允许在/18到/26之间,实际大小将基于对每个工作区整体工作负载的预测。地址空间可以是任意的(包括非RFC 1918的地址空间),但它必须与企业内部部署和云网络战略保持一致。
- 当您使用Azure门户部署工作区时,Azure Databricks将为您创建这些子网,并将执行子网委派给Microsoft。Connection/workspaces服务。这允许Azure Databricks创建所需的网络安全组(NSG)规则。如果我们需要添加或更新Azure Databricks管理的NSG规则的范围,Azure Databricks将始终提前通知。请注意,如果这些子网已经存在,服务将直接使用它们。下表详细解释了这些NSG规则。
- 在这些子网和Azure Databricks工作区之间存在一对一的关系。您不能在同一子网对中共享多个工作区,并且必须为每个不同的工作区使用新的子网对。
- 一旦部署了工作区,就不能重新调整公共和私有子网的大小。
- 请注意,Azure Databricks部署将在Azure门户上的Azure Databricks资源概述页面中创建一个托管资源组。您无法在托管资源组中创建任何资源,也可以编辑任何现有资源。
- Azure Databricks支持前端(用户到工作区,即允许公共网络访问设置为“禁用”)和后端(数据平面到控制平面,即没有Azure Databricks规则)的私有链接,启用私有连接,而不会将Azure Databricks管理流量暴露给公共互联网。
- 通过使用简化或标准部署模式,按照文档中的说明创建私有端点,以使用私有链接部署Azure Databricks。
- 启用客户管理的密钥来加密和保护DBFS、托管服务和托管磁盘。
网络安全规则:它是什么意思?
入站规则

Worker-to-Worker入站规则允许集群实例之间的流量。
出站规则
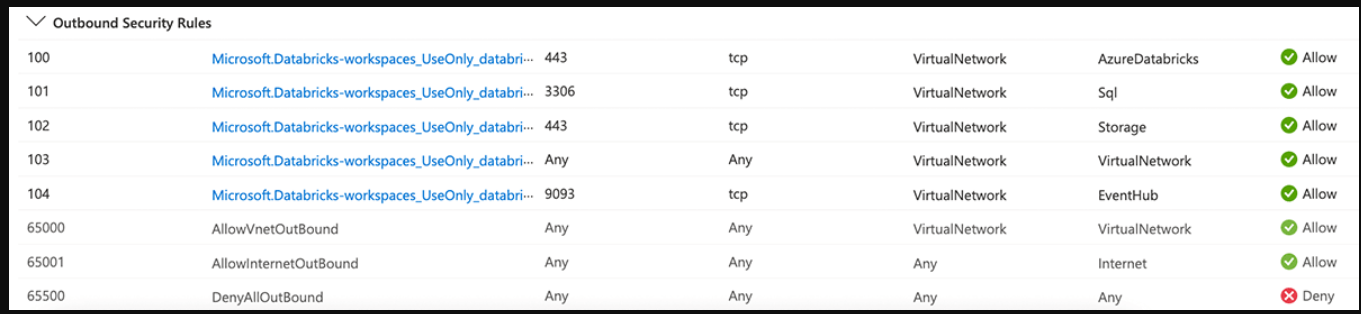
- Worker-to-Worker规则允许集群实例之间的流量,以便驱动程序和Worker可以相互通信。
- Metastore(Sql服务标签)允许从公共子网到默认HMS的出站流量
- 控制平面(AzureRancher服务标签)允许从公共子网到Azure Databricks控制平面(即SCC、Webapp)的出站流量。
注意:如果启用了后端私有链接,则AzureDatabricks服务标记将不会添加到NSG规则中。 - 存储(存储服务标签)允许出站流量从公共子网控制平面资产,如日志存储、工件和dbfs
- 事件中心(EventHub服务标签)允许从公共子网到事件中心端点的出站流量(用于可观察性)
- 对于启用了专用链接的工作区,需要添加两个额外的(4436666)端口,以便与专用端点子网进行出站通信。需要为私有端点子网的NSG规则上的入站通信打开相同的端口。
- 出站流量规则65001允许出站到互联网,这是在NSG创建时添加的自动规则。在本节的后面,我们将通过将来自Azure Databricks子网的所有出口流量转发到防火墙而不是直接发送到公共互联网来覆盖此行为。
步骤2:为默认blob存储(DBFS)设置专用终结点(可选)
Azure Databricks在部署过程中创建了一个默认的blob存储(也称为根存储),用于存储日志和遥测数据。即使在此存储上启用了公共访问,在此存储上创建的拒绝分配也禁止对存储的任何直接外部访问;它只能通过copula工作区访问。Azure Databricks部署现在支持通过创建专用终结点(dfs和blob)安全连接到根blob存储(DBFS),但为DBFS启用专用终结点不会关闭公共访问。请注意,存储的专用端点会产生额外的成本。
作为最佳实践,不建议将任何应用程序数据存储在根blob(DBFS)存储中。利用单独的ADLS Gen2存储,使用专用链接存储任何特定于应用程序的数据(安全访问Azure数据服务)
我们不建议通过网络虚拟设备/防火墙设置对此类数据服务的访问,因为这可能会对大数据工作负载和中间基础设施的性能产生不利影响。
注意:强烈建议将应用程序数据存储在外部ADLS Gen2存储上。遵循类似的设置,为外部ADLS存储创建私有链接端点,以安全地访问/存储数据。
要为其他服务配置此类专用终结点,请参阅相关的Azure文档。
步骤3:部署Azure防火墙
Azure防火墙是一个可扩展的云原生防火墙,可以作为过滤设备,用于过滤任何允许的公共端点,以便从您的Azure Databricks工作区访问。
通常,防火墙被放置在集中式集线器上,并通过多个轮辐VNet进行对等连接。Spoke-Vnet通过防火墙清除所有流量。
Azure防火墙策略是为Azure防火墙创建规则的推荐方法。防火墙策略是可跨多个Azure防火墙实例使用的全局资源。
创建网络规则(基于ip地址)和应用程序规则(基于FQDN)集合。下面的示例显示了一组具有代表性的规则,有关确切的详细信息,请参阅与您的部署区域相关的控制平面资产的完整列表。


注:-
如果为工作区启用了私有终结点,则不需要AzureDatabricks服务标记。
Azure Databricks还对NTP服务、CDN、cloudflare、GPU驱动程序和外部存储进行额外调用,以获取需要适当列入白名单的演示数据集。
将防火墙策略附加到防火墙。
步骤4:创建用户定义路由(UDR)
此时,大部分基础设施设置已完成。接下来,我们需要将流量从Azure Databricks工作区子网路由到Azure防火墙。
创建一个路由表,并通过向虚拟设备(azure防火墙)添加0.0.0.0/0规则来转发所有流量。

步骤5:配置VNET对等
最后,需要对虚拟网络中的azuredatabricks辐条vnet和集线器vnet进行透视,以便之前配置的路由表能够正常工作。按照文档设置集线器和辐条网络之间的Vnet对等。
设置现在已完成。
步骤6:分配工作区Unity目录元存储
我们现在处于最后一步。现在,将工作空间分配给Unity目录。
步骤7:验证部署
现在是时候测试一切了:
- 如果前端访问被禁用,则部署具有ExpressRoute的虚拟机。
- 转到您在步骤1中创建的Azure Databricks工作区,启动并创建集群。
- 创建一个笔记本并将其附加到集群。
- 尝试访问您在前面的步骤2中创建的存储帐户。
如果数据访问工作正常,没有任何问题,这意味着您已经在订阅中完成了Azure Databricks的最佳安全部署。这是相当多的手工工作,但这更多的是一次性展示。实际上,您希望使用ARM模板、Azure CLI、Azure SDK等的组合来自动化此类设置:
- Deploy Azure Databricks in your own managed VNET using ARM Template
- Create Private Endpoint using Azure CLI (or ARM Template)
- Deploy Azure Firewall using ARM Template (or Azure CLI)
- Deploy Route Table and Custom Routes using ARM Template
- Peer Virtual Networks using ARM Template
- Create Private Link for Azure Databricks with Terraform
数据过滤保护架构的常见问题
我可以使用服务端点来保护数据出口到Azure数据服务吗?
是的,服务端点通过Azure骨干网络上的优化路由,提供与客户拥有和管理的Azure服务(例如:ADLS gen2、Azure密钥库或事件中心)的安全和直接连接。服务端点可用于确保与外部Azure资源的连接仅限于您的虚拟网络。
我是否可以将服务端点策略与copula管理的存储服务一起使用?
不,使用网络意图策略锁定了copula使用的子网,这阻止了在我们的工件和日志服务以及健康监控服务使用的事件中心所使用的copula管理的存储服务上实施服务端点策略。Azure网络意图策略是一种内部网络构造,用于防止客户意外修改Rancher使用的子网。
我可以使用Azure防火墙以外的网络虚拟设备(NVA)吗?
是的,只要按照本文所述配置网络流量规则,您就可以使用第三方NVA。请注意,我们仅使用Azure防火墙测试了此设置,尽管我们的一些客户使用其他第三方设备。将设备部署在云端而不是本地是理想的。
我可以在与Azure Databricks相同的虚拟网络中拥有防火墙子网吗?
是的,你可以。根据Azure参考架构,建议使用中心辐射虚拟网络拓扑,以便更好地规划未来。如果您选择在与Azure Databricks工作区子网相同的虚拟网络中创建Azure防火墙子网,则不需要按照上述步骤6中的讨论配置虚拟网络对等。
我可以通过Azure防火墙过滤Azure Databricks控制平面SCC中继Ip流量吗?
是的,您可以,但我们希望您记住以下几点:
- Azure Databricks集群(数据平面)和SCC中继服务之间的流量保持在Azure网络上,不在公共互联网上流动。这主要是管理流量,以确保Azure Databricks工作区正常运行。
- SCC中继服务和数据平面需要有稳定可靠的网络通信,它们之间有防火墙或虚拟设备会引入单点故障,例如在任何防火墙规则配置错误或计划停机的情况下,这可能会导致集群引导过度延迟(瞬时防火墙问题),或者无法创建新的集群或影响调度和运行作业。
我可以分析Azure防火墙接受或阻止的流量吗?
我们建议使用Azure防火墙日志和指标来满足这一要求。
我可以将现有的非NPIP(managed Databricks deployment)升级到NPIP或启用PL的工作区吗?
否,托管数据块部署无法升级到Vnet注入工作区。Rancher建议创建新的Vnet注入工作区并迁移工作区工件。
使用Azure Databricks开始数据过滤保护
我们讨论了利用云原生安全控制为您的Azure Databricks部署实施数据泄露保护,所有这些都可以自动化,以实现大规模的数据团队。作为此项目的一部分,您可能需要考虑和实施的其他一些事情:
- 启用元控件以释放数据湖的真正潜力
- 管理对笔记本功能的访问
- 使用诊断日志、存储访问日志和NSG流日志审核所有内容(需要VNET注入)
- 登录 发表评论
- 56 次浏览
最新内容
- 4 days ago
- 1 week 4 days ago
- 2 weeks 1 day ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago