
我们通过GoldenGate技术在Oracle DB和Kafka代理之间创建集成,该技术实时发布Kafka中的CDC事件流。
Oracle在其Oracle GoldenGate for Big Data套件中提供了一个Kafka连接处理程序,用于将CDC(更改数据捕获)事件流推送到Apache Kafka集群。
因此,对于给定的Oracle数据库,成功完成的业务事务中的任何DML操作(插入、更新、删除)都将转换为实时发布的Kafka消息。
这种集成对于这类用例非常有趣和有用:
- 如果遗留的单片应用程序使用Oracle数据库作为单一数据源,那么应该可以通过监视相关表的更改来创建实时更新事件流。换句话说,我们可以实现来自遗留应用程序的数据管道,而无需更改它们。
- 我们需要承认只有在数据库事务成功完成时才会发布Kafka消息。为了赋予这个特性,我们可以(始终以事务的方式)在一个由GoldenGate特别监视的表中编写Kafka消息,通过它的Kafka连接处理程序,将发布一个“插入”事件来存储原始的Kafka消息。
在本文中,我们将逐步说明如何通过GoldenGate技术实现PoC(概念验证)来测试Oracle数据库与Kafka之间的集成。
PoC的先决条件
我们将安装所有的东西在一个本地虚拟机,所以你需要:
- 安装Oracle VirtualBox(我在Oracle VirtualBox 5.2.20上测试过)
- 16 gb的RAM。
- 大约75GB的磁盘空间空闲。
- 最后但并非最不重要的是:了解vi。
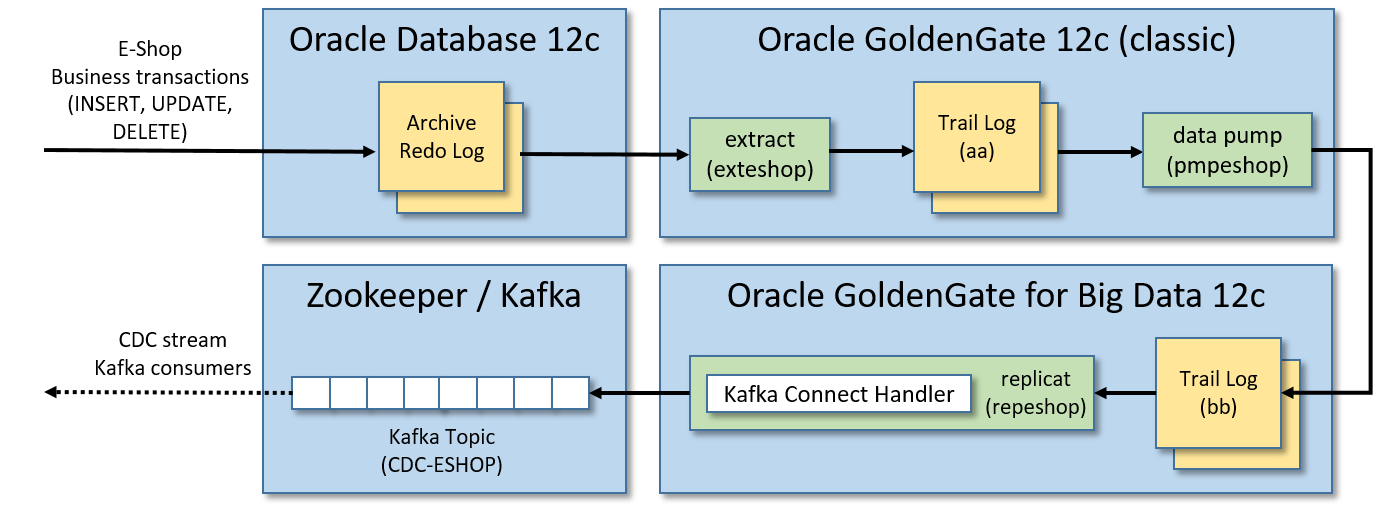
PoC架构
本指南将创建一个单一的虚拟机有:
- Oracle数据库12c:要监视的表存储在其中。
- Oracle GoldenGate 12c(经典版本):将应用于监视表的业务事务实时提取,以中间日志格式(trail log)存储,并将其输送到另一个GoldenGate(用于大数据)实例管理的远程日志。
- Oracle GoldenGate for Big Data 12c:pumped的业务事务并将其复制到Kafka消息中。
- Apache Zookeeper/Apache Kafka实例:在这里发布Kafka消息中转换的业务事务。
换句话说,在某些Oracle表上应用的任何插入、更新和删除操作都将生成Kafka消息的CDC事件流,该事件流将在单个Kafka主题中发布。
下面是我们将要创建的架构和实时数据流:
步骤1/12:启动Oracle数据库
您可以自由地安装Oracle数据库和Oracle GoldenGate手动。但幸运的是……)Oracle共享了一些虚拟机,这些虚拟机已经安装了所有的东西,可以随时进行开发。
Oracle虚拟机可以在这里下载,你需要一个免费的Oracle帐户来获得它们。
我使用了Oracle Big Data Lite虚拟机(ver)。4.11),它包含了很多Oracle产品,包括:
- Oracle数据库12c第一版企业版(12.1.0.2)
- Oracle GoldenGate 12c (12.3.0.1.2)
从上述下载页面获取所有7-zip文件(约22GB),提取VM映像文件BigDataLite411。在Oracle VirtualBox中双击文件,打开导入向导。完成导入过程后,一个名为BigDataLite-4.11的VM将可用。
启动BigDataLite-4.11并使用以下凭证登录:
- 用户:oracle
- 密码:welcome1
一个舒适的Linux桌面环境将会出现。
双击桌面上的“开始/停止服务”图标,然后:
- 检查第一项ORCL (Oracle数据库12c)。
- 不要检查所有其他的东西(对PoC无用且有害)。
- 按回车确认选择。
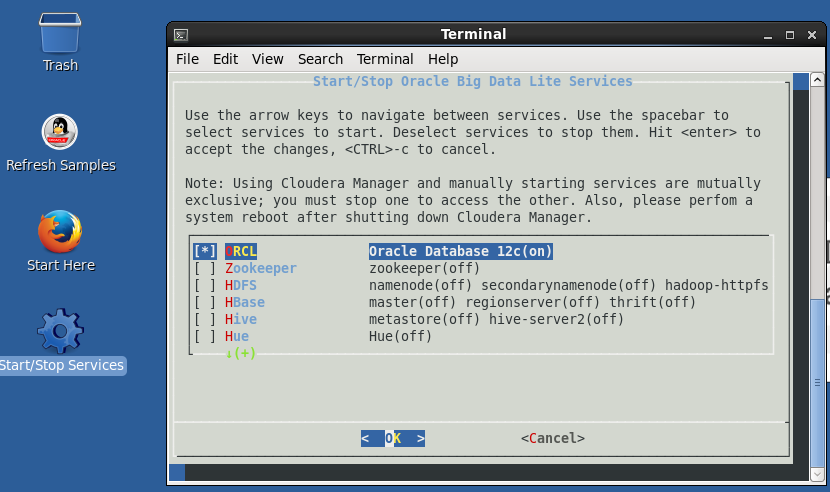
最后,Oracle数据库将启动。
当您重新启动虚拟机时,Oracle数据库将自动启动。
与下载的虚拟机有关的其他有用信息:
- Oracle主文件夹($ORACLE_HOME)是/u01/app/ Oracle /product/12.1.0.2/dbhome_1
- GoldenGate (classic)安装在/u01/ogg中
- SQL Developer安装在/u01/sqldeveloper中。您可以从上面工具栏中的图标启动SQL Developer。
- Oracle数据库是作为多租户容器数据库(CDB)安装的。
- Oracle数据库监听端口是1521
- 根容器的Oracle SID是cdb
- PDB(可插拔数据库)的Oracle SID是orcl
- 所有Oracle数据库用户(SYS、SYSTEM等)的密码都是welcome1
- 连接到PDB数据库的tnsname别名是ORCL(参见$ORACLE_HOME/network/admin/tnsnames)。ora文件内容)。
- Java主文件夹($JAVA_HOME)是/usr/java/latest
- $JAVA_HOME中安装的Java开发工具包是JDK8更新151。
步骤2/12:在Oracle中启用归档日志
我们需要在Oracle中启用归档日志来使用GoldenGate (classic)。
从VM的Linux shell中启动SQL Plus作为SYS:
sqlplus sys/welcome1 as sysdba
然后从SQL + shell运行这个命令列表(我建议一次启动一个):
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;ALTER DATABASE FORCE LOGGING;ALTER SYSTEM SWITCH LOGFILE;ALTER SYSTEM SET ENABLE_GOLDENGATE_REPLICATION=TRUE;SHUTDOWN IMMEDIATE;STARTUP MOUNT;ALTER DATABASE ARCHIVELOG;ALTER DATABASE OPEN;
然后检查存档日志是否成功启用:
ARCHIVE LOG LIST;
输出应该是这样的:
Database log mode Archive ModeAutomatic archival EnabledArchive destination USE_DB_RECOVERY_FILE_DESTOldest online log sequence 527Next log sequence to archive 529Current log sequence 529
步骤3/12:创建一个ggadmin用户
需要为GoldenGate (classic)创建一个特殊的Oracle管理员用户。
同样,从VM的Linux shell中打开SQL Plus:
sqlplus sys/welcome1作为sysdba
并通过运行这个脚本创建ggadmin用户:
ALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;CREATE USER ggadmin IDENTIFIED BY ggadmin;GRANT CREATE SESSION, CONNECT, RESOURCE, ALTER SYSTEM TO ggadmin;EXEC DBMS_GOLDENGATE_AUTH.GRANT_ADMIN_PRIVILEGE(grantee=>'ggadmin', privilege_type=>'CAPTURE', grant_optional_privileges=>'*');GRANT SELECT ANY DICTIONARY TO ggadmin;GRANT UNLIMITED TABLESPACE TO ggadmin;
步骤4/12 -创建ESHOP模式
我们将创建一个模式(ESHOP),其中只有两个表(CUSTOMER_ORDER和CUSTOMER_ORDER_ITEM),用于生成要推送到Kafka中的CDC事件流。
使用SQL Plus(或者,如果您愿意,也可以使用SQL Developer)连接orcl作为SID的Oracle PDB:
sqlplus sys/welcome1@ORCL as sysdba
运行这个脚本:
-- init sessionALTER SESSION SET "_ORACLE_SCRIPT"=TRUE;-- create tablespace for eshopCREATE TABLESPACE eshop_tbs DATAFILE 'eshop_tbs.dat' SIZE 10M AUTOEXTEND ON;CREATE TEMPORARY TABLESPACE eshop_tbs_temp TEMPFILE 'eshop_tbs_temp.dat' SIZE 5M AUTOEXTEND ON;-- create user schema eshop, please note that the password is eshopCREATE USER ESHOP IDENTIFIED BY eshop DEFAULT TABLESPACE eshop_tbs TEMPORARY TABLESPACE eshop_tbs_temp;-- grant eshop user permissionsGRANT CREATE SESSION TO ESHOP;GRANT CREATE TABLE TO ESHOP;GRANT UNLIMITED TABLESPACE TO ESHOP;GRANT RESOURCE TO ESHOP;GRANT CONNECT TO ESHOP;GRANT CREATE VIEW TO ESHOP;-- create eshop sequencesCREATE SEQUENCE ESHOP.CUSTOMER_ORDER_SEQ START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE;CREATE SEQUENCE ESHOP.CUSTOMER_ORDER_ITEM_SEQ START WITH 1 INCREMENT BY 1 NOCACHE NOCYCLE;-- create eshop tablesCREATE TABLE ESHOP.CUSTOMER_ORDER (ID NUMBER(19) PRIMARY KEY,CODE VARCHAR2(10),CREATED DATE,STATUS VARCHAR2(32),UPDATE_TIME TIMESTAMP);CREATE TABLE ESHOP.CUSTOMER_ORDER_ITEM (ID NUMBER(19) PRIMARY KEY,ID_CUSTOMER_ORDER NUMBER(19),DESCRIPTION VARCHAR2(255),QUANTITY NUMBER(3),CONSTRAINT FK_CUSTOMER_ORDER FOREIGN KEY (ID_CUSTOMER_ORDER) REFERENCES ESHOP.CUSTOMER_ORDER (ID));
步骤5/12:初始化GoldenGate Classic
现在是时候在BigDataListe-4.11虚拟机中安装GoldenGate (classic)实例了。
从Linux shell运行:
cd /u01/ogg./ggsci
GoldenGate CLI(命令行界面)将启动:
Oracle GoldenGate Command Interpreter for OracleVersion 12.2.0.1.0 OGGCORE_12.2.0.1.0_PLATFORMS_151101.1925.2_FBOLinux, x64, 64bit (optimized), Oracle 12c on Nov 11 2015 03:53:23Operating system character set identified as UTF-8.Copyright (C) 1995, 2015, Oracle and/or its affiliates. All rights reserved.GGSCI (bigdatalite.localdomain) 1>
从GoldenGate CLI启动经理与以下命令:
start mgr
它将引导GoldenGate的主控制器进程(监听端口7810)。
现在创建一个凭据库来存储ggadmin用户凭据(并使用具有相同名称的别名来引用它们):
add credentialstorealter credentialstore add user ggadmin password ggadmin alias ggadmin
现在,通过使用刚才创建的ggadmin别名连接到Oracle数据库,并启用对存储在名为orcl的PDB中的eshop模式的附加日志:
dblogin useridalias ggadminadd schematrandata orcl.eshop
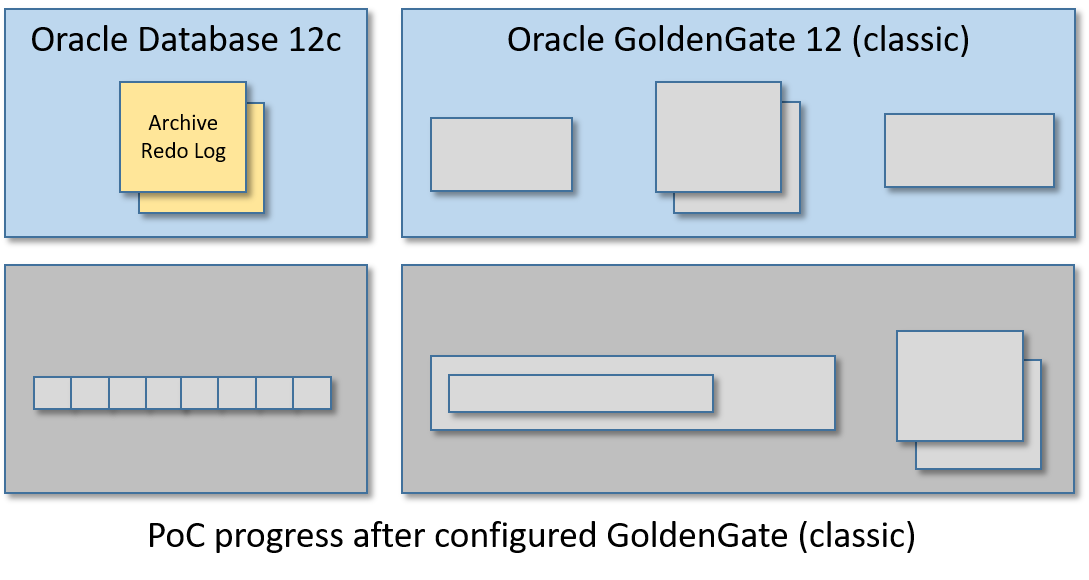
步骤6/12:制作金门果提取物
在此步骤中,我们将创建一个GoldenGate摘要,此过程将监视Oracle archive重做日志,以捕获与ESHOP表相关的数据库事务,并将此SQL修改流写入另一个名为trail log的日志文件中。
从GoldenGate CLI运行:
edit params exteshop
该命令将打开一个引用新空文件的vi实例。在vi编辑器中放入以下内容:
EXTRACT exteshopUSERIDALIAS ggadminEXTTRAIL ./dirdat/aaTABLE orcl.eshop.*;
保存内容并退出vi,以便返回GoldenGate CLI。
保存的内容将存储在/u01/ogg/dirprm/exteshop中。人口、难民和移民事务局文件。您也可以在外部编辑它的内容,而不需要再次从GoldenGate CLI运行“edit params exteshop”命令。
现在在Oracle中注册提取过程,从GoldenGate CLI运行以下命令:
dblogin useridalias ggadminregister extract exteshop database container (orcl)
最后一个命令的输出应该是这样的:
OGG-02003 Extract EXTESHOP successfully registered with database at SCN 13624423.
使用所示的SCN号来完成提取配置。从GoldenGate CLI:
add extract exteshop, integrated tranlog, scn 13624423add exttrail ./dirdat/aa, extract exteshop
现在我们可以启动名为exteshop的GoldenGate提取过程:
start exteshop
你可以使用以下命令中的on来检查进程的状态:
info exteshopview report exteshop
验证提取过程是否正常工作以完成此步骤。从Linux shell运行以下命令,用SQL Plus(或SQL Developer)连接到ESHOP模式:
sqlplus eshop / eshop@ORCL
创建一个模拟客户订单:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA01', SYSDATE, 'DRAFT', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Toy Story', 1);COMMIT;
最后,从GoldenGate CLI跑出来:
stats exteshop
并验证前面的插入操作是否已计算在内。下面是stats命令输出的一个小示例:
Extracting from ORCL.ESHOP.CUSTOMER_ORDER to ORCL.ESHOP.CUSTOMER_ORDER:*** Total statistics since 2019-05-29 09:18:12 ***Total inserts 1.00Total updates 0.00Total deletes 0.00Total discards 0.00Total operations 1.00
检查提取过程是否正常工作的另一种方法是检查GoldenGate跟踪日志文件的时间戳。在Linux shell中运行“ls -l /u01/ogg/dirdat/”,并验证以“aa”开头的文件的时间戳已经更改。
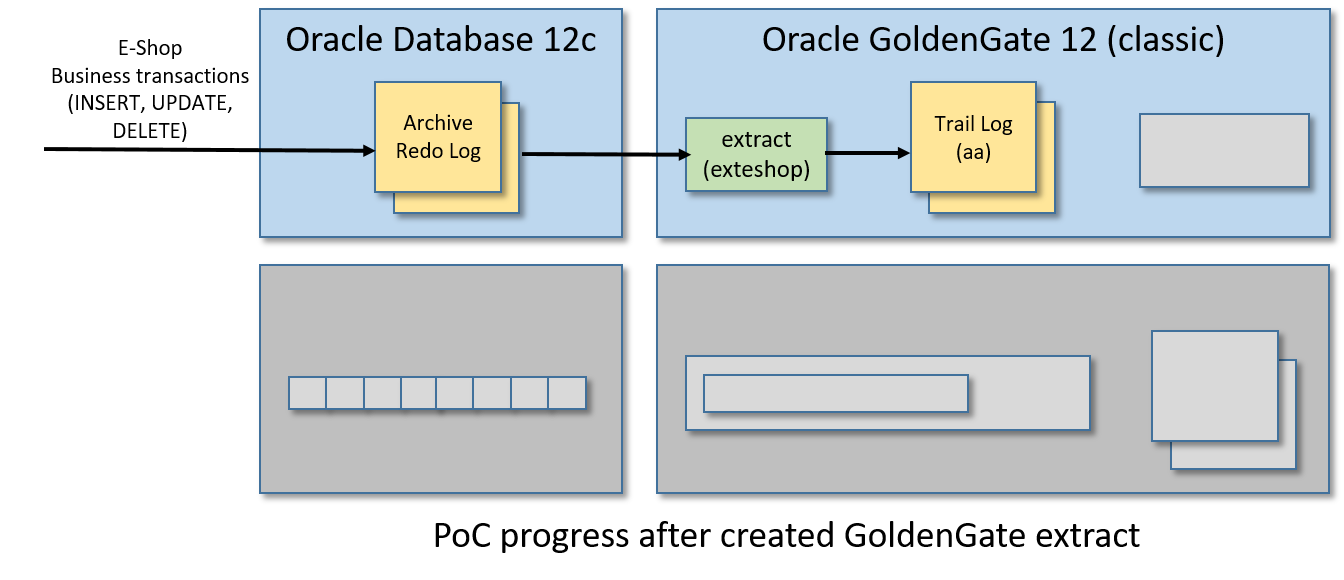
步骤7/12:安装并运行Apache Kafka
从VM的桌面环境中打开Firefox并下载Apache Kafka(我使用的是kafka_2.11-2.1.1.tgz)。
现在,打开一个Linux shell并重置CLASSPATH环境变量(在BigDataLite-4.11虚拟机中设置的当前值会在Kafka中产生冲突):
declare -x CLASSPATH=""
从同一个Linux shell中,解压缩压缩包,启动ZooKeeper和Kafka:
cdtar zxvf Downloads/kafka_2.11-2.1.1.tgzcd kafka_2.11-2.1.1./bin/zookeeper-server-start.sh -daemon config/zookeeper.properties./bin/kafka-server-start.sh -daemon config/server.properties
你可以通过启动“echo stats | nc localhost 2181”来检查ZooKeeper是否正常:
[oracle@bigdatalite ~]$ echo stats | nc localhost 2181Zookeeper version: 3.4.5-cdh5.13.1--1, built on 11/09/2017 16:28 GMTClients:/127.0.0.1:34997[1](queued=0,recved=7663,sent=7664)/0:0:0:0:0:0:0:1:17701[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/25Received: 8186Sent: 8194Connections: 2Outstanding: 0Zxid: 0x3fMode: standaloneNode count: 25
您可以检查Kafka是否与“echo dump | nc localhost 2181 | grep代理”(一个字符串/brokers/ids/0应该出现)
[oracle@bigdatalite ~]$ echo dump | nc localhost 2181 | grep brokers/brokers/ids/0
用于PoC的BigDataLite-4.11虚拟机已经在启动虚拟机时启动了一个较老的ZooKeeper实例。因此,请确保禁用了步骤1中描述的所有服务。
此外,当您打开一个新的Linux shell时,请注意在启动ZooKeeper和Kafka之前总是要重置CLASSPATH环境变量,这一点在步骤开始时已经解释过了。
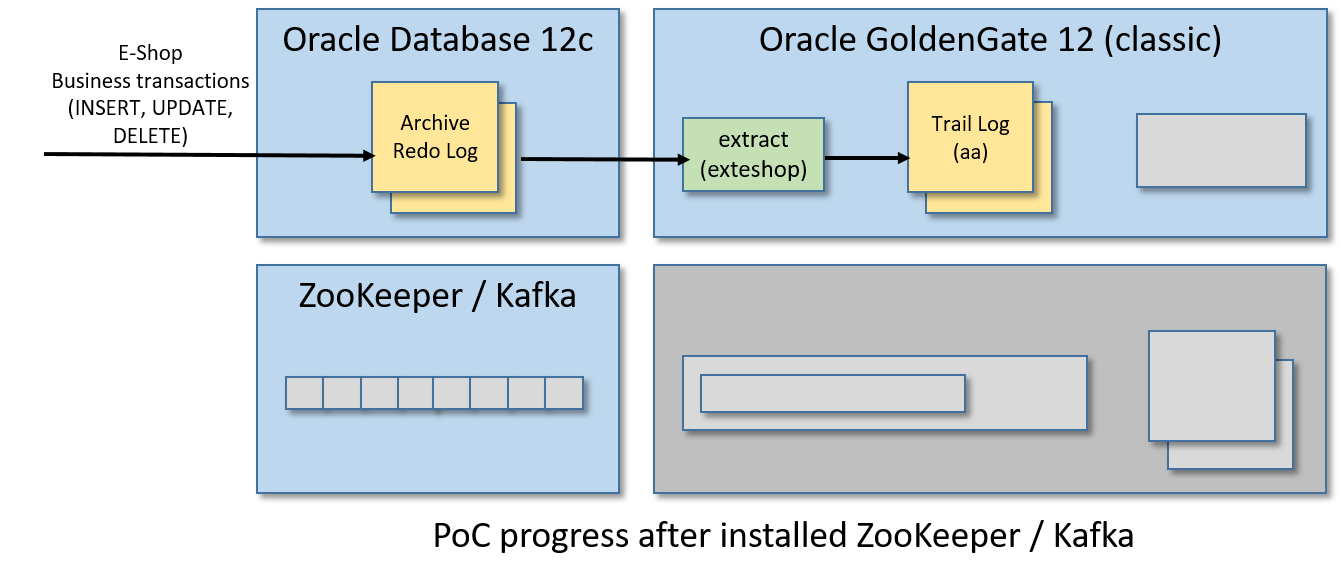
步骤8/12:为大数据安装GoldenGate
同样,从这个页面下载Oracle GoldenGate for Big Data 12c只需要使用VM中安装的Firefox浏览器(我在Linux x86-64上使用Oracle GoldenGate for Big Data 12.3.2.1.1)。请注意,您需要一个(免费)Oracle帐户来获得它。
安装很容易,只是爆炸压缩包内的下载:
cd ~/Downloadsunzip OGG_BigData_Linux_x64_12.3.2.1.1.zipcd ..mkdir ogg-bd-poccd ogg-bd-poctar xvf ../Downloads/OGG_BigData_Linux_x64_12.3.2.1.1.tar
就这样,GoldenGate for Big Data 12c被安装在/home/oracle/ogg-bd-poc文件夹中。
同样,BigDataLite-4.11虚拟机已经在/u01/ogg-bd文件夹中安装了用于大数据的GoldenGate。但它是一个较旧的版本,连接Kafka的选项较少。
步骤9/12:启动GoldenGate for Big Data Manager
打开大数据大门
cd ~/ogg-bd-poc./ggsci
需要更改管理器端口,否则之前启动的与GoldenGate (classic)管理器的冲突将被引发。
因此,从大数据的GoldenGate来看,CLI运行:
create subdirsedit params mgr
一个vi实例将开始,只是写这个内容:
PORT 27801
然后保存内容,退出vi,返回CLI,我们终于可以启动GoldenGate for Big Data manager监听端口27081:
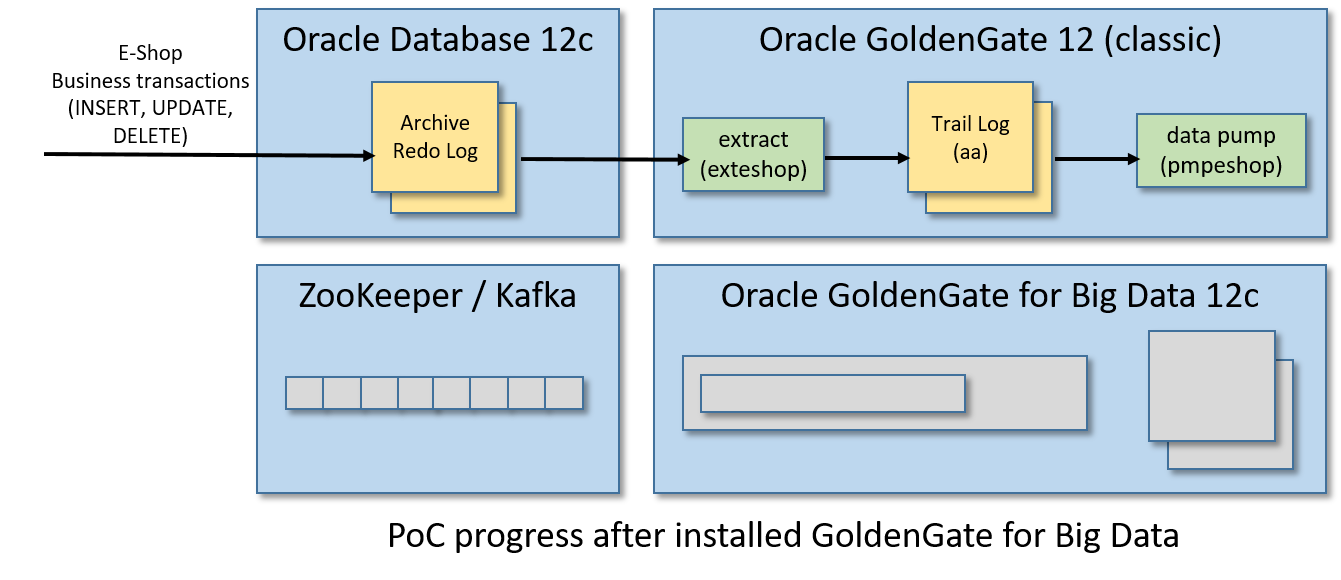
步骤10/12:创建数据泵(Data Pump)
现在,我们需要创建在GoldenGate世界中被称为数据泵的东西。数据泵是一个提取过程,它监视一个跟踪日志,并(实时地)将任何更改推到另一个由不同的(通常是远程的)GoldenGate实例管理的跟踪日志。
对于这个PoC,由GoldenGate (classic)管理的trail log aa将被泵送至GoldenGate管理的trail log bb进行大数据处理。
因此,如果您关闭它,请回到来自Linux shell的GoldenGate(经典)CLI:
cd /u01/ogg./ggsci
来自GoldenGate(经典)CLI:
edit params pmpeshop
并在vi中加入以下内容:
EXTRACT pmpeshopUSERIDALIAS ggadminSETENV (ORACLE_SID='orcl')-- GoldenGate for Big Data address/port:RMTHOST localhost, MGRPORT 27801RMTTRAIL ./dirdat/bbPASSTHRU-- The "tokens" part it is useful for writing in the Kafka messages-- the Transaction ID and the database Change Serial NumberTABLE orcl.eshop.*, tokens(txid = @GETENV('TRANSACTION', 'XID'), csn = @GETENV('TRANSACTION', 'CSN'));
保存内容并退出vi。
正如已经解释的提取器,保存的内容将存储在/u01/ogg/dirprm/pmpeshop中。人口、难民和移民事务局文件。
现在我们要注册并启动数据泵,从GoldenGate CLI:
dblogin useridalias ggadminadd extract pmpeshop, exttrailsource ./dirdat/aa begin nowadd rmttrail ./dirdat/bb extract pmpeshopstart pmpeshop
通过从CLI运行以下命令之一来检查数据泵的状态:
info pmpeshopview report pmpeshop
你甚至可以在金门大数据的dirdat文件夹中查看trail log bb是否已经创建:
[oracle@bigdatalite dirdat]$ ls -l ~/ogg-bd-poc/dirdattotal 0-rw-r-----. 1 oracle oinstall 0 May 30 13:22 bb000000000[oracle@bigdatalite dirdat]$
那检查泵送过程呢?来自Linux shell:
sqlplus eshop/eshop@ORCL
执行这个SQL脚本创建一个新的模拟客户订单:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA02', SYSDATE, 'SHIPPING', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Inside Out', 1);COMMIT;
现在从GoldenGate(经典)CLI运行:
stats pmpeshop
用于检查插入操作是否正确计数(在输出的一部分下面):
GGSCI (bigdatalite.localdomain as ggadmin@cdb/CDB$ROOT) 11> stats pmpeshopSending STATS request to EXTRACT PMPESHOP ...Start of Statistics at 2019-05-30 14:49:00.Output to ./dirdat/bb:Extracting from ORCL.ESHOP.CUSTOMER_ORDER to ORCL.ESHOP.CUSTOMER_ORDER:*** Total statistics since 2019-05-30 14:01:56 ***Total inserts 1.00Total updates 0.00Total deletes 0.00Total discards 0.00Total operations 1.00
此外,您还可以验证GoldenGate中存储的用于测试泵过程的大数据的跟踪日志的时间戳。事务提交后,从Linux shell运行:“ln -l ~/og -bd-poc/dirdat”,并检查最后一个以“bb”作为前缀的文件的时间戳。
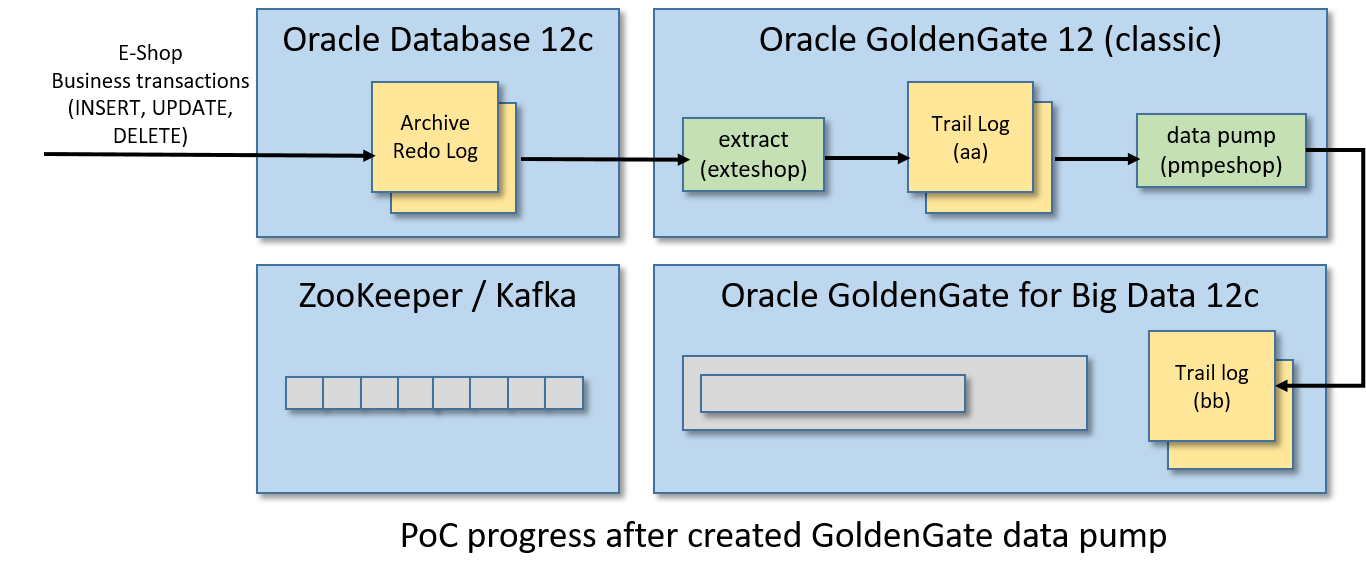
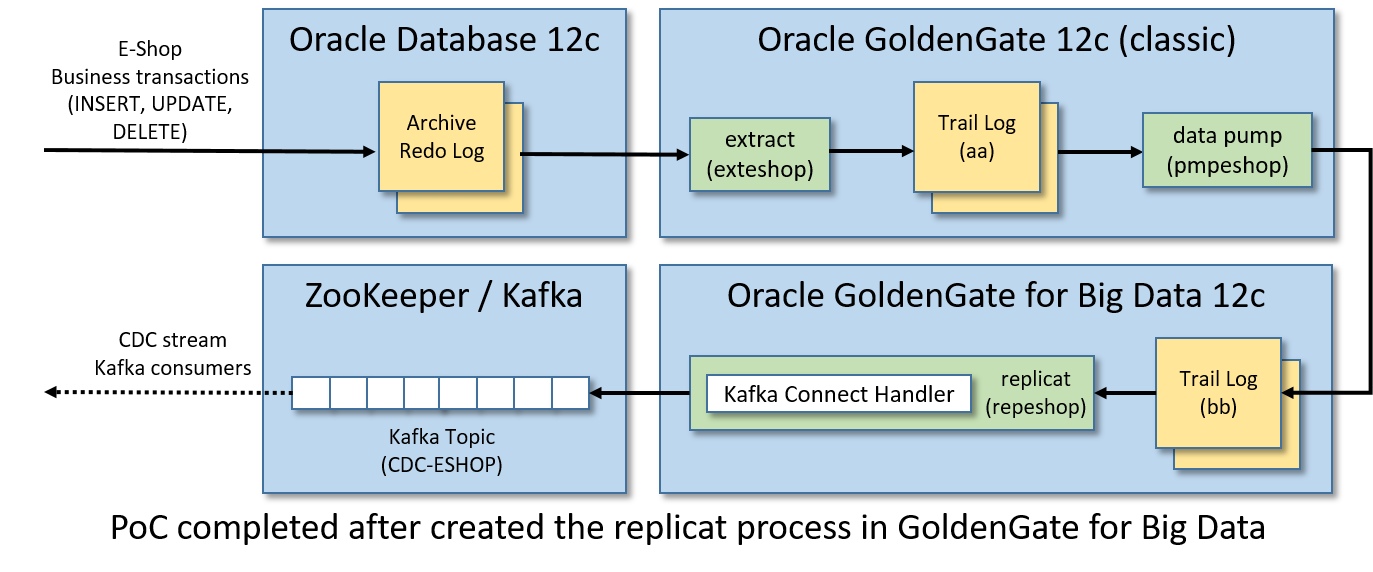
步骤11/12:将事务发布到Kafka
最后,我们将在GoldenGate中为BigData创建一个副本流程,以便在Kafka主题中发布泵出的业务事务。replicat将从trail日志bb读取事务中的插入、更新和删除操作,并将它们转换为JSON编码的Kafka消息。
因此,创建一个名为eshop_kafkaconnect的文件。文件夹/home/oracle/ogg-bd- pocd /dirprm中的属性包含以下内容:
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kafkaconnect.properties# -----------------------------------------------------------# address/port of the Kafka brokerbootstrap.servers=localhost:9092acks=1#JSON Converter Settingskey.converter=org.apache.kafka.connect.json.JsonConverterkey.converter.schemas.enable=falsevalue.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable=false#Adjust for performancebuffer.memory=33554432batch.size=16384linger.ms=0# This property fix a start-up error as explained by Oracle Support here:# https://support.oracle.com/knowledge/Middleware/2455697_1.htmlconverter.type=key
在同一个文件夹中,创建一个名为eshop_kc的文件。具有以下内容的道具:
# File: /home/oracle/ogg-bd-poc/dirprm/eshop_kc.props# ---------------------------------------------------gg.handlerlist=kafkaconnect#The handler propertiesgg.handler.kafkaconnect.type=kafkaconnectgg.handler.kafkaconnect.kafkaProducerConfigFile=eshop_kafkaconnect.propertiesgg.handler.kafkaconnect.mode=tx#The following selects the topic name based only on the schema namegg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}#The following selects the message key using the concatenated primary keysgg.handler.kafkaconnect.keyMappingTemplate=${primaryKeys}#The formatter propertiesgg.handler.kafkaconnect.messageFormatting=opgg.handler.kafkaconnect.insertOpKey=Igg.handler.kafkaconnect.updateOpKey=Ugg.handler.kafkaconnect.deleteOpKey=Dgg.handler.kafkaconnect.truncateOpKey=Tgg.handler.kafkaconnect.treatAllColumnsAsStrings=falsegg.handler.kafkaconnect.iso8601Format=falsegg.handler.kafkaconnect.pkUpdateHandling=abendgg.handler.kafkaconnect.includeTableName=truegg.handler.kafkaconnect.includeOpType=truegg.handler.kafkaconnect.includeOpTimestamp=truegg.handler.kafkaconnect.includeCurrentTimestamp=truegg.handler.kafkaconnect.includePosition=truegg.handler.kafkaconnect.includePrimaryKeys=truegg.handler.kafkaconnect.includeTokens=truegoldengate.userexit.writers=javawriterjavawriter.stats.display=TRUEjavawriter.stats.full=TRUEgg.log=log4jgg.log.level=INFOgg.report.time=30sec# Apache Kafka Classpath# Put the path of the "libs" folder inside the Kafka home pathgg.classpath=/home/oracle/kafka_2.11-2.1.1/libs/*javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=.:ggjava/ggjava.jar:./dirprm
如果关闭,重启大数据CLI的GoldenGate:
cd ~/ogg-bd-poc./ggsci
and start to create a replicat from the CLI with:
edit params repeshop
in vi put this content:
REPLICAT repeshopTARGETDB LIBFILE libggjava.so SET property=dirprm/eshop_kc.propsGROUPTRANSOPS 1000MAP orcl.eshop.*, TARGET orcl.eshop.*;
然后保存内容并退出vi。现在将replicat与trail log bb关联,并使用以下命令启动replicat进程,以便从GoldenGate启动大数据CLI:
add replicat repeshop, exttrail ./dirdat/bbstart repeshop
Check that the replicat is live and kicking with one of these commands:
info repeshopview report repeshop
Now, connect to the ESHOP schema from another Linux shell:
sqlplus eshop/eshop@ORCL
and commit something:
INSERT INTO CUSTOMER_ORDER (ID, CODE, CREATED, STATUS, UPDATE_TIME)VALUES (CUSTOMER_ORDER_SEQ.NEXTVAL, 'AAAA03', SYSDATE, 'DELIVERED', SYSTIMESTAMP);INSERT INTO CUSTOMER_ORDER_ITEM (ID, ID_CUSTOMER_ORDER, DESCRIPTION, QUANTITY)VALUES (CUSTOMER_ORDER_ITEM_SEQ.NEXTVAL, CUSTOMER_ORDER_SEQ.CURRVAL, 'Cars 3', 2);COMMIT;
From the GoldenGate for Big Data CLI, check that the INSERT operation was counted for the replicat process by running:
stats repeshop
And (hurrah!) we can have a look inside Kafka, as the Linux shell checks that the topic named CDC-ESHOP was created:
cd ~/kafka_2.11-2.1.1/bin./kafka-topics.sh --list --zookeeper localhost:2181
and from the same folder run the following command for showing the CDC events stored in the topic:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning
You should see something like:
[oracle@bigdatalite kafka_2.11-2.1.1]$ ./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning{"table":"ORCL.ESHOP.CUSTOMER_ORDER","op_type":"I","op_ts":"2019-05-31 04:24:34.000327","current_ts":"2019-05-31 04:24:39.637000","pos":"00000000020000003830","primary_keys":["ID"],"tokens":{"txid":"9.32.6726","csn":"13906131"},"before":null,"after":{"ID":11.0,"CODE":"AAAA03","CREATED":"2019-05-31 04:24:34","STATUS":"DELIVERED","UPDATE_TIME":"2019-05-31 04:24:34.929950000"}}{"table":"ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type":"I","op_ts":"2019-05-31 04:24:34.000327","current_ts":"2019-05-31 04:24:39.650000","pos":"00000000020000004074","primary_keys":["ID"],"tokens":{"txid":"9.32.6726","csn":"13906131"},"before":null,"after":{"ID":11.0,"ID_CUSTOMER_ORDER":11.0,"DESCRIPTION":"Cars 3","QUANTITY":2}}
For a better output, install jq:
sudo yum -y install jq./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic CDC-ESHOP --from-beginning | jq .
and here is how will appear the JSON events:
{"table": "ORCL.ESHOP.CUSTOMER_ORDER","op_type": "I","op_ts": "2019-05-31 04:24:34.000327","current_ts": "2019-05-31 04:24:39.637000","pos": "00000000020000003830","primary_keys": ["ID"],"tokens": {"txid": "9.32.6726","csn": "13906131"},"before": null,"after": {"ID": 11,"CODE": "AAAA03","CREATED": "2019-05-31 04:24:34","STATUS": "DELIVERED","UPDATE_TIME": "2019-05-31 04:24:34.929950000"}}{"table": "ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type": "I","op_ts": "2019-05-31 04:24:34.000327","current_ts": "2019-05-31 04:24:39.650000","pos": "00000000020000004074","primary_keys": ["ID"],"tokens": {"txid": "9.32.6726","csn": "13906131"},"before": null,"after": {"ID": 11,"ID_CUSTOMER_ORDER": 11,"DESCRIPTION": "Cars 3","QUANTITY": 2}}
现在打开Kafka -console-consumer.sh进程,并在ESHOP上执行其他一些数据库事务,以便实时打印发送给Kafka的CDC事件流。
以下是一些用于更新和删除操作的JSON事件示例:
// Generated with: UPDATE CUSTOMER_ORDER SET STATUS='DELIVERED' WHERE ID=8;{"table": "ORCL.ESHOP.CUSTOMER_ORDER","op_type": "U","op_ts": "2019-05-31 06:22:07.000245","current_ts": "2019-05-31 06:22:11.233000","pos": "00000000020000004234","primary_keys": ["ID"],"tokens": {"txid": "14.6.2656","csn": "13913689"},"before": {"ID": 8,"CODE": null,"CREATED": null,"STATUS": "SHIPPING","UPDATE_TIME": null},"after": {"ID": 8,"CODE": null,"CREATED": null,"STATUS": "DELIVERED","UPDATE_TIME": null}}// Generated with: DELETE CUSTOMER_ORDER_ITEM WHERE ID=3;{"table": "ORCL.ESHOP.CUSTOMER_ORDER_ITEM","op_type": "D","op_ts": "2019-05-31 06:25:59.000916","current_ts": "2019-05-31 06:26:04.910000","pos": "00000000020000004432","primary_keys": ["ID"],"tokens": {"txid": "14.24.2651","csn": "13913846"},"before": {"ID": 3,"ID_CUSTOMER_ORDER": 1,"DESCRIPTION": "Toy Story","QUANTITY": 1},"after": null}
恭喜你!你完成了PoC:
步骤12/12:使用PoC
GoldenGate中提供的Kafka Connect处理程序有很多有用的选项,可以根据需要定制集成。点击这里查看官方文件。
例如,您可以选择为CDC流中涉及的每个表创建不同的主题,只需在eshop_kc.props中编辑此属性:
gg.handler.kafkaconnect.topicMappingTemplate=CDC-${schemaName}-${tableName}更改后重新启动replicat,从GoldenGate for Big Data CLI:
stop repeshopstart repeshop
您可以在“~/og -bd-poc/AdapterExamples/big-data/kafka_connect”文件夹中找到其他配置示例。
结论
在本文中,我们通过GoldenGate技术在Oracle数据库和Kafka代理之间创建了一个完整的集成。CDC事件流以Kafka实时发布。
为了简单起见,我们使用了一个已经全部安装的虚拟机,但是您可以在不同的主机上免费安装用于大数据的GoldenGate和Kafka。
请在评论中告诉我您对这种集成的潜力(或限制)的看法。
原文:https://dzone.com/articles/creates-a-cdc-stream-from-oracle-database-to-kafka
本文:https://pub.intelligentx.net/node/839
讨论:请加入知识星球【首席架构师圈】或者飞聊小组【首席架构师智库】
最新内容
- 5 days 11 hours ago
- 1 week 6 days ago
- 2 weeks 3 days ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago