

如果你来自RDBMS的世界,在Cassandra有效地开始建模实体之前,需要一些时间来适应。帮助我解决问题的经验法则是让您的查询定义您需要的实体。
最近,我将应用程序的持久层从Oracle迁移到Cassandra。虽然迁移一些主要实体相当简单,但它解决了一些用例,比如支持范围扫描,这给我们带来了一组独特的挑战。
注意:范围扫描/查询基本上是基于时间戳范围的记录查找,在它之上有或没有任何过滤器。
在进入实际问题之前,让我们先了解一下这个应用程序,我在这里提到的应用程序处理客户在我们的站点上执行的所有事务的所有通信。我们平均每天要通过电子邮件、短信和应用程序通知等各种渠道向客户发送数千万条信息。
问题是什么?
我们希望确保在迁移到Cassandra时支持实体上的范围查询,原因有两个:
- 当我们使用Oracle时,我们的团队已经在一些仪表板上使用了类似的读取,所以必须确保向后兼容性。
例如,在“Y”和“Z”时间之间,在“X”日期为一个特定事件发送了多少通信。
- 此外,它还可以帮助您为将来可能要执行的任何向下一代持久性解决方案的迁移提供证据。
对于这个文章的范围,让我们假设我们有一个列族定义如下:
create table if not exists my_keyspace.message_log ( id uuid, message_id text, event text, event_type text, machine_ip text, created_date date, created_date_timestamp timestamp, primary key ((message_id), id) );
现在,这可以帮助您基于message_id查询消息的详细信息,因为上面的实体是根据message_id分区的。
但是,如果希望查找在特定时间范围内着陆的消息,就会出现问题。为了支持这一点,我们将引入一个列族,如下所示:
create table if not exists my_keyspace.message_log_dated (
id uuid,
message_id text,
event text,
created_date date,
created_date_timestamp timestamp,
primary key ((created_date), event, created_date_timestamp, message_id, id)
);
现在,这允许我们执行像下面这样的查询,以获得跨时间范围的数据:
select message_id from my_keyspace.message_log where created_date='2019–12–04'
and event='order-confirmation'
and created_date_timestamp > 1575417601000
and created_date_timestamp < 1575547200000
虽然这可能适用于旨在服务一致和可预测流量的系统,但对于容易受到客户行为驱动的意外激增的系统来说,这样的模型可能是一个绝对的噩梦。
由于上述模型是在created_date列上分区的,因此在给定日期上任何意外的流量激增都将意味着您的所有写操作都被定向到同一个分区,并且很可能在Cassandra集群上创建了一个热点。就集群性能而言,这基本上意味着三件事:
- 您可能会冒集群中的某些节点的风险。
- 您可能永远无法成功读取此数据,因为查找有超时的风险。
- 这样就违反了保持集群处于健康状态的黄金法则,即不要让分区大小增长得太大。(建议将分区大小保持在100 MB左右,但没有确切的数字。)
我们做了什么?我们尝试引入一个叫做“一天之窗”(window of the day)的新因素,它只是一个时间插槽(统一),它将一天划分为相等的插槽,并将流量分散到多个分区,如下所示:
create table if not exists my_keyspace.message_log_slotted (
id uuid,
message_id text,
event text,
event_type text,
machine_ip text,
created_date date,
slot_id text,
created_date_timestamp timestamp,
primary key ((created_date, slot_id), event, created_date_timestamp, message_id, id)
);
现在,在某一天出现流量激增的情况下,我们仍然能够在写入数据的同时访问多个分区,并防止任何潜在的热点。
在本例中,读取一天的整个数据的查询是这样的(假设我们决定使用6小时的插槽)
select message_id from my_keyspace.message_log where created_date='2019–12–04'
and slot_id in ('slot_00_06', 'slot_06_12', 'slot_12_18', 'slot_18_24')
and created_date_timestamp > 1575417601000
and created_date_timestamp < 1575547200000-- please note this may need some app side filtering to narrow down results to certain events in the entity.
虽然这种方法确实解决了问题,但它只是部分地解决了问题。如果流量激增被限制在一个特定的插槽内,该模型仍然容易出现与第一个模型相同的问题。
您可以决定将插槽大小减少到更少的小时数甚至分钟数,但事实是您的模型仍然是易受影响的。
试图使这种方法适合我们的生产用例的绝望尝试,它将需要一个槽的大小约5分钟,确保即使在最大峰值(当前)我们能够阻止任何热点和能够直接交通尽快下一个分区,同时保持当前分区大小可接受范围。这就意味着我们需要在12 * 24 = 288个分区中查找一天的数据。
那么我们该怎么办呢?
我们决定后退一步,重新评估我们的计划,而不是粗暴地按所有数据Cassandra建模指南行事。我们的结论是,我们需要一种可靠的方式向每个分区发送受控的写操作,一旦达到限制(每个分区希望维护的最大存储空间),我们的应用程序应该能够将写操作重定向到一个新的分区。
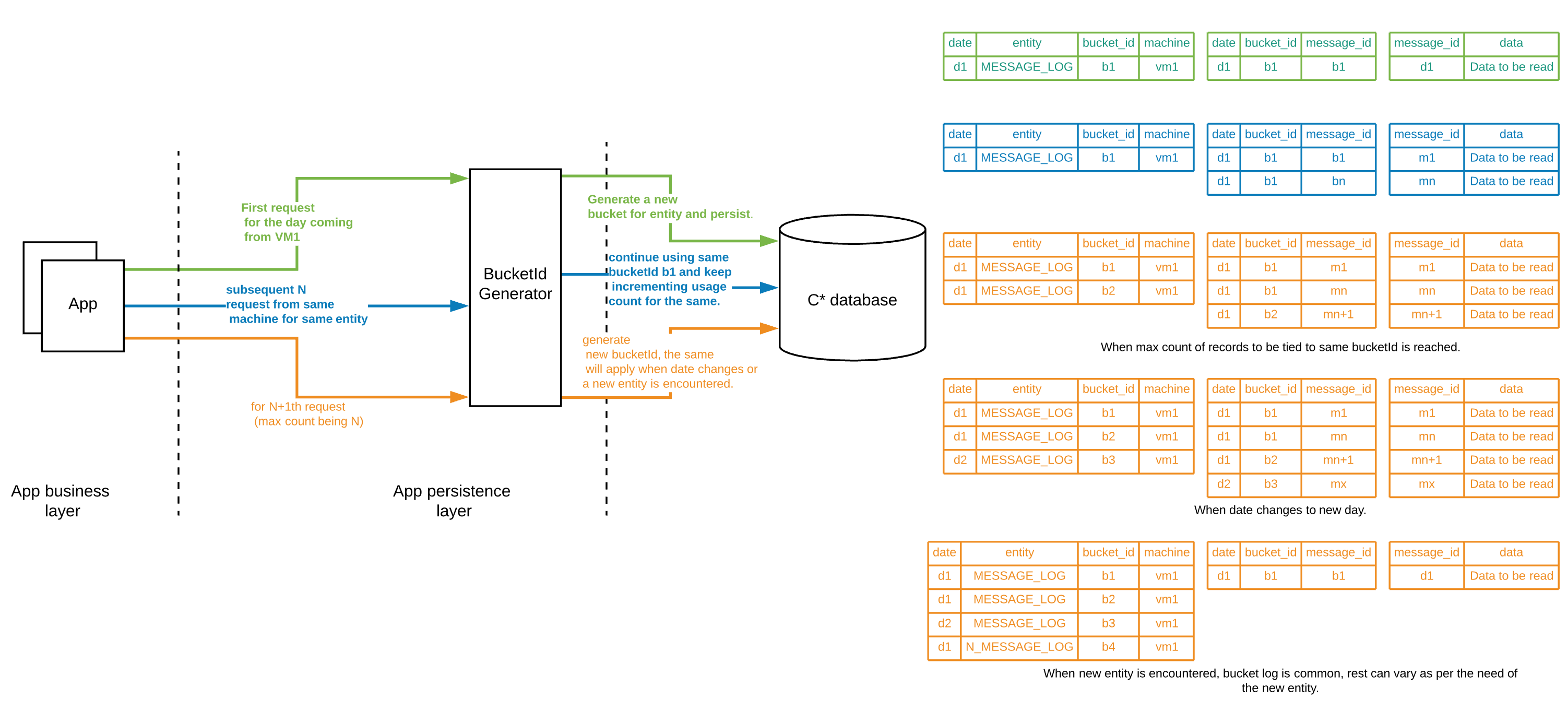
我们提出了一种bucketing策略,其中每个应用程序实例(VMs/computes)为它持久保存的记录维护它自己的内存计数器,并为所有这些写操作分配一个专用的bucket_id。每次进入流动状态时,应用程序都会生成一个新的随机唯一id:
- 日期已经改变了。
- 一个新的实体已经被引入。
- 桶已达到其最大计数。(这意味着在这个特定分区中保存了足够多的记录,需要将写操作移动到一个新的分区。)
这还需要我们维护一个字典,以维护由所有应用程序实例生成的所有bucket_ids到它们为之创建的日期和实体的映射。我们可以将其持久化到同一个Cassandra密钥空间中。
在本例中,实体(message_log_date)中支持范围扫描的行如下所示
| created_date | bucket_id | event | app_instance | created_ts | message_id | |
|---|---|---|---|---|---|---|
| d1 | random_unique_id1 | order-confirmation | vm1 | ts1 | m1 | |
| d1 | random_unique_id1 | ship-confirmation | vm1 | ts2 | m2 | |
| d1 | random_unique_id2 | ship-confirmation | vm2 | ts3 | m3 | |
| d1 | random_unique_id3 | order-confirmation | vm3 | ts4 | m4 | |
| d1 | random_unique_id1 | delivery-confirmation | vm1 | ts5 | m5 |
而用于维护日期和实体到该范围各自存储段之间的映射的字典将是这样的。
| created_date | entity_name | created_ts | app_instance | bucket_id | |
|---|---|---|---|---|---|
| d1 | message_log | ts1 | vm1 | random_unique_id1 | |
| d1 | message_log | ts2 | vm2 | random_unique_id2 | |
| d1 | success_log | ts3 | vm1 | random_unique_id3 | |
| d1 | failure_log | ts4 | vm1 | random_unique_id4 |
现在,当你的bucket在某一天溢出时,你可能会看到下面这样的条目(注意,同一时间内为同一VM创建的第7行):
| created_date | bucket_id | event | app_instance | created_ts | message_id | |
|---|---|---|---|---|---|---|
| d1 | random_unique_id1 | order-confirmation | vm1 | ts1 | m1 | |
| d1 | random_unique_id1 | ship-confirmation | vm1 | ts2 | m2 | |
| d1 | random_unique_id2 | ship-confirmation | vm2 | ts3 | m3 | |
| d1 | random_unique_id3 | order-confirmation | vm3 | ts4 | m4 | |
| d1 | random_unique_id1 | delivery-confirmation | vm1 | ts5 | m5 | |
| d1 | random_unique_id4 | delivery-confirmation | vm1 | ts6 | m1 |
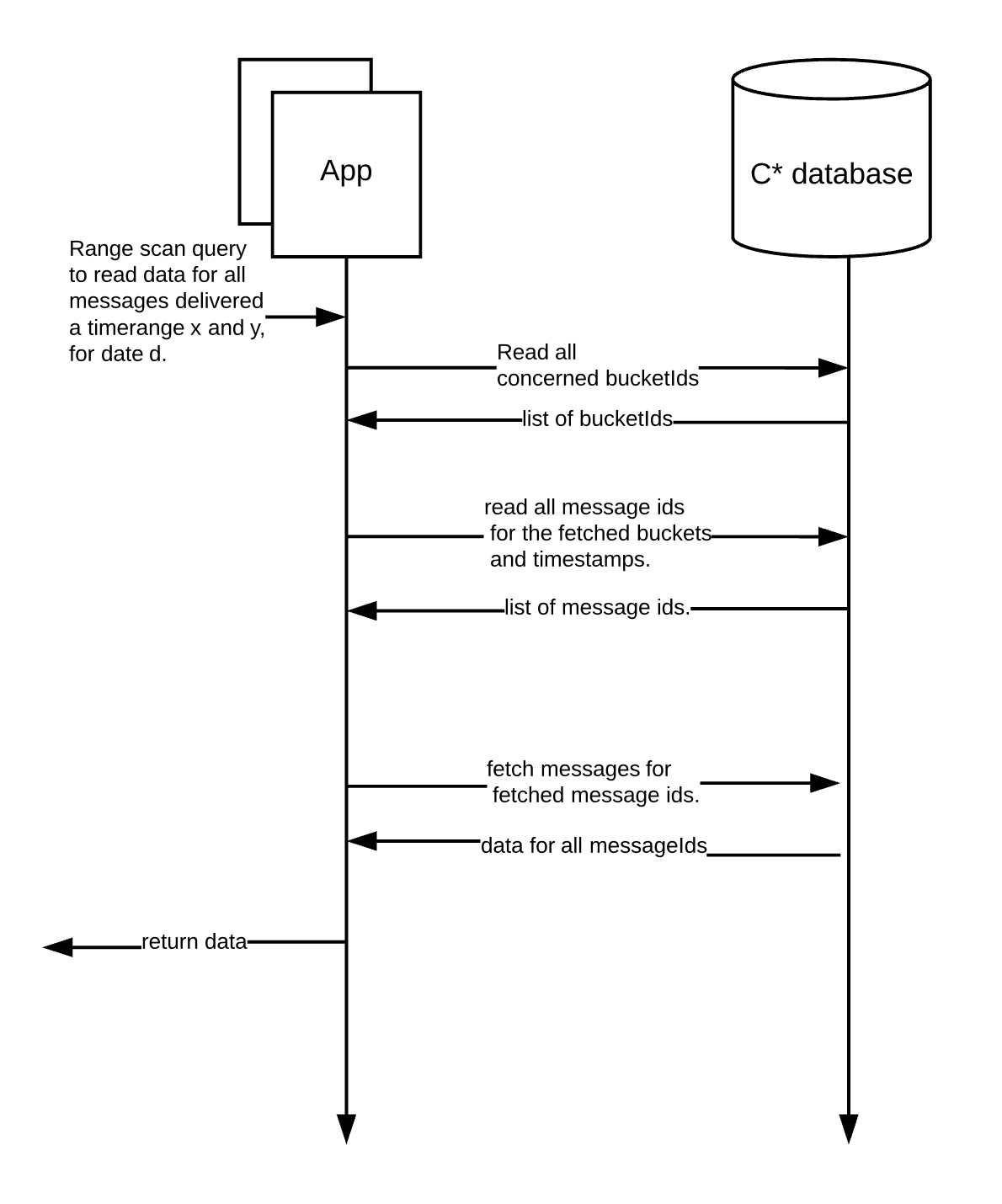
现在,让我们看看如何使用这个模型对给定的实体执行范围扫描,并使用一些实际的测试数据。
-- view bucket ids.
team@cqlsh> select * from my_keyspace.bucket_id_log where created_date='2019-12-01' and entity_name='MESSAGE_LOG_DATED';created_date | entity_name | created_date_timestamp | id (just here to make pk unique) | bucket_id | created_by
--------------+-------------------+--------------------------+--------------------------------------+--------------------------------------+----------------
2019-12-01 | MESSAGE_LOG_DATED | 2019-12-01 00:00:06+0000 | dc5a7fb9-eeb2-425d-ae9c-4c14f9ab581c | 8751a640-13cd-11ea-bcc0-7f2f66afd78a | 10.65.99.183
2019-12-01 | MESSAGE_LOG_DATED | 2019-12-01 00:00:06+0000 | b61afafe-13a8-4b8d-9014-d249183760e1 | 8751a640-13cd-11ea-bcc0-7f2f66afd78b | 10.65.103.141
2019-12-01 | MESSAGE_LOG_DATED | 2019-12-01 00:00:05+0000 | 5a60bd48-cd97-4912-9cba-d543225e7bfe | 8751a640-13cd-11ea-bcc0-7f2f66afd78c | 10.117.233.105
-- Read bucket ids.
team@cqlsh> select bucket_id from my_keyspace.bucket_id_log where created_date='2019-12-01' and entity_name='MESSAGE_LOG_DATED';bucket_id
--------------------------------------
8751a640-13cd-11ea-bcc0-7f2f66afd78a
8751a640-13cd-11ea-bcc0-7f2f66afd78b
8751a640-13cd-11ea-bcc0-7f2f66afd78c
-- Read message log for the time span.
team@cqlsh> select * from my_keyspace.message_log_dated where created_date='2019-12-01' and bucket_id in (8823ea60-13cd-11ea-b3c9-adfcfeffafbc, 881eba40-13cd-11ea-b0bc-dd0e281ebb5f, 87bbd9c0-13cd-11ea-81d9-81a480b11fcf, 8751a640-13cd-11ea-bcc0-7f2f66afd78c);
created_date | bucket_id | event | created_date_timestamp | message_id | id (part of pk, (surrogate)) | created_by
--------------+---------------------------------------+-----------------------+--------------------------+--------------------------------------+---------------------------------------+----------------
2019-12-01 | 8751a640-13cd-11ea-bcc0-7f2f66afd78a | order-confirmation | 2019-12-01 15:58:00+0000 | 13a07a49-8169-44d1-a7a9-ae8f33ba44c5 | 71c1f81e-cd6e-4ab8-b714-ebf48af32be0 | 10.247.194.101
2019-12-01 | 8751a640-13cd-11ea-bcc0-7f2f66afd78b | ship-confirmation | 2019-12-01 22:21:53+0000 | 3dfd0c23-1a62-45e8-a7b6-d4e14d65149a | 9ea23802-121e-48cc-91ac-711ab261b195 | 10.247.194.102
2019-12-01 | 8751a640-13cd-11ea-bcc0-7f2f66afd78c | delivery-confirmation | 2019-12-01 22:21:17+0000 | 4a24e822-624f-486e-b67c-f25be2f40110 | 9f8ce5ad-69a1-4e1a-8a4f-d31dedba7847 | 10.247.194.103-- now we can easily scan through each message using message ids resulted above for the given time range.
这里有一个快速查询,确认每个bucket都符合分配的最大bucket计数,在我的测试中保持50000。team@cqlsh> select count(*) from my_keyspace.message_log_dated where created_date='2019-12-01' and bucket_id=8751a640-13cd-11ea-bcc0-7f2f66afd78a;
count
-------
50000(1 rows)
下面是这个流程的写和读的快速演示:
评价
现在我们来评估一下这个方法,
优点:
- 过滤应该是直接的,你可以在日期日志中复制更多的列,这样你就可以读取你想要的配置的消息id。
- 插入操作简单快捷。
- 读是很快速的。
- 最重要的是,它解决了我们在这里试图解决的集群平衡问题。
- 如果应用程序上的负载均衡器是公正的,它会很有帮助,但即使它在错误/配置改变的情况下摇摆不定,这种方法仍然会保持稳定。
缺点:
- 排序(如果需要)将需要在应用程序层进行。
- 分页需要在应用程序层上执行。
总结
Cassandra上的范围扫描解决起来并不简单,但是只要有合适的数据模型,就一定可以解决这个问题。为了保持集群正常运行,您的写操作必须是分布式的和统一的。
虽然您可能会认为使用上述建议的解决方案会消耗更多存储空间,但在Cassandra的世界中这完全没问题。你可以复制数据(而不是以最规格化的形式),如果它有助于优化你的查询。
使用这种基于“Bucketisation”的方法,您可以支持范围扫描,同时避免意外流量激增,并且不会对集群的运行状况造成任何风险。
最后但并非最不重要的是,我要对我的导师大喊一声,感谢他从这个方法的开始到它在生产中发挥作用一直在指导我。
本文:http://jiagoushi.pro/node/1362
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】或者QQ群【11107777】
- 登录 发表评论
- 123 次浏览
最新内容
- 1 month 2 weeks ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago
- 5 months 1 week ago