
category

让我们简单了解一下Mlflow,它是什么以及它提供了什么。
介绍
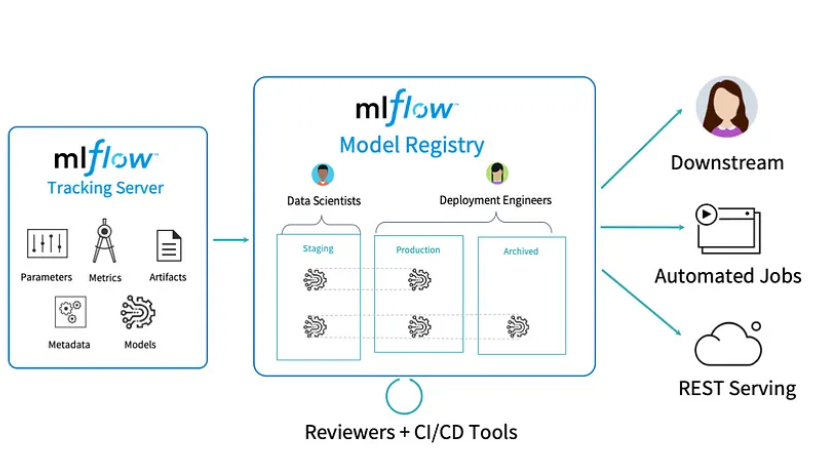
MLflow是一个用于管理端到端机器学习生命周期的开源平台。它处理四个主要功能:
- 跟踪实验以记录和比较参数和结果(MLflow Tracking)。
- 以可重复使用、可复制的形式封装ML代码,以便与其他数据科学家共享或转移到生产中(MLflow项目)
- 管理和部署从各种ML库到各种模型服务和推理平台(MLflow models)的模型。
- 提供一个中央模型存储,以协作管理MLflow模型的整个生命周期,包括模型版本控制、阶段转换和注释(MLflow模型注册表)。
Installation:
Install mlflow in python env:
pip install mlflow # includes UI
pip install mlflow[extras] # downloads extra ML libraries
MLflow on localhost with SQLite:
mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root ./artifac
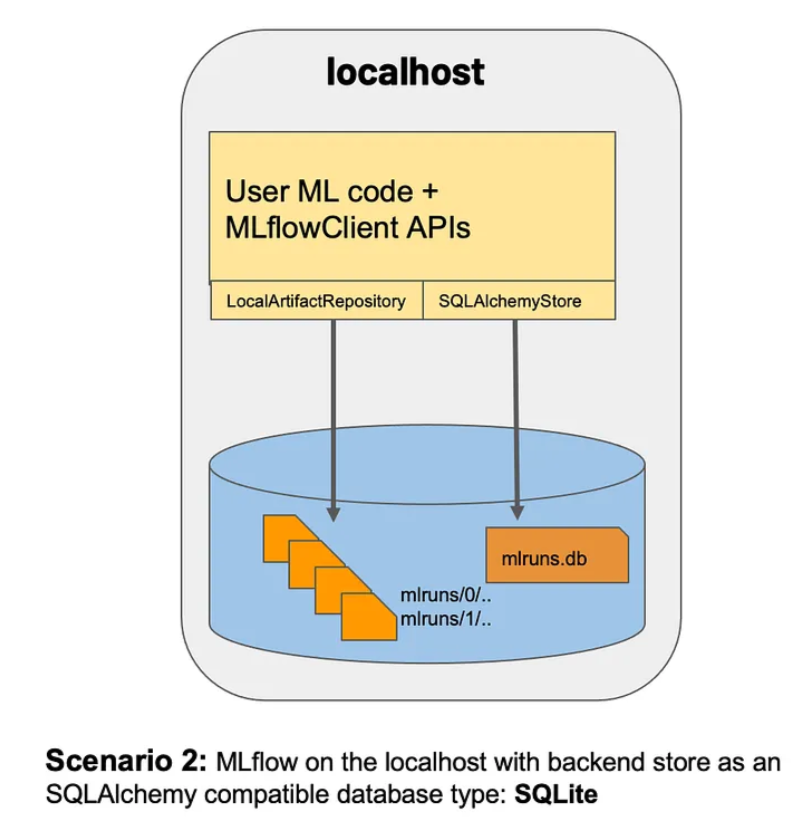
- 后端存储:将运行/实验信息与模型存储信息一起存储为数据库。
- 工件:运行/体验的输出文件(模型、针叶树、标签等)
有关其他类型的跟踪方法,请查看此处。
使用Python API的开始日志记录运行/实验:
日志记录功能
mlflow.set_tracking_uri()连接到跟踪uri。您还可以设置mlflow_tracking_uri环境变量,使mlflow从中查找uri。在这两种情况下,URI可以是远程服务器的HTTP/HTTPS URI、数据库连接字符串,也可以是将数据记录到目录的本地路径。URI默认为mlrun。
mlflow.create_experiment()创建一个新的实验并返回其ID。通过将实验ID传递给mlflow.start_run,可以在实验下启动运行。
mlflow.set_experiment()将实验设置为活动。如果该实验不存在,则创建一个新的实验。如果没有在mlflow.start_run()中指定实验,则会在此实验下启动新的运行。
mlflow.start_run()返回当前活动的运行(如果存在),或者启动新的运行并返回mlflow。ActiveRun对象,可用作当前运行的上下文管理器。您不需要显式调用start_run:在没有活动运行的情况下调用其中一个日志记录函数会自动启动一个新函数。
mlflow.end_run()结束当前活动的运行(如果有的话),采取可选的运行状态。
log_metric()记录单个键值度量。该值必须始终是一个数字。MLflow会记住每个度量值的历史记录。使用mlflow.log_metrics()一次记录多个度量。
在上查看仪表板http://localhost:5000mlflow服务器运行的位置。

MLflow模型注册表:
MLflow模型注册表组件是一个集中的模型存储、一组API和UI,用于协作管理MLflow模型的整个生命周期。它提供了模型沿袭(MLflow实验和运行产生的模型)、模型版本控制、阶段转换(例如从阶段到生产)和注释。
将模型添加到模型注册表:
from random import random, randint
from sklearn.ensemble import RandomForestRegressor
import mlflow
import mlflow.sklearn
with mlflow.start_run(run_name="YOUR_RUN_NAME") as run:
params = {"n_estimators": 5, "random_state": 42}
sk_learn_rfr = RandomForestRegressor(**params)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_param("param_1", randint(0, 100))
mlflow.log_metrics({"metric_1": random(), "metric_2": random() + 1})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=sk_learn_rfr,
artifact_path="sklearn-model",
registered_model_name="sk-learn-random-forest-reg-model"
)更多功能,如获取服务,重命名等。
https://mlflow.org/docs/latest/model-registry.html#id6
现在让我们看看什么是Triton推理服务器,
介绍
NVIDIA Triton推理服务器是一款开源推理服务软件,可简化人工智能推理。Triton使团队能够部署来自多个深度学习和机器学习框架的任何人工智能模型,包括TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPID FIL等。
Triton支持在NVIDIA GPU、x86和ARM CPU或AWS Inferentia上跨云、数据中心、边缘和嵌入式设备进行推理。
使用mlflow的Triton推理服务器:
为了使用Triton推理服务器为模型提供服务,Nvidia提供了Mlflow Triton插件。
目前,它支持onnx和triton型号的口味。
步骤:
- 运行Triton推理服务器
- 运行MLFlow Triton插件
- 将模型发布到Mflow服务器
- 将已发布的模型部署到Triton
以EXPLICIT模式启动Triton推理服务器
docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/home/ubuntu/triton_models:/models nvcr.io/nvidia/tritonserver:22.12-py3 tritonserver --model-repository=/models --model-control-mode=explicit
# Explicit mode does not load models at runtime.
#显式模式不在运行时加载模型。
Mlfow Triton插件:
在机器中创建一个名为triton_models的文件夹,并根据triton Server的要求将您的模型复制到具有模型结构的文件夹中
用于推断的模型结构:
└── model_folder/ # model_folder
├── 1 # Version of the model
└── model.ckpt # model file
├── config.pbxt # model configfile
└── labels.txt # labels of classes
这里我们举一个yolov6n的例子:
└── yolov6n/ # model_folder
├── 1 # Version of the model
└── model.onnx # model file
├── config.pbxt # model configfile
└── labels.txt # labels of classes
创建MLFlow Triton Plugin容器并将其卷装载到Triton模型存储库,然后在容器中打开bash:
docker run -it -v /home/ubuntu/triton_models:/triton_models \
--env TRITON_MODEL_REPO=/triton_models \
--gpus '"device=0"' \
--net=host \
--rm \
-d nvcr.io/nvidia/morpheus/mlflow-triton-plugin:2.2.2
docker exec -it <container_name> bash
导出Mlflow跟踪服务器url并启动服务器:
export MLFLOW_TRACKING_URI=http://localhost:5000
nohup mlflow server --backend-store-uri sqlite:////tmp/mlflow-db.sqlite --default-artifact-root /mlflow/artifacts --host 0.0.0.0 &
将参考模型发布到MLflow:
python3 publish_model_to_mlflow.py --model_name yolov6n --model_directory /triton_models/yolov6n --flavor triton
创建到Triton推理服务器的部署:
mlflow deployments create -t triton --flavor triton --name yolov6n -m models:/yolov6n/1

如果要删除和更新模型:
mlflow deployments delete -t triton --name yolov6n
mlflow deployments update -t triton --flavor triton --name yolov6n -m models:/yolov6n/2
对于推理,我们有两种选择:
1)使用mlflow进行推理:
mlflow deployments predict -t triton --name yolov6n --input-path <path-to-the-examples-directory>/input.json --output-path output.json
#Example input json for yolov6n:
#img_ex is list of ndarray
{"inputs":[{"name":"images","datatype":"FP32","shape":[1, 3, 640, 640],"data":"example_image_array"}]}
2)使用triton http://gRPC客户端进行推理:
import tritonclient.http as httpclient
model_name = "yolov6n"
triton_client = httpclient.InferenceServerClient(url="0.0.0.0:8000")
triton_client.get_model_metadata(model_name)
"""
output:
{'name': 'yolov6n', 'versions': ['1'], 'platform': 'onnxruntime_onnx',
'inputs': [{'name': 'images', 'datatype': 'FP32',
'shape': [1, 3, 640, 640]}],
'outputs': [{'name': 'outputs', 'datatype': 'FP32', 'shape': [1, 8400, 85]}]}
"""
inputs = []
outputs = []
im = np.array(im, dtype=np.float32) # im is the image numpy array
inputs.append(httpclient.InferInput('images', [1,3,640,640], "FP32"))
outputs.append(httpclient.InferRequestedOutput("outputs"))
inputs[0].set_data_from_numpy(im)
results = triton_client.infer(model_name=model_name, inputs=inputs)
results.get_response()
"""
output:
{'model_name': 'yolov6n', 'model_version': '1',
'outputs': [{'name': 'outputs', 'datatype': 'FP32',
'shape': [1, 8400, 85], 'parameters': {'binary_data_size': 2856000}}]}
"""
结论
同时使用mlflow和triton推理服务器有几个优点:
我们可以利用Triton的推理能力,即。
- 支持多后端/架构推理。
- CPU/GPU资源的完整优化利用。
- 多协议支持gRPC/Http
并且我们使用mlflow作为模型部署和模型管理的前端具有优势,
- Mlflow是一个轻量级且功能齐全的MLOps工具包,包含大量的API。
- 一个具有UI的集中式模型存储,用于协作管理ML模型的整个生命周期。
- 在整个开发和部署过程中使用交互式UI进行模型跟踪和实验。
参考文献:
- https://github.com/mlflow/mlflow
- https://github.com/triton-inference-server
- https://github.com/triton-inference-server/client
- https://catalog.ngc.nvidia.com/orgs/nvidia/teams/morpheus/containers/mlflow-triton-plugin
- https://github.com/triton-inference-server/server/tree/r22.09/deploy/mlflow-triton-plugin
- https://catalog.ngc.nvidia.com/orgs/nvidia/teams/morpheus/containers/mlflow-triton-plugin
- https://github.com/nv-morpheus/Morpheus/tree/bc791eaec7ffa19db2fd292f8fb65a74473885a2/models/mlflow
- 登录 发表评论
- 169 次浏览
Tags
最新内容
- 1 week 5 days ago
- 2 weeks 6 days ago
- 3 weeks 3 days ago
- 2 months 1 week ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago
- 6 months ago