
category
本文解释了用于计算全文搜索的搜索分数的BM25相关性评分算法。BM25相关性仅限于全文搜索。过滤查询、自动完成和建议查询、通配符搜索或模糊搜索查询不会根据相关性进行评分或排名。
全文搜索中使用的评分算法
Azure AI Search为全文搜索提供了以下评分算法:
| Algorithm | Usage | Range |
|---|---|---|
BM25Similarity |
Fixed algorithm on all search services created after July 2020. You can configure this algorithm, but you can't switch to an older one (classic). | Unbounded. |
ClassicSimilarity |
Present on older search services. You can opt-in for BM25 and choose an algorithm on a per-index basis. | 0 < 1.00 |
BM25和Classic都是类似TF IDF的检索函数,使用术语频率(TF)和逆文档频率(IDF)作为变量来计算每个文档查询对的相关性得分,然后将其用于对结果进行排名。虽然BM25在概念上与经典相似,但它植根于概率信息检索,通过用户研究可以产生更直观的匹配。
BM25提供了高级定制选项,例如允许用户决定相关性分数如何随着匹配术语的术语频率而缩放。有关详细信息,请参阅配置评分算法。
笔记
如果你使用的搜索服务是在2020年7月之前创建的,那么评分算法很可能是以前的默认值ClassicSimilarity,你可以根据每个索引进行升级。有关详细信息,请参阅在旧服务上启用BM25评分。
以下视频片段快速介绍Azure AI搜索中使用的常用排名算法。您可以观看完整的视频以获取更多背景信息。
BM25排名的工作原理
相关性评分是指计算搜索得分(@search.score),该得分作为项目在当前查询上下文中相关性的指标。范围是无限的。然而,分数越高,项目就越相关。
搜索得分是基于字符串输入和查询本身的统计特性来计算的。Azure AI Search会查找与搜索词匹配的文档(部分或全部,取决于searchMode),支持包含许多搜索词实例的文档。如果该术语在数据索引中很少见,但在文档中很常见,则搜索得分会更高。这种计算相关性的方法的基础被称为TF-IDF或术语频率逆文档频率。
搜索分数可以在整个结果集中重复。当多个点击具有相同的搜索得分时,相同得分项目的排序是未定义的且不稳定的。再次运行查询,您可能会看到项目的位置发生了变化,尤其是当您使用免费服务或具有多个副本的收费服务时。给定两个分数相同的项目,不能保证其中一个先出现。
要打破重复分数之间的平局,可以将$orderby子句添加到第一个按分数排序,然后按另一个可排序字段排序(例如,$orderby=search.score()desc,Rating desc)。有关详细信息,请参阅$orderby。
只有在索引中标记为可搜索的字段或查询中的searchFields才会用于评分。只有标记为可检索的字段或在查询中的select中指定的字段才会在搜索结果中返回,以及它们的搜索得分。
笔记
@search.score=1表示未得分或未排名的结果集。所有结果的得分都是一致的。当查询形式为模糊搜索、通配符或正则表达式查询或空搜索(search=*,有时与筛选器配对,其中筛选器是返回匹配项的主要手段)时,会出现未得分的结果。
文本结果中的分数
无论何时对结果进行排序,@search.score属性都包含用于对结果排序的值。
下表确定了每个匹配、算法和范围返回的评分属性。
| Search method | Parameter | Scoring algorithm | Range |
|---|---|---|---|
| full text search | @search.score |
BM25 algorithm, using the parameters specified in the index. | Unbounded. |
得分变化
搜索分数传达了一般的相关性,反映了相对于同一结果集中其他文档的匹配强度。但是,不同查询的分数并不总是一致的,所以当您处理查询时,您可能会注意到搜索文档的排序方式存在微小差异。有几种解释可以解释为什么会发生这种情况。
| Cause | Description |
|---|---|
| Identical scores | If multiple documents have the same score, any one of them might appear first. |
| Data volatility | Index content varies as you add, modify, or delete documents. Term frequencies will change as index updates are processed over time, affecting the search scores of matching documents. |
| Multiple replicas | For services using multiple replicas, queries are issued against each replica in parallel. The index statistics used to calculate a search score are calculated on a per-replica basis, with results merged and ordered in the query response. Replicas are mostly mirrors of each other, but statistics can differ due to small differences in state. For example, one replica might have deleted documents contributing to their statistics, which were merged out of other replicas. Typically, differences in per-replica statistics are more noticeable in smaller indexes. The following section provides more information about this condition. |
对查询结果的碎片化影响
碎片是索引的一大块。Azure AI Search将索引细分为碎片,以加快添加分区的过程(通过将碎片移动到新的搜索单元)。在搜索服务中,分片管理是一个实现细节,不可配置,但知道索引是分片的有助于理解排名和自动完成行为中偶尔出现的异常:
- 排名异常:搜索分数首先在碎片级别计算,然后聚合到一个结果集中。根据碎片内容的特性,来自一个碎片的匹配可能比另一个碎片中的匹配排名更高。如果你注意到搜索结果中的排名与直觉相悖,那很可能是由于分片的影响,尤其是在索引很小的情况下。您可以通过选择全局计算整个指数的分数来避免这些排名异常,但这样做会导致性能损失。
- 自动完成异常:自动完成查询在部分输入的词条的前几个字符上进行匹配,接受一个模糊参数,该参数可以原谅拼写上的小偏差。对于自动完成,模糊匹配仅限于当前碎片中的项。例如,如果一个碎片包含“Microsoft”,并且输入了“micro”的部分术语,则搜索引擎将匹配该碎片中的“Microsoft”而不是包含索引其余部分的其他碎片。
下图显示了副本、分区、碎片和搜索单元之间的关系。它展示了一个示例,说明如何在具有两个副本和两个分区的服务中跨越四个搜索单元来创建单个索引。四个搜索单元中的每一个只存储索引的一半碎片。左列中的搜索单元存储包括第一分区的前半个碎片,而右列中的搜索单位存储包括第二分区的后半个碎片。由于有两个副本,所以每个索引碎片都有两个拷贝。顶行中的搜索单元存储一个包括第一副本的副本,而底行中的那些搜索单元存储另一个包括第二副本的副本。
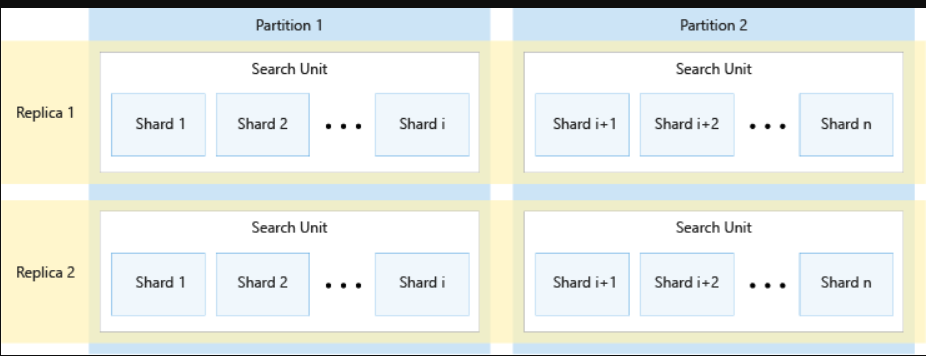
上图只是一个例子。分区和副本的许多组合都是可能的,最多总共36个搜索单元。
笔记
副本和分区的数量平均分为12个(具体地说,1、2、3、4、6、12个)。Azure AI Search将每个索引预先划分为12个碎片,以便在所有分区中等分。例如,如果您的服务有三个分区,并且您创建了一个索引,那么每个分区将包含索引的四个碎片。Azure AI搜索如何分割索引是一个实现细节,可能会在未来版本中发生变化。虽然今天的数字是12,但你不应该期望将来这个数字总是12。
得分统计和粘性会话
为了实现可扩展性,Azure AI Search通过分片过程水平分布每个索引,这意味着索引的部分在物理上是分开的。
默认情况下,文档的分数是根据碎片中数据的统计特性计算的。这种方法对于大型数据语料库来说通常不是问题,并且它提供了比必须基于所有碎片上的信息来计算分数更好的性能。也就是说,使用这种性能优化可能会导致两个非常相似的文档(甚至是相同的文档)在不同的碎片中得到不同的相关性分数。
如果您更喜欢根据所有碎片的统计属性来计算分数,可以通过添加scoringStatistics=global作为查询参数(或添加“scoringtatistics”:“global”作为查询请求的主体参数)来实现。
HTTP
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2023-11-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
使用scoringStatistics将确保同一副本中的所有碎片都能提供相同的结果。也就是说,不同的副本之间可能略有不同,因为它们总是随着索引的最新更改而更新。在某些情况下,您可能希望用户在“查询会话”期间获得更一致的结果。在这种情况下,您可以提供sessionId作为查询的一部分。sessionId是您为引用唯一用户会话而创建的唯一字符串。
HTTP
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2023-11-01
{
"search": "<query string>",
"sessionId": "<string>"
}
只要使用相同的sessionId,就会尽最大努力以相同的复制副本为目标,从而提高用户将看到的结果的一致性。
笔记
重复使用相同的sessionId值可能会干扰跨副本请求的负载平衡,并对搜索服务的性能产生不利影响。用作sessionId的值不能以“_”字符开头。
相关性调整
在Azure AI搜索中,您可以配置BM25算法参数,并通过以下机制调整搜索相关性和提高搜索分数:
| Approach | Implementation | Description |
|---|---|---|
| Scoring algorithm configuration | Search index | |
| Scoring profiles | Search index | Provide criteria for boosting the search score of a match based on content characteristics. For example, you might want to boost matches based on their revenue potential, promote newer items, or perhaps boost items that have been in inventory too long. A scoring profile is part of the index definition, composed of weighted fields, functions, and parameters. You can update an existing index with scoring profile changes, without incurring an index rebuild. |
| Semantic ranking | Query request | Applies machine reading comprehension to search results, promoting more semantically relevant results to the top. |
| featuresMode parameter | Query request | This parameter is mostly used for unpacking a score, but it can be used for in code that provides a custom scoring solution. |
功能模式参数(预览)
搜索文档请求具有一个新功能Mode参数,该参数可以在字段级别提供有关相关性的更多详细信息。尽管@searchScore是为文档计算的(该文档在该查询的上下文中的相关性如何),但通过featuresMode,您可以获得有关各个字段的信息,如@search.features结构所示。该结构包含查询中使用的所有字段(通过查询中的searchFields的特定字段,或索引中可搜索的所有字段)。对于每个字段,您将获得以下值:
- 在字段中找到的唯一令牌数
- 相似性得分,或字段内容相对于查询项的相似程度的度量
- 术语频率,或在字段中找到查询术语的次数
对于针对“描述”和“标题”字段的查询,包含@search.features的响应可能如下所示:
JSON
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
您可以在自定义评分解决方案中使用这些数据点,也可以使用这些信息来调试搜索相关性问题。
全文查询响应中的排名结果数
默认情况下,如果不使用分页,搜索引擎会返回排名前50位的全文搜索匹配项。您可以使用top参数返回较小或较大数量的项目(单个响应中最多1000个)。全文搜索的最大匹配限制为1000(请参阅API响应限制)。一旦找到1000个匹配项,搜索引擎就不再寻找更多匹配项。
要返回或多或少的结果,请使用分页参数top、skip和next。分页是确定每个逻辑页上的结果数并浏览整个负载的方式。有关详细信息,请参阅如何使用搜索结果。
另请参阅
- 登录 发表评论
- 72 次浏览
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago