
我们激动地宣布,作为Databricks运行时7.0的一部分,可以在Databricks上使用Apache SparkTM 3.0.0版本。3.0.0版本包含超过3400个补丁,是开源社区做出巨大贡献的顶峰,带来了Python和SQL功能方面的重大进步,并关注于开发和生产的易用性。这些举措反映了该项目如何发展,以满足更多的用例和更广泛的受众,今年是它作为一个开源项目的10周年纪念日。
以下是Spark 3.0最大的新特性:
- TPC-DS比Spark 2.4的性能提高了2倍,支持自适应查询执行、动态分区剪枝和其他优化
- ANSI SQL合规
- 对panda api进行了重大改进,包括Python类型提示和额外的panda udf
- 更好的Python错误处理,简化PySpark异常
- 结构化流的新UI
- 调用R用户定义函数的速度可达到40x
- 3400多张Jira票已经解决
采用这个版本的Apache Spark不需要做大的代码更改。有关更多信息,请查看迁移指南。
庆祝Spark发展和演变的10年
Spark的前身是加州大学伯克利分校的AMPlab实验室,这是一个专注于数据密集型计算的研究实验室。AMPlab的研究人员与大型互联网公司合作研究他们的数据和人工智能问题,但是他们发现这些同样的问题也会被所有拥有大量且不断增长的数据的公司所面临。该团队开发了一个新的引擎来处理这些新兴的工作负载,同时使开发人员更容易访问用于处理大数据的api。
社区的贡献很快就加入进来,将Spark扩展到不同的领域,提供了围绕流、Python和SQL的新功能,这些模式现在构成了Spark的一些主要用例。这种持续的投资为它带来了今天的火花,成为数据处理、数据科学、机器学习和数据分析工作负载事实上的引擎。Apache Spark 3.0延续了这一趋势,显著改进了对SQL和Python(目前Spark使用最广泛的两种语言)的支持,并对Spark其余部分的性能和可操作性进行了优化。
改进Spark SQL引擎
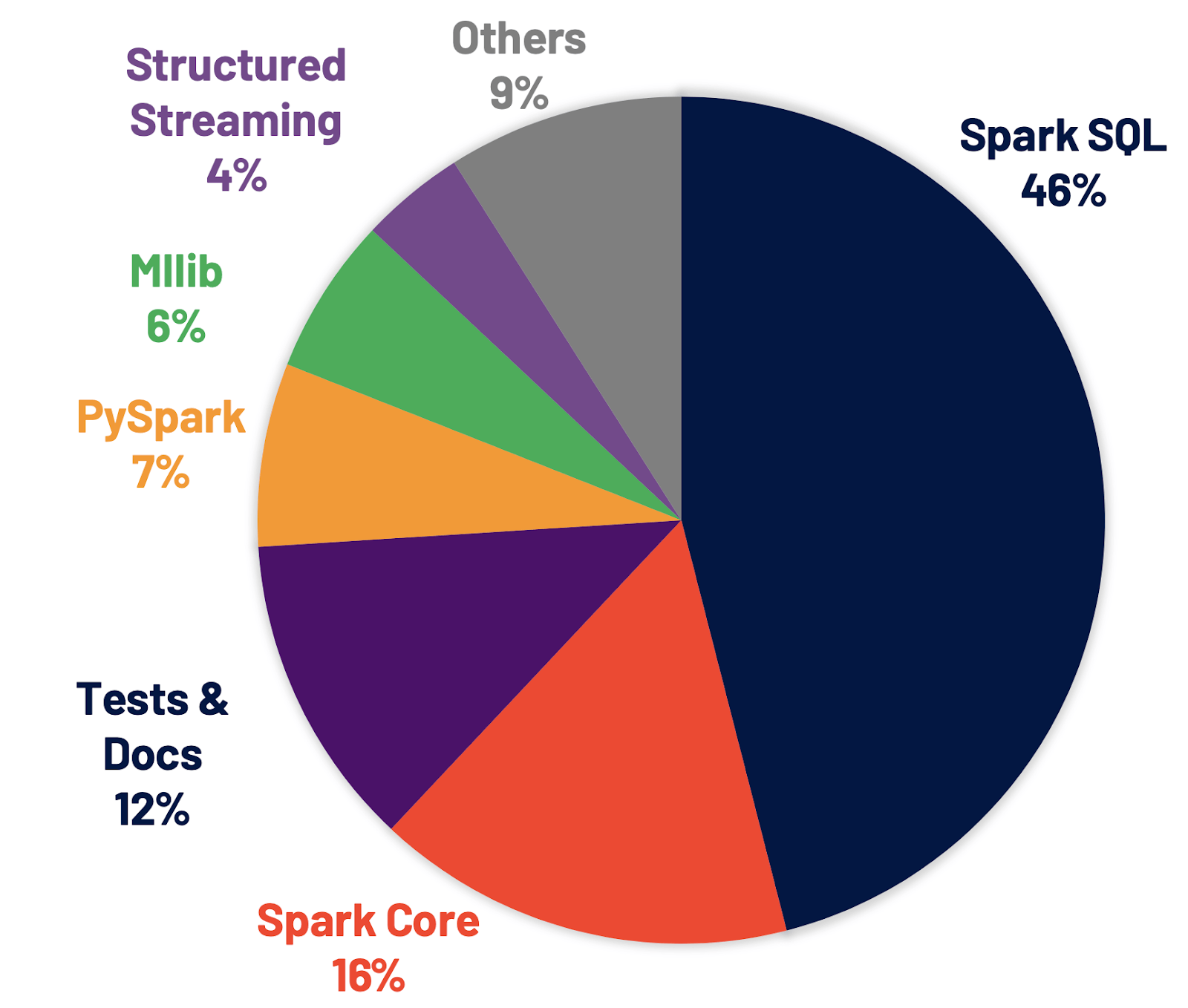
Spark SQL是支持大多数Spark应用程序的引擎。例如,在Databricks上,我们发现超过90%的Spark API调用使用DataFrame、Dataset和SQL API以及其他由SQL优化器优化的库。这意味着即使是Python和Scala开发人员也要通过Spark SQL引擎来传递他们的大部分工作。在Spark 3.0版本中,46%的补丁是针对SQL的,从而提高了性能和ANSI兼容性。如下所示,Spark 3.0在运行时的总体性能大约比Spark 2.4好2倍。接下来,我们将解释Spark SQL引擎中的四个新特性。

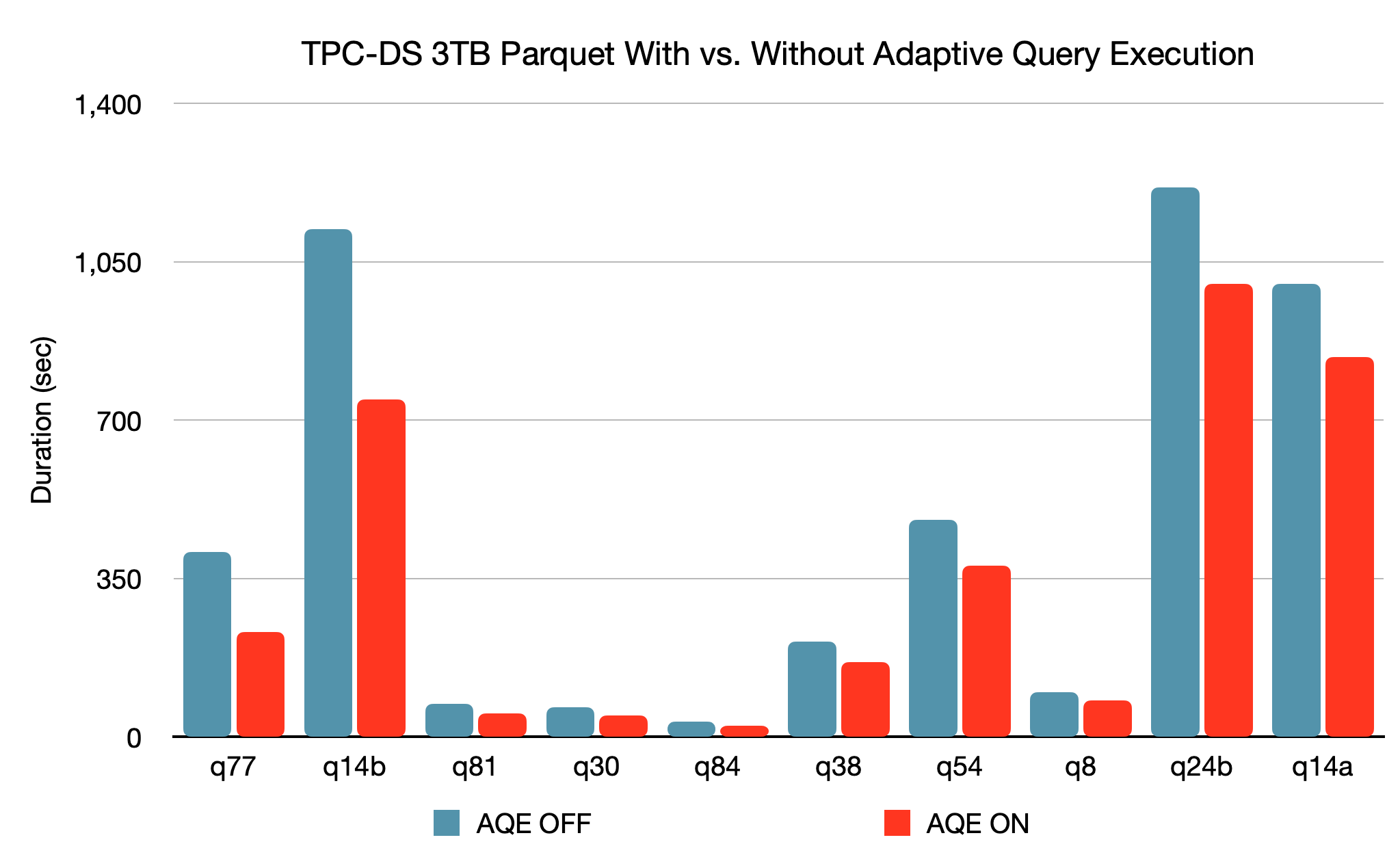
新的自适应查询执行(AQE)框架通过在运行时生成更好的执行计划来改进性能和简化调优,即使初始计划由于缺乏/不准确的数据统计和错误估计的成本而不是最优的。由于Spark中的存储和计算分离,数据到达可能是不可预测的。由于所有这些原因,与传统系统相比,Spark的运行时适应性变得更加关键。这个版本引入了三个主要的自适应优化:
- 动态合并洗牌分区可以简化甚至避免调整洗牌分区的数量。用户可以在开始时设置相对大量的转移分区,然后AQE可以在运行时将相邻的小分区合并为较大的分区。
- 动态切换连接策略可以部分避免执行由于缺少统计信息和/或大小估计错误而导致的次优计划。这种自适应优化可以在运行时自动将排序合并连接转换为广播散列连接,从而进一步简化调优并提高性能。
- 动态优化倾斜连接是另一个关键的性能增强,因为倾斜连接会导致工作的极度不平衡并严重降低性能。在AQE从shuffle文件统计数据中检测到任何倾斜后,它可以将倾斜分区分割成更小的分区,并将它们与另一端的相应分区连接起来。该优化可以并行化倾斜处理,获得更好的整体性能。
基于3TB的TPC-DS基准测试,与没有AQE相比,Spark与AQE可以对两个查询产生超过1.5倍的性能加速,对另外37个查询产生超过1.1倍的性能加速。

当优化器在编译时无法识别它可以跳过的分区时,将应用动态分区剪枝。
这在星型模式中并不少见,星型模式由一个或多个事实表组成,这些表引用任意数量的维度表。在这样的连接操作中,我们可以通过标识那些过滤维度表的分区来删除连接从事实表中读取的分区。在TPC-DS基准测试中,102个查询中有60个查询的速度显著提高了2倍到18倍。
ANSI SQL遵从性对于从其他SQL引擎到Spark SQL的工作负载迁移至关重要。
为了提高兼容性,该版本切换到预期的公历,还允许用户禁止使用保留的ANSI SQL关键字作为标识符。此外,我们还在数值操作中引入了运行时溢出检查,并在使用预定义模式将数据插入表时引入了编译时类型强制。这些新的验证可以提高数据质量。
连接提示:
虽然我们继续改进编译器,但不能保证编译器总是在每种情况下做出最优决策——连接算法的选择是基于统计和启发式的。当编译器无法做出最佳选择时,用户可以使用连接提示来影响优化器选择更好的计划。这个版本通过添加新的提示扩展了现有的连接提示:SHUFFLE_MERGE、SHUFFLE_HASH和SHUFFLE_REPLICATE_NL。
增强Python api: PySpark和Koalas
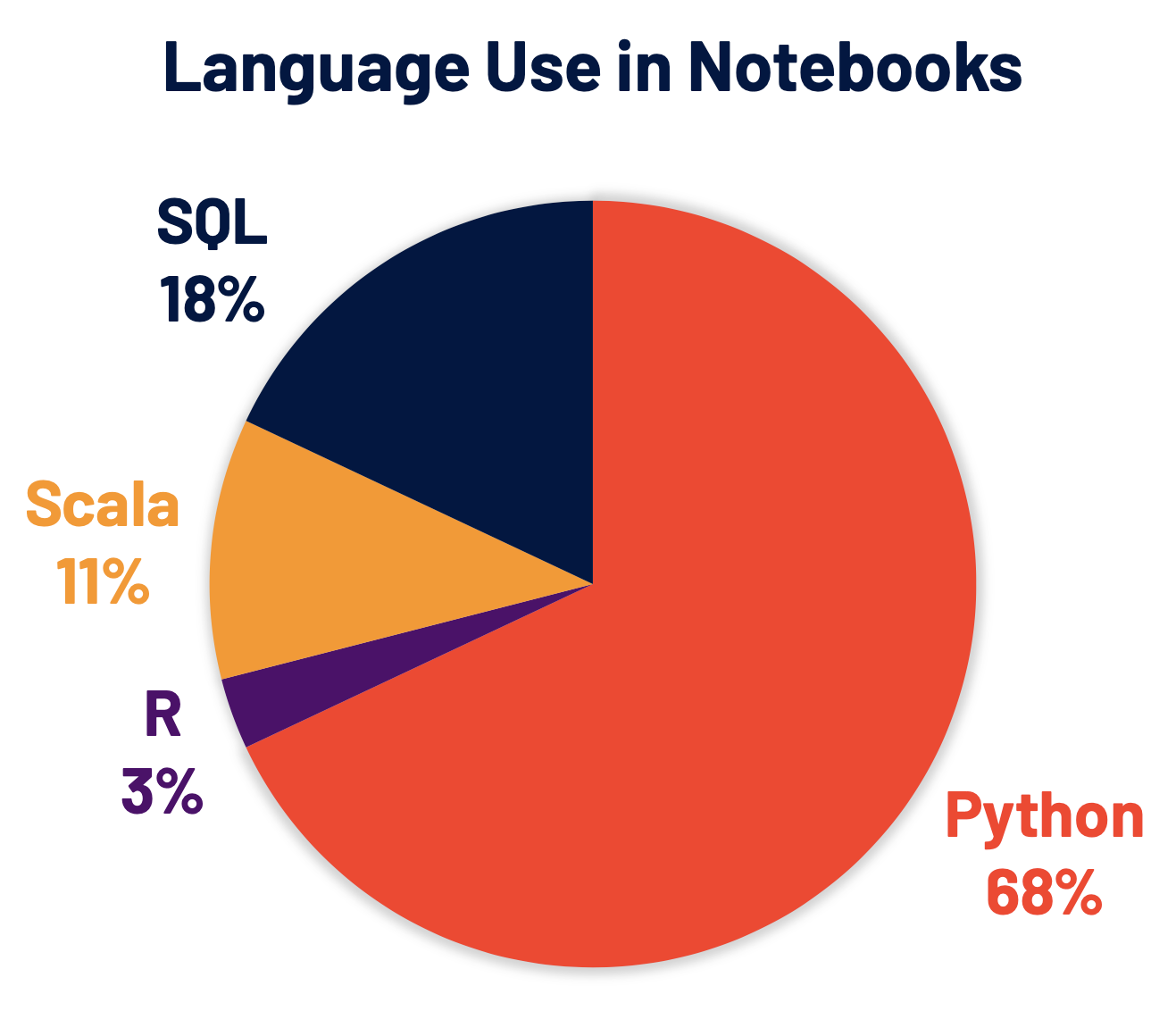
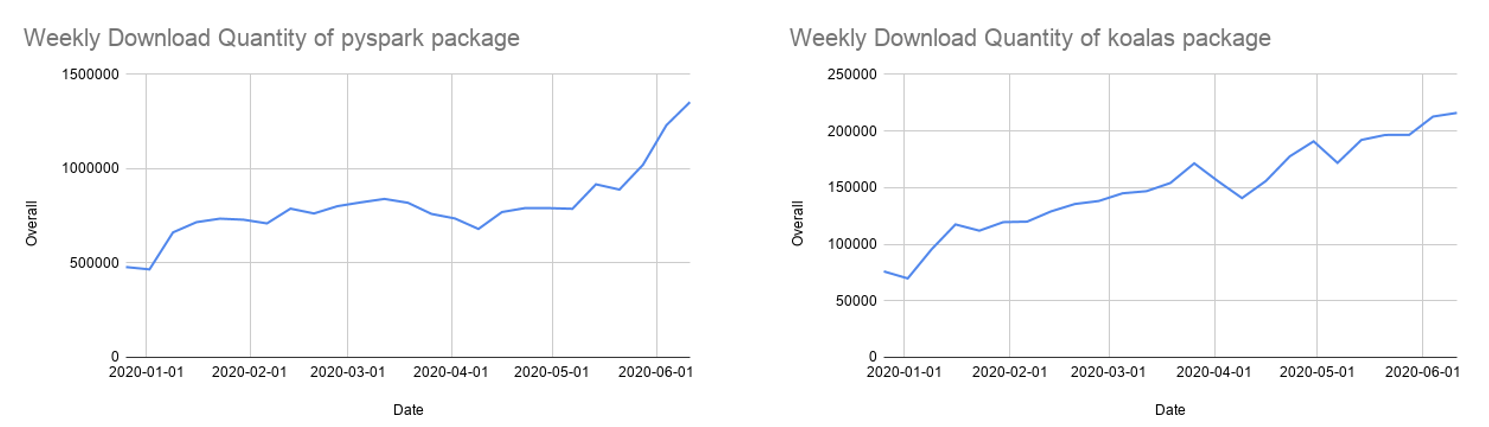
Python现在是Spark上使用最广泛的语言,因此,它是Spark 3.0开发的一个关键关注领域。Databricks上68%的笔记本命令是用Python编写的。Apache Spark Python API PySpark每月在Python包索引PyPI上的下载量超过500万次。
许多Python开发人员使用pandas API进行数据结构和数据分析,但是它仅限于单节点处理。我们还在继续开发考拉(Koalas),这是在Apache Spark上实现的panda API,使数据科学家在分布式环境中处理大数据时更有效率。Koalas不需要在PySpark中构建许多函数(例如,绘图支持),从而实现跨集群的高效性能。
经过一年多的发展,考拉对熊猫的API覆盖率接近80%。每月的PyPI下载量已经迅速增长到85万,而且考拉也以每两周发布一次的节奏迅速发展。虽然考拉可能是从单节点熊猫代码进行迁移的最简单方法,但许多考拉仍然使用PySpark api,而PySpark api也在日益流行。
Spark 3.0增强了PySpark api:
- 带有类型提示的pandas API:熊猫udf最初是在Spark 2.3中引入的,用于扩展PySpark中的用户定义函数,并将熊猫api集成到PySpark应用程序中。但是,当添加更多的UDF类型时,现有的接口很难理解。这个版本引入了一个新的panda UDF接口,它利用Python类型提示来解决panda UDF类型的激增问题。新的接口变得更加python化和自描述。
- pandas UDF的新类型和熊猫函数api:该版本添加了两种新的熊猫UDF类型,即对级数的迭代器添加级数的迭代器,对级数的迭代器添加多级数的迭代器。它对于数据预取和昂贵的初始化非常有用。另外,还添加了两个新的pandas-function api map和co- grouping map。更多的细节可以在这篇博客文章中找到。
- 更好的错误处理:PySpark错误处理对Python用户并不总是友好的。这个版本简化了PySpark异常,隐藏了不必要的JVM堆栈跟踪,并使它们更符合python风格。
改进Spark中的Python支持和可用性仍然是我们的最高优先级之一。
Hydrogen,流化和延展性
通过Spark 3.0,我们完成了Hydrogen项目的关键组件,并引入了改进流和可扩展性的新功能。
基于加速器的调度:
Hydrogen项目是Spark的一个主要项目,旨在更好地统一Spark上的深度学习和数据处理。gpu和其他加速器已被广泛用于加速深度学习工作负载。为了让Spark在目标平台上利用硬件加速器,这个版本增强了现有的调度器,使集群管理器能够感知加速器。用户可以在发现脚本的帮助下通过配置指定加速器。然后,用户可以调用新的RDD api来利用这些加速器。
用于结构化流的新UI:
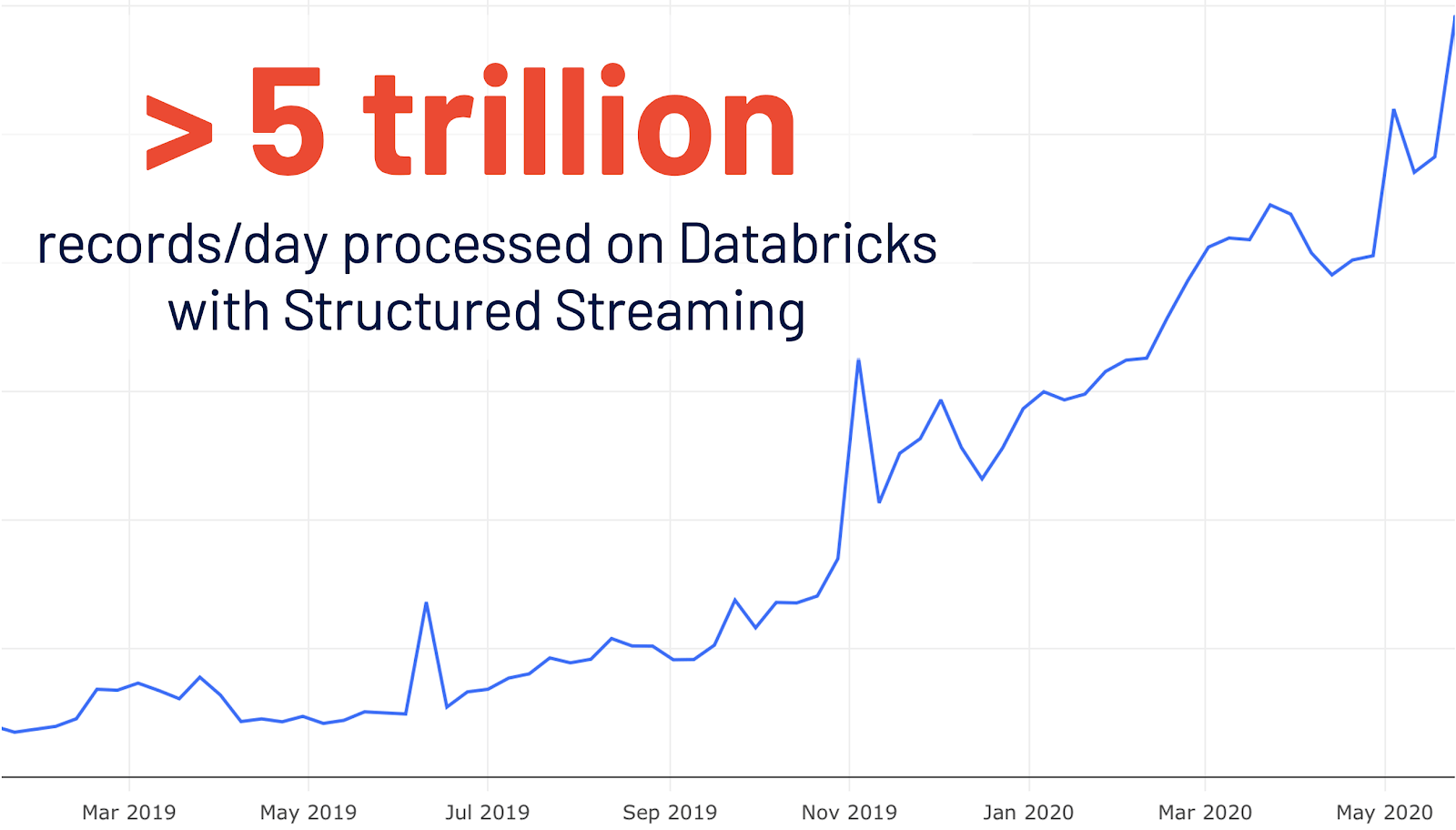
结构化流最初是在Spark 2.0中引入的。在数据库里的使用增长了4倍之后,每天有超过5万亿条记录在数据库里被结构化流媒体处理。这个版本添加了一个专用的新的Spark UI,用于检查这些流作业。这个新的UI提供了两组统计信息:1)已完成的流化查询作业的聚合信息和2)流化查询的详细统计信息。
可观察指标:
持续监控数据质量的变化是管理数据管道的一个非常理想的特性。这个版本引入了对批处理和流应用程序的监视。可观察指标是可以在查询(DataFrame)上定义的任意聚合函数。一旦一个DataFrame的执行达到一个完成点(例如,完成批处理查询或到达流历元),一个命名的事件就会发出,它包含了自最后一个完成点以来处理的数据的度量。
新的目录插件API:
现有的数据源API缺乏访问和操作外部数据源的元数据的能力。这个版本丰富了数据源V2 API,并引入了新的目录插件API。对于既实现了目录插件API又实现了数据源V2 API的外部数据源,在注册了相应的外部目录之后,用户可以通过多部分标识符直接操作外部表的数据和元数据。
Spark 3.0中的其他更新
Spark 3.0是该社区的一个主要发行版,解决了超过3400个Jira罚单。它是超过440名贡献者的贡献,包括个人和公司,如Databricks,谷歌,微软,英特尔,IBM,阿里巴巴,Facebook, Nvidia, Netflix, Adobe等。在这篇博客文章中,我们强调了Spark在SQL、Python和流媒体方面的一些关键改进,但是在这个3.0里程碑中,还有许多其他功能没有在这里介绍。在发布说明中了解更多信息,并发现Spark的所有其他改进,包括数据源、生态系统、监控等等。
现在就开始使用Spark 3.0吧
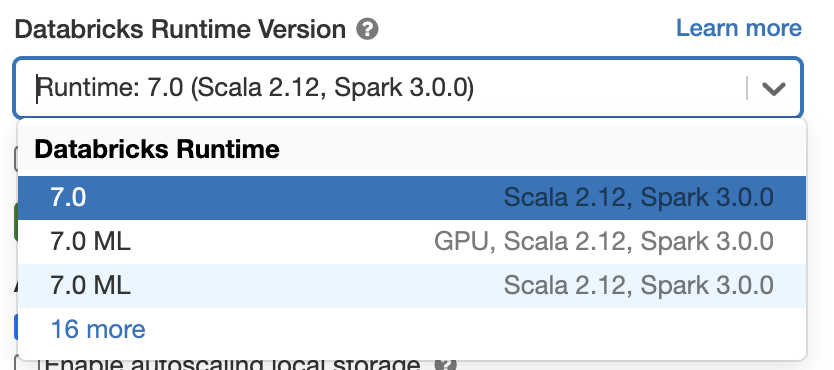
如果您想在Databricks运行时7.0中试用Apache Spark 3.0,请注册一个免费试用帐户,并在几分钟内启动。使用Spark 3.0就像在启动集群时选择version“7.0”一样简单。
本文:http://jiagoushi.pro/node/1190
讨论:请加入知识星球【首席架构师圈】或者加小号【jiagoushi_pro】或者微信圈【11107777】
最新内容
- 1 day 4 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago