
category
评估方法衡量我们的系统性能如何。对每个摘要进行人工评估(人工审查)既费时又昂贵,而且不可扩展,因此通常会辅以自动评估。许多自动评估方法试图衡量人类评估者会考虑的文本质量。这些品质包括流畅性、连贯性、相关性、事实一致性和公平性。内容或风格与参考文本的相似性也可能是生成文本的重要质量。
下图包括用于评估LLM生成内容的许多指标,以及如何对其进行分类。
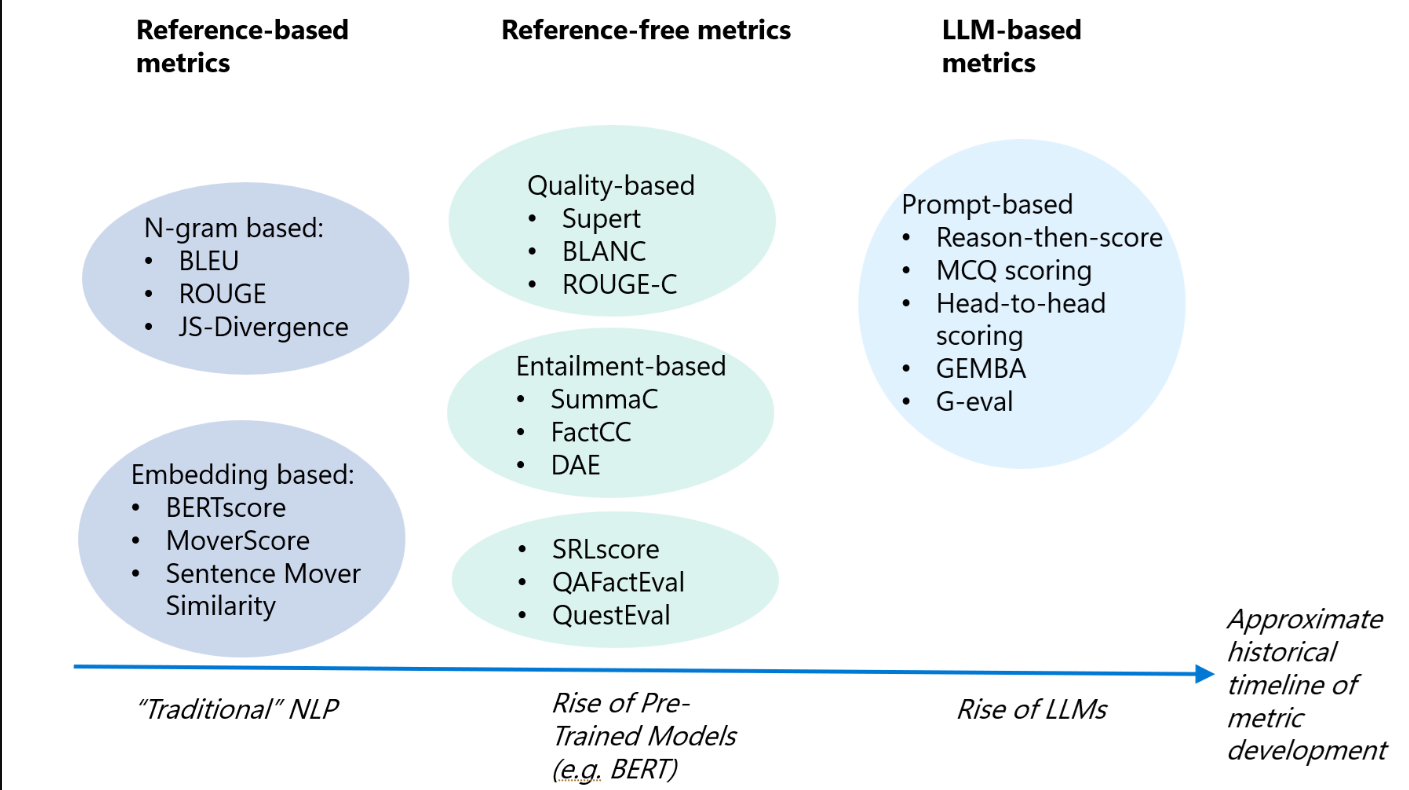
评估指标系列
图1:LLM内容的评估指标,以及如何对其进行分类。时间线显示了人工智能历史上指标是在什么时候开发的
基于参考的指标
基于参考的度量用于将生成的文本与参考(人类注释的地面真实文本)进行比较。其中许多指标是在LLM开发之前为传统NLP任务开发的,但仍然适用于LLM生成的文本。
基于N-gram的度量
指标BLEU(双语评估亚学习)、ROUGE(面向回忆的Gisting评价亚学习)和JS散度(JS2)是基于重叠的指标,使用n元语法衡量输出文本和参考文本的相似性。
BLEU评分
BLEU(双语评估替补)分数评估了机器翻译文本从一种自然语言到另一种语言的质量。因此,它通常用于机器翻译任务,但也用于其他任务,如文本生成、释义生成和文本摘要。其基本思想涉及计算精度,即参考翻译中候选词的分数。通过将单个翻译片段(通常是句子)与一组高质量的参考翻译进行比较来计算分数。然后将这些分数在整个语料库上取平均值,以估计翻译的整体质量。评分时不考虑标点符号或语法正确性。
很少有人工翻译能达到完美的BLEU分数,因为完美的分数表明候选翻译与参考翻译之一相同。因此,没有必要获得满分。鉴于有更多的机会与添加多个参考翻译相匹配,我们鼓励使用一个或多个有助于最大化BLEU分数的参考翻译。
$$P={m\overw_t}$$m:引用中的候选单词数*wt:候选单词的总数。
通常,上述计算会考虑目标中出现的候选单词或单字。然而,为了更准确地评估比赛,可以计算二元图甚至三元图,并将从各种n元图中获得的分数取平均值,以计算整体BLEU分数。
ROUGE
与BLEU评分不同,面向回忆的Gisting评估(ROUGE)评估指标衡量的是回忆。它通常用于评估生成文本的质量和机器翻译任务。然而,由于它衡量的是回忆,所以它被用于总结任务。更重要的是评估模型在这些类型的任务中可以回忆的单词数量。
ROUGE类中最受欢迎的评估指标是ROUGE-N和ROUGE-L:
Rouge-N:测量引用(a)和测试(b)字符串之间匹配的“N元语法”的数量$$精度={\text{在a和b中都找到的n元数}\over\text{b中的n元数来}$$$Recall={\text{a和b都找到的n-元数}-over\text{a中的n-元数来}$Rouge-L:测量参考(a)和测试(b)字符串之间的最长公共子序列(LCS)。$$Precision={LCS(a,b)\over\text{b中的单位数}$$$Recall={LCS(a、b)\over \text{a中的单位数来}$对于Rouge-n Rouge-L:$$F1={2\times\text{Precision}\over-Recall}$$
文本相似性度量
文本相似性度量评估者专注于通过比较文本元素之间的单词或单词序列的重叠来计算相似性。它们可用于为LLM和参考地面真实文本的预测输出生成相似性得分。这些指标还指示了模型对每个相应任务的执行情况。
Levenshtein相似比
Levenshtein相似度是一个用于衡量两个序列之间相似性的字符串度量。该测量基于Levenshtein距离。非正式地说,两个字符串之间的Levenshtein距离是将一个字符串更改为另一个字符串所需的最小单字符编辑次数(插入、删除或替换)。Levenshtein相似度可以使用Levenshten距离值和以下定义中两个序列的总长度来计算:
Levenstein相似性比(简单比):$$Lev.rev.Ratio(a,b)={(|a|+|b|)-Lev.dist(a、b)\over|a|+|b|}$$,其中|a|和|b|是a和b的长度。
从简单Levenshtein相似比中得出了几种不同的方法:
- 部分比率:通过取最短字符串来计算相似度,并将其与较长字符串中相同长度的子字符串进行比较。
- 标记排序比率:通过首先将字符串拆分为单个单词或标记,按字母顺序对标记进行排序,然后将它们重新组合成一个新字符串来计算相似性。然后使用简单比率方法对这个新字符串进行比较。
- 令牌集比率:通过首先将字符串拆分为单个单词或令牌,然后匹配两个字符串之间的令牌集的交集和并集来计算相似性。
语义相似性度量
BERTScore、MoverScore和句子移动器相似性(SMS)指标都依赖于上下文嵌入来衡量两个文本之间的相似性。虽然与基于LLM的指标相比,这些指标的计算相对简单、快速、廉价,但研究表明,它们与人类评估者的相关性较差,缺乏可解释性,固有偏见,对更广泛任务的适应性较差,无法捕捉语言中的细微差别。
两个句子之间的语义相似性是指它们的意义有多紧密相关。为此,首先将每个字符串表示为一个特征向量,以捕获其语义/含义。一种常用的方法是生成字符串的嵌入(例如,使用LLM),然后使用余弦相似性来衡量两个嵌入向量之间的相似性。更具体地说,给定表示目标字符串的嵌入向量(A)和表示参考字符串的嵌入矢量(B),余弦相似度计算如下:
$$ \text{cosine similarity} = {A \cdot B \over ||A|| ||B||}$$
如上所示,该度量测量两个非零向量之间的角度余弦,范围为-1到1。1表示两个向量相同,-1表示它们不同。
无参考指标
无参考(基于上下文)指标为生成的文本生成分数,不依赖于实际情况。评估基于上下文或源文档。其中许多指标是为了应对创建地面实况数据的挑战而开发的。这些方法往往比基于参考的技术更新,反映了随着PTM变得越来越强大,对可扩展文本评估的需求日益增长。这些指标包括基于质量、基于推论、基于事实、基于问答(QA)和基于问题生成(QG)的指标。
- 用于总结的基于质量的指标。这些方法检测摘要是否包含相关信息。SUPERT质量用于衡量摘要与基于BERT的伪参考的相似性,BLANC质量用于衡量两次掩码令牌重建的准确性差异。ROUGE-C是对ROUGE的修改,不需要引用,并使用源文本作为比较的上下文。
- 基于蕴涵的度量。基于蕴涵的度量基于自然语言推理(NLI)任务,对于给定的文本(前提),它确定输出文本(假设)是否包含、矛盾或破坏前提[24]。这有助于检测事实的不一致性。SummaC(摘要一致性)基准、FactCC和DAE(依赖弧蕴涵)指标是检测与源文本事实不一致的一种方法。基于蕴涵的度量被设计为一个带有“一致”或“不一致”标签的分类任务。
- 基于事实、QA和QG的指标。基于事实的指标,如SRLScore(语义角色标签)和QAFactEval,评估生成的文本是否包含与源文本不符的错误信息。基于QA(如QuestEval)和基于QG的指标被用作衡量事实一致性和相关性的另一种方法。
与基于参考的指标相比,无参考指标与人类评估者的相关性有所改善,但将无参考指标用作任务进展的单一衡量标准存在局限性。一些局限性包括对其基础模型输出的偏见和对高质量文本的偏见。
基于LLM的评估器
LLM的卓越能力使其不仅被用于生成文本,还被用作文本的评估者。这些评估器提供了可扩展性和可解释性。
基于提示的评估器
基于LLM的评估者提示LLM对某些文本进行评判。判断可以基于(i)单独的文本(无参考文献),其中LLM正在判断流畅性和连贯性等品质;(ii)生成的文本、原始文本,以及潜在的主题或问题(无参考),其中LLM正在判断一致性和相关性等质量。这些评估提示的一些框架包括原因然后评分(RTS)、多项选择题评分(MCQ)、面对面评分(H2H)和G-Eval(请参阅使用G-Eval评估LLM总结提示的性能页面)。GEMBA是评估翻译质量的指标。
法学硕士评价是一个新兴的研究领域,尚未得到系统的研究。研究人员已经发现了LLM评估者的可靠性问题,如位置偏见、冗长偏见、自我增强偏见、数学和推理能力有限,以及LLM在分配数字分数方面的成功问题。为减轻位置偏差而提出的策略包括多证据校准(MEC)、平衡位置校准(BPC)和人体在环校准(HITLC)。
基于提示的评估器示例
我们可以获取模型产生的输出,并提示模型确定生成的完井质量。使用这种评估方法通常需要以下步骤:
- 从给定的测试集生成输出预测。
- 提示模型在给定参考文本和足够的上下文(例如,评估标准)的情况下,专注于评估输出的质量。
- 将提示输入模型并分析结果。
该模型应该能够在足够的提示和背景下提供分数。虽然GPT-4采用这种评估方法取得了相当好的结果,但仍需要有人在循环中验证模型生成的输出。该模型在涉及应用特定方法评估输出的特定领域任务或情况下可能表现不佳。因此,应根据数据集的性质密切研究模型的行为。请记住,执行基于LLM的评估需要自己的提示工程。下面是NL2Python应用程序中使用的示例提示模板。
文本
You are an AI-based evaluator. Given an input (starts with --INPUT) that consists or a user prompt (denoted by STATEMENT)
and the two completions (labelled EXPECTED and GENERATED), please do the following:
1- Parse user prompt (STATEMENT) and EXPECTED output to understand task and expected outcome.
2- Check GENERATED code for syntax errors and key variables/functions.
3- Compare GENERATED code to EXPECTED output for similarities/differences, including the use of appropriate Python functions and syntax.
4- Perform a static analysis of the GENERATED code to check for potential functional issues, such as incorrect data types, uninitialized variables,
and improper use of functions.
5- Evaluate the GENERATED code based on other criteria such as readability, efficiency, and adherence to best programming practices.
6- Use the results of steps 2-5 to assign a score to the GENERATED code between 1 to 5, with a higher score indicating better quality.
The score can be based on a weighted combination of the different criteria.
7- Come up an explanation for the score assigned to the GENERATED code. This should also mention if the code is valid or not
When the above is done, please generate an ANSWER that includes outputs:
--ANSWER
EXPLANATION:
SCORE:
Below are two example:
# Example 1
--INPUT
STATEMENT = create a cube
EXPECTED = makeCube()
GENERATED = makeCube(n='cube1')
--ANSWER
SCORE: 4
EXPLANATION: Both completions are valid for creating a cubes . However, the GENERATED one differs by including the cube name (n=cube1), which is not necessary.
# Example 2
--INPUT
STATEMENT = make cube1 red
EXPECTED = changeColor(color=(1, 0, 0), objects=["cube1"])
GENERATED = makeItRed(n='cube1')
--ANSWER
SCORE: 0
EXPLANATION: There is no function in the API called makeItRed. Therefore, this is a made-up function.
Now please process the example blow
--INPUT
STATEMENT = {prompt}
EXPECTED = {expected_output}
GENERATED = {completion}
--ANSWER
LLM评估器的输出通常是一个分数(例如0-1),也可以是一个解释,这是我们不一定用传统指标得到的。
LLM嵌入基础度量
最近,LLM的嵌入模型,如GPT3的text-embedding-ada-002,也被用于计算语义相似性的基于嵌入的度量。
LLM生成代码的度量
当使用LLM生成代码时,以下指标适用。
功能正确性
当LLM的任务是用自然语言为特定任务生成代码时,函数正确性评估NL对代码生成任务的准确性。在这种情况下,函数正确性评估用于评估生成的代码是否为给定的输入产生了所需的输出。
例如,为了使用功能正确性评估,我们可以定义一组涵盖不同输入及其预期输出的测试用例。例如,我们可以定义以下测试用例:
Input: 0
Expected Output: 1
Input: 1
Expected Output: 1
Input: 2
Expected Output: 2
Input: 5
Expected Output: 120
Input: 10
Expected Output: 3628800
然后,我们可以使用LLM生成的代码来计算每个输入的阶乘,并将生成的输出与预期的输出进行比较。如果生成的输出与每个输入的预期输出匹配,我们认为测试用例已经通过,并得出结论,LLM在功能上对该任务是正确的。
功能正确性评估的局限性在于,有时为实现生成的代码设置执行环境的成本过高。此外,功能正确性评估没有考虑到生成代码的以下重要因素:
- 可读性
- 可维护性
- 效率
此外,很难定义一套全面的测试用例,涵盖给定任务的所有可能输入和边缘用例。这种困难可能会限制功能正确性评估的有效性。
基于规则的度量
对于特定领域的应用和实验,实现基于规则的度量可能是有用的。例如,假设我们要求模型为给定的任务生成多个完成项。我们可能有兴趣选择输出,以最大限度地提高某些关键字出现在提示中的概率。此外,在某些情况下,整个提示可能没有用——只有关键实体可能有用。创建对生成的输出执行实体提取的模型也可用于评估预测输出的质量。考虑到许多可能性,考虑针对特定领域任务量身定制的自定义、基于规则的指标是一种很好的做法。在这里,我们为NL2Code和NL2NL用例提供了一些广泛使用的基于规则的评估指标的示例:
- 语法正确性:该指标衡量生成的代码是否符合所使用的编程语言的语法规则。可以使用一组检查常见语法错误的规则来评估此指标。常见语法错误的一些例子是缺少分号、变量名不正确或函数调用不正确。
- 格式检查:另一个可用于评估NL2Code模型的指标是生成代码的格式。此指标衡量生成的代码是否遵循一致且可读的格式。可以使用一组规则来评估它,这些规则检查常见的格式问题,如缩进、换行和空白。
- 语言检查:语言检查指标评估生成的文本或代码的编写是否可理解,是否与用户的输入一致。可以使用一组检查常见语言问题的规则来评估此检查,例如不正确的单词选择或语法。
- 关键字存在:此指标衡量生成的文本是否包含自然语言输入中使用的关键字或关键短语。它可以使用一组规则进行评估。这些规则检查是否存在与正在执行的任务相关的特定关键字或关键短语。
自动测试生成
我们还可以使用LLM进行自动测试生成,其中LLM生成各种测试用例,包括不同的输入类型、上下文和难度级别:
- 生成测试用例:正在评估的LLM的任务是解决生成的测试用例。
- 预定义指标:基于LLM的评估系统然后使用预定义的指标(如相关性和流畅性)来衡量模型的性能。
- 比较和排名:将结果与基线或其他LLM进行比较,深入了解模型的相对优势和劣势。
RAG模式的指标
检索增强生成(RAG)模式是提高LLM性能的一种流行方法。该模式涉及从知识库中检索相关信息,然后使用生成模型生成最终输出。检索和生成模型都可以是LLM。RAGAS实现中的以下指标(RAGAS是您的检索增强生成管道的评估框架-见下文)要求每个查询检索上下文,可用于评估检索模型和生成模型的性能:
与生成相关的指标:
- 可信度:衡量生成的答案在给定背景下的事实一致性。如果答案中有任何无法从上下文中推断出来的说法,那么这些说法将受到惩罚。这是使用两步范式完成的,包括根据生成的答案创建语句,然后根据上下文验证每个语句(推理)。它是根据答案和检索到的上下文计算的。答案被缩放到(0,1)范围,其中1是最好的。
- 答案相关性:指回答直接针对特定问题或背景的程度。这并没有考虑到答案的真实性,而是惩罚了问题中冗余信息或不完整答案的存在。它是根据问答计算的。
检索相关指标:
- 上下文相关性:衡量检索到的上下文与问题的相关性。理想情况下,上下文应该只包含回答问题所需的信息。上下文中存在冗余信息会受到惩罚。传达回收管道的质量。它是根据问题和检索到的上下文计算的。
- 上下文回忆:使用带注释的答案作为基础事实来衡量检索到的上下文的回忆。带注释的答案被视为地面实况上下文的代理。它是根据地面实况和检索到的上下文计算的。
实施
- Azure Machine Learning prompt flow: Nine built-in evaluation methods available, including classification metrics.
-
OpenAI Evals: Evals is a framework for evaluating LLMs and LLM systems, and an open-source registry of benchmarks (github.com).
-
RAGAS: Metrics specific for RAG
- 登录 发表评论
- 84 次浏览
Tags
最新内容
- 1 week ago
- 1 week 4 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago