
4 INTREPID框架
所提出的框架背后的思想是将公共文件的数据保护问题建模为二进制文本分类任务。我们语料库中的每个文档都被标记为符合或不符合GDPR标准。图2显示了INTREPID体系结构的示意图。
Fig. 2
From: An AI framework to support decisions on GDPR compliance
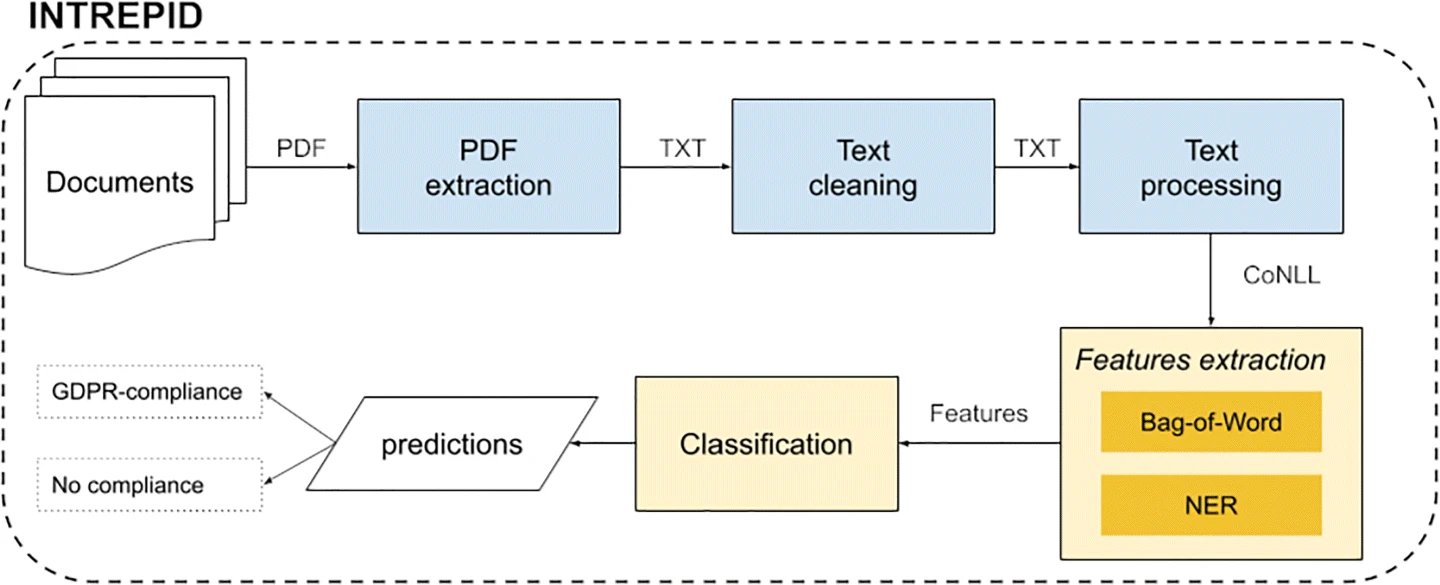
由于语料库是以PDF格式提供的,因此第一步涉及从PDF中提取文本内容。然后,对提取的内容应用清理步骤,以便不删除有效字符并更正OCR错误。为了从PDF中提取文本,我们依赖Apache Tika库;脚注8当PDF中没有直接可用的文本时,我们使用Tesseract.Footnote9软件执行OCR。此外,通过正则表达式发现无效字符。特别是,我们检测非字母数字字符的长序列。NLP管道处理清除的文本。请注意,所提出的框架不依赖于预定义的管道,但可以集成任何可以生成CoNLL格式Footnote10的管道。CoNLL格式是一个文本文件,其中每一行代表一个单词,带有一系列制表符分隔的字段。特别地,句子中的每个记号由与句子中的记号位置相对应的索引(第一列)表示(从1开始)。其他列是管道提取的特征,例如实体识别器的令牌、引理、PoS标签和IOB2标签Footnote11。特别是,在我们的框架中,生成的CoNLL格式必须包括以下文本操作:标记化、旅名化、停止单词删除、PoS标记和实体识别。
在当前版本的框架中,我们为两个NLP管道提供支持:SpaCyFootnote12和Tint(Palmero Aprosio和Moretti,2018)。这种选择的动机是,它们为意大利语提供了最好的支持,不需要进一步的配置或开发步骤。此外,这两个管道都可以轻松地执行实体识别,这是基于命名实体构建特征的核心组件。为了识别依赖领域的实体(健康、管理和省略),我们利用领域专家建立的特定地名录。更详细地说,卫生和行政公报由分别识别医学和行政术语的关键词组成,而省略公报是识别文本中遗漏的语言表达的列表。下一步涉及提取用于分类的特征。在该步骤中,使用CoNLL格式的NLP管道的输出来提取对训练分类器有用的特征。我们利用了两种特征:经典的单词袋(BoW)和基于NER输出的其他特征。我们相信,实体的出现可以帮助分类器检测不符合要求的文档。特征提取步骤的详细说明见第4.1节。提取的特征用于训练分类器,然后用于预测新文档的类别。INTREPID框架可以很容易地进行调整,以支持不同的NLP管道和涉及PA中文本分类的几个任务。
考虑到语料库的小规模和所涉及的特征的数量,在所提出的框架的当前实现中,我们提供了对三个基本分类器的支持:线性支持向量机(Joachims,1998)、随机森林(Breiman,2001)和XGBoost(Chen&Guestrin,2016)。选择这些分类算法是因为各种研究证明它们通常优于几种竞争对手的分类器(Bansal&Kaur,2018;Ghosh等人,2021)。
为了构建最佳分类器并衡量每个特征组的贡献,我们进行了一次评估,其中利用了特征组选择步骤。特别是,我们构建了所有可能的特征组合,并通过使用手动注释的语料库来测试每一个。对于每个组合,我们还选择最佳参数。有关评估的详细信息,请参见第5节。
4.1特征提取
对于特征提取阶段,我们同时考虑基于BoW的特征和基于NER的特征。
4.1.1基于工程量清单的特征
BoW特征模型(Joachims,1998)是NLP中常用的特征生成基本策略。为了表示BoW模型中的每个文本文档,我们首先将文档转换为“单词袋”。然后,我们通过计算词汇表中某个术语出现在文档中的次数来计算BoW词汇表的频率特征。
在所提出的框架中,BoW词汇表中填充了在语料库中至少出现一次的独特单词。我们使用引理化将词汇转换为其基本形式,同时考虑词性上下文(例如,在图1a所示的意大利语文本中,“dichiarato”的基本形式是“dichierare”,而在图1b所示的英语翻译中,“declared”的基本形式是“declare”)。此外,我们使用小写单词来克服大写问题(例如,专有名称“Paolo”小写为“Paolo”)。停止语(即冠词、介词、代词和连词)被删除。
例如,图1a中意大利文本的BoW模型包括以下单词:
|
paolo |
|
rossi |
|
copenaghen |
|
roma |
|
xxxxxx |
|
sclerosi |
|
multipla |
|
roma |
|
... |
BoW特征paolo出现一次,而BoW特征roma在图1a中的意大利语文本中出现两次
4.1.2基于NER的特征
我们考虑了三组基于净入学率的特征。
第1组:命名实体袋(BoNE)
BoNE特征模型扩展了BoW模型,以便生成基于NER的特征。为了表示每个文本文档,我们首先使用NER工具识别文本语料库中的命名实体,将其转换为“命名实体袋”。然后,我们通过计算命名实体类别在文档中出现的次数,从命名实体类别(管理、健康、位置、遗漏、组织和个人)中计算频率特征。
例如,让我们考虑图1a中意大利文本的BoNE模型。它由以下命名实体组成:
|
PERSON |
paolo rossi |
|
LOCATION |
copenaghen |
|
LOCATION |
roma |
|
OMISSIS |
xxxxxxx |
|
HEALTH |
sclerosi multipla |
|
OMISSIS |
xxxxxxx |
|
HEALTH |
fisioterapia |
|
ORGANIZATION |
ragioneria |
|
LOCATION |
roma |
|
PERSON |
maria verde |
BoNE特征是通过计算先前BoNE模型中每个命名实体类别的频率来生成的。在该示例中,我们确定ADMINISTRATION(管理)未出现,HEALTH(健康)出现两次,LOCATION(位置)出现三次,OMISIS(省略)出现两遍,ORGANIZATON(组织)出现一次,PERSON(个人)显示两次。请注意,在所提出的框架的当前版本中,BoNE模型允许我们从每个文档中提取六个特征,每个命名实体类别一个特征。
第2组:命名实体袋双克(BoNNEG)
BoNNEG模型基于将每个文档表示为一袋相邻命名实体(即出现在同一上下文中的相邻实体)的概念。为了表示BoNNEG模型中的每个文本文档,我们首先将文档转换为“一袋命名为实体的邻居”。然后,我们从命名的实体直方图中计算频率特征。让我们考虑命名实体双图X−Y,其中X和Y是NER识别的命名实体类别。当且仅当NER在文本中识别出一个以X命名的实体X和一个以Y命名的实体Y,使得X和Y之间的距离最多为maxd时,双格X−Y才会出现在文档中。该距离通过忽略停止词来计算。在本案例研究中,根据PA文档中相关实体之间预期距离的一些领域知识,将maxd设置为5。
例如,让我们考虑图1a中报告的文件,该文本的BoNNEG模型包括以下邻居命名实体图:
|
PERSON-LOCATION |
paolo rossi-copenhaghen |
d = 1 |
|
PERSON-LOCATION |
paolo rossi-roma |
d = 4 |
|
LOCATION-LOCATION |
copenhaghen-roma |
d = 2 |
|
LOCATION-OMISSIS |
copenhaghen-xxxxxxx |
d = 4 |
|
LOCATION-OMISSIS |
roma-xxxxxxx |
d = 1 |
|
OMISSIS-HEALTH |
xxxxxxx-fisioterapia |
d = 3 |
|
OMISSIS-ORGANIZATION |
xxxxxxx-ragioneria |
d = 5 |
|
HEALTH-ORGANIZATION |
fisioterapia-ragioneria |
d = 1 |
|
HEALTH-LOCATION |
fisioterapia-roma |
d = 3 |
|
HEALTH-PERSON |
fisioterapia-maria verde |
d = 4 |
|
ORGANIZATION-LOCATION |
ragioneria-roma |
d = 1 |
|
ORGANIZATION-PERSON |
ragioneria-maria verde |
d = 2 |
|
LOCATION-PERSON |
roma-maria verde |
d = 0 |
BoNNEG特征是通过计算先前BoNNEG模型中每个命名实体双图的频率来生成的。例如,我们确定,由于名为LOCATION的实体“Copenhaghen”与名为PERSON的实体“Paolo Rossi”相距1个标记,以及名为LOCATION的实体“Roma”与“Paolo-Rosi”相距4个非停止词标记,因此双格PERSON-LOCATION在文本中出现两次(如图3所示)。请注意,BoNNEG模型允许我们从每个文档中提取三十六个特征,每两克命名实体类别一个特征。
Fig. 3
From: An AI framework to support decisions on GDPR compliance
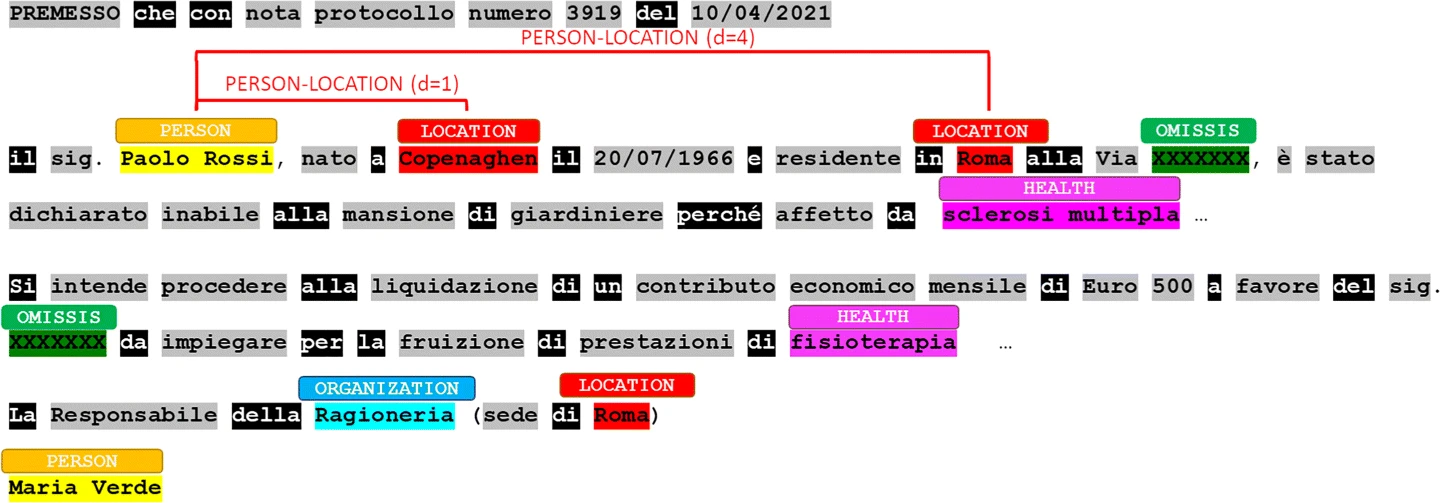
BoNNEG feature PERSON-LOCATION. Stop-words are highlighted in black
第3组:每个命名实体的单词袋(BoWNE)
BoWNE模型从每个文档中提取六个特征,即每个命名实体类别一个特征。为了表示BoWNE模型中的每个文档,我们结合了单词信息和命名实体分类。最后,对于每个命名的实体类别,我们计算在所考虑的类别中命名的不同单词标记的数量,这些标记在文本中至少出现两次。
例如,图1a中报告的文件的BoWNE模型包括以下用命名实体标记的单词袋:
|
paolo rossi/PERSON |
|
copenaghen/LOCATION |
|
roma/LOCATION |
|
xxxxxxx/OMISSIS |
|
sclerosi multipla/HEALTH |
|
xxxxxxx/OMISSIS |
|
fisioterapia/HEALTH |
|
ragioneria/ORGANIZATION |
|
roma/LOCATION |
|
maria verde/PERSON |
BoWNE特征是通过计算每个命名实体类别的重复单词而生成的。因此,在所考虑的示例中,我们确定LOCATION只命名一个在文本中至少出现两次的单词(roma),而ADMINISTRATION、HEALTH、OMISIS、ORGANIZATON和PERSON不命名任何在文本中出现至少两次的词。因此,与LOCATION和OMISIS相关联的BoWNE特征等于1,而分别与ADMINISTRATION、HEALTH、ORGANIZATON和PERSON相关联的BoWNE特征设置为零。
4.2实施细节
该框架是用Python和Java实现的。PDF提取和文本清理是用Java开发的,使用Apache TikaFootnote13库从PDF中提取文本。文本处理模块允许为NLP集成不同的管道。特别是,我们集成了SpaCyFootnote14(Python)和Tint(Palmero Aprosio和Moretti,2018)(Java)。SpaCy提出的模型是在WikiNER语料库上训练的(Nothman et al.,2013),而Tint则利用了意大利内容注释库(I-CAB)(Magnini et al.,2006)。标记化、停止字去除和引理化分别由每个NLP管道执行。
文本处理提供由负责构建BoW和NER特征的特征提取模块处理的CoNLL格式的输出,如第4.1节所述。功能是分类模块的输入,该模块与评估组件一起使用scikit学习工具在Python中开发。对于分类,我们采用了:线性支持向量机(SVM)、随机森林(RF)和XGBoost分类器。这些分类器的参数是通过用k倍(k=5)执行网格搜索来选择的。表3中报告了网格搜索过程中使用的参数和一组值。
Table 3 Parameters and the set of values used during the grid-search
From: An AI framework to support decisions on GDPR compliance
|
Classifier |
Parameters |
|---|---|
|
SVM |
C = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} |
|
RF |
number of estimators = {100, 200, 400, 600, 800} |
|
XGBoost |
learning rate = {0.1, 0.2, 0.3} |
|
max depth = {3, 6, 9} |
|
|
number of estimators = {100, 200, 400} |
最新内容
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago