
在今天的文章中,我将讨论数据架构的演变。是什么促使了体系结构的变化及其对数据计划的影响。我将介绍数据网格,这是最新一代的数据体系结构。如果您还没有订阅,请考虑订阅。
标签:数据架构|数据网格|数据湖|去中心化数据所有权
为什么我们需要数据架构?
成为一个数据驱动的组织仍然是许多公司的首要战略目标之一。数据驱动意味着将数据置于组织中所有决策和过程的中心。
领导者明白,通过超个性化和客户旅程重新设计,通过自动化和机器学习降低运营成本,并了解对高层战略和市场定位至关重要的商业趋势,成为数据驱动是改善客户体验的唯一途径。数据平台为数据的蓬勃发展创造了一个繁荣的环境。
数据平台是组织所有数据的存储库和处理库。它处理数据的收集、清理、转换和应用,以生成业务见解。它有时被称为“现代数据堆栈”,因为数据平台通常由不同供应商(Dbt、Snowflake、Kafka等)支持的多个集成工具组成。
数据平台的主要元素之一是数据架构。数据架构是设计、构建和管理组织数据资产结构的过程。它就像一个用于集成来自不同来源和应用程序的数据的框架。
设计良好的数据架构的主要目标是减少数据孤岛,最大限度地减少数据重复,并提高数据管理过程的整体效率。
随着数据环境在过去几十年中的发展,数据架构也在发展。让我们更详细地了解这种演变。
在新的消费模型的驱动下,分析数据经历了演变,从支持商业决策的传统分析到增强ML的智能产品
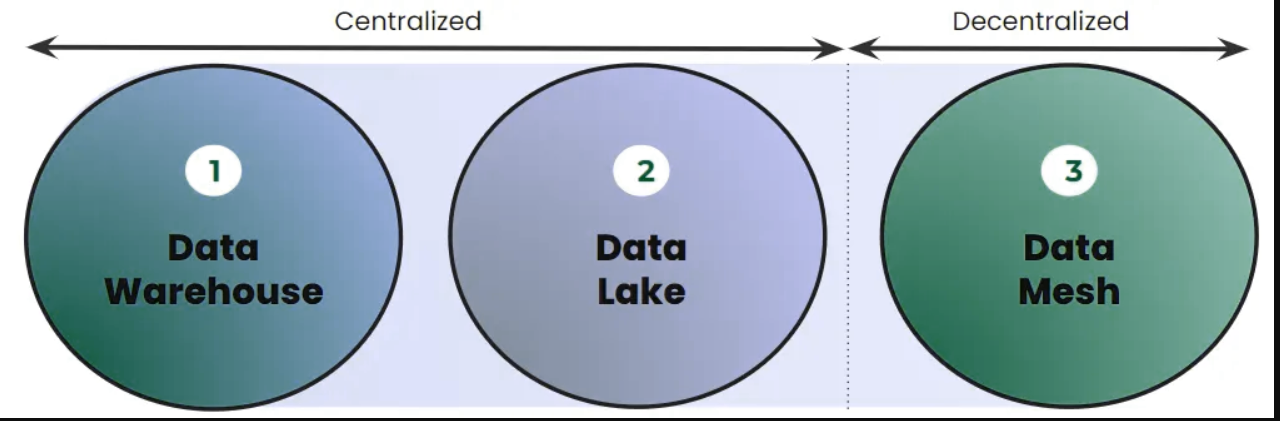
第一代:数据仓库架构
数据仓库架构是由从操作系统(SAP、Salesforce)和第一方数据库(MySQL、SQL Server)到商业智能系统的数据移动定义的。数据仓库是定义模式(雪花模式、星形模式)的中心点,数据将存储在维度和事实表中,使企业能够跟踪和跟踪其运营和客户互动中的变化。数据为:
- 从许多操作数据库和来源中提取
- 转换为以多维和时变表格格式表示的通用模式
- 通过CDC(变更数据捕获)过程加载到仓库表中
- 通过类似SQL的查询访问
- 主要为数据分析师提供报告和分析可视化用例服务
在这种架构风格中,数据集市也开始发挥作用。它们是数据仓库顶部的一个附加层(由一个或多个表组成),以特定的模式格式为特定的部门业务问题提供服务。如果没有数据集市,这些部门将不得不在仓库中探索和创建多个查询,以获得具有所需内容和格式的数据。
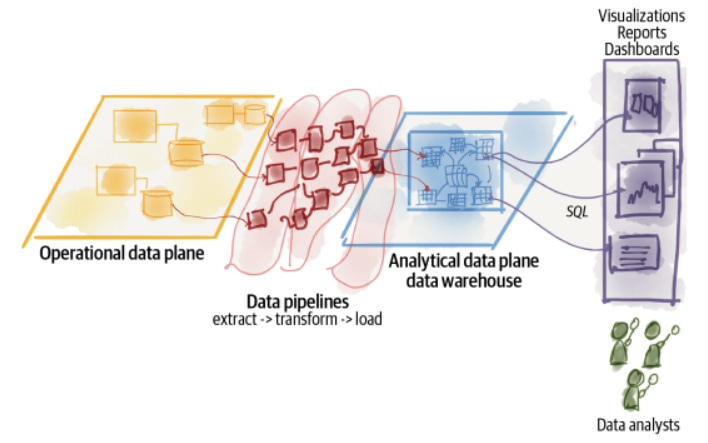
Figure 2 - Data Warehouse Architecture | Source: Data Mesh Book
这种方法的主要挑战:
- 随着时间的推移,成千上万的ETL作业、表和报告被构建出来,只有专门的团队才能理解和维护。
- 不应用现代工程实践,如CI/CD。
- 数据仓库的数据模型和模式设计过于僵化,无法处理来自多个来源的大量结构化和非结构化数据。
这将引导我们进入下一代数据架构。
第二代:数据湖架构
数据湖架构于2010年推出,以应对数据仓库架构在满足数据的新用途方面的挑战:数据科学家在机器学习模型训练过程中访问数据。
数据科学家需要原始形式的数据来进行机器学习(ML)模型训练过程。ML模型还需要大量数据,这些数据很难存储在数据仓库中。
构建的第一个数据湖涉及在Hadoop分布式文件系统(HDFS)中跨一组集群计算节点存储数据。数据将使用MapReduce、Spark和其他数据处理框架进行提取和处理。
数据湖架构在ELT过程中工作,而不是在ETL过程中工作。数据从操作系统中提取(E),并加载(L)到中央存储库中。然而,与数据仓库不同的是,数据湖只需要很少或根本不需要预先对数据进行转换和建模。目标是保持数据接近其原始形式。一旦数据进入湖中,该架构就会通过数据转换管道(T)进行扩展,以对原始数据进行建模,并将其存储在数据仓库或功能存储中。
数据工程团队,为了更好地组织湖泊,创建不同的“区域”。目标是根据清理和转换的程度存储数据,从最原始的数据到数据丰富的步骤,再到最干净、最可访问的数据。
这种数据架构旨在改善数据仓库所需的大量前期建模的无效性和摩擦。前置转换是一个阻碍因素,会导致数据访问和模型训练的迭代速度减慢。

Figure 3 - Data Lake Architecture | Source: Data Mesh Book
这种方法的主要挑战:
- 数据湖架构存在复杂性和恶化,导致数据质量和可靠性较差。
- 由超专业数据工程师组成的中央团队操作的批处理或流式作业的复杂管道。
- 它创建了非托管数据集,这些数据集通常不受信任且不可访问,几乎没有价值
- 数据沿袭和依赖关系很难跟踪
- 没有广泛的前期数据建模会给在不同数据源之间建立语义映射带来困难,从而产生数据沼泽。
第三代:云数据湖架构
从第二代到第三代数据架构的最大变化是向云的切换、实时数据可用性以及数据仓库和数据湖之间的融合。更详细地说:
- 使用Kappa等架构,支持流式传输以实现近乎实时的数据可用性。
- 尝试将数据转换的批处理和流处理与Apache Beam等框架统一起来。
- 完全接受基于云的托管服务,并使用具有独立计算和存储的现代云原生实现。存储数据变得更加便宜。
- 将仓库和lake融合为一种技术,要么扩展数据仓库以包括嵌入式ML训练,要么将数据仓库的完整性、事务性和查询系统构建到数据lake解决方案中。Databricks Lakehouse是一个具有类似仓库的事务和查询支持的传统湖泊存储解决方案的示例。

Figure 4 - From Data Warehouse to Data Lakehouse Architecture (On the right) | Source: Databricks blog
云数据湖正在解决前几代人的一些差距。然而,仍然存在一些挑战:
- 数据湖架构的管理仍然非常复杂,影响数据质量和可靠性。
- 架构设计仍然是集中的,需要一支超专业的数据工程师团队。
- 需要很长时间才能洞察。数据消费者需要等待几个月才能获得用于分析或机器学习用例的数据集。
- 数据仓库不再是通过数据复制真实世界,在探索数据的同时影响数据消费者的体验。
所有这些挑战使我们产生了第四代数据架构,在本文发表时,该架构仍处于早期阶段。
第四代:数据网格架构
数据网格架构是一种相对较新的数据架构方法,旨在解决以前集中式架构中发现的一些挑战。
数据网格为数据架构带来了微服务为单片应用带来的东西。
在数据网格中,数据是分散的,数据的所有权分布在各个域中。每个域都负责其范围内的数据,包括数据建模、存储和治理,架构必须提供一套实践,使每个域能够独立管理其数据。
以下是数据网格架构的关键组件:
- 域-域是一个独立的业务单元,拥有并管理自己的数据。每个域都有明确的业务目的,并负责定义数据建模、实体、模式和策略来管理数据。这一概念不同于为营销或销售等不同团队设计的数据仓库架构中的数据集市。在数据网格架构中,销售可以有多个领域,这取决于团队可能拥有的不同重点/领域。
- 数据产品-数据产品是域产生的最终结果,可供其他域或应用程序使用。每个数据产品都有明确的业务用途。一个域可以处理多个数据产品。并非所有数据资产都将被视为数据产品或应接受数据产品处理(尽管在完美的世界中是这样)。数据产品是在组织中发挥关键作用的数据资产。
- 数据基础设施-数据基础设施包括管理域内数据所需的工具和技术,类似于软件应用程序的容器化微服务。这包括数据存储、处理和分析工具。
- 数据治理-数据治理由每个域管理。这是指管理数据质量、隐私和安全的一套程序。
- 网格API——就像微服务通过HTTP REST API公开所有内容一样,数据网格域将通过定义良好的接口公开所有内容,其他域和数据产品可以使用该接口。

Figure 5 - Data Mesh Architecture. Each domain team performs cross-domain data analysis on its own. The domain ingests operational data, builds analytical data models as data products, and publish them with data contracts to serve other domains’ data needs | Source: datamesh-architecture.com
您可以将数据网格视为当今数据架构设计和数据团队组织方式的范式转变:
- 数据团队成为跨职能团队,专门从事一个或多个业务领域(而非技术),就像软件产品团队非常面向服务一样。
- 每个由一个或多个微服务组成的业务领域都有自己的OLAP数据库和分布式文件存储系统,就像微服务的任何部分都被容器化以独立工作一样。
- 数据产品A将被数据产品B消费,两者都将通过流或REST API与其他数据产品通信,就像应用程序微服务相互通信一样。
- 数据产品API之后将是传统的REST API文档,并且可以通过网格数据目录发现数据产品。
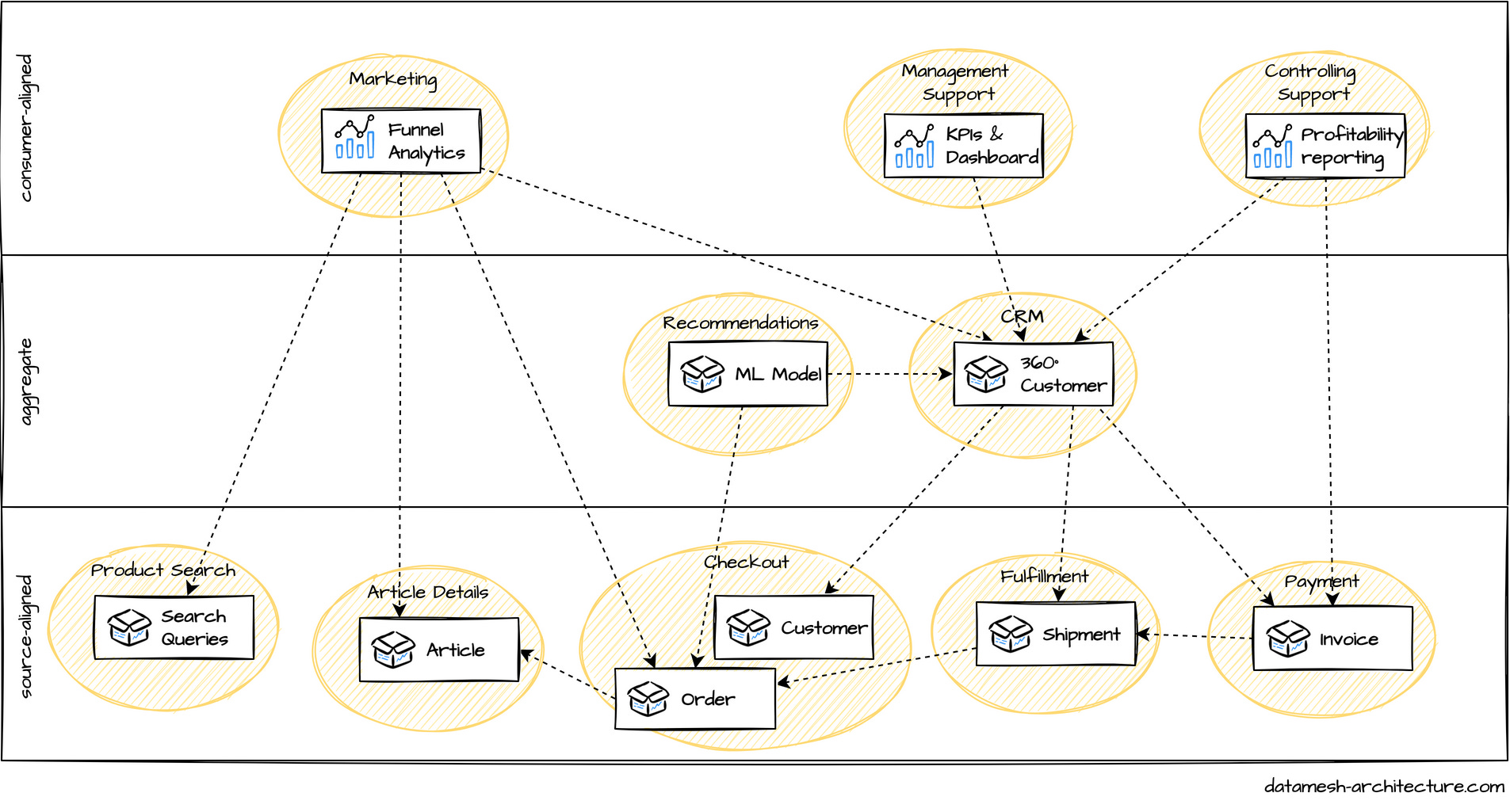
Figure 6: The mesh emerges when teams use other domains’ data products. Upstream domains publish articles, orders, and customer data products that are consumed either upstream by other data products such as shipment, or downstream by ML Models, CRM systems, or Analytics. | Source: datamesh-architecture.com
除了架构之外,数据网格还有什么变化?
数据网格最具影响力的变化是架构。但是,从集中式数据湖转移到去中心化数据网格是一种社会技术现象,这意味着还有一些额外的变化。
如果你还记得的话,从单片应用程序到微服务应用程序的转变使软件工程团队改变了他们的开发生命周期、组织结构、动机、技能和治理。这时,产品经理的角色出现了,以确保应用程序能够解决真正的用户问题。
在应用数据网格架构时也需要发生同样的情况。
在接下来的文章中,我将写更多关于数据网格实现的挑战。
最新内容
- 6 hours ago
- 1 week 6 days ago
- 3 weeks ago
- 3 weeks 4 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago