
category
对大型语言模型(LLM)性能的评估,特别是对各种提示的响应,对于旨在充分利用这一快速发展技术的组织至关重要。引入LLM即法官框架是简化和精简模型评估过程的重要一步。这种方法允许组织使用预定义的指标来评估其人工智能模型的有效性,确保该技术符合其特定的需求和目标。通过采用这种方法,公司可以更准确地衡量其人工智能系统的性能,就模型选择、优化和部署做出明智的决策。这不仅提高了人工智能应用程序的可靠性和效率,还有助于在组织内采用更具战略性和知情性的技术方法。
Amazon Bedrock是一项全面管理的服务,通过一个API提供领先人工智能公司的高性能基础模型,最近推出了两种重要的评估功能:亚马逊Bedrock模型评估下的LLM-as-a-pjudge和亚马逊Bedrock-知识库的RAG评估。这两个功能在幕后都使用了LLM作为评判技术,但评估的内容不同。这篇博客文章探讨了LLM作为亚马逊基岩模型评估的评判者,提供了关于功能设置的全面指导,通过控制台和Python SDK和API评估作业启动,并展示了这一创新的评估功能如何增强包括质量、用户体验、指令遵循和安全在内的多个指标类别的生成性人工智能应用程序。
在我们探讨技术方面和实施细节之前,让我们先来看看使LLM作为亚马逊基岩模型评估的评判者特别强大并将其与传统评估方法区分开来的关键特征。了解这些核心功能将有助于阐明为什么这一功能代表了人工智能模型评估的重大进步。
LLM作为法官的主要特征
- 自动智能评估:LLM-as-a-jester使用预先训练的模型自动评估反应,提供类似人类的评估质量,节省高达98%的成本。该系统将评估时间从数周大幅缩短到数小时,同时在大型数据集中保持一致的评估标准。
- 综合指标类别:评估体系涵盖四个关键指标领域:质量评估(正确性、完整性、忠诚度)、用户体验(有用性、连贯性、相关性)、指令合规性(遵循指令、专业风格)和安全监控(危害性、刻板印象、拒绝处理)。
- 无缝集成:该功能直接与亚马逊基岩集成,并与现有的亚马逊基岩模型评估功能保持兼容。用户可以通过Amazon Bedrock的AWS管理控制台访问该功能,并快速集成其自定义数据集以进行评估。
- 灵活的实施:该系统支持对Amazon Bedrock上托管的模型、自定义微调模型和导入模型进行评估。用户可以通过Amazon Simple Storage Service(Amazon S3)存储桶无缝连接他们的评估数据集,使评估过程简化高效。
- 精心策划的评判模型:Amazon Bedrock提供预选的高质量评估模型,并采用优化的即时工程进行准确评估。用户无需携带外部评判模型,因为亚马逊基岩团队会维护和更新一系列评判模型和相关的评估评判提示。
- 经济高效的扩展:该功能使组织能够大规模进行全面的模型评估,而无需与人工评估相关的传统成本和时间投资。自动化流程保持了高质量的评估,同时显著降低了运营开销。
这些功能创建了一个强大的评估框架,帮助组织在其安全的AWS环境中优化其AI模型性能,同时保持高标准的质量和安全性。
产品概述
现在您已经了解了LLM作为判断者的关键功能,让我们来看看如何在Amazon Bedrock Model Evaluation中实现和使用此功能。本节对架构进行了全面的概述,并逐一介绍了每个组件,演示了它们如何协同工作以提供准确有效的模型评估。
LLM作为亚马逊基岩模型评估的评判者,为评估和优化AI模型性能提供了一个全面的端到端解决方案。这个自动化过程利用LLM的强大功能来评估多个指标类别的响应,提供可以显著改善您的AI应用程序的见解。让我们浏览一下此解决方案的关键组件,如下图所示:
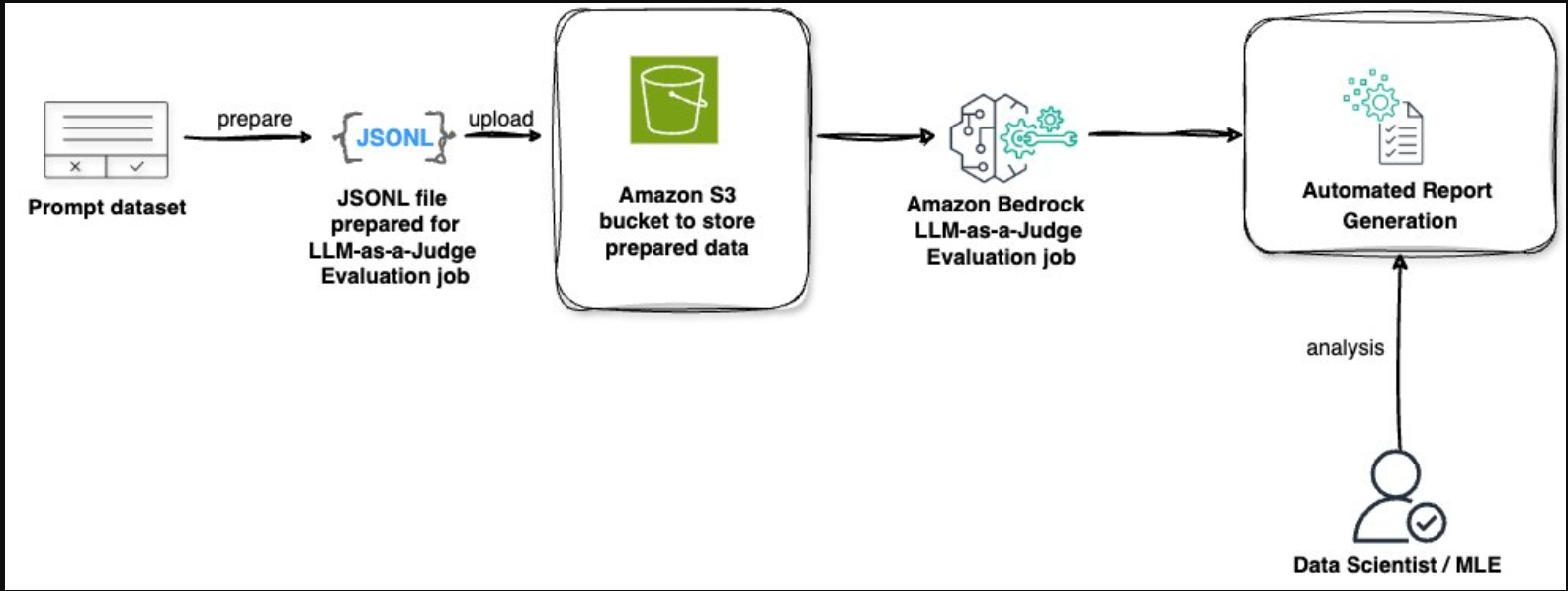
LLM作为亚马逊基岩模型评估的评委,遵循简化的工作流程,实现了系统的模型评估。以下是每个组件在评估过程中如何协同工作:
- 提示数据集:该过程始于一个准备好的数据集,其中包含用于测试模型性能的提示。评估可以在有或没有地面实况响应的情况下进行——虽然包括地面实况提供了额外的比较点,但它完全是可选的,不是成功评估所必需的。
- JSONL文件准备:将提示数据集转换为JSONL格式,该格式是专门为LLM-as-year评估作业构建的。这种格式有助于正确处理评估数据。
Amazon S3存储:将准备好的JSONL文件上传到S3存储桶中,作为评估数据的安全存储位置。 - 评估处理:Amazon Bedrock LLM-as a judger模型评估作业处理存储的数据,对选定的指标类别(包括质量、用户体验、指令遵循和安全)进行全面评估。
- 自动生成报告:完成后,系统生成详细的评估报告,其中包含总体和个人响应级别的指标、分数和见解。
专家分析:数据科学家或机器学习工程师分析生成的报告,以得出可操作的见解并做出明智的决策。
考虑到这种解决方案架构,让我们探讨如何有效地实施LLM-as-year模型评估,确保您从评估过程中获得最有价值的见解。
先决条件
要使用LLM作为评判模型评估,请确保您满足以下要求:
- 一个活跃的AWS帐户。
- 在Amazon Bedrock中启用了选定的评估器和生成器模型。您可以在Amazon Bedrock控制台的模型访问页面上确认为您的帐户启用了模型。
- 确认模型可用的AWS区域和配额。
- 完成与AWS身份和访问管理(IAM)创建相关的模型评估先决条件,并为S3存储桶添加访问和写入输出数据的权限。
- 您还需要在S3存储桶上设置并启用CORS。
- 如果您对生成器模型使用自定义模型而不是按需模型,请确保在推理过程中有足够的配额来运行Provisioned Throughput。
- 完成导入自定义模型的先决条件。
- 转到AWS服务配额控制台,检查以下配额:
- 模型单位无承诺跨自定义模型提供吞吐量。
- [您的自定义模型名称]的每个配置模型的模型单位。
- 这两个字段都需要有足够的配额来支持您的Provisioned Throughput模型单元。如有必要,请求增加配额,以适应您预期的推理工作量。
准备输入数据集
在为LLM即判断模型评估作业准备数据集时,每个提示都必须包含特定的键值对。以下是必填和可选字段:
- prompt(必填):此键表示各种任务的输入。它可用于模型需要提供响应的一般文本生成、模型必须回答特定问题的问答任务、模型需要总结给定文本的文本摘要任务,或模型必须对提供的文本进行分类的分类任务。
- referenceResponse(用于具有基本事实的特定指标):此键包含基本事实或正确答案。如果提供了模型,它将作为评估模型响应的参考点。
- category(可选):此键用于生成按类别报告的评估分数,帮助组织和细分评估结果以进行更好的分析。
数据集要求:
每一行都必须是有效的JSON对象
文件必须使用JSONL格式
数据集应存储在Amazon S3存储桶中
示例JSONL格式,不带背景真相(类别是可选的):
{
"prompt": "What is machine learning?"
"category": "technical"
}
{
"prompt": "Summarize climate change impacts",
"category": "environmental"
}
Example JSONL format with ground truth (category is optional):
{
"prompt": "What is machine learning?",
"referenceResponse": "Machine learning is a subset of artificial intelligence that enables systems to learn and improve from experience without being explicitly programmed. It uses algorithms and statistical models to analyze and draw inferences from patterns in data, allowing computers to perform specific tasks without explicit instructions.",
"category": "technical"
}
{
"prompt": "Summarize climate change impacts",
"referenceResponse": "Climate change leads to rising global temperatures, extreme weather events, sea level rise, and disruption of ecosystems. These changes result in more frequent natural disasters, threats to food security, loss of biodiversity, and various public health challenges. The impacts affect agriculture, coastal communities, and vulnerable populations disproportionately.",
"category": "environmental"
}
使用控制台启动LLM即判断模型评估作业
You can use LLM-as-a-judge on Amazon Bedrock Model Evaluation to assess model performance through a user-friendly console interface. Follow these steps to start an evaluation job:
- In the Amazon Bedrock console, choose Inference and Assessment and then select Evalutaions. On the Evaluations page, choose the Models

- Choose Create and select Automatic: LLM-as-a-judge.
- Enter a name and description and select an Evaluator model. This model will be used as a judge to evaluate the response of a prompt or model from your generative AI application.

- Choose Tags and select the model to be used for generating responses in this evaluation job.

- Select the metrics you want to use to evaluate the model response (such as helpfulness, correctness, faithfulness, relevance, and harmfulness).

- Select the S3 URI for Choose a prompt dataset and for Evaluation results. You can use the Browse S3 option.

- Select or create an IAM service role with the proper permissions. This includes service access to Amazon Bedrock, the S3 buckets in the evaluation job, and the models being used in the job. If you create a new IAM role in the evaluation setup, the service will automatically give the role the proper permissions for the job. Specify the output S3 bucket and choose Create.

- You will be able to see the evaluation job is In Progress. Wait for the job status to change to Complete.

- When complete, select the job to see its details. The following is the metrics summary (such as 0.83 for helpfulness, 1.00 for correctness, 1.00 for faithfulness, 1.00 for relevance, and 0.00 for harmfulness).

- To view generation metrics details, scroll down in the model evaluation report and choose any individual metric (like helpfulness or correctness) to see its detailed breakdown.

- To see each record’s prompt input, generation output, ground truth, and individual scores, choose a metric and select “Prompt details”. Hover over any individual score to view its detailed explanation.

使用Python SDK和API启动LLM即判断评估作业
To use the Python SDK for creating an LLM-as-a-judge model evaluation job, use the following steps. First, set up the required configurations:
import boto3
from datetime import datetime
# Generate unique name for the job
job_name = f"Model-evaluation-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
# Configure your knowledge base and model settings
evaluator_model = "mistral.mistral-large-2402-v1:0"
generator_model = "amazon.nova-pro-v1:0"
role_arn = "arn:aws:iam::<YOUR_ACCOUNT_ID>:role/<YOUR_IAM_ROLE>"
# Specify S3 locations for evaluation data and output
input_data = "s3://<YOUR_BUCKET>/evaluation_data/input.jsonl"
output_path = "s3://<YOUR_BUCKET>/evaluation_output/"
# Create Bedrock client
bedrock_client = boto3.client('bedrock')要创建LLM即评判模型评估作业,请执行以下操作:
def create_llm_judge_evaluation(
client,
job_name: str,
role_arn: str,
input_s3_uri: str,
output_s3_uri: str,
evaluator_model_id: str,
generator_model_id: str,
dataset_name: str = None,
task_type: str = "General" # must be General for LLMaaJ
):
# All available LLM-as-judge metrics
llm_judge_metrics = [
"Builtin.Correctness",
"Builtin.Completeness",
"Builtin.Faithfulness",
"Builtin.Helpfulness",
"Builtin.Coherence",
"Builtin.Relevance",
"Builtin.FollowingInstructions",
"Builtin.ProfessionalStyleAndTone",
"Builtin.Harmfulness",
"Builtin.Stereotyping",
"Builtin.Refusal"
]
# Configure dataset
dataset_config = {
"name": dataset_name or "CustomDataset",
"datasetLocation": {
"s3Uri": input_s3_uri
}
}
try:
response = client.create_evaluation_job(
jobName=job_name,
roleArn=role_arn,
applicationType="ModelEvaluation",
evaluationConfig={
"automated": {
"datasetMetricConfigs": [
{
"taskType": task_type,
"dataset": dataset_config,
"metricNames": llm_judge_metrics
}
],
"evaluatorModelConfig": {
"bedrockEvaluatorModels": [
{
"modelIdentifier": evaluator_model_id
}
]
}
}
},
inferenceConfig={
"models": [
{
"bedrockModel": {
"modelIdentifier": generator_model_id
}
}
]
},
outputDataConfig={
"s3Uri": output_s3_uri
}
)
return response
except Exception as e:
print(f"Error creating evaluation job: {str(e)}")
raise
# Create evaluation job
try:
llm_as_judge_response = create_llm_judge_evaluation(
client=bedrock_client,
job_name=job_name,
role_arn=ROLE_ARN,
input_s3_uri=input_data,
output_s3_uri=output_path,
evaluator_model_id=evaluator_model,
generator_model_id=generator_model,
task_type="General"
)
print(f"✓ Created evaluation job: {llm_as_judge_response['jobArn']}")
except Exception as e:
print(f"✗ Failed to create evaluation job: {str(e)}")
raise
要监控评估作业的进度,请执行以下操作:
# Get job ARN based on job type
evaluation_job_arn = llm_as_judge_response['jobArn']
# Check job status
check_status = bedrock_client.get_evaluation_job(jobIdentifier=evaluation_job_arn)
print(f"Job Status: {check_status['status']}")您还可以比较多个基础模型,以确定哪一个最适合您的需求。通过在所有比较中使用相同的评估器模型,您将获得一致的基准测试结果,以帮助确定用例的最佳模型。
def run_model_comparison(
generator_models: List[str],
evaluator_model: str
) -> List[Dict[str, Any]]:
evaluation_jobs = []
for generator_model in generator_models:
job_name = f"llmaaj-{generator_model.split('.')[0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
try:
response = create_llm_judge_evaluation(
client=bedrock_client,
job_name=job_name,
role_arn=ROLE_ARN,
input_s3_uri=input_data,
output_s3_uri=f"{output_path}/{job_name}/",
evaluator_model_id=evaluator_model,
generator_model_id=generator_model,
task_type="General"
)
job_info = {
"job_name": job_name,
"job_arn": response["jobArn"],
"generator_model": generator_model,
"evaluator_model": evaluator_model,
"status": "CREATED"
}
evaluation_jobs.append(job_info)
print(f"✓ Created job: {job_name}")
print(f" Generator: {generator_model}")
print(f" Evaluator: {evaluator_model}")
print("-" * 80)
except Exception as e:
print(f"✗ Error with {generator_model}: {str(e)}")
continue
return evaluation_jobs
# Run model comparison
evaluation_jobs = run_model_comparison(GENERATOR_MODELS, EVALUATOR_MODEL)
LLM作为评判的相关性分析
You can use the Spearman’s rank correlation coefficient to compare evaluation results between different generator models using LLM-as-a-judge in Amazon Bedrock. After retrieving the evaluation results from your S3 bucket, containing evaluation scores across various metrics, you can begin the correlation analysis.
Using scipy.stats, compute the correlation coefficient between pairs of generator models, filtering out constant values or error messages to have a valid statistical comparison. The resulting correlation coefficients help identify how similarly different models respond to the same prompts. A coefficient closer to 1.0 indicates stronger agreement between the models’ responses, while values closer to 0 suggest more divergent behavior. This analysis provides valuable insights into model consistency and helps identify cases where different models might produce significantly different outputs for the same input.
import json
import boto3
import numpy as np
from scipy import stats
def read_and_organize_metrics_from_s3(bucket_name, file_key):
s3_client = boto3.client('s3')
metrics_dict = {}
try:
response = s3_client.get_object(Bucket=bucket_name, Key=file_key)
content = response['Body'].read().decode('utf-8')
for line in content.strip().split('\n'):
if line:
data = json.loads(line)
if 'automatedEvaluationResult' in data and 'scores' in data['automatedEvaluationResult']:
for score in data['automatedEvaluationResult']['scores']:
metric_name = score['metricName']
if 'result' in score:
metric_value = score['result']
if metric_name not in metrics_dict:
metrics_dict[metric_name] = []
metrics_dict[metric_name].append(metric_value)
return metrics_dict
except Exception as e:
print(f"Error: {e}")
return None
def get_spearmanr_correlation(scores1, scores2):
if len(set(scores1)) == 1 or len(set(scores2)) == 1:
return "undefined (constant scores)", "undefined"
try:
result = stats.spearmanr(scores1, scores2)
return round(float(result.statistic), 4), round(float(result.pvalue), 4)
except Exception as e:
return f"error: {str(e)}", "undefined"
# Extract metrics
bucket_name = "<EVALUATION_OUTPUT_BUCKET>"
file_key1 = "<EVALUATION_FILE_KEY1>"
file_key2 = "<EVALUATION_FILE_KEY2>"
metrics1 = read_and_organize_metrics_from_s3(bucket_name, file_key1)
metrics2 = read_and_organize_metrics_from_s3(bucket_name, file_key2)
# Calculate correlations for common metrics
common_metrics = set(metrics1.keys()) & set(metrics2.keys())
for metric_name in common_metrics:
scores1 = metrics1[metric_name]
scores2 = metrics2[metric_name]
if len(scores1) == len(scores2):
correlation, p_value = get_spearmanr_correlation(scores1, scores2)
print(f"\nMetric: {metric_name}")
print(f"Number of samples: {len(scores1)}")
print(f"Unique values in Model 1 scores: {len(set(scores1))}")
print(f"Unique values in Model 2 scores: {len(set(scores2))}")
print(f"Model 1 scores range: [{min(scores1)}, {max(scores1)}]")
print(f"Model 2 scores range: [{min(scores2)}, {max(scores2)}]")
print(f"Spearman correlation coefficient: {correlation}")
print(f"P-value: {p_value}")
else:
print(f"\nMetric: {metric_name}")
print("Error: Different number of samples between models")LLM作为法官实施的最佳实践
您还可以比较多个基础模型,以确定哪一个最适合您的需求。通过在所有比较中使用相同的评估器模型,您将获得一致、可扩展的结果。以下最佳实践将帮助您在比较不同的基础模型时建立标准化的基准测试。
- 创建代表真实用例和边缘用例的多样化测试数据集。对于大型工作负载(超过1000个提示),使用分层抽样来保持全面覆盖,同时管理成本和完成时间。包括简单和复杂的提示,以测试不同难度级别的模型能力。
- 选择与您的特定业务目标和应用程序要求相一致的评估指标。平衡质量指标(正确性、完整性)和用户体验指标(有用性、连贯性)。在部署面向客户的应用程序时包括安全指标。
- 在比较不同模型时,保持一致的评估条件。在标准化基准测试的比较中使用相同的评估器模型。记录您的评估配置和参数,以确保可重复性。
- 安排定期评估作业,以跟踪模型性能随时间的变化。监控不同指标类别的趋势,以确定需要改进的领域。为每个指标设置绩效基线和阈值。
- 根据您的评估需求和成本限制优化批量大小。考虑使用较小的测试集进行快速迭代,使用较大的集进行综合评估。平衡评估频率和资源利用率。
- 维护评估工作的详细记录,包括配置和结果。跟踪模型性能随时间的改进和变化。记录基于评估见解所做的任何修改。可选的职位描述字段可以在这里为您提供帮助。
- 使用评估结果指导模型选择和优化。实施反馈循环,持续改进及时工程。根据新出现的需求和用户反馈定期更新评估标准。
- 设计您的评估框架以适应不断增长的工作负载。在添加更多模型或用例时,为增加的复杂性做好计划。考虑定期评估任务的自动化工作流程。
这些最佳实践有助于在Amazon Bedrock上使用LLM作为评判建立一个强大的评估框架。如需深入了解这些实践的科学验证,包括案例研究和与人类判断的相关性,请继续关注我们即将发布的技术深度博客文章。
结论
LLM作为亚马逊基岩模型评估的评委代表了自动化模型评估的重大进步,为组织提供了一个强大的工具来系统地评估和优化他们的人工智能应用程序。该功能将自动评估的效率与通常与人工评估相关的细致理解相结合,使组织能够扩展其质量保证流程,同时保持高标准的性能和安全性。
全面的指标类别、灵活的实施选项以及与现有AWS服务的无缝集成,使组织能够建立随需求增长的稳健评估框架。无论您是在开发会话式人工智能应用程序、内容生成系统还是专门的企业解决方案,LLM-as-a-chester都能提供必要的工具,以确保您的模型符合技术要求和业务目标。
我们提供了从初始设置到最佳实践的详细实施指南,以帮助您有效地使用此功能。本文中附带的代码示例和配置示例演示了如何在实践中实现这些评估。通过系统评估和持续改进,组织可以构建更可靠、准确和值得信赖的人工智能应用程序。
我们鼓励您探索Amazon Bedrock控制台中的LLM即法官功能,并了解自动评估如何增强您的AI应用程序。为了帮助您入门,我们准备了一个Jupyter笔记本,其中包含您可以在我们的GitHub存储库上找到的实际示例和代码片段(https://github.com/aws-samples/amazon-bedrock-samples/tree/main/evaluat…)。
- 登录 发表评论
- 44 次浏览
最新内容
- 3 days 14 hours ago
- 1 week 4 days ago
- 2 weeks 1 day ago
- 2 months ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago
- 5 months 4 weeks ago