
category
LLM评估是质量检查,有助于确保你的AI产品做它应该做的事情,无论是编写代码还是处理支持票。
它们与基准测试不同:你在任务上测试你的系统,而不仅仅是比较模型。从测试到实时监控,您需要在整个AI产品生命周期中进行这些检查。
本指南侧重于自动化LLM评估。我们将介绍适用于从摘要到聊天机器人等用例的指标和方法。我们的目标是给你一个概述,这样你就可以很容易地为你遇到的任何LLM任务选择正确的方法。
有关实际代码示例,请查看开源Evidently库和Quickstart文档。
TL;DR
- LLM评估方法分为两种主要类型:基于参考和无参考。
- 基于参考的LLM评估方法使用精确匹配、单词重叠、嵌入相似性或LLM作为判断,将响应与已知的地面真实答案进行比较。对于分类和排名(在RAG中很常见),有特定任务的质量指标。
- 无需参考的LLM评估方法通过智能体指标和自定义标准,使用正则表达式、文本统计、程序验证、自定义LLM判断和基于ML的评分来评估输出。
- LLM作为法官是最受欢迎的方法之一。它提示LLM根据自定义标准对输出进行评分,并可以处理对话级别的评估。
LLM评估是如何工作的
如果你是LLM评估的新手,请查看本介绍指南。它涵盖了为什么评估很重要,并分解了核心工作流程。这里是一个快速回顾:
- LLM评估有助于评估系统在能力和安全方面是否表现良好。
- 由于LLM是非确定性的,并且具有独特的故障模式,因此这是一个持续的过程。例如,您可以在每次更改提示时运行evals。
- 手动查看LLM输出是理想的,但不可扩展,因此您需要自动化。
自动化LLM评估工作流程有两个部分。首先,您需要数据:这可能是合成示例、精心策划的测试用例,也可能是LLM应用程序中的真实日志。其次,你需要一种评分方法。这可能会返回一个通过/失败、一个标签或一个数字分数,告诉您输出是否正确。最终,你总是会得到一些指标,但有很多方法可以达到它。
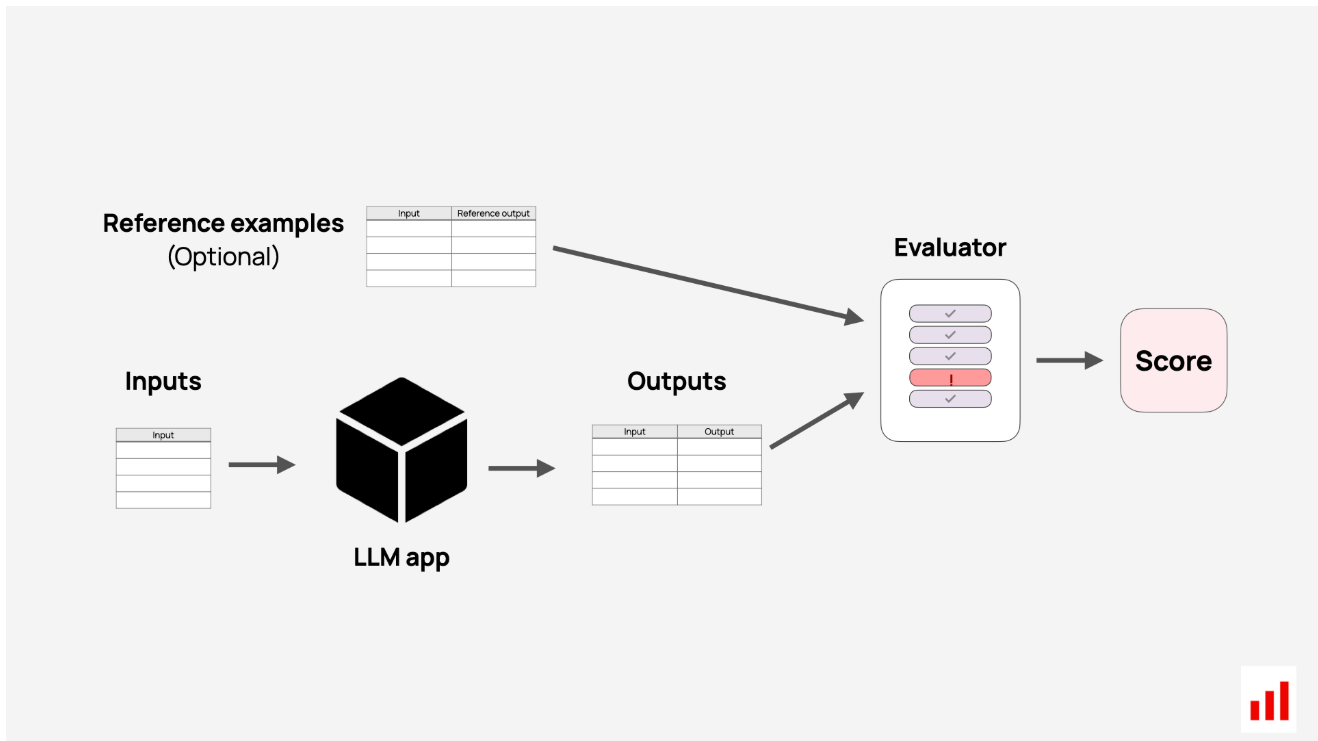
这个LLM评估过程表面上看起来很简单,但很快就会变得混乱。每个用例都有不同的任务、数据结构和“好”的定义。你究竟是如何进行这种自动评分的?
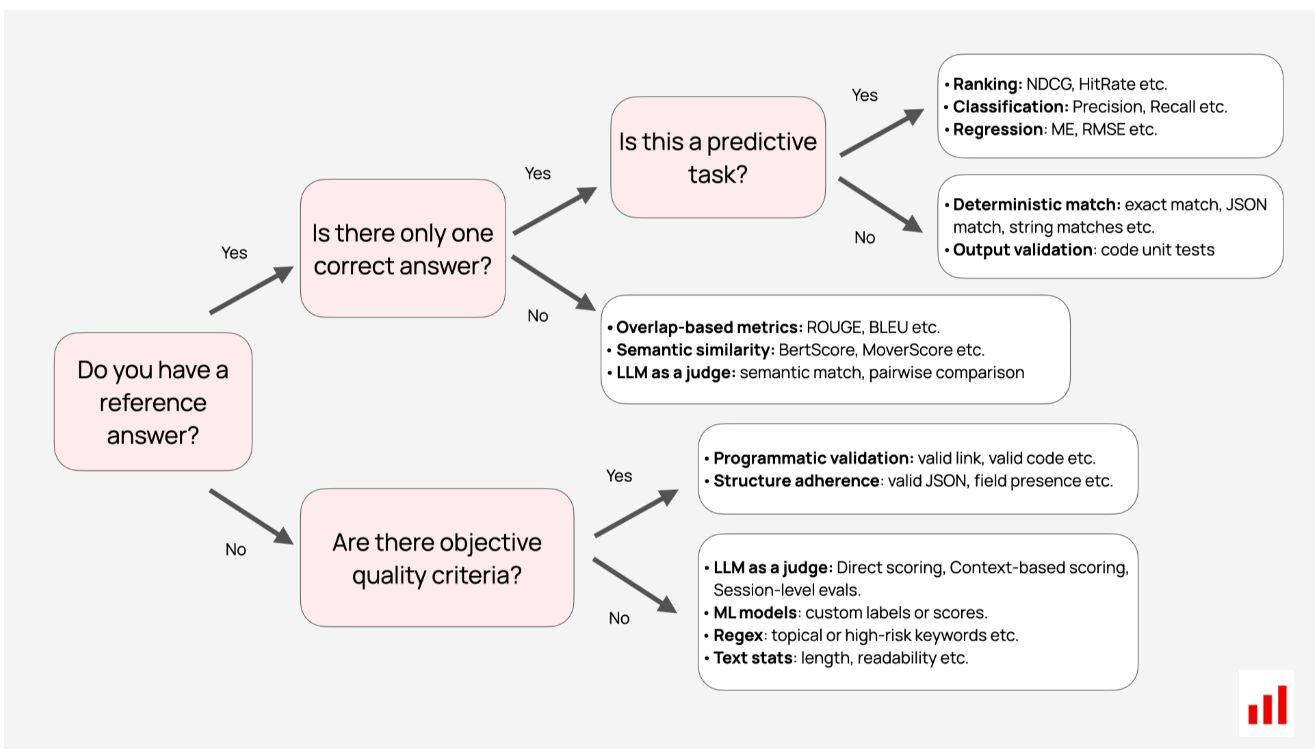
你有参考例子吗?
要选择正确的方法和指标,您首先需要确定LLM评估场景。它们分为两个主要部分:
- 基于参考:将输出与预定义答案进行比较。
- 无需参考:您可以直接评估输出。
基于参考的LLM评估将输出与已知答案进行比较,通常称为“基本事实”。一旦你创建了这个测试数据集,你的工作就是衡量新的LLM输出与这些已知答案的匹配程度。技术范围从精确匹配到语义比较。

虽然在你已经知道的东西上测试系统可能看起来很奇怪,但这给出了一个明确的目标。当你迭代你的LLM应用程序时,你可以跟踪它变得更好(或更差)的程度。
无需参考的LLM评估不需要预定义的答案。相反,他们根据智能体指标或音调、结构或安全性等特定品质来评估输出。
这适用于创建地面实况数据困难或不切实际的任务,如聊天机器人对话或创意写作。它也是实时监控的理想选择,您可以实时对响应进行评分。这里的一种常见方法是LLM作为判断,在这种方法中,您会提示LLM从各个维度评估输出,比如问:“这个回答有帮助吗?”

无参考文献评估:直接对回答进行评分。
一些LLM评估方法,如LLM评委,在这两种情况下都很有效。然而,许多指标仅限于基于参考的场景,这使得这种区分很有用。
有一个正确的答案吗?
即使你有参考示例,一个重要的问题是每个输入是否都有一个正确答案。如果是这样,您可以使用直接的、确定性的检查。如果你得到了你所期望的,很容易比较。
当LLM处理预测性任务时,您还可以依赖既定的机器学习指标。这比看起来更频繁地出现!即使你的系统没有预测性,它的一部分也可能是。例如,分类器可能会检测聊天机器人中的用户意图,或者你可能会解决RAG系统的排名问题。这两个任务都有多个评估指标可供选择。
然而,你并不总是有一个“完美”的答案。在翻译、内容生成或摘要中,有多个有效的输出,精确匹配是行不通的。相反,你需要像语义相似性这样的比较方法来处理变化。
类似的情况也适用于无参考的LLM评估。有时,您可以使用客观检查,如运行生成的代码以查看其是否有效或验证JSON密钥。但在大多数情况下,你会处理开放式LLM评估。因此,你需要找到量化主观品质或提出智能体指标的方法。
这是一个用于导航不同方法的决策树。我们将在下面解释每个选项。
数据集级评估
让我们来谈谈另一个区别:数据集级别与输入级别的评估。
一些指标自然适用于整个数据集。例如,精度或F1分数等分类指标汇总了所有预测的结果,并为您提供了一个单一的质量指标。你可以根据最重要的因素选择不同的指标,比如专注于最小化某些类型的错误。
相比之下,LLM特定的评估方法通常会单独评估每个响应。例如,您可以使用LLM判断或计算每个输出的语义相似性。但是,没有内置的机制将这些分数组合成一个单一的绩效指标。如何在测试集或实时响应中汇总结果取决于您。
有时很简单:平均分数或计算有多少输出被标记为“好”。但在其他情况下,您可能需要额外的步骤。例如,数字平均值并不能告诉你有多少个单独的坏输出。为了解决这个问题,你可以先设置一个阈值,比如将语义相似度低于0.85的任何响应标记为“不正确”。
您还可以运行复合检查,对每个响应评估多个标准,例如评估其语气、长度和相关性。然后,每个输入都可以得到多个描述符。

为了避免淹没在指标中,定义明确的测试条件是有帮助的。例如,您可以设置以下质量阈值:
- 任何产出的情绪都不应低于零。
- 不超过80%的回复可以超过一定的长度。
- 不到5%的输出应该是无关的。
通过将LLM评估分解为这些结构化测试,您可以更好地理解每次评估运行的结果。如果出了什么问题,你会知道具体在哪里。
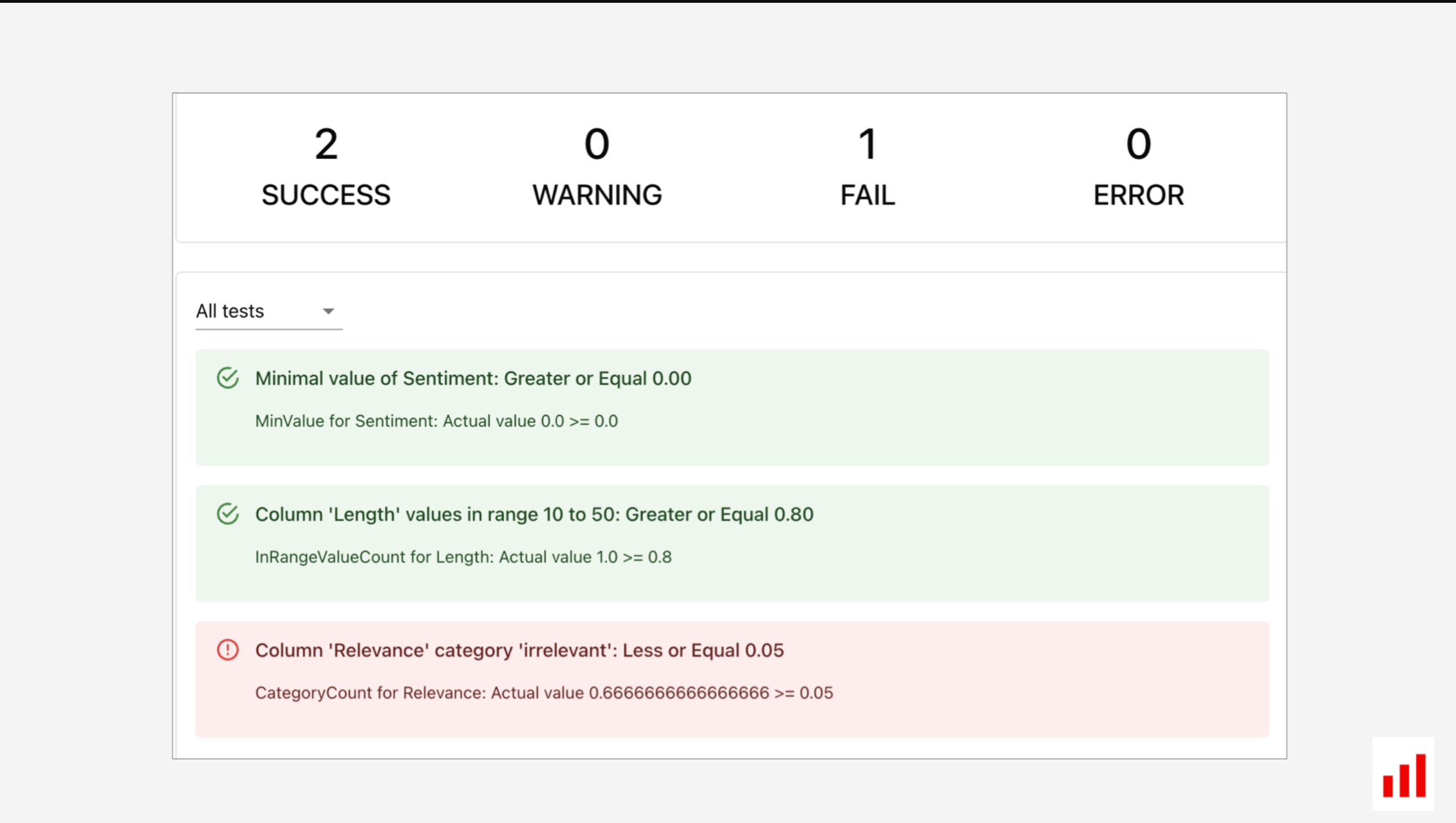
您可以使用Evidently Python库运行这些检查并获得可导出的报告。
LLM评估方法
最后,让我们继续讨论LLM评估方法!我们将根据您是否需要地面实况数据来分解它们,并逐一介绍方法。每个部分都是独立的,所以你可以跳到你最感兴趣的部分。
以下是所有方法概览:

基于参考的评估
基于参考的LLM评估非常适合实验。当您测试不同的提示、模型或配置时,您需要一种跟踪进度的方法。否则,你只是盲目地尝试想法。对测试集进行重复检查可以帮助您了解随着时间的推移,您是否正确地完成了更多的事情。
在LLM回归测试中,同样的方法可以帮助您确认更新不会破坏已经工作的东西或引入新的错误。
评估过程本身很简单:
- 通过系统传递您的测试输入。
- 生成新的输出。
- 将它们与参考答案进行比较。
但有一点需要注意:你的LLM评估只与测试数据集一样好。你必须投入工作——标记一些数据,创建合成示例,或从生产日志中提取。数据集需要多样化,并在发现新的用户场景或问题时保持最新。如果它太小太简单,评估不会告诉你太多。
分类指标
TL;DR:这些LLM评估指标有助于量化二进制和多类分类等任务的示例数据集的性能。
分类是关于预测每个输入的离散标签。这通常作为较大工作流中的一个组件出现,但LLM也可以直接处理它们。一些例子:
- 意图检测。将聊天机器人查询分为“退货”或“付款”等类别。
- 智能体路由。根据用户输入预测正确的下一步。
- 支持票分类。按紧急程度(如高、中、低)或主题(如技术问题、账单)标记门票。
- 内容审核。标记违反政策的内容,如垃圾邮件或脏话。
- 查看标记。将反馈标记为正面、负面或中性。
每个任务都有预定义的类别,系统需要将每个输入分配给其中一个类别,如果允许使用多个标签,则有时需要分配给多个类别。为了评估性能,您需要检查系统是否在一组不同的输入中选择了正确的类。
例如,假设你正在测试一个聊天机器人意图检测器。您首先准备一个包含用户问题及其正确类别的测试集。然后,你必须通过你的人工智能应用程序运行这些问题,并将其预测与实际标签进行比较。

这里的一个直观指标是准确度,它告诉你有多少分类是正确的。然而,这并不总是最好的措施。
想象一下,你将查询分类为“安全”或“不安全”,以避免提供个人财务建议等危险情况。在这种情况下,您将更多地关注:
- 回想一下:“我们抓到所有不安全的输入了吗?”
- 精度:“有多少标记的查询是真正不安全的?”
这两个指标都给出了一个平衡的观点。比如说,高回忆率可能表明你捕捉到了所有糟糕的输出。但是,如果精度低,则会错误地标记太多无害的查询。这不是一个好的用户体验!
您可能还需要每类指标。例如,在内容审核中,你的系统可能会完美地检测到“冒犯性语言”,但会错过很多“垃圾邮件”。当你有多个类别时,只跟踪整体准确性可能会掩盖这种不平衡。
以下是关键分类指标的快速总结:
| Metric | Description |
|---|---|
| Accuracy | Proportion of correctly classified examples. |
| Precision | Proportion of true positives out of all predicted positives. |
| Recall | Proportion of true positives out of all actual positives. |
| F1-Score | Harmonic mean of precision and recall. |
| Per-class metrics | Precision, recall, and F1-scores for each class. |
度量描述
- 正确分类示例的准确率。
- 准确度所有预测阳性中的真阳性比例。
- 召回真实阳性占所有实际阳性的比例。
- F1分数精确度和召回率的调和平均值。
- 每节课的精确度、召回率和F1分数。
这些指标是传统机器学习评估的核心。有很多关于他们利弊的材料。例如,请查看我们的指南,了解精度-召回率权衡和按类别分类的指标。
排名指标
TL;DR:这些指标通过评估系统对相关结果的排名来衡量检索(包括RAG)和推荐等任务的性能。
当我们谈论排名任务时,我们通常指的是搜索或推荐,这两者在LLM应用程序中都很重要。
- 搜索(检索)是RAG中的“R”。例如,聊天机器人可能需要搜索支持数据库以查找相关内容。它检索文档或上下文块并对其进行排名,然后LLM使用它们来生成答案。LLM还可以重写查询,帮助用户更容易地找到他们需要的东西(就像Picnic为电子商务所做的那样)。如果您正在使用RAG,我们有一个单独的RAG评估指南。
- 建议有一个相似的目标——返回一个排序的选项列表——但重点不同。他们的目标不是找到一些精确的答案,而是为用户提供许多好的选择供其探索。这可能是电子商务网站上的“你也可能喜欢”屏蔽,也可能是像LinkedIn上那样提前输入搜索建议。
在这两种情况下,每个项目(文档、产品、块等)都可以标记为相关或不相关,为绩效评估创造基本事实。
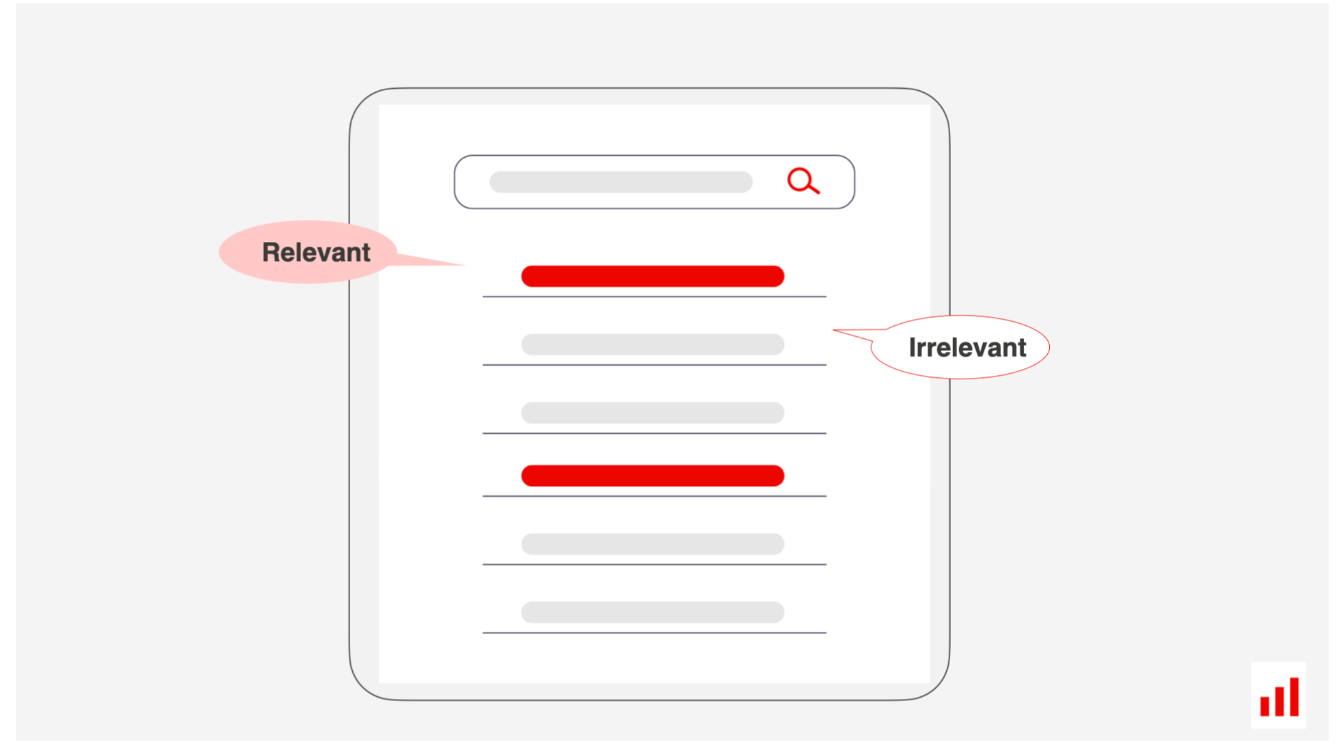
有趣的是,LLM本身可以通过为查询项对分配分数来帮助生成这些相关性标签。(Thomas等人,2024)。它们还可以帮助生成RAG评估的基本事实问题-回答对。
一旦你有了地面实况数据,你就可以评估系统性能。排名指标分为两种主要类型:
- 与排名无关的指标侧重于是否检索到相关项目,而不管其顺序如何。(系统是否找到了它应该找到的项目?)
- 排名感知指标考虑项目顺序,奖励在顶部附近显示相关结果的系统。
例如,像NDCG这样的指标评估相关性和排名顺序,为列表顶部附近的项目分配更多权重。相比之下,命中率检查是否至少找到了一个正确答案,即使它排在最后。
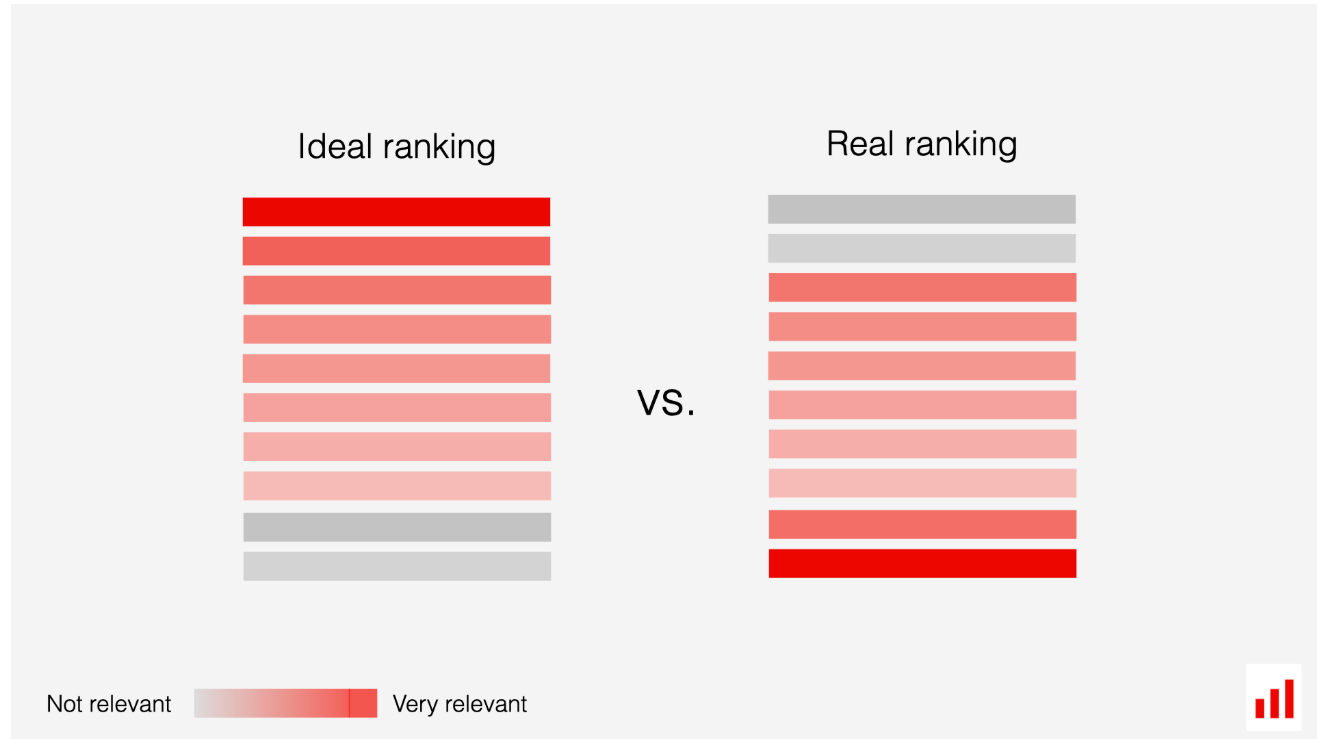
NDCG奖励物品的正确顺序。
评估通常针对前K名的结果(例如前5名或前10名),因为系统通常会检索到许多项目,但只显示或使用少数项目。例如,HitRate@5衡量至少一个相关结果出现在前5名中的频率。
以下是一些常用的排名指标:
| Metric | Description |
|---|---|
| Precision @k | Proportion of top-K items that are relevant. |
| Recall @k | Proportion of all relevant items retrieved within the top-K results. |
| Normalized Discounted Cumulative Gain (nDCG@K) | Measures ranking quality, giving higher weight to relevant items ranked near the top. |
| Hit Rate @K | Binary metric that checks if at least one relevant item appears in the top-K. |
| Mean Reciprocal Rank (MRR@K) | Average of the reciprocal ranks of the first relevant item for all queries in top-K. |
在推荐系统中,多样性、新颖性和偶然性等额外指标评估用户体验。这些指标检查建议是否多样、新颖和不重复。
排名指标解释者。查看此入门级指南,深入了解。
确定性匹配
TL;DR:只要你能编写代码来验证输出是否正确。
分类和排名是具有明确定义的指标的狭义任务的例子。但在其他情况下,你可以有一个正确答案,或者接近正确答案的答案。例如:
- 编程
- 数据提取
- 窄问答
- 智能体工作流中的各个步骤
在这些情况下,您可以执行确定性匹配,以编程方式检查输出,类似于软件单元测试。但是对于LLM,正确回答一个问题并不意味着其他问题都是正确的,因此您需要各种测试输入来确保良好的覆盖率。
想象一下,测试一个从招聘广告中提取信息的系统,比如识别职位。(OLX做了类似的事情)。您可以在输出和预期结果之间进行精确匹配,也可以进行模糊匹配来处理微小的变化,如格式或大小写。
如果输出结构为JSON,如{“job role”:“AI engineer”,“min_experience_yrs”:“3”},您还可以匹配JSON键值对。
如果你处理狭义的问答,你可以用预期的关键字构建一个基本事实数据集。例如,“法国首都是什么?”的答案应始终包含“巴黎”。然后,您可以检查每个答案是否包含正确的单词,而无需进行全文匹配。

在压力测试中,您可能会将所有输出与预期单词或短语的单个列表进行比较。例如,如果你想让聊天机器人避免提及竞争对手,你可以创建具有挑战性的提示,并测试响应是否包含预期的拒绝词。
您可以在其他场景中应用类似的非模糊检查。例如,您可以验证AI智能体是否调用了正确的工具,或者脚本交互是否导致了已知的结果,例如检索特定的数据库条目。
对于编码任务,您并不总是期望与参考完全匹配,但您可以找到其他方法来验证正确性。例如,准备文字单元测试。GitLab在评估他们的Copilot系统时使用了这一点:他们故意引入故障,然后检查模型是否可以生成修复错误并通过测试的代码。
| Method | Description |
|---|---|
| Exact Match | Check if the response exactly matches the expected output. |
| Fuzzy Match | Allows for minor variations, such as ignoring whitespace or formatting. |
| Word or Item Match | Verifies if the response includes specific fixed words or strings, regardless of full phrasing. |
| JSON match | Matches key-value pairs in structured JSON outputs. |
| Unit test pass rate | Tracks whether generated code passes predefined test cases. |
要获得单个LLM评估指标,您可以跟踪总体通过率或按场景组织测试用例,以获得更详细的见解。
基于重叠的指标
TL;DR:使用单词、项目或字符重叠来比较回答。
到目前为止,我们主要关注有单一正确结果的受限任务。但是许多LLM应用程序生成自由格式的文本。在这些情况下,您可能有一个示例响应,但不会期望与之精确匹配。
例如,在总结财务报告时,您可能会将每个新的摘要与人类编写的“理想”摘要进行比较。但是有很多方法可以传达相同的信息,所以许多只有部分匹配的摘要仍然很好。
为了解决这个问题,机器学习研究界提出了基于重叠的指标。它们反映了引用和生成的响应之间有多少共享符号、单词或单词序列。
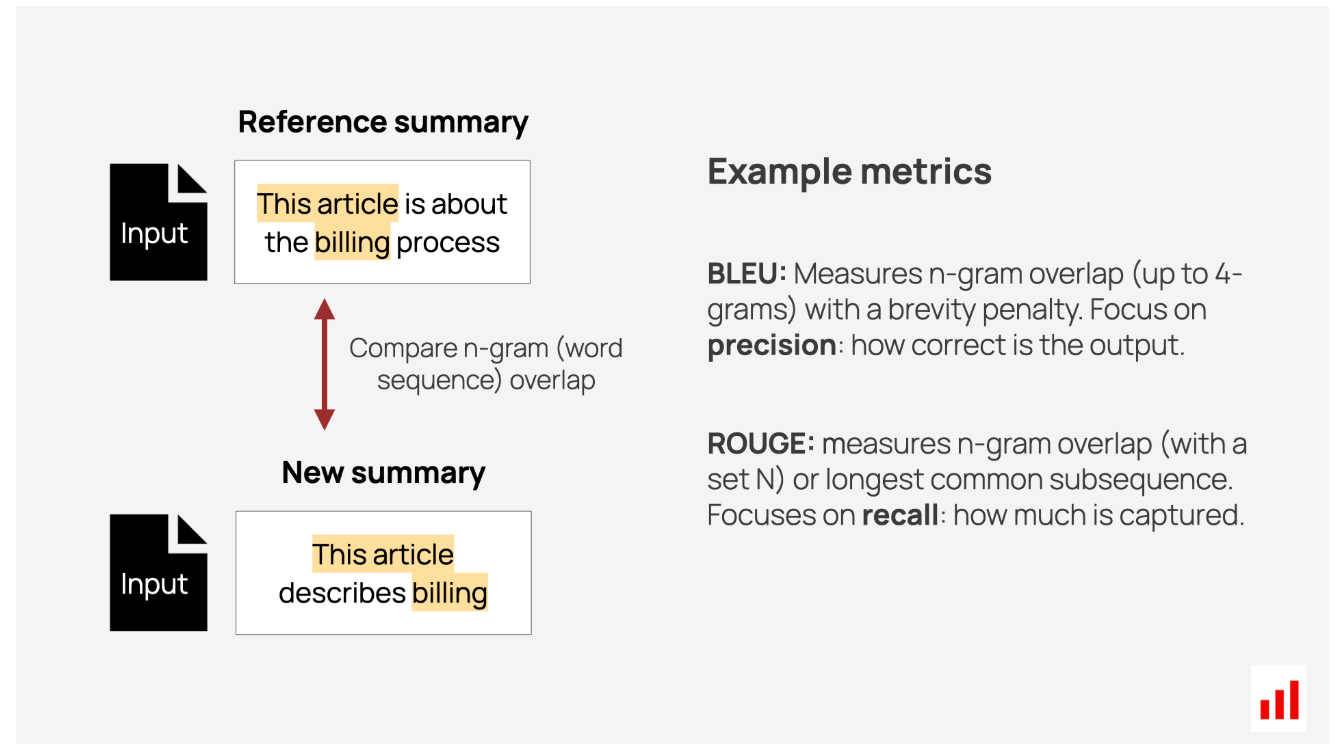
以下是一些示例:
- BLEU评分是为机器翻译开发的,但也用于其他语言任务。它评估n元语法(短单词序列)的重叠,并反映精度:生成的响应中出现在参考中的单词比例。它还应用了简短惩罚来阻止过短的回复。
- ROUGE最初是为总结而设计的,其工作原理类似,但强调回忆,衡量生成的响应中存在多少参考文本。
- METEOR执行单词级匹配,但也使用外部语言词典考虑同义词和词根形式。
- 还有一些指标侧重于重叠字符,如Levenstein距离。
通常使用平均值来总结多个示例的分数,但也可能存在差异,例如为整个示例数据集重新计算BLEU或ROUGE。
| Method | Description |
|---|---|
| BLEU (Bilingual Evaluation Understudy) | Evaluates n-gram overlap (up to 4). Focuses on precision; penalizes brevity. |
| ROUGE-n (Recall-Oriented Understudy for Gisting Evaluation) | Evaluates the specified n-gram overlap. Focuses on recall. |
| ROUGE-l (Recall-Oriented Understudy for Gisting Evaluation) | Evaluates the longest common subsequence between generated and reference texts. Focus on recall. |
| METEOR (Metric for Evaluation of Translation with Explicit ORdering) | Evaluates the word overlap, accounting for synonyms and stemming. Balances precision and recall. |
| Levenstein distance | Calculates the number of character edits (insertions, deletions, or substitutions) needed to match two strings. |
但问题是:虽然基于重叠的指标是NLP研究的基础,但它们往往与人类的判断不太相关,也不适合非常开放的任务。现代替代方案,如基于嵌入式或LLM的评估,提供了更多的情境感知评估。
语义相似性
TL;DR:使用预先训练的嵌入模型进行语义匹配。
基于精确匹配和重叠的指标都会比较单词和响应元素,但它们不考虑它们的含义。但这正是我们经常关心的!
考虑这两个聊天机器人的响应:
- 是的,我们接受购买后的产品退货。
- 当然,您可以在购买后将商品退回。
大多数人类读者会同意这些大致相当。然而,基于重叠的指标不会,因为它们之间共享的单词很少。
语义相似性方法有助于比较意义而不是单词。他们使用像BERT这样的预训练模型,其中许多是开源的。这些模型将文本转化为向量,捕捉单词之间的上下文和关系。通过比较这些向量之间的距离,你可以了解文本到底有多相似。
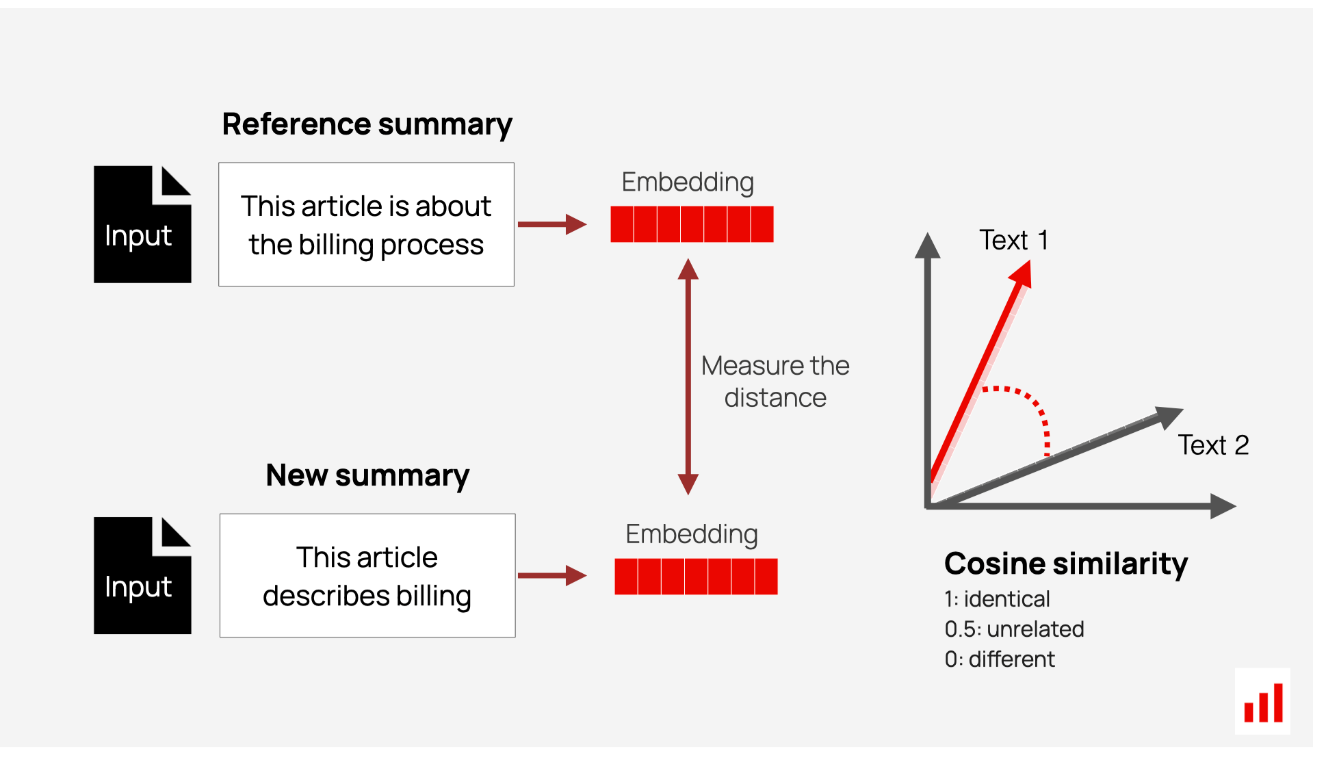
一些流行的方法包括:
- BERTScore使用BERT嵌入将生成文本中的每个标记与引用中的标记进行比较,计算这些比较的余弦相似度。然后,它汇总分数以提供精确度、召回率或F1。
- MoverScore以BERTScore为基础,量化文本之间的上下文差异。它使用地球移动器距离(Wasserstein距离)来衡量将一个文本转换为另一个文本需要多少“工作”。
- COMET是为机器翻译而设计的,不仅需要参考翻译,还需要源文本。它还使用一个在人类评估数据集上预先训练的单独模型来预测翻译的好坏。
您还可以直接实现语义相似性:选择一个嵌入模型(例如,在句子级别工作的模型),将文本转换为向量,并测量余弦相似性。
为了汇总结果,您可以查看平均值或定义一个截止阈值,并计算具有足够高相似性的匹配份额。如果你有有有意义的元数据(比如问答数据集中的主题),你也可以计算特定类别的分数。
| Method | Description |
|---|---|
| BERTScore | Compares token-level embeddings using cosine similarity. Focuses on precision, recall, or F1. |
| MoverScore | Measures Earth Mover’s Distance (EMD) between embedded texts and returns a similarity score. |
| COMET | Evaluates translations by comparing embeddings of source, reference, and generated text. |
| Direct implementation | Measure Cosine Similarity using the chosen embeddings model. |
这些LLM评估方法的局限性在于,它们完全取决于您使用的嵌入模型。它可能无法很好地捕捉到意义的细微差别,并且可能会出现错误匹配。只关注象征或句子层面的比较有时也会错过单词段落的更广泛背景。
LLM作为法官
TL;DR:促使LLM比较答案或选择最佳答案。
虽然进行语义匹配(“这两个响应是否意味着同一件事?”)通常是目标,但基于嵌入的相似性并不总是最精确的选择。嵌入可以捕捉总体思路,但会遗漏重要细节。例如:
- 在联系支持人员之前,请重新启动设备。
- 重新启动设备之前,请联系支持人员。
尽管顺序改变了意义,但这些句子的嵌入向量可能看起来仍然相似。或者考虑:
- 点击菜单中的“帐户”页面。
- 点击菜单中的“帐户详细信息”页面。
在这种情况下,特定菜单项的正确命名对于确定准确性至关重要,但基于嵌入的检查不会对此造成足够的惩罚。为了获得更好的结果,您可以使用LLM作为相似性匹配的判断标准。
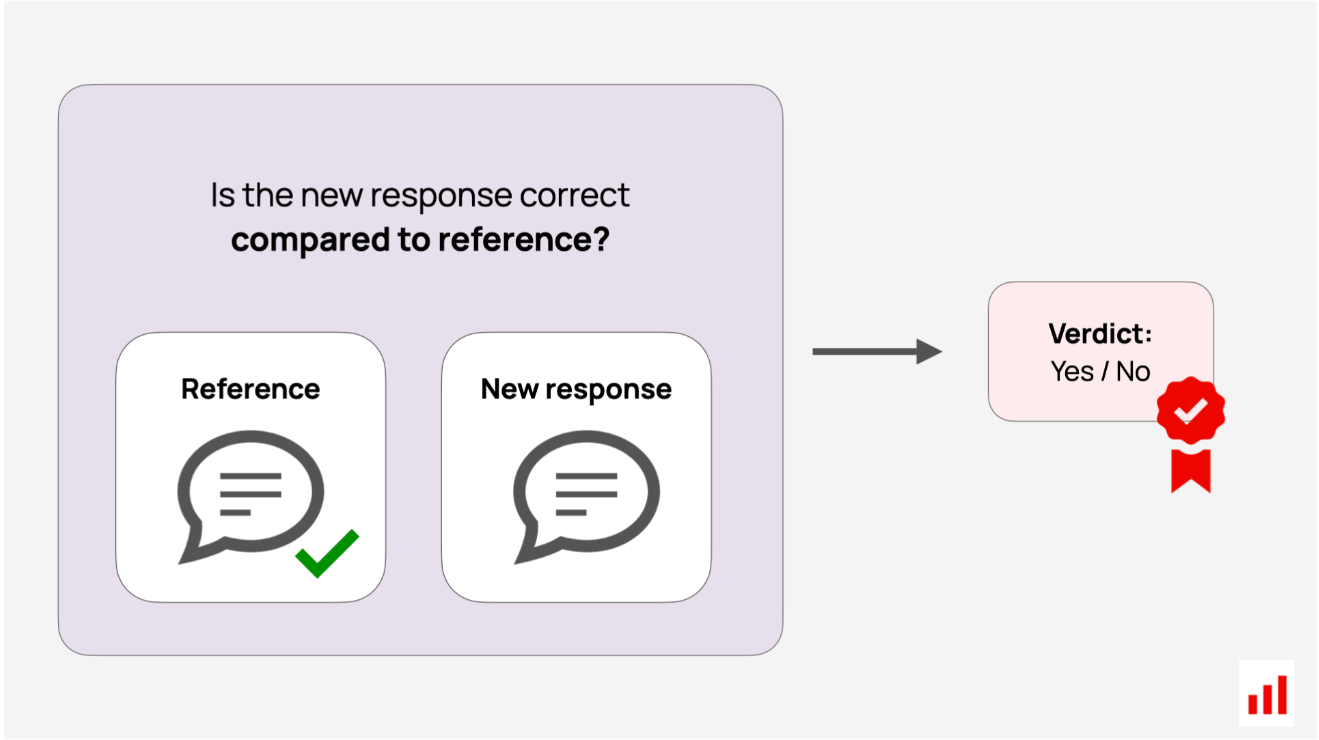
这个过程与你在产品中使用LLM的方式很接近——除了这里,任务是一个狭义的分类。例如,你可以向LLM传递一个参考和新的回复,并问:“回复是否传达了与参考相同的含义?是或否”。
这种方法适应性很强。您可以指定匹配中的优先顺序,例如精确的术语、遗漏或风格一致性。你也可以要求LLM解释它的推理。这使得结果更容易解析,并提高了评估的质量。
例如,您可以分别评估这两个答案在事实和风格上是否匹配。

这种LLM评估方法在实践中得到了广泛的应用。例如,segment描述了他们如何使用基于LLM的匹配来比较生成的查询。基于提示的评估也证明了其可用于翻译(见Kocmi等人,2023)。
使用LLM的另一种方法是通过成对比较,你给LLM两个答案,让它确定哪个更好。这就是“LLM作为法官”这一绰号的由来(见郑等人,2023)。
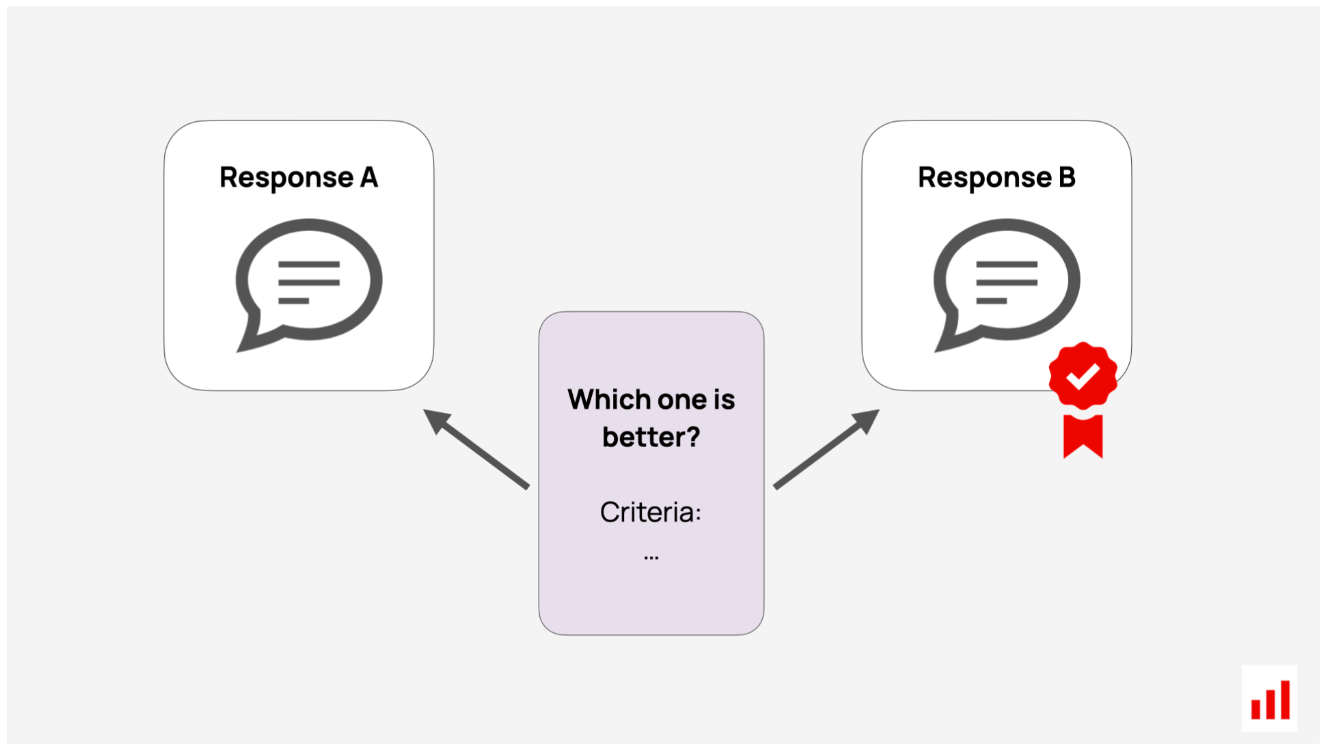
| Method | Description |
|---|---|
| Similarly matching | Use an LLM to compare two responses to determine if they convey the same meaning, style, or details. |
| Pairwise comparison | Use an LLM to choose the best of two responses or declare a tie based on specified criteria. |
这两种方法都可能需要调整以匹配您的偏好:LLM评委需要自己的评估!特别是成对比较也可能有偏见——LLM可能更倾向于更长或更精细的反应或与自己相似的输出。
无参考价值评估
如果无法匹配两个答案,请使用无参考的评估。这适用于:
- 生产LLM监控:实时、持续的检查和护栏。
- 多回合任务:很难设计参考的聊天机器人或智能体。
- 微调标准:评估语气、风格或其他主观品质。
高容量评估:在大型合成数据集上测试响应安全性或格式遵守等标准。
在这些情况下,您可以衡量自定义质量或使用智能体指标——可量化的属性,从简单的文本长度开始,说明输出的一些有用信息。
值得注意的是,虽然我们经常将“平均有用性”等检查称为LLM质量指标,但它们没有像NDCG或精度那样严格的数学定义。你可以根据你的用例定制它们的实现,这就是大部分工作的地方。
你可以应用的LLM评估方法是一致的。让我们把它们分解!
正则表达式
TL;DR。跟踪单词和模式的频率,如主题或有风险的关键字。
正则表达式是检查文本中特定关键字、短语或结构的简单方法。虽然它们看起来很基本,但它们也可能非常有用。
例如,您可以使用正则表达式来跟踪竞争对手或产品的提及情况。每个通常是一个有限的实体列表,因此很容易定义和标记它们出现的频率。
您还可以跟踪主题关键字。比如说,如果你有一个旅行聊天机器人,你可以搜索“取消”、“退款”或“更改预订”等词,以查看它处理取消的频率。为了简化设置此类eval,您可以使用LLM来头脑风暴单词列表,并使用自动处理同一词根变体的库。
您还可以通过检查高风险关键字来标记对话。例如:
- 在订阅服务聊天中查找“取消”或“投诉”等词语。
- 设置亵渎过滤器以捕捉辱骂性语言。
- 通过监控“忽略指令”等短语来检测基本的越狱尝试

正则表达式还可以捕获重复的错误模式。一些LLM会生成预设响应,如“作为AI语言模型”或经常以“当然!”开头。您可以在回归测试期间设置正则表达式检查来捕捉这些响应。同样,拒绝模式(例如,“对不起”或“我不能”)很容易跟踪,因为模型经常重复使用相同的措辞。
正则表达式也有助于结构检查。如果您的输出需要特定的元素(例如,生成的报告中的标题或免责声明),字符串匹配可以确认所有部分都存在。
一旦定义了模式,正则表达式就可以有效地扫描大型数据集。它快速可靠,不需要外部API调用。此外,它在一个原本不可预测的领域中增加了一种受欢迎的确定性——如果模式存在,正则表达式将检测到它。
以下是您可以实施的LLM评估指标的示例:
| Example metric | Description |
|---|---|
| Share of responses containing a topic | Measures how often responses include topic-related keywords. |
| Share of responses with high-risk keywords | Track risky phrases or profanity. |
| Competitor, product and brand mentions | Count competitor or product name mentions. |
| Verbatim error occurrence | Detect errors or refusal patterns. |
| Structure adherence | Verify that responses contain required sections or disclaimers. |
也就是说,正则表达式有其局限性。它本质上是严格的,这意味着除非你明确定义,否则它不会发现拼写错误或变体。您需要仔细设计和维护您的模式定义,以涵盖所有可能的输出。
文本统计
TL;DR。跟踪单词或句子计数等统计数据。
您通常可以将质量与可测量的文本特征联系起来。例如,文本长度对于生成社交媒体帖子、帮助文章或摘要等任务很重要——输出应该简洁但仍然有意义。有时,长度要求会直接写入提示中,比如:“给一句话外卖”。
单词和句子计数等检查快速、廉价且易于实施,使其在每个阶段都很有用。在LLM回归测试中:所有输出都在预期范围内吗?在LLM监控中:平均、最小或最大长度是多少?个别异常值通常会发出问题的信号,比如包含越狱的较长提示。
您还可以探索可读性得分等指标。这些提供了理解文本所需的教育水平的粗略估计。如果您正在生成年轻受众或非母语人士可以访问的内容,这将非常有用。
还有其他统计数据需要考虑,比如非字母字符数。它们并不总是像现在这样有用,但如果情况发生变化,它们可以发出良好的信号。例如,非词汇词的突然增加可能表明垃圾邮件、模型行为变化或需要调查的自动攻击。
| Example metric | Description |
|---|---|
| Word, sentence, or symbol count | Tracks if output meets length requirements. |
| Non-letter character count | Measure the proportion of symbols, special characters or punctuation. |
| Language detection or share of non-vocabulary words | Detect the language of the text or the share of texts not belonging to this language. |
| Stopword ratio | Track the share of filler words like "the" or "is”. |
| Readability scores (like Flesch-Kincaid) | Assess how easy or difficult the text is to read based on sentence and word complexity. |
| Named entity count | Tracks mentions of key entities (e.g., names, locations). |
确定性验证
TL;DR。验证代码或JSON生成等任务的格式和结构。
除了正则表达式和文本统计之外,还有其他程序检查。如果你的LLM生成结构化内容,如SQL、代码、JSON,或与API和数据库交互,你通常可以编写代码来验证至少部分正确性。
这些检查侧重于格式、结构或功能。举几个例子:
- 检查响应格式。如果您要求JSON、SQL或XML,请验证响应是否符合正确的语法。
- 确保必填字段存在。例如,在提取了产品详细信息的JSON中,检查product_name、price和in_stock等键。
- 验证内容。确认提取的电子邮件与电子邮件模式匹配,或者提供的链接指向可访问的网页。
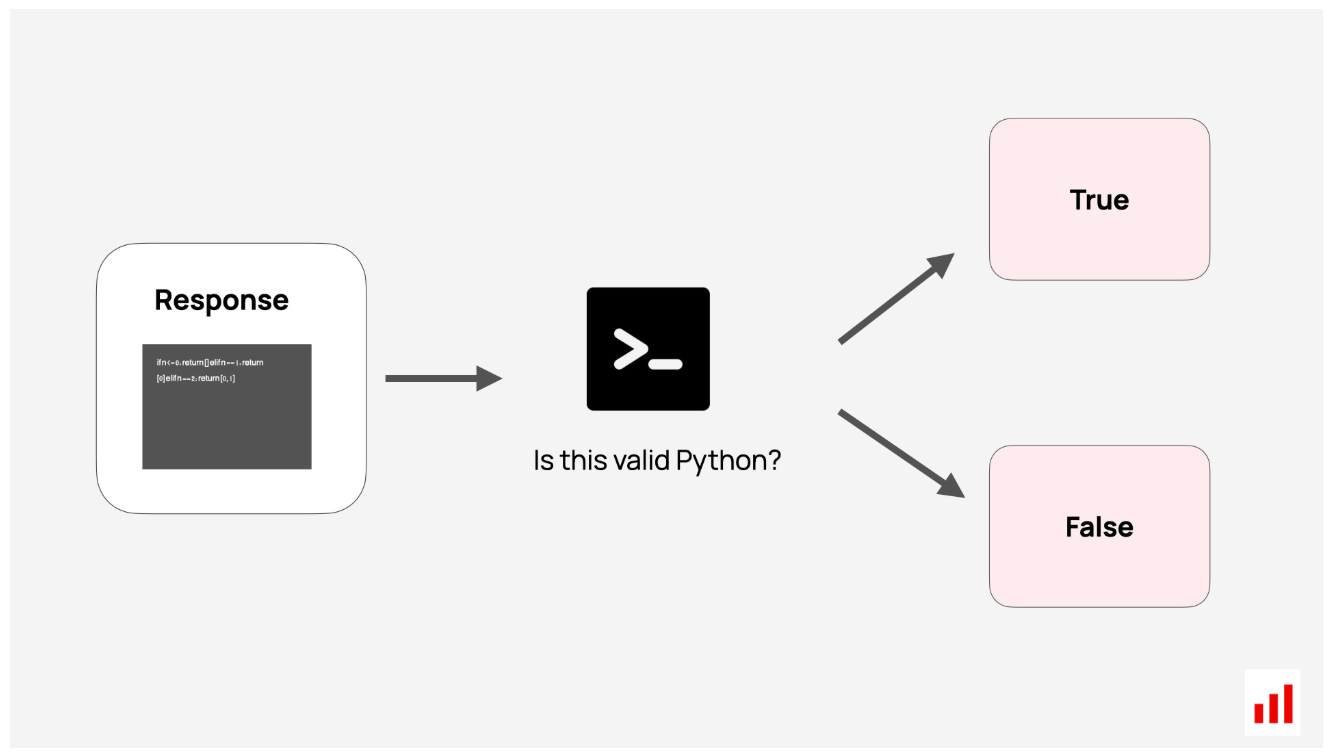
- 测试代码执行。如果模型返回代码,您可以测试它在语法上是否正确,理想情况下是否可执行。您可以在沙箱中或针对自己的测试套件运行它,以验证它是否按预期运行。
| Example metric | Description |
|---|---|
| Format adherence | Confirms that output follows required formats (e.g., is valid JSON, SQL, Python code). |
| Field completeness | Checks for the presence of expected fields in structured responses, e.g. all JSON keys are present and non-empty. |
| Code execution success | Tests whether generated code can run without errors. |
| Data quality validation | Confirms that generated data meets expectations (e.g., non-null, non-negative values). |
语义相似性
TL;DR。检查响应是否与输入、上下文或已知模式一致。
语义相似性不仅仅用于引用匹配。当你没有地面真相响应时,它也很有用。以下是它可以提供帮助的几种方法:
输入输出相似性。例如,如果你要把要点变成一封完整的电子邮件,你可以衡量它与原始要点的匹配程度。这有助于检查它是否与源保持一致。同样,在问答任务中,问题和回答之间的巨大语义差距可能表明答案不相关。
响应上下文相似性。在RAG任务中,您可以将生成的答案与检索到的上下文进行比较。高度相似性将反映模型正确使用了信息。低相似性可能暗示幻觉——当模型制造出不受支持的细节时。
例如,DoorDash以这种方式监控聊天机器人的响应,标记与相关知识库文章相似度低的输出。
模式相似性。例如,您可以将模型的响应与一组拒绝模板进行比较。即使措辞不同,高度相似性也可能表明回应是拒绝。你也可以对其他模式做同样的事情,包括越狱。
| Example metric | Description |
|---|---|
| Response relevance | Measure how well the output aligns with input content. |
| Response groundedness | Measure how well the output aligns with the retrieved context. |
| Denial detection | Measure similarity between the response and the known examples of a specific pattern (like denial). |
示例度量描述
响应相关性衡量输出与输入内容的一致性。
响应基础度衡量输出与检索到的上下文对齐的程度。
拒绝检测测量响应与特定模式(如拒绝)的已知示例之间的相似性。
LLM作为法官
TL;DR:促使LLM根据自定义标准评估输出。
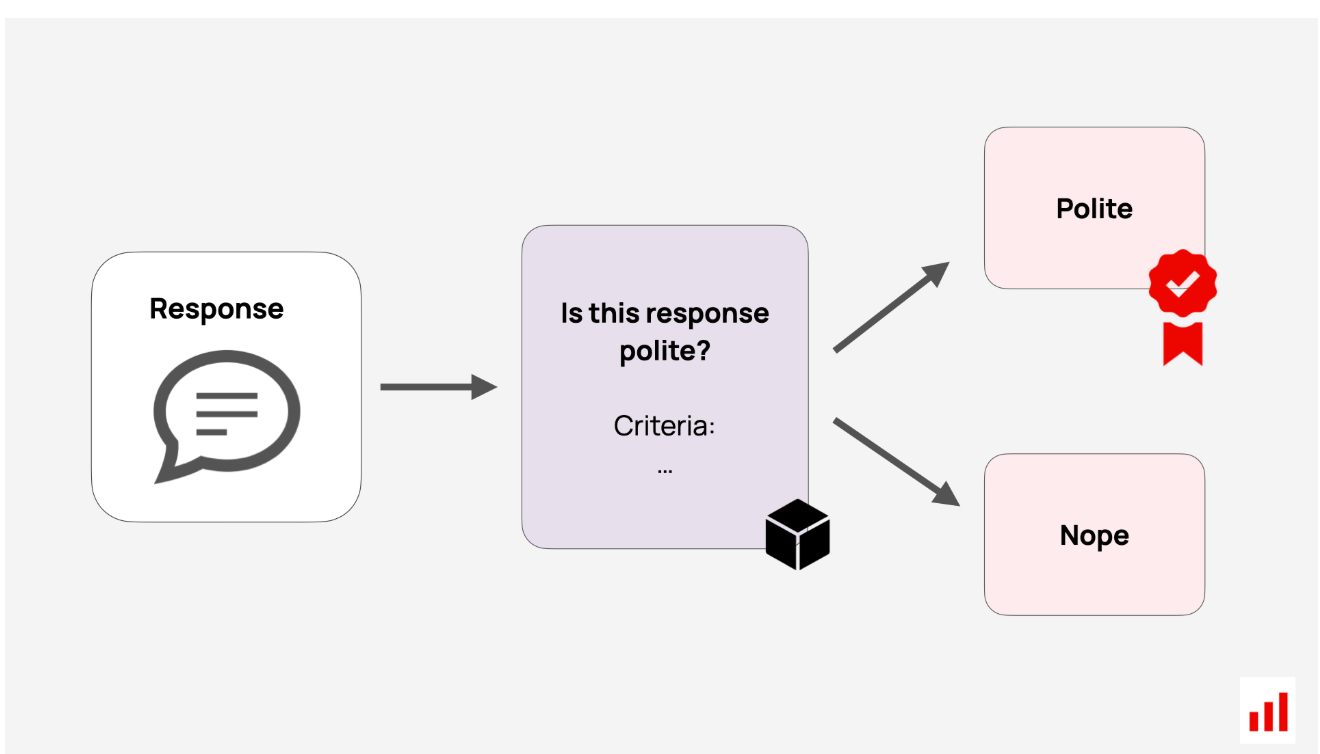
我们已经研究了基于引用的LLM判断,但您可以对无法通过规则定义的任何自定义属性执行相同的操作。只需用自然语言解释你的标准,把它们放在提示中,让LLM判断输出并返回分数或标签。
这些LLM法官有助于扩大人类标签工作,是最通用的评估方法之一。以下是他们的工作方式。
直接评价。您可以判断任何独立的文本质量。例如,检查聊天机器人的响应是否具有正确的语气,或者用户的查询是否合适。
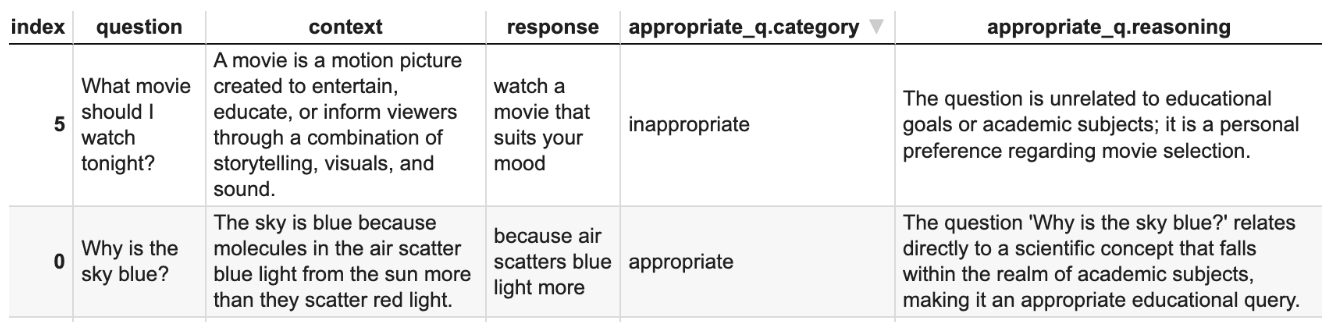
在应用程序上下文中将用户请求标记为“适当”。
基于情境的评估。您还可以评估输出与输入或检索到的数据一起。在这种情况下,您将向计算器传递两段文本。例如,您可以检查RAG搜索是否找到可以回答用户问题的上下文:

评估上下文是否包含足够的信息来回答问题。
或者,你可以寻找“幻觉”来检测任何反应是否提供了不受支持的信息。传递上下文和答案:

评估响应是否基于检索到的上下文。
会话级别评估。您还可以通过要求LLM审查成绩单来评估整个用户会话。这对人工智能智能体和聊天机器人特别有用。目标可能是检查LLM是否完成了用户的任务或保持了一致的语气。
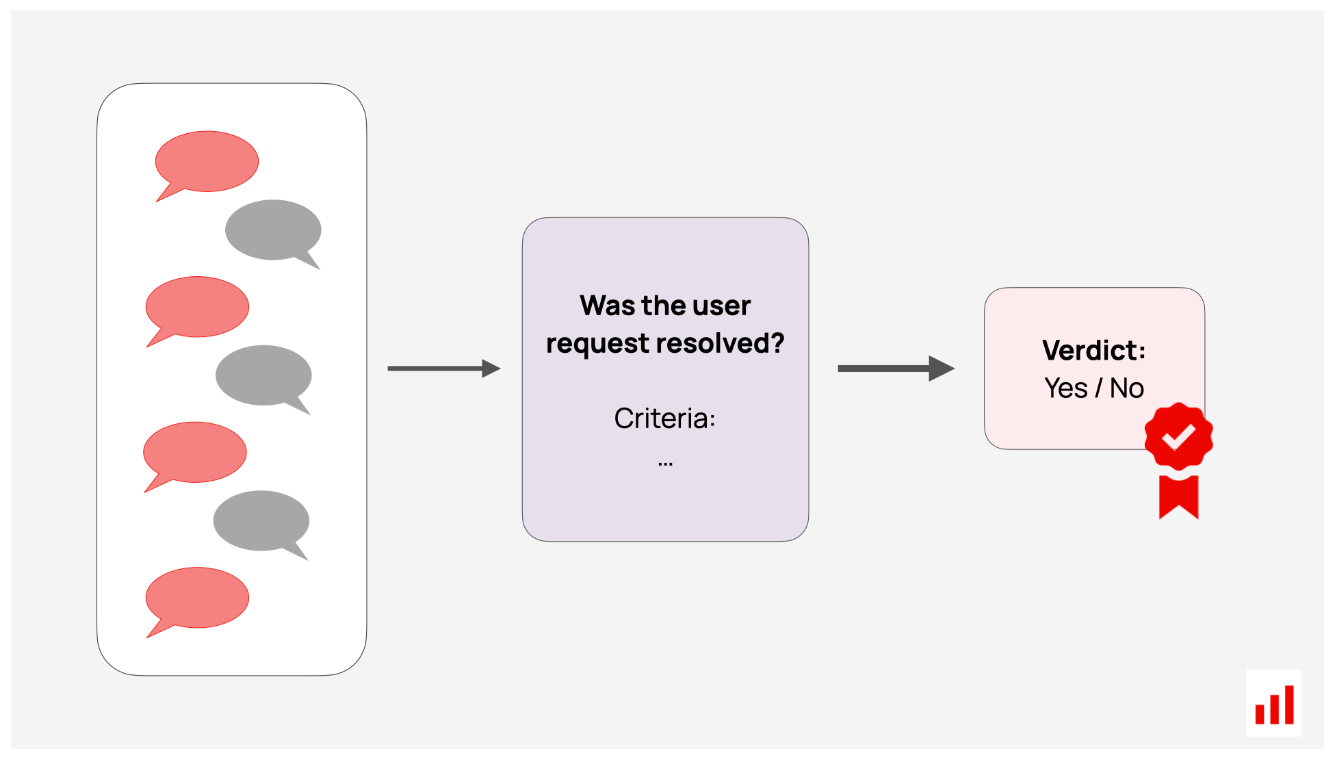
要创建LLM评委,你可以从直接提示开始,问这样的问题:“这个回答礼貌吗?”添加你所说的礼貌的详细信息,并要求二元(是/否)或多级评分(例如,1-5颗星)。
你可以通过思维链(CoT)来增强这一点,让模型一步一步地推理,并可选地包含示例。(参见王等人,2023和郑等人,2023)。
几个更复杂的方法建立在这个想法之上。例如:
- SelfCheckGPT:对同一提示生成多个响应,并比较其一致性,如果答案不同,则标记幻觉。(Manakul等人,2023)
- G-EVAL:将CoT与基于表单的评估相结合,模型首先根据特定标准生成分步说明。(Liu等人,2023)
- FineSurE:将复杂的评估(如忠实性、完整性)分解为离散的标准,并使用逐个事实的检查。(宋等人,2024)
- 模特陪审团:同时询问几个不同的LLM。(Verga等人,2024)
浏览这些昵称可能会令人困惑:像G-Eval或GPTScore这样的术语听起来像是特定的指标,但它们实际上是在提示LLM评估的技术。还有像普罗米修斯这样的微调评估模型(Li等人,2024)。你可以使用它们或提示任何LLM自己评估特定的品质,如“忠诚”或“礼貌”。
研究还表明,复杂的技术并不总是能产生更好的结果。例如,简单地要求LLM一步一步地思考可以超越G-Eval。(Chiang等人,2023)。最好根据自己的评估测试不同的方法!
以下是通过LLM评委实施的一些常见指标:
| Example metric | Description |
|---|---|
| Helpfulness | Checks if the response fully satisfies the user’s request. |
| Groundedness / Faithfulness | Verifies alignment with retrieved context, checks for unsupported details. |
| Politeness / Tone | Evaluates whether tone and language are appropriate. |
| Toxicity / Bias | Detects harmful or biased language. |
| Relevance | Ensures that the response or context is relevant to the query. |
| Safety | Ensures that the response does not contain harmful content. |
虽然LLM的评委很强大,但他们的质量完全取决于及时和潜在的LLM。就像系统提示一样,评估提示也需要改进和测试。此外,对医学或金融等领域要谨慎——通用LLM可能无法为专业主题提供可靠的评估。
基于模型的评分
TL;DR:使用预先训练好的机器学习模型对你的文本进行评分。
要将机器学习用于LLM评估,您并不总是需要一个大型的通用LLM。较小的模型通常可以很好地执行特定任务。
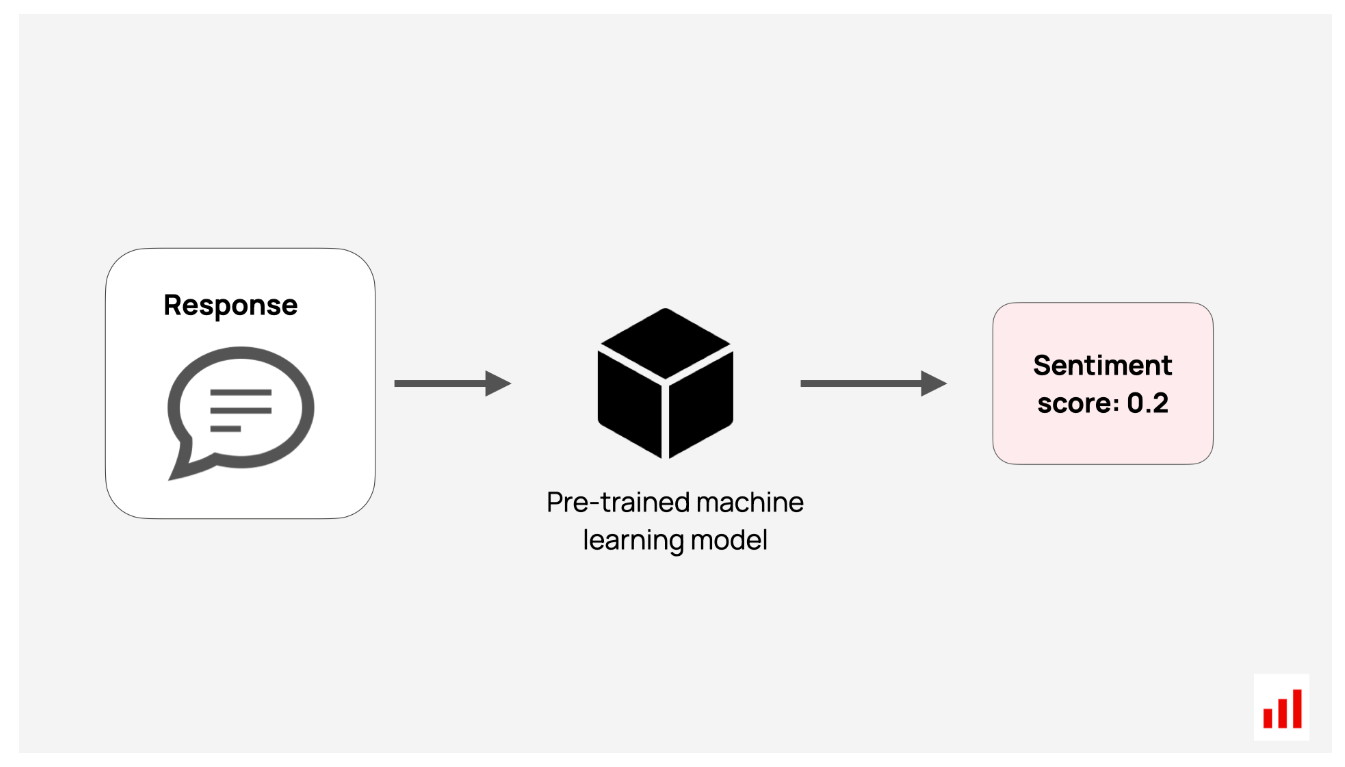
这些模型在标记数据上进行训练,以预测或检测特定特征。例如:
- 按语言对文本进行分类。
- 评估文本中传达的情绪或情感。
- 从预定义列表中识别文本主题或意图。
- 评估文本可读性。
其中许多特性在各种用例中都有广泛的应用。得益于开源社区,您可以访问公开可用的预训练模型。您可以在本地运行它们,而无需承担API成本或向外部发送敏感数据。
此外,如果你已经标记了数据(或从LLM评委那里收集了足够的评估),你可以训练自己的专业模型。通过用你的例子微调预训练的模型,你可以创建一个高度定制的评估器,它既便宜又运行快速。
| Example metric | Description |
|---|---|
| Topic classification | Classifies text by predefined topics. |
| PII detection | Verifies if the text contains personally identifiable information (PII). |
| Toxicity | Detects harmful, biased, or offensive language. |
| Sentiment | Analyzes the emotional tone (e.g., positive, neutral, or negative). |
| Alignment (NLI model) | Tests if the text is consistent (entailment), contradictory, or neutral with respect to a reference text. |
当然,有一个问题:你需要知道每个机器学习模型的作用,并根据你的标准对其进行测试。如果你的数据与模型训练的数据非常不同,质量会有所不同。
要点
市面上有很多LLM评估方法和指标,但你不需要为每个应用程序提供所有这些方法和指标。根据您的用例和遇到的错误,专注于最重要的事情。
例如,对于基于RAG的聊天机器人,您可能会检查检索质量、答案准确性和过度拒绝。一些排名指标和定制的LLM评委可以做到这一点。
以下是一些需要牢记的关键提示:
- 首先,始终查看您的数据。没有什么比看现实世界的例子更能建立直觉了。这有助于你发现模式,制定质量标准,并了解失败。尽早让你的整个团队——尤其是领域专家——来整理测试数据。
- 接下来,定义“质量”对你的应用程序意味着什么。考虑基本要素:响应结构、长度和语言。你的积极指标是什么,比如语气或乐于助人?你想避免哪些风险,比如有毒反应、否认或无关内容?
- 最后,明智地选择你的LLM评估方法。不要只追求一个复杂、晦涩的LLM指标,你无法解释或匹配你的标签。首先,进行自己的定性评估。然后,回想一下指标,并决定如何实施它们。例如,您可以使用LLM判断、ML模型或正则表达式过滤器来测量毒性。最佳选择将取决于成本、隐私和准确性等因素。
如有疑问,请从LLM评委开始。它们在实践中被广泛使用,为人工审查提供了一种灵活的替代方案,特别是对于开放式或会话级评估。此外,它们很容易上手——只需编写一个自定义提示并根据需要进行优化。
LLM evals with Evidently
LLM评估可能会变得棘手:我们构建了Evidently,使这一过程更容易。我们的开源库(下载量超过2500万!)支持多种评估方法。对于团队,我们提供了Evidently Cloud——一个无代码的工作空间,用于在人工智能质量、测试、监控和运行复杂的评估工作流程方面进行协作。
我们专门帮助您评估复杂的系统,如RAG、AI智能体和关键任务应用程序,在这些系统中,您需要额外的安全保障。显然,它还可以帮助您使用合成数据生成测试场景和智能体模拟。如果这是你正在做的事情,请联系我们——我们很乐意提供帮助
- 登录 发表评论
- 131 次浏览
最新内容
- 2 hours ago
- 1 week 1 day ago
- 1 week 5 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago