
MySQL 和 Elasticsearch 之间全文搜索和比较的分步指南
您是否曾经在超市或百货公司四处走动,但找不到您要找的物品?在网上购物时,您可能会遇到同样的情况。尽管大多数网站按类别排列产品,但如果您不知道目标产品的类别,浏览类别仍然是一件苦差事。搜索栏为我们节省了大量时间,因为我们可以简单地输入关键字或文本短语,然后它会向我们显示所有相关项目。毫无疑问,全文搜索是所有电子商务网站的基本功能。
全文搜索是 MySQL 和 Elasticsearch 等许多数据库支持的流行功能。但是,在全文搜索能力方面,MySQL 和 Elasticsearch 有什么区别呢?如果您正在寻找实现全文搜索的解决方案,则无法在不了解差异的情况下做出正确的决定。在本文中,我将向您展示 MySQL 和 Elasticsearch 上全文搜索的用法,并强调它们的区别。
什么是全文搜索?
如果搜索引擎通过完全匹配来查找数据记录,您几乎不会得到任何搜索结果。例如,下面的 SQL 语句不太可能返回任何记录,因为可能不存在名称或描述与名称或描述中的文本短语“鱼和番茄罐头”完全相同的此类产品。
SELECT * FROM products WHERE name = ‘canned food with fish and tomato’ OR description = ‘canned food with fish and tomato’
如果我们使用通配符“LIKE %”可能会有所帮助,但您只会收到在数据字段中包含确切文本短语的记录。
SELECT * FROM products WHERE name LIKE ‘%canned food with fish and tomato%’ OR description LIKE ‘%canned food with fish and tomato%’
全文搜索的想法是将文本短语分解为标记。上例中的文本短语分为以下标记:“罐头”、“食物”、“与”、“鱼”、“和”和“番茄”。然后,搜索引擎查找与任何一个标记匹配的所有记录。记录匹配的标记越多,它与文本短语的相关性就越高。因此,搜索引擎通过在搜索结果中分配分数来指示相关性。如果您的查询字符串中的标记包含诸如“食物”之类的常用词,并且许多产品可能匹配一个或多个标记,您可能会收到包含大量记录的搜索结果。但是,您始终可以按分数过滤结果,以获得最相关的记录。
全文搜索是 MySQL 和 Elasticsearch 等许多数据库支持的流行功能。启用此功能的设置实际上非常简单明了。例如,您可以在 MySQL 上打开选定数据字段的全文搜索功能,而无需对表架构进行任何更改。说到 Elasticsearch 就更直接了,因为它默认支持全文搜索,不需要额外的配置。
全文搜索概览 — MySQL 与 Elasticsearch
简而言之,MySQL 和 Elasticsearch 在全文搜索方面有着相似的想法。它是通过将文本内容分解为标记来创建索引。然后,查询会将查询文本分解为标记并与索引匹配。根据匹配结果,搜索引擎计算得分并分配给代表相关性的搜索结果。
主要区别在于固定解决方案和可配置解决方案之间的解决方案方法。 MySQL 以 3 种不同的模式提供全文搜索的固定功能——自然语言、布尔和扩展查询。它几乎没有调整和微调的空间。
相反,Elasticsearch 的设计是高度可配置的。标记分解和查询执行的过程是基于分析器、标记器和过滤器的集合来执行的。这些组件可以定制并组合在一起,以实现更高级的功能。
我将逐步介绍 MySQL 和 Elasticsearch 上的全文搜索用法。
样本数据集
全文搜索功能的演示基于一个样本数据集,该样本数据集是一组图书馆图书记录。架构相当简单,包含以下列:id、title 和 publicationPlace。

MySQL
运行下面的 SQL 语句创建图书馆图书表并导入示例数据。
CREATE TABLE `library-book` (
`id` int(11) NOT NULL,
`title` text COLLATE utf8_unicode_ci,
`publicationPlace` text COLLATE utf8_unicode_ci
);
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('1', 'How To Grow Your Own Fruit and Veg: A Week-by-week Guide to
Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural
Balance Gardening', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('2', 'The Life of God in the Soul of the Church: The Root and
Fruit of Spiritual Fellowship', 'Edinburgh');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('3', 'Fruit and vegetable production in Africa - The important
fruits are bananas, pineapples, dates, figs, olives, and citrus;
the principal vegetables include tomatoes and onions', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('4', 'Silver fruit upon silver trees', 'London');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('5', 'A life to live', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('6', 'The emergency medical services in Edinburgh', 'New York');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('7', 'SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH
VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual
Herb Recipes', 'Auckland');
INSERT INTO `library-book` (`id`, `title`, `publicationPlace`)
VALUES ('8', 'Good Food For Bad Days - Tasty vegan meals really
don''t have to take all the time in the world or grand ingredients', 'Edinburgh');
MySQL 需要为全文搜索设置索引,假设读者有兴趣根据这两个数据字段查找书籍,则运行以下语句为“title”和“publicationPlace”创建全文索引。
ALTER TABLE `library`.`books` ADD FULLTEXT `book_free_text_index` (`title`, `publicationPlace`);
Elasticsearch
Elasticsearch 的所有 CRUD 操作都是通过 REST API 调用来完成的。 要将同一组示例书籍记录加载到 Elasticsearch 中,请运行下面的 curl 命令,该命令会提交 POST 请求以进行批量数据插入。 如果您想知道如何在本地机器上运行 Elasticsearch 和 Kibana 进行测试,请按照本文在 docker 上部署 Elasticsearch 节点。
与 MySQL 不同,Elasticsearch 是一个 NoSQL 数据库,无需事先创建表模式即可完成数据插入。 Elasticsearch中的“索引”是指关系数据库中的数据库,如果该索引尚不存在,它会自动创建一个名为“library-book”的索引,如请求中指定的那样。 此外,无需创建全文搜索索引,因为 Elasticsearch 在数据插入或更新过程中将文本内容分解为令牌并存储在索引中。
curl --request POST \
--url 'http://localhost:9200/_bulk?pretty=' \
--header 'Content-Type: application/json' \
--data '{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "1" } }
{ "title" : "How To Grow Your Own Fruit and Veg: A Week-by-week Guide to
Wild-life Friendly Fruit and Vegetable Gardening - Recipes Of Natural
Balance Gardening", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "2" } }
{ "title" : "The Life of God in the Soul of the Church: The Root and
Fruit of Spiritual Fellowship", "publicationPlace": "Edinburgh" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "3" } }
{ "title" : "Fruit and vegetable production in Africa - The important fruits
are bananas, pineapples, dates, figs, olives, and citrus; the principal
vegetables include tomatoes and onions", "publicationPlace": "London"}
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "4" } }
{ "title" : "Silver fruit upon silver trees", "publicationPlace": "London" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "5" } }
{ "title" : "A life to live", "publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "6" } }
{ "title" : "The emergency medical services in Edinburgh",
"publicationPlace": "New York" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "7" } }
{ "title" : "SIMPLE GREEN SUPPERS: A FRESH STRATEGY FOR ONE-DISH
VEGETARIAN MEALS BY SUSIE MIDDLETON - Delicious Dishes And Unusual
Herb Recipes", "publicationPlace": "Auckland" }
{ "index" : { "_index" : "library-book", "_type" : "_doc", "_id" : "8" } }
{ "title" : "Good Food For Bad Days - Tasty vegan meals really
don'\''t have to take all the time in the world or grand ingredients",
"publicationPlace": "Edinburgh" }简单的关键字搜索
让我们从一个简单的搜索开始,假设我们搜索一个关键字“爱丁堡”。
MySQL
要查找与该关键字匹配的所有记录,请在 MySQL 中使用 match() 以布尔模式进行全文查询。 运行此 SQL 语句以搜索“爱丁堡”。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('edinburgh' IN BOOLEAN MODE) AS score
FROM `library-book`
ORDER BY score DESC
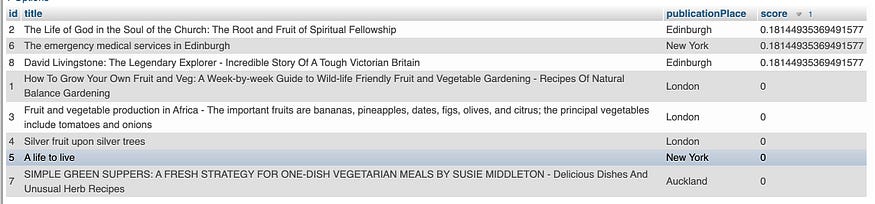
搜索结果为每条记录分配一个分数,以显示相关性。 分数越高,记录与关键字的相关性越高。 有 3 条记录的得分 > 0,因为标题和 publicationPlace 与关键字“爱丁堡”匹配,而其他记录与关键字不匹配,因此分配零分。
Elasticsearch
Elasticsearch 支持多种查询方法,例如关键字、文本短语、前缀等。我们在此示例中使用查询类型“multi_match”来搜索多个数据字段——“title”和“publicationPlace”。 提交此 POST 请求以搜索关键字“edinburgh”。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title",
"publicationPlace"
]
}
}
}'

根据指定数据字段微调分数
对于某些用例,某些数据字段更重要,这些字段上的关键字匹配应给予更高的分数。 虽然 MySQL 不提供这种灵活性,但可以在 Elasticsearch 中通过将插入符号“^”附加到数据字段来实现它。 此处的示例将“title”字段的重要性设置为 3 倍。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "edinburgh",
"fields": [
"title^3",
"publicationPlace"
]
}
}
}'由于“title”更重要,“title”字段与关键字匹配的记录得分更高。

使用逻辑条件搜索
您可能想要指定某些搜索条件,例如 AND / OR / NOT。 比如说,我们想搜索同时匹配关键字“生活”和“生活”的书籍。 为此,我们在每个关键字前面添加一个符号“+”,以表明它是一个“AND”条件。
MySQL
MySQL 提供的 BOOLEAN 模式支持带逻辑条件的查询。 让我们搜索关键字“生活”和“生活”的书籍。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('+life +live' IN BOOLEAN MODE) AS score
FROM `library-book`
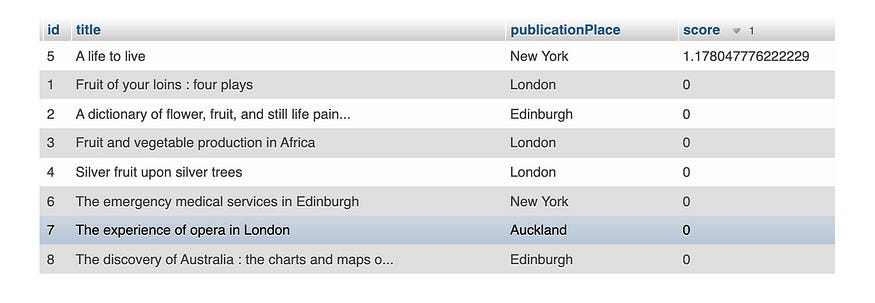
ORDER BY score DESC;现在只有“A life to live”这本书与 score > 0 相关,而所有其余书籍的 score = 0。
布尔模式不仅支持 AND 运算符(+),还支持其他符号,如 NOT(~)、高相关性(>)、低相关性(<)等,具体请参考 MySQL 官方参考。
弹性搜索
同一组符号可以应用于 Elasticsearch。 我们可以在带有逻辑条件的文本短语的 POST 请求中使用查询类型“simple_query_string”。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"simple_query_string": {
"query": "+life +live",
"fields": [
"title",
"publicationPlace"
]
}
}
}'结果只显示一条记录,与 MySQL 的结果相同。

文本短语搜索
“Recipes Of A Delicious And Tasty Meal”的文本短语的搜索结果是什么? 由于文本短语被分解为小写“recipes”、“of”、“a”、“delicious”、“and”、“tasty”和“meal”的标记。 记录匹配更多标记,这意味着它与文本短语更相关。
人们自然会用人类语言输入文本短语以进行查询。 考虑到人类语言,需要进行特殊处理才能产生准确的结果。 例如,匹配那些在英语中出现频率很高的单词,如“a”、“an”、“of”、“the”等,就不太可能产生有意义的结果。 这些词被称为“停用词”,搜索引擎应该在文本短语查询中忽略它们。
MySQL
MySQL 支持忽略“停用词”并运行不区分大小写的搜索的自然语言模式。 运行此查询语句以搜索文本短语。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST
('Recipes Of A Delicious And Tasty Meal' IN NATURAL LANGUAGE MODE) AS score
FROM `library-book`
ORDER BY score DESC;得分最高的前 3 条记录与搜索文本短语中的大多数标记匹配。

Elasticsearch
Elasticsearch 的默认索引设置不具备 MySQL 提供的自然语言模式等功能。
当您将此 POST 请求发送到 Elasticsearch 以搜索相同的文本短语时,您将看到不同的结果。
curl --request POST \
--url http://localhost:9200/library-book/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
}'默认设置将停用词考虑在内以进行匹配和分数计算。 结果,与“of”和“and”等大多数停用词匹配的得分最高的搜索结果显然是不相关的。

不用担心,Elasticsearch 实际上是一个非常强大的搜索引擎,可以通过在索引设置中为停用词配置标记过滤器来支持自然语言搜索。
Elasticsearch 提供了 15 个 tokenzier 和 50 多个适用于各种用例的 token 过滤器。 要实现类似于 MySQL 的全文搜索,只需在分析器中添加停用词标记过滤器即可。 下图显示分析仪由以下组件组成:
- 标准分析器——将文本短语分解为标记
- 小写标记过滤器 - 将标记转换为小写以进行不区分大小写的搜索
- 停用词标记过滤器 - 删除常用词的标记,例如“of”、“a”、“and”等。
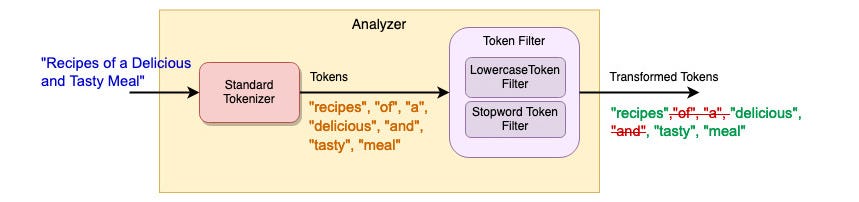
Analyzer 在索引设置中配置,并映射到数据字段“title”和“publicationPlace”。
提交此 PUT 请求以使用新的分析器配置和字段映射创建一个名为“library-book-text-phrase”的新索引(即 Elasticsearch 中的数据库)。
curl --request PUT \
--url http://localhost:9200/library-book-text-phrase \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
}
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'然后,提交这个 POST 请求,将数据从原始索引“library-book”复制到新创建的索引“library-book-text-phrase”。
curl --request POST \
--url 'http://localhost:9200/_reindex \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-text-phrase"
}
}'让我们对新索引“library-book-text-phrase”运行相同的查询。 结果现在更有意义了。
curl --request POST \
--url http://localhost:9200/library-book-text-phrase/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "Recipes Of A Delicious And Tasty Meal",
"fields": [
"title",
"publicationPlace"
]
}
}
MySQL — 扩展搜索条件
强大的搜索引擎不仅可以通过token匹配进行搜索,还可以理解关键字并扩展搜索其他具有相似含义的关键字。 例如,当您搜索关键字“woods”时,预计搜索引擎应该寻找与“timber”、“lumber”和“trees”等其他类似关键字匹配的记录。
MySQL 能够使用“QUERY EXPANSION”模式猜测您要查找的内容。
SELECT id, title, publicationPlace,
MATCH (title, publicationPlace) AGAINST ('green' WITH QUERY EXPANSION) AS score
FROM `library-book`
ORDER BY score DESC当我们搜索关键字“绿色”时。 将返回 3 条记录。 第 2 条和第 3 条记录的标题字段实际上并不包含关键字“green”,但搜索引擎以某种方式猜测这些记录的内容与关键字“green”相关

但是,当我们在搜索条件中添加更多关键字时,搜索结果会包含更多“噪音”。 几乎所有的图书记录都在查询扩展模式下搜索到了文本短语“美好生活”。
如果您对准确性不满意,则无法微调搜索结果。

Elasticsearch - 使用同义词标记过滤器的广泛搜索
Elasticsearch 提供了多种方式来实现类似于 MySQL 支持的扩展模式的扩展搜索。 令牌过滤器的使用不是提供固定的解决方案,而是可以实现高级全文搜索的能力。
我们来看看对同义词搜索的支持。 我们配置令牌过滤器,以便将搜索扩展到同义词。 我们使用了一个名为 WordNet 的免费词汇数据库。 一般来说,它存储超过 2 万个单词和同义词的映射。
配置是为同义词添加新的标记过滤器,过滤器从 WordNet 文件中读取同义词映射。

要启用新的索引设置,请下载 WordNet 文件并复制到 [elasticsearch 文件夹]/config/analysis,然后提交此 PUT 请求以创建一个名为“library-book-synonym-wordnet”的新索引
curl --request PUT \
--url http://localhost:9200/library-book-synonym-wordnet \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"format": "wordnet",
"lenient": true,
"synonyms_path": "analysis/wn_s.pl"
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'然后,提交这个 POST 请求,将数据从原始索引“library-book”复制到新创建的索引“library-book-synonym-wordnet”。
curl --request POST \
--url 'http://localhost:9200/_reindex' \
--header 'Content-Type: application/json' \
--data '{
"source": {
"index": "library-book"
},
"dest": {
"index": "library-book-synonym-wordnet"
}
}'现在,在新索引上搜索关键字“green”。 然后,您将获得与“green”同义词匹配的记录列表。
curl --request POST \
--url http://localhost:9200/library-book-synonym-wordnet/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"multi_match": {
"query": "green",
"fields": [
"title",
"publicationPlace"
]
}
}
}'结果:

具有自定义词映射的 Elasticsearch 令牌同义词过滤器
如果 WordNet 不能满足您的需求,Elasticsearch 支持自定义同义词映射。 我们配置了一个同义词标记过滤器,以便将关键字“fruit”映射到关键字列表——“banana”、“pineapple”、“date”、“fig”、“olive”和“citrus”。 因此,搜索关键字“banana”将匹配任何带有“fruit”的记录。
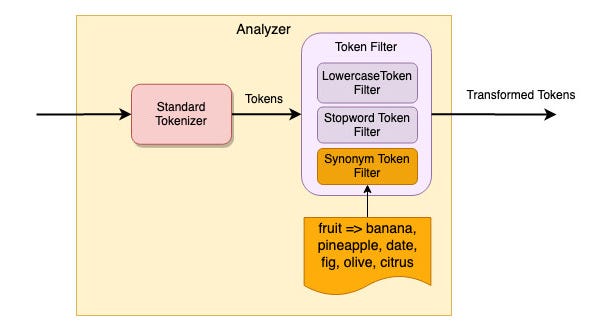
提交此 PUT 请求以使用令牌过滤器“synonym_filter”创建新索引和自定义分析器。
curl --request PUT \
--url http://localhost:9200/library-book-custom-synonym \
--header 'Content-Type: application/json' \
--data '
{
"settings": {
"analysis": {
"analyzer": {
"english_analyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "english_stop_filter", "synonym_filter"]
}
},
"filter": {
"english_stop_filter": {
"type": "stop",
"stopwords": "_english_"
},
"synonym_filter": {
"type": "synonym",
"lenient": true,
"synonyms": [
"fruit => banana, pineapple, date, fig, olive, citrus"
]
},
}
}
},
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"analyzer": "english_analyzer"
},
"description": {
"type": "text",
"analyzer": "english_analyzer"
},
"publicationPlace": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
}'将数据复制到新创建的索引后,提交此 POST 请求以搜索关键字“banana”。 然后,您将看到结果包含与“fruit”关键字匹配的所有记录。
curl --request POST \
--url http://localhost:9200/library-book-custom-synonym/_search \
--header 'Content-Type: application/json' \
--data '{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "banana"
}
}
]
}
}
}'结果:

最后的想法
MySQL 和 Elasticsearch 都提供了强大的全文搜索能力。 如果您的系统使用 MySQL 作为数据存储,则可以通过为目标数据字段创建全文索引来快速启用全文搜索功能。 该解决方案适用于大多数用例,因为它为用户提供了一种在多个数据字段上搜索关键字和文本短语的快捷方式。 但是,在搜索结果微调和自定义方面,MySQL 中可用的选项有限。 因此,Elasticsearch 可能是高级功能和定制搜索行为的更好选择,因为该解决方案具有高度可配置性且更加灵活。
原文:https://blog.devgenius.io/how-to-enable-powerful-full-text-search-for-y…
最新内容
- 1 day 6 hours ago
- 1 week 2 days ago
- 1 week 6 days ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago