
介绍
数据是新机油。公司希望充分利用他们产生的数据。为了实现这一目标,需要能够消耗、处理、分析和呈现大量数据的系统。这些系统需要易于使用,但也需要可靠,能够检测问题并正确存储数据。这些和其他问题旨在由数据平台解决。
建立一个数据平台不是一件容易的事。从基础设施和编程到数据管理,都需要多种技能。
这篇文章是第一篇,我希望这将是一系列更长的文章中的第一篇,在这些文章中,我们将试图揭示如何构建一个数据平台的秘密,使您能够为用户生成增值产品。
什么是数据平台?
我们可以使用我们首选的网络搜索引擎来发现什么是数据平台的定义。例如,我发现了以下定义:
- 数据平台实现了数据的获取、存储、准备、交付和管理,并为用户和应用程序添加了一个安全层:https://www.mongodb.com/what-is-a-data-platform
- 数据平台是一个完整的解决方案,用于接收、处理、分析和呈现现代数字组织的系统、流程和基础设施生成的数据:https://www.splunk.com/en_us/data-insider/what-is-a-data-platform.html
因此,数据平台是一个我们可以存储来自多个来源的数据的地方。此外,数据平台为用户提供了搜索、处理和转换数据所需的工具,目的是创建某些类型的产品。这些产品可以是具有有用见解的仪表盘、机器学习产品等。
什么是数据平台?非常简单的图表。
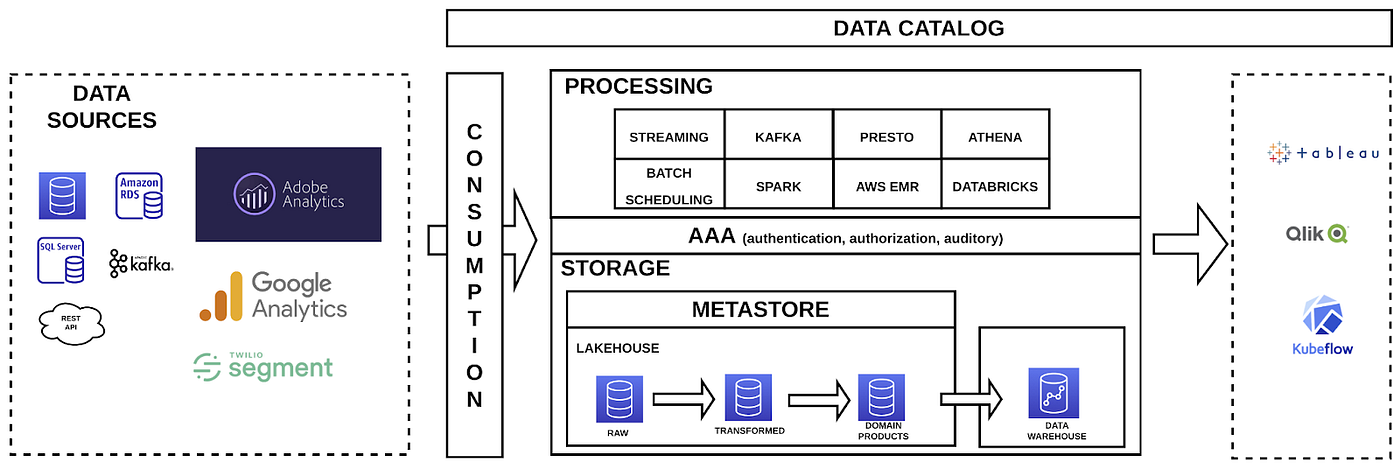
在这个图表中,我们可以找到创建数据平台的所有基本组件(我们不是试图描述数据网格或数据管理平台,这些东西将在未来的其他文章中省略)。您可以在描述其他数据平台的其他图表中找到具有其他名称但功能相同的组件。在这个图中,我们可以找到这些组件:
- 数据源:数据库、RESTAPI、事件总线、分析工具等。
- 消费:用于消费数据源的工具。
- 存储:消耗的数据所在的位置。
- 安全层:负责提供身份验证、授权和听觉的组件。
- 处理:使我们能够处理存储数据的程序或工具。
- 数据目录:由于存储的数据量将是巨大的,我们需要一个工具,让用户能够轻松地找到他们需要的数据。
- Tableau、Qlik、Kubeflow、MLflow等:数据将用于某些目标。通常,这个目标可以是创建一个带有有意义的图表的仪表板,为机器学习和许多其他事情创建模型。
第一篇文章将重点讨论存储层,因此从现在起,我们将只讨论该组件。
存储层。
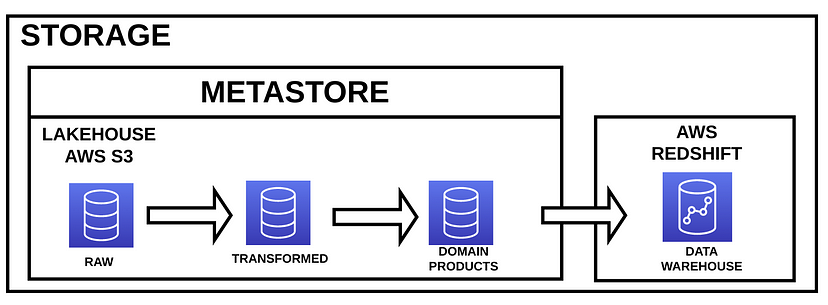
当然,存储层是存储数据的地方。因为要存储的数据量很大,我们不能使用HDD或SSD数据存储,我们需要更便宜的东西。在这种情况下,我们将讨论AWS S3,因为我们正在与亚马逊网络服务合作。对于Azure,您可以使用Azure Data Lake Storage Gen2。如果你使用谷歌云,你可以使用谷歌云存储。使用什么存储并不重要,只要它便宜并且可以存储大量数据。
您可以在该图中看到三个不同的元素:
- 数据湖仓:它是传统数据湖的演变。Data Lakehouse实现了Data Lake加ACID事务的所有功能。你可以在这个链接中找到更多关于Lakehouses的信息。
通常在Data Lakehouse或Data Lake中,您可以找到不同的区域来存储数据。您可以找到的区域数量取决于您希望如何对数据进行分类。如何在data Lake或Lakehouse中创建和分类数据是一个复杂的问题,将在未来的文章中讨论。数据湖是存储消耗数据的第一个地方。有时它只是毫无意义的原始数据。
- 数据仓库:很多时候,您需要实现星形模式来创建数据集市,以便用户更容易地使用存储的数据。在这里,用户可以找到有意义的数据,用于创建仪表板、机器学习产品或用户需要的任何其他东西。
- Metastore:数据存储在blob存储中,如果您想将这些数据当作存储在传统数据库中一样使用,我们需要一个元素来将架构和表名转换为blob存储中的文件夹和文件。这个翻译是由元存储制作的。
本文并没有试图深入解释上述三个要素是如何工作的。这些解释将在未来的其他文章中省略。
现状(环境隔离)
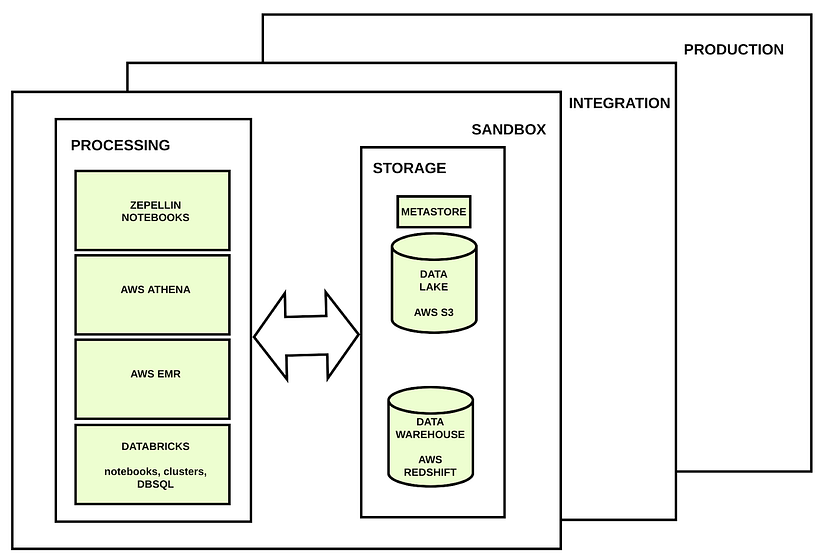
如果您希望用户尽快创建数据产品,那么您需要至少创建一个环境,让这些用户可以随意处理存储的数据。在这个与世隔绝的环境中,他们将能够打破和改变他们想要的任何事情。我们的生产环境必须与此环境和其他环境隔离,因为我们不想破坏生产流程。将存在不同且孤立的环境。这些环境包含相同的处理和存储层,但这些层在它们自己的环境中是隔离的。因此,沙盒环境中的笔记本电脑无法从生产环境中破坏存储层中存储的数据。
数据问题。
数据工程师、数据分析师、数据科学家和处理大数据的一般数据人员需要大量数据来实施、开发和测试他们的应用程序。这些应用程序可以是ETL、ELT、笔记本电脑、仪表板等。
在一个健康的系统中,这些用户应该能够在一个安全的环境中工作,在那里他们可以确保在尝试实施新的解决方案时不会破坏生产中已经有效的任何东西。我们需要创造孤立的环境。这些环境可以是沙箱、集成、生产环境等。
拥有不同且孤立的环境的问题在于,在没有生产能力的环境中,数据量可能会比生产中生成的数据量低得多。
因此,现在,我们面临着以下问题:我们希望用户能够以简单快捷的方式处理大量数据,但我们希望他们在与生产环境隔离的环境中这样做,因为我们不希望他们破坏任何东西。
解决方案1。
请记住,我们有数据源,这些数据源必须连接到我们不同的、孤立的环境。我们可以要求这些数据源向我们发送与他们在生产环境中发送的数据量相同的数据。
此解决方案的问题在于,在许多情况下,这些数据源都有自己的非生产前环境,并且它们不可能在其他环境中生成与生产环境中相同数量的数据。此外,他们不会愿意将我们自己的非生产性环境与他们的生产性环境联系起来,因为我们可能会破坏他们的环境。
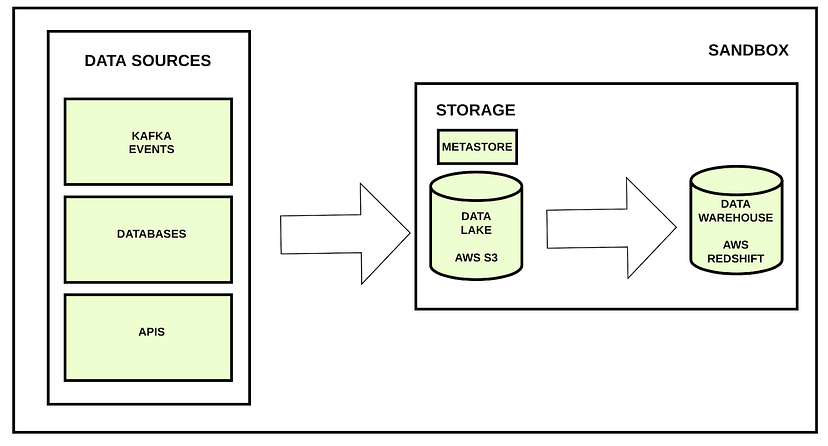
这种解决方案在许多情况下是行不通的。
解决方案2。
另一种解决方案可以很简单,只需执行一项作业,将数据从位于生产环境中的存储器复制到非生产环境中。例如,詹金斯的工作。
此解决方案的问题是复制大量数据的速度不快,而且由于多种原因(没有正确的权限、移动所有所需数据的正确内存等),作业很容易中断
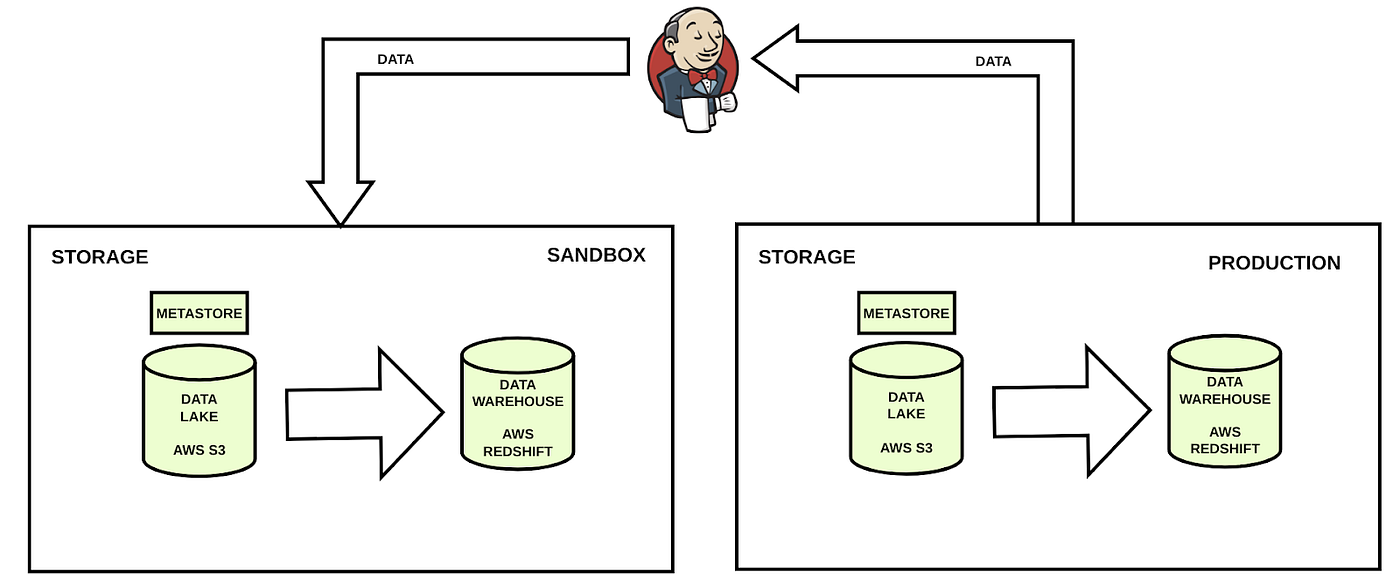
这种解决方案并不能简化新应用程序的开发,因为复制过程很慢,有时无法工作,而且数据无法立即获得。
解决方案3。
我们的用户需要的是能够访问在非生产环境中运行的工具在生产环境中生成的数据。我们需要提供一种解决方案,让在集成环境中运行的笔记本电脑等应用程序可以访问生产环境中的存储。
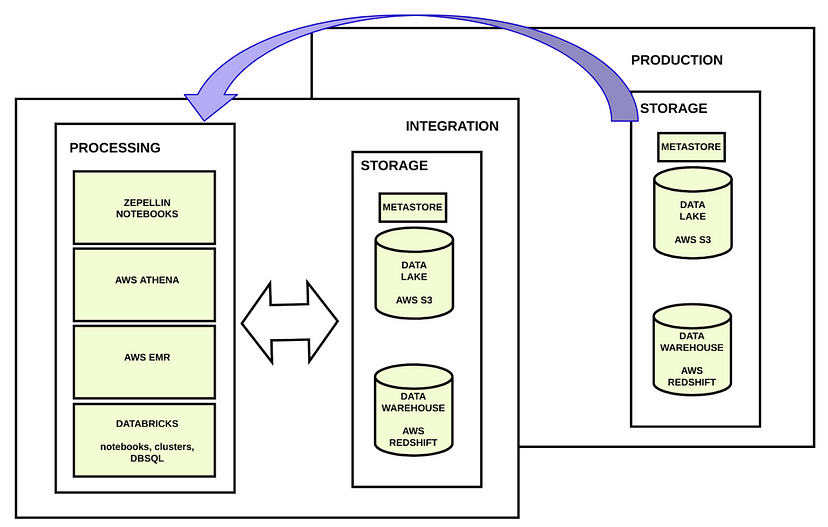
这种解决方案在任何情况下都有效。这就是我们将在本文中重点介绍的与数据湖相关的组件的解决方案。在下一篇文章中,我们将解释在数据仓库中实现的相同解决方案。
数据湖,AWS S3。
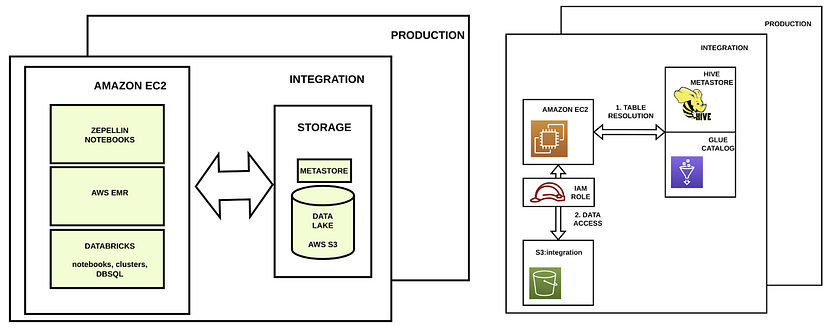
- 笔记本、Spark作业、集群等都在名为EC2的亚马逊虚拟服务器中运行。
- 这些虚拟服务器需要访问AWS S3的权限。这些权限由IAM角色授予。
- 我们将与亚马逊网络服务合作。正如我们之前所说,由于要存储的数据量巨大,我们不能使用HDD或SSD数据存储,我们需要更便宜的东西。在这种情况下,我们将讨论AWS S3。
- 此外,为了方便使用数据湖,我们可以在其顶部实现元存储。例如,Hive元存储或Glue Catalog。我们不会深入解释元商店是如何工作的,这将留给未来的另一篇文章。
当使用笔记本电脑(例如Databricks笔记本电脑)并拥有元存储时,笔记本电脑要做的第一件事是询问元存储数据的物理位置。一旦元存储做出响应,笔记本将转到AWS S3中的路径,在该路径中使用IAM角色给定的权限存储数据。
数据湖、集成和生产环境。
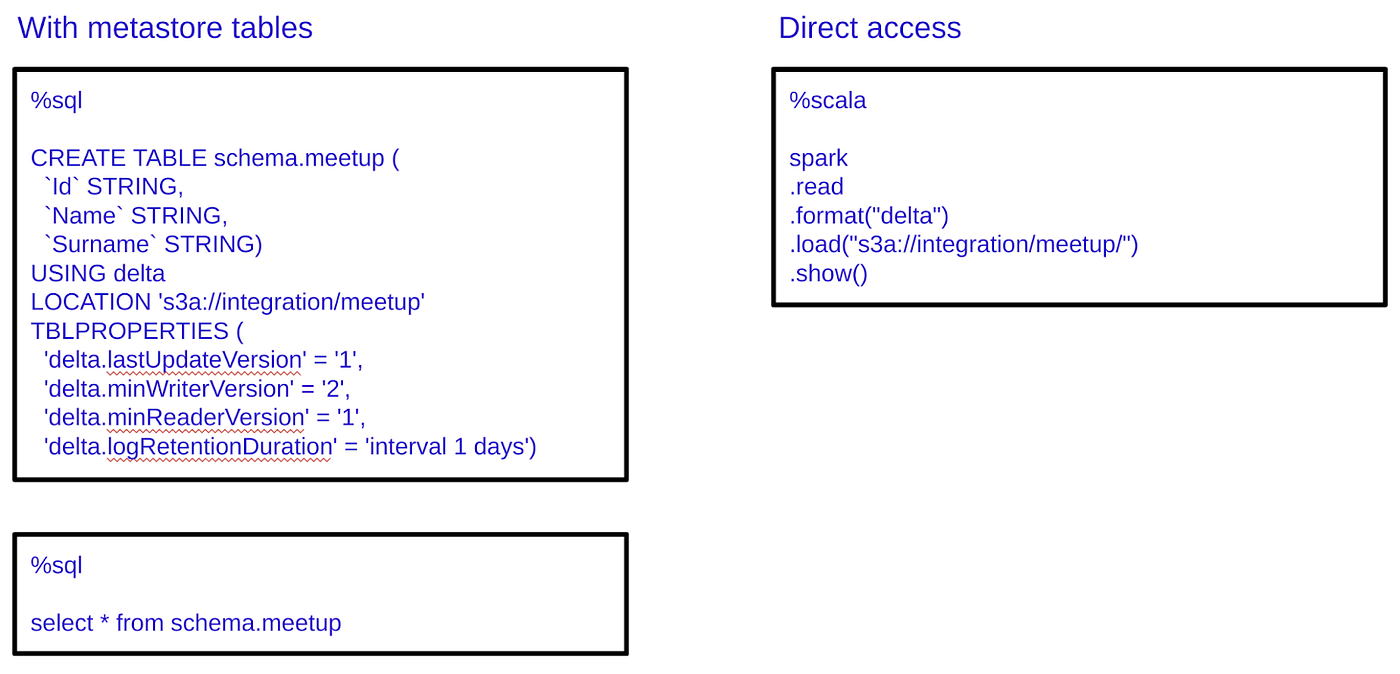
在集成环境中,我们有两种处理数据的选项。使用或不使用元存储。
在生产环境中,我们有完全相同的系统,但与集成环境隔离。在生产中,我们发现了完全相同的两种选择。
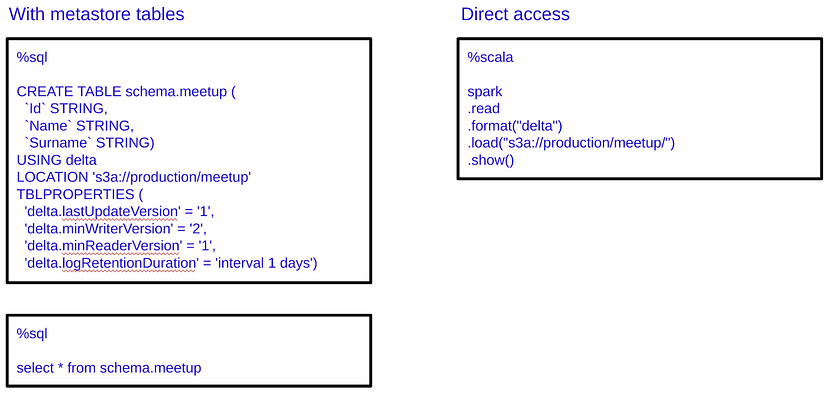
正如大家所看到的,元存储允许我们使用位于数据湖中的数据,因为它是一个普通的数据库。此外,我们可以看到元存储不是存储数据,而是允许我们在AWS S3中找到真实存储数据的元数据。有了元存储,用户可以更容易地访问数据湖中的数据,因为他们可以像在任何其他数据库中一样使用SQL语句。
数据湖,共享数据。
当用户从集成环境中运行笔记本电脑或任何其他应用程序时,他们需要访问位于生产环境存储区中的生产数据。
请记住,这些笔记本电脑和应用程序运行在称为亚马逊EC2实例的亚马逊虚拟服务器中,为了访问位于AWS S3中的数据,它们使用IAM角色(访问数据的权限)。我们可以在(例如)集成环境中修改IAM角色,以允许EC2实例访问位于生产存储区中的数据。
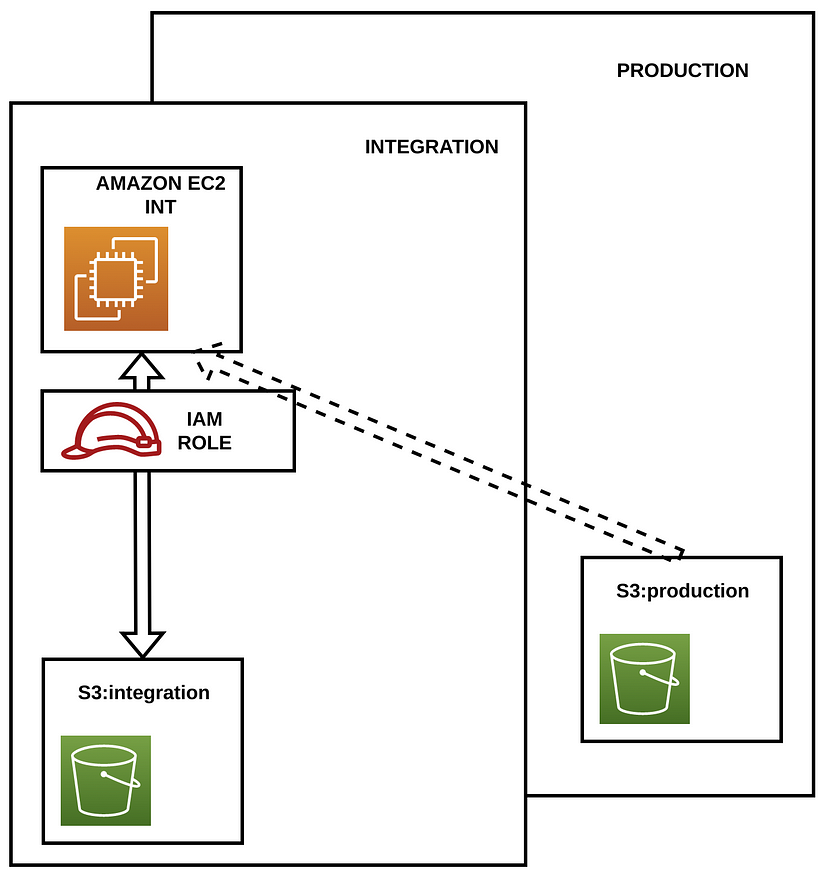
IAM角色配置。
例如,为了能够访问S3集成和生产文件夹,我们可以通过以下方式配置IAM角色:
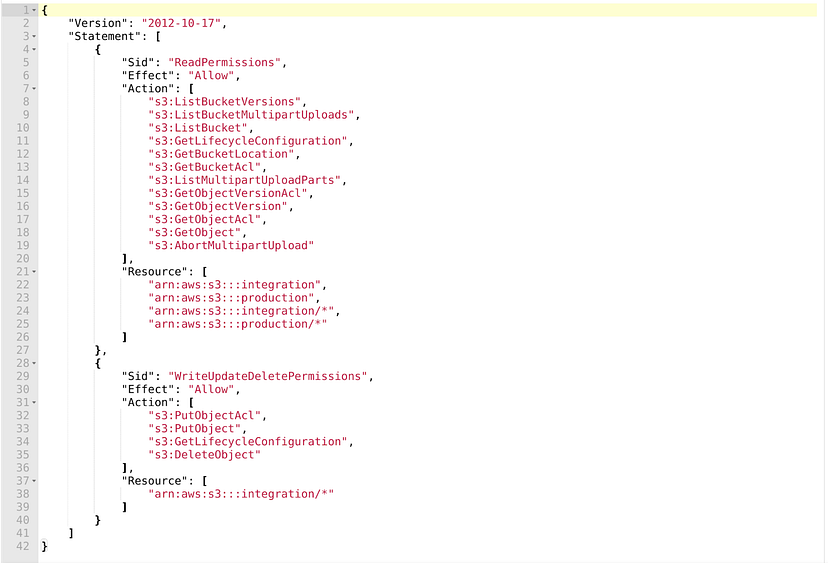
在具有此IAM角色的计算机上运行的任何应用程序都可以从生产和集成中读取数据,并且只能修改位于集成环境中的数据。因此,生产数据不会以任何方式进行修改。
应用解决方案。
一旦我们在IAM角色中应用了上述配置,用户就可以直接访问生产环境中的数据,例如从集成环境中访问。
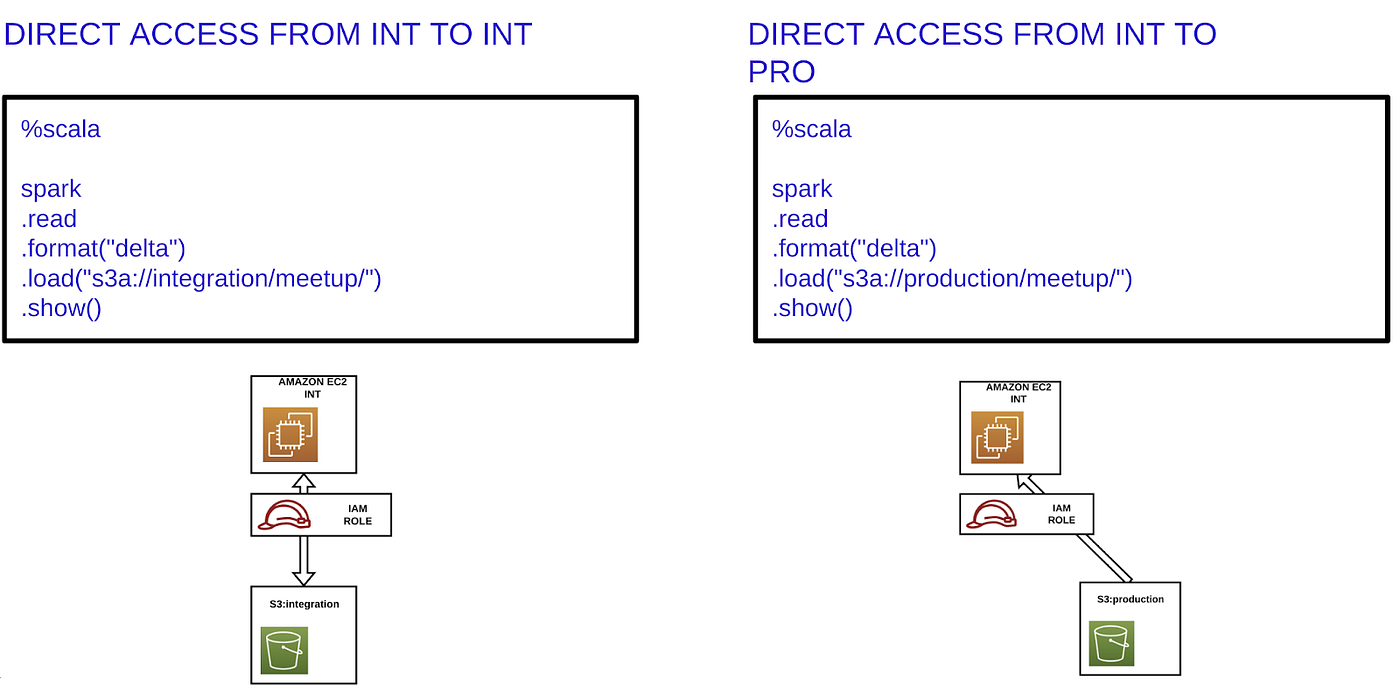
我们能做得更好吗?
有了这种配置,用户,例如他们的笔记本电脑,可以访问生产数据并使用它,而无需修改。但是,我们知道,通过元存储,用户可以更轻松地访问数据。所以问题是:我们可以将元存储与这个解决方案一起使用吗?
我们将在本文的下一节中看到如何做到这一点。
数据湖,共享数据。摇摆舞。
Waggle Dance是一个请求路由配置单元元存储代理,允许在多个配置单元部署中同时访问表。
简而言之,Waggle Dance提供了一个统一的端点,您可以使用它来描述、查询和连接可能存在于多个不同Hive部署中的表。这样的部署可能存在于不同的区域、帐户或云中(安全和网络允许)。
欲了解更多信息,请点击此链接:https://github.com/ExpediaGroup/waggle-dance
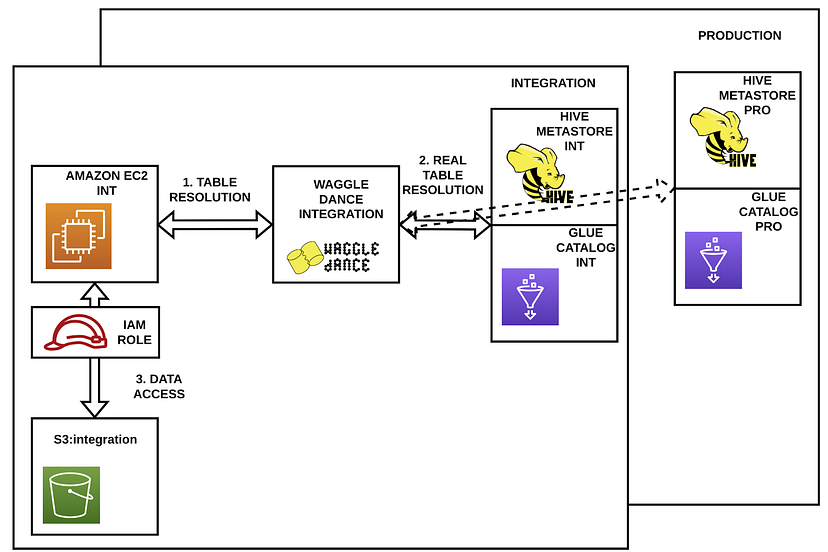
现在,当从集成环境中请求一些表时,并基于一些配置,生活在集成环境中的Waggle Dance决定要请求的元存储是位于生产环境中还是集成环境中。
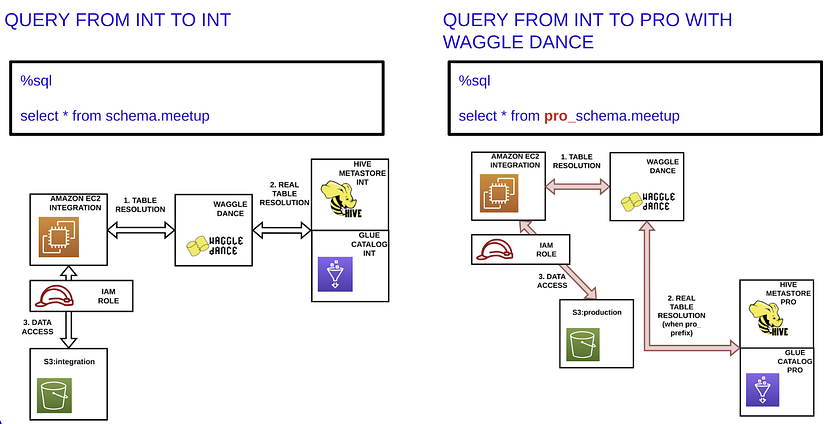
例如,这种配置可以基于某种前缀。在下面的示例中,pro_前缀。使用此前缀时,要检索的数据将位于生产环境中,而不是集成环境中。
结论
通过本文,我们介绍了如何解决AWS S3中实现的数据湖中的以下问题:
- 用户(数据工程师、数据分析师和数据科学家)需要在生产前环境中使用与生产中相同数量的数据。
- 我们希望拥有不同且孤立的环境:集成、生产等。
- 用户需要以最简单的方式处理数据。
请继续关注下一篇关于如何与AWS Redshift共享数据的文章,以及接下来的许多关于如何成功实现自己的数据平台的文章。