
category
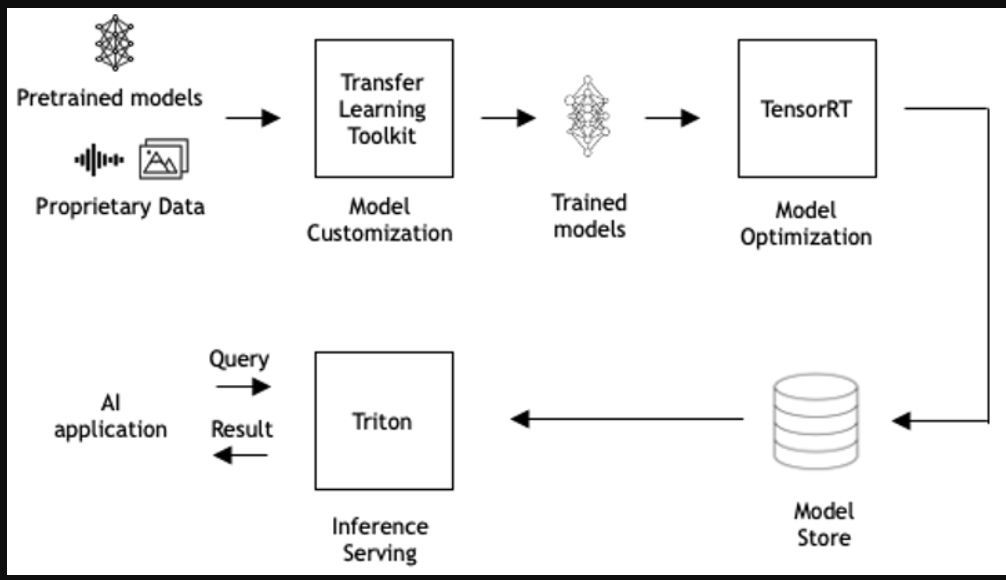
人工智能、机器学习(ML)和深度学习(DL)是解决各种计算问题的有效工具,如产品推荐、客户互动、财务风险评估、制造缺陷检测等。在生产中使用人工智能模型,称为推理服务,是将人工智能融入应用程序中最复杂的部分。Triton推理服务器负责提供推理服务的所有管道,以便您能够专注于应用程序开发。
高效推理服务
每一个人工智能驱动的应用程序都需要推理服务。然而,推理服务是复杂的,原因如下:
- 单个应用程序可以使用来自不同人工智能框架的多个模型以及各种预处理和后处理步骤。推理服务必须支持多个框架后端。
- 有几种类型的查询:
- 实时(在线)——推理服务受到延迟限制。
- 批处理(离线)--推理服务提供高吞吐量。
- 流式处理——推理服务必须保留查询序列。
- 模型可以在公共云、数据中心或企业边缘的GPU和CPU基础设施上运行。
- 必须对模型进行最佳缩放以满足应用程序需求。
- 必须监控模型状态并解决问题,以防止停机。
- 必须优化多个KPI:硬件利用率、模型推出时间和TCO。
有一些推理服务解决方案可以处理其中的一些复杂性,但缺乏许多有效推理服务的优化。
Triton推理服务器
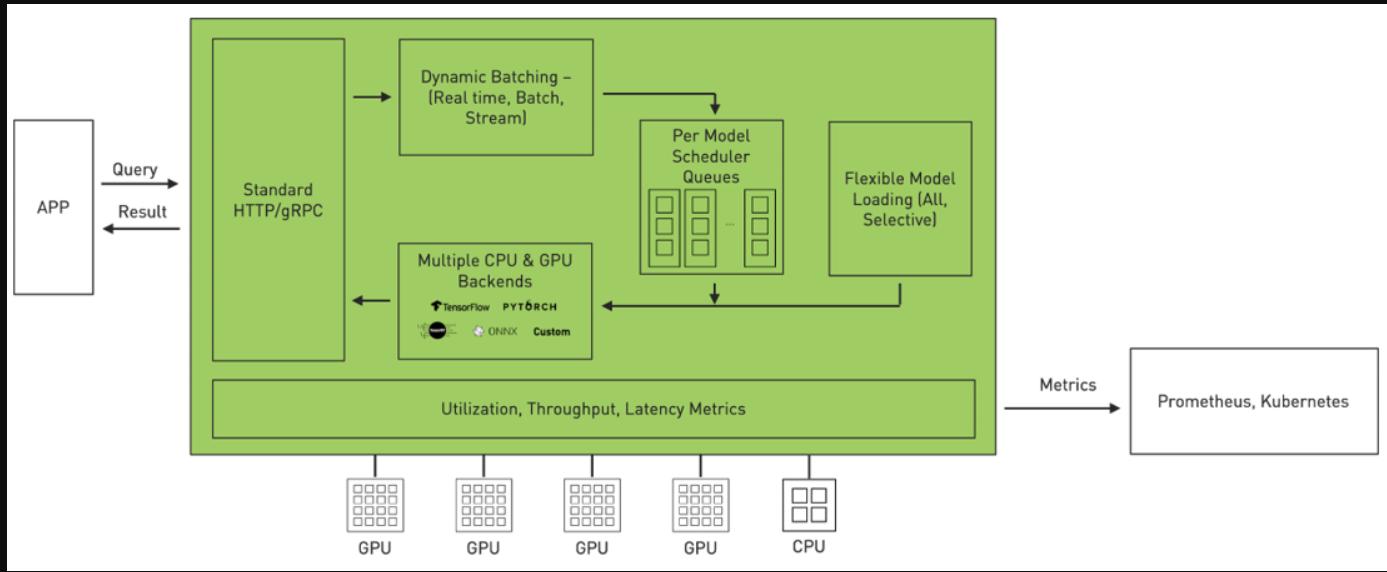
Triton是一款高效的推理服务软件,使您能够专注于应用程序开发。它是一款开源软件,使用所有主要的框架后端进行推理:TensorFlow、PyTorch、TensorRT、ONNX Runtime,甚至C++和Python中的自定义后端。它在三个维度上优化了服务。
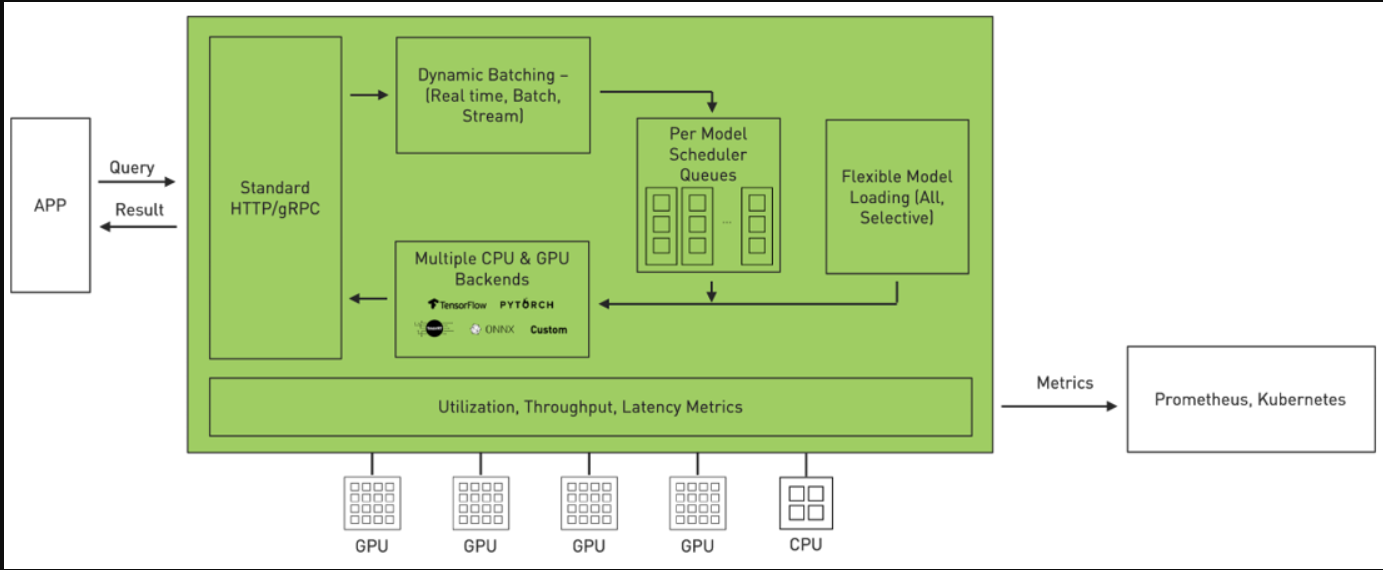
- 利用率:Triton可用于在GPU或CPU上部署模型。它通过动态批处理和并发模型执行等功能最大限度地提高了GPU/CPU的利用率。
- 可扩展性:Triton通过基于微服务的推理提供数据中心和云的规模。它可以部署为容器微服务,为GPU和CPU上的预处理或后处理以及DL模型提供服务。每个Triton实例都可以在类似Kubernetes的环境中独立扩展,以获得最佳性能。来自NGC的单一Helm命令将海卫一部署在Kubernetes。
- 应用程序体验:Triton拥有标准的HTTP/REST和gRPC端点,应用程序使用这些端点进行通信。Triton支持实时、批量和流式推理查询,以获得最佳应用程序体验。可以在Triton中实时更新模型,而不会中断应用程序。Triton提供高吞吐量推理,同时使用动态批处理和并发模型执行来满足紧迫的延迟预算。
宣布推出Triton 2.3
我们很高兴地宣布Triton推理服务器版本2.3。此版本引入了进一步简化缩放推理服务的重要功能:
- Kubernetes无服务器推理
- 支持最新版本的框架后端:TensorRT 7.1、TensorFlow 2.2、PyTorch 1.6和ONNX Runtime 1.4
- Python自定义后端
- 支持NVIDIA A100和MIG
- 解耦推理服务
- Triton模型分析仪
- Microsoft Azure机器学习集成
- NVIDIA DeepStream集成
Kubernetes无服务器推理
Triton是第一个采用KFServing新社区标准gRPC和HTTP/REST数据平面v2协议的推理服务软件。KFServing是基于Kubernetes标准的无服务器推理。
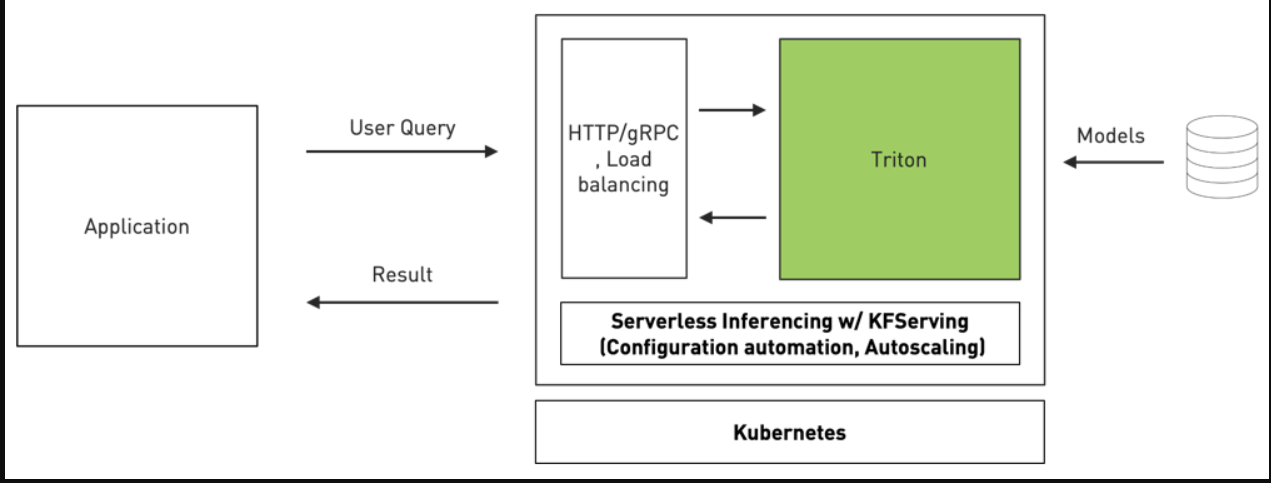
它通过配置自动化和自动扩展简化了Kubernetes中的推理服务部署。它透明地处理负载峰值,因此即使请求数量显著增加,您的服务也能继续平稳工作。有了这种新的集成,组织现在可以在Kubernetes环境中轻松地使用Triton部署高性能推理。
以下代码示例显示了使用Triton部署BERT模型的情况。InferenceService是KFServing引入的自定义资源,您可以在其中指定类型为triton的预测器。正如您所看到的,只有大约30行代码在Kubernetes中使用KFServing和Triton实现了可扩展的推理服务。
apiVersion: "serving.kubeflow.org/v1alpha2" kind: "InferenceService" metadata: name: "bert-large" spec: default: transformer: custom: container: name: kfserving-container image: gcr.io/kubeflow-ci/kfserving/bert-transformer:latest resources: limits: cpu: "1" memory: 1Gi command: - "python" - "-m" - "bert_transformer" env: - name: STORAGE_URI value: "gs://kfserving-samples/models/triton/bert-transformer" predictor: triton: resources: limits: cpu: "1" memory: 16Gi nvidia.com/gpu: 1 storageUri: "gs://nv-enterprise/trtis_models/"
使用KFServing,通过定义转换器,可以很容易地将预处理步骤(如标记化和后处理)包括在部署中。有关更多信息,请参阅GitHub中的samples/triton/bert示例。
Python自定义后端
除了支持C和C++应用程序的现有自定义后端环境外,Triton还添加了一个新的Python自定义后端。Python自定义后端功能强大,因为它允许在Triton内部执行任何任意的Python代码。使用Python代码的常见场景是在神经网络的预处理和后处理中修改张量结构,例如旋转或裁剪图像或推荐工作负载的特征工程。使用Triton中现有的模型集成功能,可以在DL框架后端进行神经网络推理之前和之后执行Python代码。
支持A100和MIG
NVIDIA A100带来了突破性技术,如第三代Tensor Core,可加速不同工作负载的每一个精度,以及多实例GPU(MIG),可将单个A100划分为最多七个GPU实例,以优化GPU利用率并扩大对更多用户的访问。在A100上使用Triton进行推断可提供比V100更高的性能(图4)。与V100相比,带有Triton的A100使用ResNet50 PyTorch模型在吞吐量和延迟方面提高了近3倍。
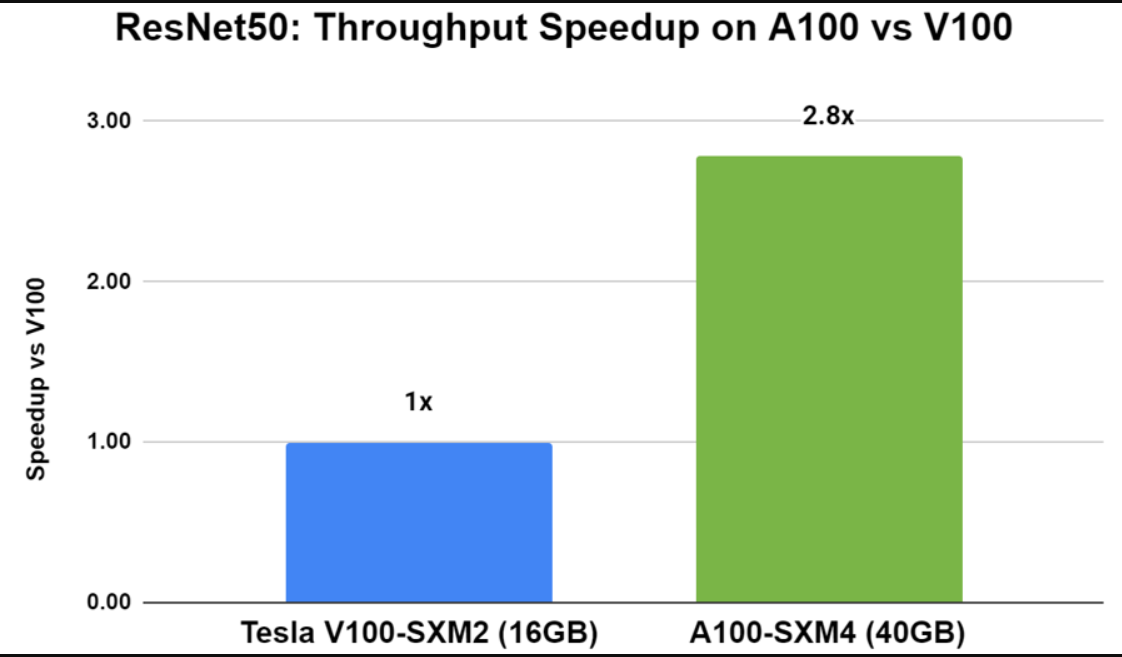
您还可以使用Triton对具有性能和故障隔离的个别MIG实例进行推断。
解耦推理服务
这一特征是语音识别和语音合成等新兴用例所要求的,其中推理结果不依赖于完整推理请求的完成。在这种解耦模式下运行的模型可以逐个请求地决定为请求生成多少响应。例如,在语音识别中,客户端可以以不同的速率向推理服务器发送音频样本,在任何给定时间具有不同数量的样本。解耦模式使Triton能够在接收到足够但并非所有输入时启用模型。在2.3版本中,此功能仅适用于C/C++自定义后端。
Riva Conversational AI平台利用了解耦的推理服务功能,将于今年年底进行公测。有关更多信息和早期访问,请在NVIDIA Riva注册。
Triton模型分析仪
2.3版中的一个关键功能是Triton Model Analyzer,它用于表征模型性能和内存占用,以实现高效服务。它由两个工具组成:
- Triton perf_client工具,将其重命名为perf_analyzer。它有助于为各种批处理大小和请求并发值表征模型的吞吐量和延迟。
- 一种新的内存分析器功能,它有助于为各种批处理大小和请求并发值表征模型的内存占用。
这里是perf_analyzer的输出示例,它有助于确定给定模型的最佳批处理和并发值,显示批处理大小、延迟百分比、吞吐量和并发详细信息。
$ perf_client -m resnet50_netdef --concurrency-range 1:4*** Measurement Settings *** Batch size: 1 Measurement window: 5000 msec Latency limit: 0 msec Concurrency limit: 4 concurrent requests Stabilizing using average latency Request concurrency: 1 Client: Request count: 804 Throughput: 160.8 infer/sec Avg latency: 6207 usec (standard deviation 267 usec) p50 latency: 6212 usec ... Request concurrency: 4 Client: Request count: 1042 Throughput: 208.4 infer/sec Avg latency: 19185 usec (standard deviation 105 usec) p50 latency: 19168 usec p90 latency: 19218 usec p95 latency: 19265 usec p99 latency: 19583 usec Avg HTTP time: 19156 usec (send/recv 79 usec + response wait 19077 usec) Server: Request count: 1250 Avg request latency: 18099 usec (overhead 9 usec + queue 13314 usec + compute 4776 usec) Inferences/Second vs. Client Average Batch Latency Concurrency: 1, 160.8 infer/sec, latency 6207 usec Concurrency: 2, 209.2 infer/sec, latency 9548 usec Concurrency: 3, 207.8 infer/sec, latency 14423 usec Concurrency: 4, 208.4 infer/sec, latency 19185 usec
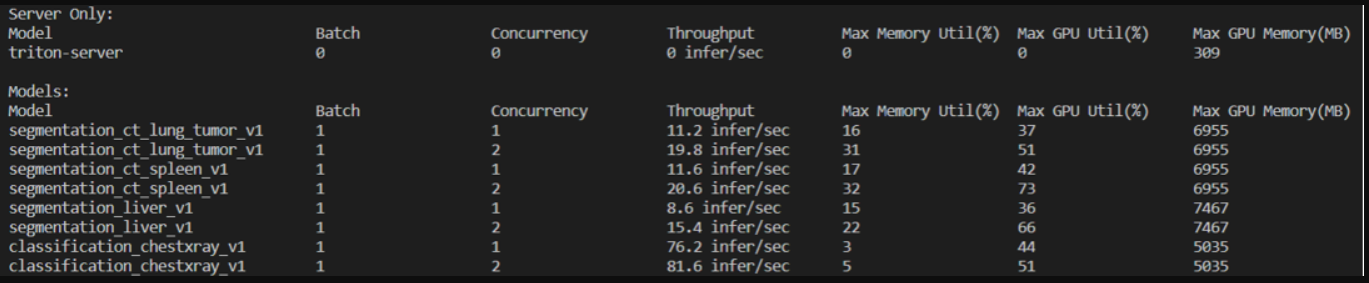
Triton内存分析器提供了许多好处,如将模型优化分配给GPU以避免生产中的内存不足错误,优化模型的内存使用以获得更好的性能,以及为模型确定合适的GPU。图6显示了内存分析器的示例输出,它有助于确定要加载到GPU内存中用于推理服务的模型实例的数量。
Microsoft Azure机器学习集成
在Microsoft Azure机器学习上使用Triton,客户可以在推理过程中获得高性能的推理和更具成本效益的GPU利用率。Triton提供了动态批处理、GPU上的并发执行、对CPU的支持以及包括ONNX Runtime在内的多个框架后端等优势。Azure机器学习提供了一个中央注册表和MLOps功能,以自动为部署的模型和其他ML资产提供版本跟踪和审计跟踪。阅读文档,了解如何在Azure机器学习中使用Triton。
NVIDIA DeepStream集成
NVIDIA DeepStream SDK是一个完整的流媒体分析工具包,用于基于人工智能的多传感器处理、视频和图像理解。通过在DeepStream 5.0中与Triton的本地集成,您可以从TensorRT之外的多个DL框架部署模型,用于NVIDIA T4和Jetson平台的快速原型设计。有关更多信息,请参阅使用NVIDIA DeepStream 5.0构建智能视频分析应用程序。
客户用例
以下是客户如何使用Triton。
微软
微软正在使用人工智能为微软Word在线用户提供语法建议。他们希望以最先进的精度和速度,经济高效地部署基于DL的复杂计算模型。实时语法建议要求200毫秒或更短的延迟预算。
他们使用实时推理服务于Azure机器学习和NVIDIA V100 GPU以及Triton和ONNX Runtime。Triton可以使用动态批处理、并发执行和ONNX运行时集成提供高吞吐量(在一个V100上每秒450次推断)和低延迟(200毫秒)。他们可以在Azure机器学习计算V100 GPU上实现三分之一的低成本。有关更多信息,请参阅NVIDIA AI on Microsoft Azure Machine Learning to Power Grammar Suggestions in Microsoft Editor For Word。
美国运通
美国运通服务拥有1.44亿张卡,年交易量超过80亿笔。他们希望构建和部署一个实时(低于2ms)的欺诈检测系统,同时使用ML和DL来提高准确性。
他们使用Triton部署了一个TensorRT优化的门控循环单元模型,以使用配备T4的服务器分析数千万笔日常事务。这种增强的实时欺诈检测系统在2毫秒的延迟预算内运行,与无法满足延迟要求的CPU相比,提高了50倍。
韩国NAVER网
Naver是韩国顶级的搜索引擎和互联网服务公司。他们将DL用于实时图像分类、搜索推荐和其他用途。多种框架(TensorFlow、PyTorch、Caffe和TensorRT)的使用减缓了新人工智能模型的及时引入。此外,管理成本高昂。
他们采用Triton是因为它支持多个框架以及GPU和CPU上的真实、批处理和流式推理。Triton为他们提供了一个单一的推理平台,允许从多个框架更快地推出新的DL模型,并降低Naver的运营成本。
SPIL
SPIL是世界上最大的外包半导体组装和测试公司。作为晶圆碰撞服务的一部分,他们每天在一条生产线上检查约30000张晶圆图像,以寻找缺陷。他们目前的自动光学检查(AOI)平台产生了70%的假阳性,然后需要进行第二次筛查。
SPIL使用DL模型(U-Net、DenseNet和Autoencoder),使用NVIDIA T4 GPU、TensorRT和Triton进行二级筛选。他们现在可以检测100%的缺陷,所有装配线晶圆的假阳性率低于10%。Triton的动态模型加载和卸载帮助他们在不改变服务基础设施的情况下扩展到100个不同的模型。
Tracxpoint
Tracxpoint是一家零售技术公司,创建了一款名为AiC的DL动力实体购物车。有了AiC,购物者可以将产品放在购物车中,然后实时收到个性化的产品优惠,轻松浏览超市,并进行数字支付。
Tracxpoint在NVIDIA T4 Tensor Core GPU上使用TensorFlow和TensorRT优化模型,使用Triton进行实时推理。AiC可以在不到一秒钟的时间内识别出100000种产品。每天对模型进行再培训,Tracxpoint可以在Triton中无缝更新,不会对用户造成干扰。
结论
Triton简化了大规模生产中AI和DL模型的部署。它支持所有主要的框架,同时运行多个模型以提高吞吐量和利用率,同时支持GPU和CPU,并与Kubernetes集成以进行扩展推理。
从NGC下载Triton推理服务器2.3版,并从Triton推理机/服务器GitHub repo访问源代码。
- 登录 发表评论
- 150 次浏览
Tags
最新内容
- 1 day 7 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago