
category
MDP在行动:用RL和AI解决现实问题的下一步

欢迎回到我的AI博客!现在我们已经了解了马尔可夫属性和马尔可夫链,这是我在强化学习第2部分中介绍的,我们准备讨论马尔可夫决策过程(MDP)。
在本文中,我们将使用一个简单的例子来解释机器学习的这个经典概念。
到最后,您将掌握以下基本知识:
- 马尔可夫决策过程是如何定义的;
- MDP如何通过一个简单的例子工作;
- 为什么以及如何使用折扣奖励。
为什么我们需要了解MDP
为了理解为什么MDP对强化学习如此重要,我们必须回顾强化学习第1部分中定义的四个必要元素。这些是代理、环境、行动和奖励。如果你能在MDP中构建你的任务,恭喜你!你定义了你的环境。现在,你有了一个空间,代理人可以在那里采取行动、获得奖励和学习。
MDP是一个框架,可以解决大多数具有离散动作的强化学习问题。通过马尔可夫决策过程,代理可以随着时间的推移得出最佳策略(我们将在下周讨论),以获得最大的回报。
现在,为了建立对这是如何运作的实际理解,让我们提出我们的示例任务:今天,我们将帮助一个名叫亚当的年轻人做出连续的决定,以赚取尽可能多的钱。
定义马尔可夫决策过程(MDP)
在阅读了我上一篇文章后,你应该对马尔可夫属性是什么以及当我们使用马尔可夫链时它是什么样子有了一个很好的了解。这意味着我们已经准备好深入探讨MDP的基本强化学习概念。
回想一下我们对马尔可夫链的讨论,它与S(一组状态)和P(从一个状态转换到下一个状态的概率)一起工作。它还使用马尔可夫属性,这意味着每个状态只依赖于它之前的状态。
现在,马尔可夫决策过程与马尔可夫链的不同之处在于,它使行动发挥作用。这意味着下一个状态不仅与当前状态本身有关,还与在当前状态下采取的行动有关。此外,在MDP中,与状态相对应的一些操作可以返回奖励。
事实上,MDP的目的是训练一个代理找到一个策略,该策略将从在一个或多个州采取一系列行动中获得最大的累积奖励。
这是一个公式化的定义,如果你在谷歌上搜索马尔可夫决策过程,你可能会得到这个定义:

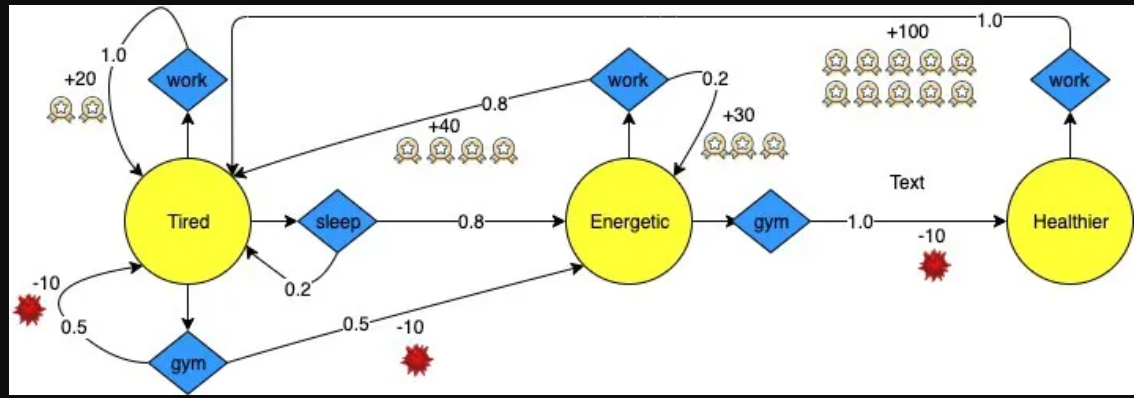
现在,让我们将此框架应用于上图2,以便更具体地理解这些抽象注释:

▶️ MDP在行动:Adam学习
以亚当为例,我们可以通过故事更容易地理解这一点。众所周知,这个勤奋的年轻人想尽可能多地赚钱。使用上面定义的框架,我们可以帮助他做到这一点。
▶️ 当Adam感到疲倦时,他可以从三个动作中选择一个:(1)继续工作,(2)去健身房,(3)睡一会儿。
如果他选择工作,他仍然处于疲惫状态,肯定会得到+20的奖励。如果他选择睡觉,他有80%的机会进入下一个状态,精力充沛,有20%的机会保持疲劳。
如果他不想睡觉,他可能会去健身房锻炼。这给了他50%的机会进入精力充沛的状态,50%的机会保持疲劳。然而,他需要支付健身房的费用,所以这个选择会得到-10的奖励。
▶️ 当Adam变得精力充沛时,他可以回去工作,效率更高。从那时起,他有80%的机会再次感到疲倦(奖励+40),有20%的机会保持活力(奖励+30)。
有时,当他精力充沛时,他想锻炼身体。当他在这种状态下锻炼时,他玩得很开心,100%变得更健康。当然,他需要支付-10的奖励。
▶️ 一旦他达到更健康的状态,他脑子里只有一件事:通过做更多的工作赚更多的钱。因为他处于如此良好的状态,所以他以最高的效率工作,获得+100的奖励,并一直工作到再次疲劳。
有了上述信息,我们可以训练一个代理,旨在帮助Adam找到最佳策略,随着时间的推移最大限度地提高他的回报。该代理将执行马尔可夫决策过程。
然而,在我们这样做之前,我们需要知道如何计算在一个状态下采取行动时的累积奖励。也就是说,我们必须能够估计状态值。
别担心!这只需要一分钟的时间。
折扣奖励
正如我在RL介绍中所了解到的,强化学习是一个多决策过程。与监督学习的“一个实例,一个预测”模型不同,强化学习代理的目标是最大化一系列决策的累积回报,而不仅仅是一个决策的即时回报。
它要求代理人展望未来,同时收集当前的奖励。
在亚当上面的例子中,未来的奖励和当前的奖励一样重要。但在我们在这里讨论的CartPole游戏中,活在当下比什么都重要。
由于未来奖励的价值可能因场景而异,因此我们需要一种机制来降低未来奖励在不同时间步的重要性。

上述贴现率或系数符号是该机制的关键。它计算的奖励称为折扣奖励。
 述信息。如果折扣率接近0,那么与即时奖励相比,未来的奖励就不重要了。相比之下,如果折现率接近1,那么遥远的未来的奖励几乎和即时奖励一样重要。
述信息。如果折扣率接近0,那么与即时奖励相比,未来的奖励就不重要了。相比之下,如果折现率接近1,那么遥远的未来的奖励几乎和即时奖励一样重要。
简而言之,折扣奖励是我们如何估计一个州的价值。
总结
到目前为止,在强化学习系列中,我们学到了:
- 什么是强化学习,以及如何在日常生活中使用它。
- 马尔可夫属性和链如何生成单词。
- 现在,我们知道如何使用MDP和折扣奖励。
有了MDP,我们可以帮助亚当做出决定,在不损害健康的情况下保证最大的收入。在现实世界中,你可以收集反映现实的数据,分析统计数据,并创建有效的MDP来解决各种问题!
下周回来学习如何使用MDP进行最佳策略搜索。
- 登录 发表评论
- 37 次浏览
最新内容
- 1 day 3 hours ago
- 2 weeks ago
- 3 weeks 1 day ago
- 3 weeks 5 days ago
- 2 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago