

数据科学在过去十年中呈爆炸式增长,改变了我们开展业务的方式,并让下一代年轻人为未来的工作做好准备。但是这种快速增长伴随着对数据科学工作的不断发展的理解,这导致我们在如何使用数据科学从我们的大量数据中获得可操作的见解方面存在很多模糊性。在数据科学的发展塑造了我自己的职业生涯之后,我想深入研究什么是数据科学、数据科学的工作是什么以及谁是数据科学家等问题。我翻阅了研究文献,以提取关于数据科学和数据科学家的各种研究和分析的线索,将这些问题的答案编织在一起。我在一篇题为“传递数据指挥棒:对数据科学工作和工作者的回顾性分析”的研究出版物中介绍了这些结果。
这项研究的部分动机是作为研究和开发的基础,以便我可以确定可视化分析工具可能解决未满足需求的领域。然而,另一个动机是对一个十多年前我第一次开始计算机科学高级研究时还不存在的领域的个人反思。在这篇博文中,我总结了这篇研究论文的几个关键要点,并分享了我对它的发现如何帮助我们为数据科学构建下一代数据可视化工具的想法。
什么是数据科学?

事实证明,数据科学对不同的人来说是不同的东西。对某些人来说,数据科学并不是什么新鲜事物,它只是已经存在很长时间的统计技术的实际应用。对其他人来说,这种观点过于狭隘,因为数据科学不仅需要统计方法的知识,还需要计算技术才能使这些方法的应用变得实用。例如,数据科学家仅了解线性回归是不够的,他们还需要知道如何将其大规模应用于大量数据——这不是传统统计学教育的一部分。尽管如此,即使是那些认为数据科学不仅仅是应用统计学的人也可能会犹豫说它是新事物。收集和分析数据(甚至是大量数据)的做法长期以来一直是科学研究的一部分,例如生物学或物理学;许多人认为数据科学只是经验科学中已经发生的事情的延伸。
但这里还有第三种观点,即数据科学确实是新事物,既不同于统计学,也不同于科学家在研究原子和基因时使用的方法。将统计学和计算机科学与必要的主题专业知识结合在一起,带来了新的挑战,这些挑战由数据科学独特地解决,并由数据科学家解决。此外,数据科学家开展的工作不同于其他类型的数据分析,因为它需要更广泛的多学科技能。我们的研究和其他人的研究认为,数据科学确实是新的和不同的东西,因此我们创建了一个工作定义,作为我们工作的基础:
“数据科学是一个多学科领域,旨在通过主要统计和计算技术的结构化应用, 从现实世界的数据中学习新的见解”
这个定义很重要,因为它有助于我们理解数据科学工作者面临的挑战和未满足的需求,这主要源于使用真实数据而不是模拟数据的挑战,以及伴随应用统计和计算方法的挑战这些数据大规模。
什么是数据科学工作?
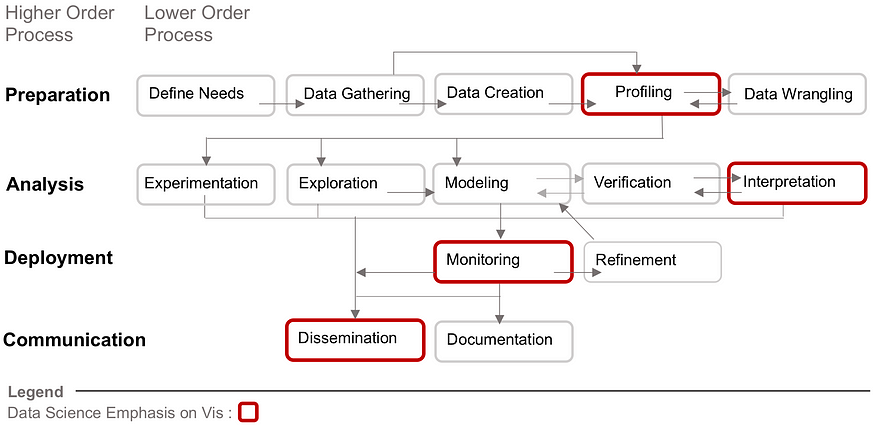
- 将数据科学工作提炼成四个高阶(准备、分析、部署和通信)和 14 个低阶过程。 红色标出的过程是主要使用数据可视化的过程,但这并不排除它在数据科学工作的其他方面的使用。
重要的是,数据科学的工作定义缩小了研究范围。我们没有考虑人们可能希望进行的所有可能类型的数据分析,而是仔细研究数据科学家进行的分析类型。这种区别很重要,因为实验物理学家分析数据所采取的具体步骤与数据科学家可能采取的分析步骤不同,即使它们有共同点。这导致了一个重要的后续问题:数据科学的工作到底是什么?
有几个行业标准用于分解数据科学工作。第一个是 KDD(或数据发现中的知识)方法,随着时间的推移,它被其他人修改和扩展。根据这些推导以及采访数据科学家的研究,我们创建了一个框架,该框架具有四个高阶流程(准备、分析、部署和通信)和 14 个低阶流程。使用红色笔划轮廓,我们还强调了数据可视化已经在数据科学工作中发挥重要作用的特定领域。在我们的研究文章中,我们提供了这些过程的详细定义和示例。
谁是数据科学工作者?

Nine Data Science roles that we found across twelve in depth studies with Data Scientists
这些年来,我听到了很多关于数据科学家是什么的不同看法。我喜欢的一个观点是,数据科学家是“比统计学家更擅长软件工程,比软件工程师更擅长统计”的人。我最近听到的一种厚颜无耻的说法是,数据科学家是“西海岸的统计学家”。
然而,当我们深入研究对数据科学家的现有研究时,我们没有预料到会发现一些东西,但它变得一致且重要,那就是“数据科学家”的多样性以及他们的角色如何在特定的数据科学过程中发生变化。例如,您可能已经注意到数据工程师的崛起,作为一个独特但仍然相邻的数据科学角色。随着数据科学工作的复杂性增加,数据科学家变得不那么笼统而更加专业,他们经常从事数据科学工作的特定方面。哈里斯等人进行的采访。早在 2012 年就已经确定了这一趋势,而且随着时间的推移,这种趋势只会加速。他们敏锐地观察到,数据科学角色之间的这种多样性导致“数据科学家与寻求帮助的人之间的沟通不畅”。
我们在 Harris 工作的结果的基础上,检查了 12 项研究,总计数千名被认定为数据科学家的人。从我们对这些研究的元分析中,我们能够确定 9 个不同的数据角色。这些人具有不同的技能和背景,我们沿着统计、计算机科学和领域专业知识的轴进行了说明。我们还将以人为本的设计纳入我们对数据科学技能的描述中,因为考虑到数据产品(如面部识别应用程序)的影响越来越重要。我们要强调的是,这些角色不是绝对的类别,它们的界限以及担任这些角色的这些人的技术技能强度是流动的。相反,这些类别的角色旨在作为指导,帮助研究人员和其他人了解他们正在与谁交谈以及他们的背景可能是什么。
这将如何改变我们构建可视化和数据分析工具的方式?
当然,最重要的考虑是我们对数据科学的定义以及我们的数据科学工作和工作者框架如何帮助我们构建更好的数据可视化工具。首先,它有助于明确数据科学工作和工作人员的多样性并以证据为基础。我们已经使用这个框架来创建更清晰的标准来分解数据科学中的 Tableau 客户体验。我们可以更精确地确定他们正在尝试做什么,并且可以就这些过程提出更多探索性的问题。知道“数据科学家”这个角色本身包含大量的多样性,我们可以通过将我们正在与之交谈的个人分类为我们的九个数据科学角色来更好地确定谁在执行这项工作。这样的分类使我们更容易理解我们的可视化系统需要支持的任务以及在什么级别上。例如,技术分析师和 ML/AI 工程师,这是我们描述的两个数据科学角色,都可以从事模型构建的共同任务,但需求却截然不同;如果我们忽略这些差异,我们就有可能为这两个角色构建错误的工具。
但也许对我来说最重要的是,这个框架还帮助我思考当前的可视化分析工具生态系统中缺少什么。我得出的一个令人担忧的结论是,现有工具只专注于可视化机器学习模型,并且缺乏支持数据科学工作其他关键方面的工具,例如数据准备、部署或通信。这种工具的缺乏不仅增加了数据科学工作的开销,而且还使数据科学家无论担任什么角色,都更难以让他们的工作影响组织决策和实践。这项关于数据科学工作和工作者的研究帮助我发现了这些挑战,并为构建更好的工具来帮助人们查看和理解他们的数据定义了机会。
原文:https://engineering.tableau.com/reflecting-on-a-decade-of-data-science-…
最新内容
- 1 day 23 hours ago
- 2 weeks 1 day ago
- 3 weeks 2 days ago
- 3 weeks 6 days ago
- 2 months 2 weeks ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago
- 6 months 1 week ago