
category
大型语言模型(LLM)擅长生成类似人类的文本,但面临着一个关键的挑战:幻觉——产生听起来令人信服但实际上不正确的反应。虽然这些模型是在大量通用数据上训练的,但它们往往缺乏在业务环境中准确响应所需的特定于组织的上下文和最新信息。检索增强生成(RAG)技术通过在推理过程中将LLM建立在相关数据中来帮助解决这个问题,但即使给出了准确的源材料,这些模型仍然可以生成非确定性输出,偶尔也会制造信息。对于在生产应用程序中部署LLM的组织来说,特别是在医疗保健、金融或法律服务等关键领域,这些残留的幻觉会带来严重的风险,可能会导致错误信息、责任问题和用户信任的丧失。
为了应对这些挑战,我们引入了一种实用的解决方案,将LLM的灵活性与起草、策划、验证的答案的可靠性相结合。我们的解决方案使用两个关键的亚马逊基岩服务:亚马逊基岩知识库,这是一个完全托管的服务,您可以使用它来存储、搜索和检索特定于组织的信息,以供LLM使用;以及Amazon Bedrock Agents,这是一种完全托管的服务,可用于构建、测试和部署能够理解用户请求、将其分解为步骤并执行操作的AI助手。与客户服务团队如何维护一组精心设计的常见问题(FAQ)答案类似,我们的解决方案首先检查用户的问题是否与精心策划和验证的答案相匹配,然后让LLM生成新的答案。这种方法通过尽可能使用可信信息来帮助防止幻觉,同时仍然允许LLM处理新的或独特的问题。通过实施这项技术,组织可以提高响应准确性,缩短响应时间,降低成本。无论你是人工智能开发的新手还是经验丰富的从业者,这篇文章都提供了分步指导和代码示例,以帮助你构建更可靠的人工智能应用程序。
解决方案概述
我们的解决方案使用Amazon Bedrock知识库检索API实现了经过验证的语义缓存,以减少LLM响应中的幻觉,同时提高延迟并降低成本。这个只读语义缓存充当用户和亚马逊基岩代理之间的智能中介层,存储经过策划和验证的问答对。
当用户提交查询时,解决方案首先评估其与知识库中现有已验证问题的语义相似性。对于高度相似的查询(匹配率大于80%),该解决方案完全绕过LLM,直接返回经过策划和验证的答案。当发现部分匹配(60-80%相似性)时,该解决方案使用经过验证的答案作为少数镜头示例来指导LLM的响应,显著提高了准确性和一致性。对于相似度低(低于60%)或不匹配的查询,解决方案会退回到标准的LLM处理,确保用户问题得到适当的回答。
这种方法有几个关键好处:
- 降低成本:通过最大限度地减少对常见问题的不必要的LLM调用,该解决方案显著降低了大规模的运营成本
- 提高准确性:经过精心策划和验证的答案最大限度地减少了已知用户查询产生幻觉的可能性,而很少有镜头提示可以提高类似问题的准确性。
- 更低的延迟:直接检索缓存的答案可以为已知查询提供近乎即时的响应,从而改善整体用户体验。
语义缓存作为一个不断增长的可信响应存储库,不断提高解决方案的可靠性,同时保持处理用户查询的效率。
方案架构
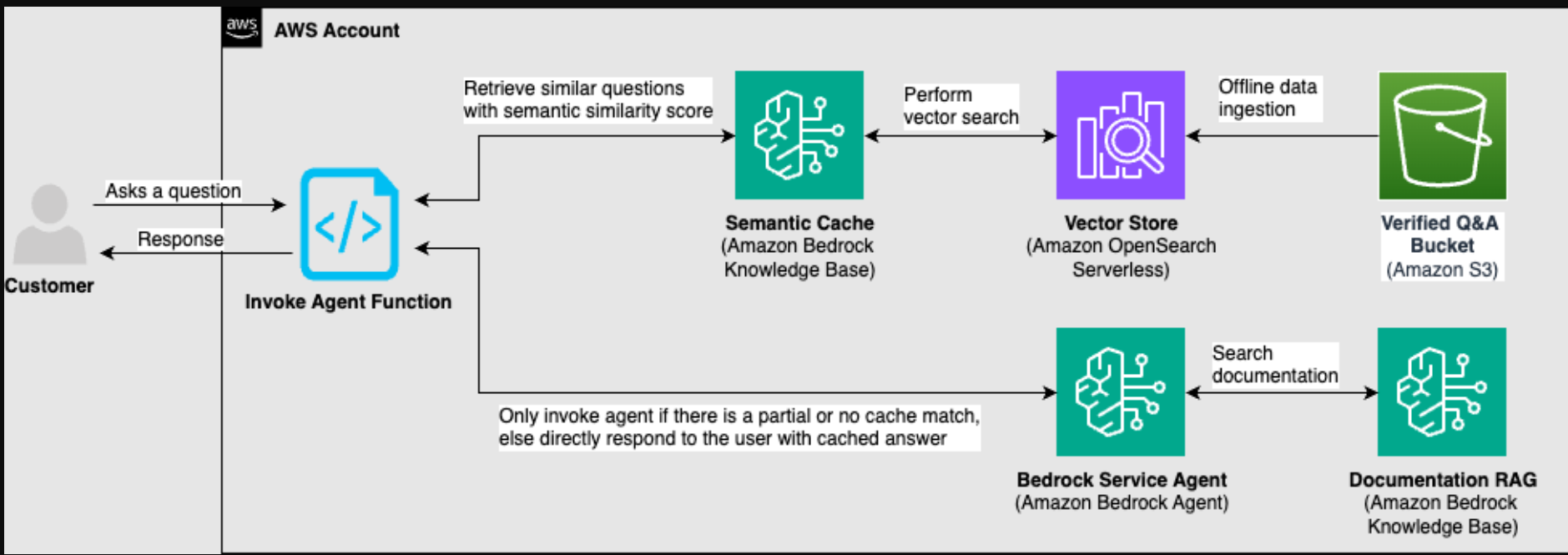
The solution architecture in the preceding figure consists of the following components and workflow. Let’s assume that the question “What date will AWS re:invent 2024 occur?” is within the verified semantic cache. The corresponding answer is also input as “AWS re:Invent 2024 takes place on December 2–6, 2024.” Let’s walkthrough an example of how this solution would handle a user’s question.
1. Query processing:
a. User submits a question “When is re:Invent happening this year?”, which is received by the Invoke Agent function.
b. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
c. Amazon Bedrock Knowledge Bases performs a semantic search and finds a similar question with an 85% similarity score.
2. Response paths: (Based on the 85% similarity score in step 1.c, our solution follows the strong match path)
a. Strong match (similarity score greater than 80%):
i. Invoke Agent function returns exactly the verified answer “AWS re:Invent 2024 takes place on December 2–6, 2024” directly from the Amazon Bedrock knowledge base, providing a deterministic response.
ii. No LLM invocation needed, response in less than 1 second.
b. Partial match (similarity score 60–80%):
i. The Invoke Agent function invokes the Amazon Bedrock agent and provides the cached answer as a few-shot example for the agent through Amazon Bedrock Agents promptSessionAttributes.
ii. If the question was “What’s the schedule for AWS events in December?”, our solution would provide the verified re:Invent dates to guide the Amazon Bedrock agent’s response with additional context.
iii. Providing the Amazon Bedrock agent with a curated and verified example might help increase accuracy.
c. No match (similarity score less than 60%):
i. If the user’s question isn’t similar to any of the curated and verified questions in the cache, the Invoke Agent function invokes the Amazon Bedrock agent without providing it any additional context from cache.
ii. For example, if the question was “What hotels are near re:Invent?”, our solution would invoke the Amazon Bedrock agent directly, and the agent would use the tools at its disposal to formulate a response.
3. Offline knowledge management:
a. Verified question-answer pairs are stored in a verified Q&A Amazon S3 bucket (Amazon Simple Storage Service), and must be updated or reviewed periodically to make sure that the cache contains the most recent and accurate information.
b. The S3 bucket is periodically synchronized with the Amazon Bedrock knowledge base. This offline batch process makes sure that the semantic cache remains up-to-date without impacting real-time operations.
Solution walkthrough
You need to meet the following prerequisites for the walkthrough:
- An AWS account
- Model access to Anthropic’s Claude Sonnet V1 and Amazon Titan Text Embedding V2
- AWS Command Line Interface (AWS CLI) installed and configured with the appropriate credentials
Once you have the prerequisites in place, use the following steps to set up the solution in your AWS account.
Step 0: Set up the necessary infrastructure
Follow the “Getting started” instructions in the README of the Git repository to set up the infrastructure for this solution. All the following code samples are extracted from the Jupyter notebook in this repository.
Step 1: Set up two Amazon Bedrock knowledge bases
This step creates two Amazon Bedrock knowledge bases. The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
This establishes the foundation for your semantic caching solution, setting up the AWS resources to store the agent’s knowledge and verified cache entries.
Step 2: Populate the agent knowledge base and associate it with an Amazon Bedrock agent
For this walkthrough, you will create an LLM Amazon Bedrock agent specialized in answering questions about Amazon Bedrock. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset. After ingesting the data, you create an agent with specific instructions:
This setup enables the Amazon Bedrock agent to use the ingested knowledge to provide responses about Amazon Bedrock services. To test it, you can ask a question that isn’t present in the agent’s knowledge base, making the LLM either refuse to answer or hallucinate.
Step 3: Create a cache dataset with known question-answer pairs and populate the cache knowledge base
In this step, you create a raw dataset of verified question-answer pairs that aren’t present in the agent knowledge base. These curated and verified answers serve as our semantic cache to prevent hallucinations on known topics. Good candidates for inclusion in this cache are:
- Frequently asked questions (FAQs): Common queries that users often ask, which can be answered consistently and accurately.
- Critical questions requiring deterministic answers: Topics where precision is crucial, such as pricing information, service limits, or compliance details.
- Time-sensitive information: Recent updates, announcements, or temporary changes that might not be reflected in the main RAG knowledge base.
By carefully curating this cache with high-quality, verified answers to such questions, you can significantly improve the accuracy and reliability of your solution’s responses. For this walkthrough, use the following example pairs for the cache:
Q: 'What are the dates for reinvent 2024?'
A: 'The AWS re:Invent conference was held from December 2-6 in 2024.'
Q: 'What was the biggest new feature announcement for Bedrock Agents during reinvent 2024?'
A: 'During re:Invent 2024, one of the headline new feature announcements for Bedrock Agents was
the custom orchestrator. This key feature allows users to implement their own orchestration strategies
through AWS Lambda functions, providing granular control over task planning, completion,
and verification while enabling real-time adjustments and reusability across multiple agents.'You then format these pairs as individual text files with corresponding metadata JSON files, upload them to an S3 bucket, and ingest them into your cache knowledge base. This process makes sure that your semantic cache is populated with accurate, curated, and verified information that can be quickly retrieved to answer user queries or guide the agent’s responses.
Step 4: Implement the verified semantic cache logic
In this step, you implement the core logic of your verified semantic cache solution. You create a function that integrates the semantic cache with your Amazon Bedrock agent, enhancing its ability to provide accurate and consistent responses.
- Queries the cache knowledge base for similar entries to the user question.
- If a high similarity match is found (greater than 80%), it returns the cached answer directly.
- For partial matches (60–80%), it uses the cached answer as a few-shot example for the agent.
- For low similarity (less than 60%), it falls back to standard agent processing.
This simplified logic forms the core of the semantic caching solution, efficiently using curated and verified information to improve response accuracy and reduce unnecessary LLM invocations.
Step 5: Evaluate results and performance
This step demonstrates the effectiveness of the verified semantic cache solution by testing it with different scenarios and comparing the results and latency. You’ll use three test cases to showcase the solution’s behavior:
- Strong semantic match (greater than 80% similarity)
- Partial semantic match (60-80% similarity)
- No semantic match (less than 60% similarity)
Here are the results:
-
Strong semantic match (greater than 80% similarity) provides the exact curated and verified answer in less than 1 second.
-
Partial semantic match (60–80% similarity) passes the verified answer to the LLM during the invocation. The Amazon Bedrock agent answers the question correctly using the cached answer even though the information is not present in the agent knowledge base.
-
No semantic match (less than 60% similarity) invokes the Amazon Bedrock agent as usual. For this query, the LLM will either refuse to provide the information because it’s not present in the agent’s knowledge base, or will hallucinate and provide a response that is plausible but incorrect.
These results demonstrate the effectiveness of the semantic caching solution:
- Strong matches provide near-instant, accurate, and deterministic responses without invoking an LLM.
- Partial matches guide the LLM agent to provide a more relevant or accurate answer.
- No matches fall back to standard LLM agent processing, maintaining flexibility.
The semantic cache significantly reduces latency for known questions and improves accuracy for similar queries, while still allowing the agent to handle unique questions when necessary.
Step 6: Resource clean up
Make sure that the Amazon Bedrock knowledge bases that you created, along with the underlying Amazon OpenSearch Serverless collections are deleted to avoid incurring unnecessary costs.
生产准备考虑因素
在将此解决方案部署到生产环境之前,请解决以下关键问题:
- 相似性阈值优化:尝试不同的阈值来平衡缓存命中率和准确性。这直接影响了解决方案在保持相关性的同时预防幻觉的有效性。
- 反馈循环实现:创建一种机制,用新的、准确的响应不断更新经过验证的缓存。这有助于防止缓存过时,并保持解决方案作为LLM真实来源的完整性。
- 缓存管理和更新策略:定期用当前常见问题刷新语义缓存,以保持相关性并提高命中率。实施一个系统化的流程,用于审查、验证和合并新条目,以帮助确保缓存质量并与不断变化的用户需求保持一致。
- 持续调整:随着数据集的发展调整相似性阈值。将语义缓存视为一个动态组件,需要针对您的特定用例进行持续优化。
结论
这种经过验证的语义缓存方法提供了一种强大的解决方案,可以减少LLM响应中的幻觉,同时改善延迟并降低成本。通过使用亚马逊基岩知识库,您可以实现一个解决方案,该解决方案可以有效地提供经过策划和验证的答案,用很少的镜头示例指导LLM响应,并在需要时优雅地回退到完整的LLM处理。
- 登录 发表评论
- 34 次浏览
Tags
最新内容
- 5 days 13 hours ago
- 1 week 2 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago