
category

如果你在读这个博客,你可能已经意识到Scylla 提供的力量和速度。也许您已经在生产中使用Scylla 来支持高I/O实时应用程序。但是当你遇到一个需要一些本地Scylla 不易实现的特性的问题时,会发生什么呢?
我最近在一家大型网络安全公司从事主数据管理(MDM)项目。他们的分析团队希望为业务用户提供更好、更快、更具洞察力的客户和供应链活动视图。
但是,任何试图构建这样一个解决方案的人都知道,主要的困难之一是包含现有数据源的绝对数量和复杂性。这些数据源通常作为独立设计和实现的系统的后端。每一个都包含了客户活动的整体情况。为了提供一个真正的解决方案,我们需要能够将这些不同的数据放在一起。
这个过程不仅需要性能和可伸缩性,还需要灵活性和快速迭代的能力。我们试图揭示重要的关系,并使它们成为数据模型本身的一个明确部分。
以JanusGraph为基础,以Scylla 为后盾的图形数据系统非常适合解决这一问题。
什么是图形数据系统?
我们将它分成两部分:
- 图形-我们将数据建模为图形,顶点和边表示我们的每个实体和关系
- 数据系统-我们将使用几个组件来构建一个单一的系统来存储和检索我们的数据
市场上有几种图形数据库的选择,但是当我们需要可伸缩性、灵活性和性能的结合时,我们可以寻找由JanusGraph、Scylla和Elasticsearch构建的系统。
在较高的层次上,它看起来是这样的:
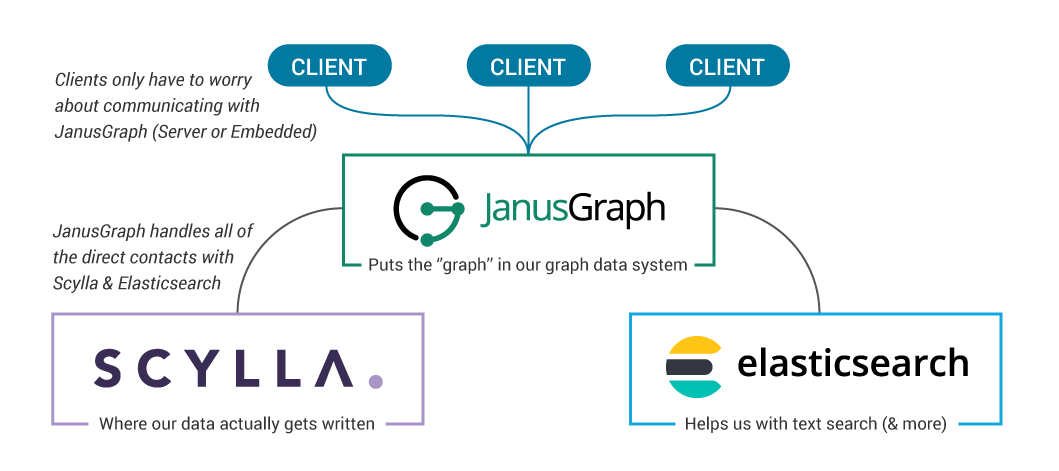
让我们重点介绍这个数据系统真正闪耀的三个核心领域:
- 灵活性
- 模式/纲要支持
- OLTP+OLAP支持
1 . 灵活性
虽然我们当然关心数据加载和查询性能,但图形数据系统的致命特性是灵活性。大多数数据库在启动后都会将您锁定到数据模型中。定义一些支持系统业务逻辑的表,然后存储和检索这些表中的数据。当您需要添加新的数据源、交付新的应用程序功能或提出创新性问题时,您最好希望它可以在现有模式中完成!如果您必须打开现有数据模式的引擎盖,那么您已经开始了一个耗时且容易出错的更改管理过程。
不幸的是,这不是企业成长的方式。毕竟,今天要问的最有价值的问题是那些我们昨天都没有想到的问题。
另一方面,我们的图形数据系统允许我们灵活地随着时间发展我们的数据模型。这意味着,当我们了解更多关于数据的信息时,我们可以在模型上迭代以匹配我们的理解,而不必从头开始。(请查看本文以了解该过程的更完整的演练)。
这对我们的实践有什么帮助?这意味着我们可以将新的数据源合并为新的顶点和边,而不必破坏图上现有的工作负载。我们还可以立即将查询结果写入到图表中—消除每天运行的重复OLAP工作负载,这些工作负载只会产生相同的结果。每一个新的分析都可以建立在之前的基础之上,为我们提供了一种在业务团队之间共享生产质量结果的强大方式。所有这些都意味着我们可以用我们的数据来回答更具洞察力的问题。
2. 纲要/模式强制
虽然schema lite乍一看似乎不错,但使用这样的数据库意味着我们将大量工作卸载到应用程序层中。一阶和二阶效果是跨多个使用者应用程序复制的代码,由不同的团队用不同的语言编写。强制执行应该包含在数据库层中的逻辑是一个巨大的负担。
JanusGraph提供了灵活的模式支持,可以在不惹麻烦的情况下减轻我们的痛苦。它具有现成的可靠数据类型支持,我们可以使用它预先定义给定顶点或边可以包含的属性,而不需要每个顶点都必须包含所有这些已定义的属性。同样,我们可以定义允许哪些边类型连接一对顶点,但这对顶点不会自动强制具有该边。当我们决定为一个现有的顶点定义一个新的属性时,我们不必为已经存储在图中的每个现有顶点编写该属性,而是可以只在适用的顶点插入中包含它。
这种模式实施方法对于管理大型数据集(尤其是将用于MDM工作负载的数据集)非常有帮助。当我们的图表看到新的用例时,它简化了测试需求,并且清晰地将数据完整性维护和业务逻辑分开。
3.OLTP+OLAP支持
与任何数据系统一样,我们可以将工作负载分为两类:事务性和分析性。JanusGraph遵循Apache TinkerPop项目的图形计算方法。总的来说,我们的目标是“遍历”我们的图,通过连接边从一个顶点到另一个顶点。我们使用Gremlin图遍历语言来实现这一点。幸运的是,我们可以使用相同的Gremlin遍历语言来编写OLTP和OLAP工作负载。
事务性工作负载从少量顶点开始(在索引的帮助下找到),然后遍历相当少量的边和顶点以返回结果或添加新的图形元素。我们可以将这些事务性工作负载描述为图形本地遍历。我们对这些遍历的目标是最小化延迟。
分析工作负载需要遍历图中的大部分顶点和边才能找到答案。许多经典的分析图算法都适合这个领域。我们可以将其描述为图全局遍历。我们对这些遍历的目标是最大化吞吐量。
有了我们的JanusGraph-Scylla图形数据系统,我们可以混合这两种功能。在“Scylla ”高IO性能的支持下,我们可以为事务性工作负载实现可伸缩的单位数毫秒响应。我们还可以利用Spark来处理大规模的分析工作。
部署我们的数据系统
这在理论上是很好的,所以让我们开始实际部署这个图形数据系统。我们将在Google云平台上进行部署,但是下面描述的所有内容都应该可以在您选择的任何平台上复制。
下面是我们将要部署的图形数据系统的设计:
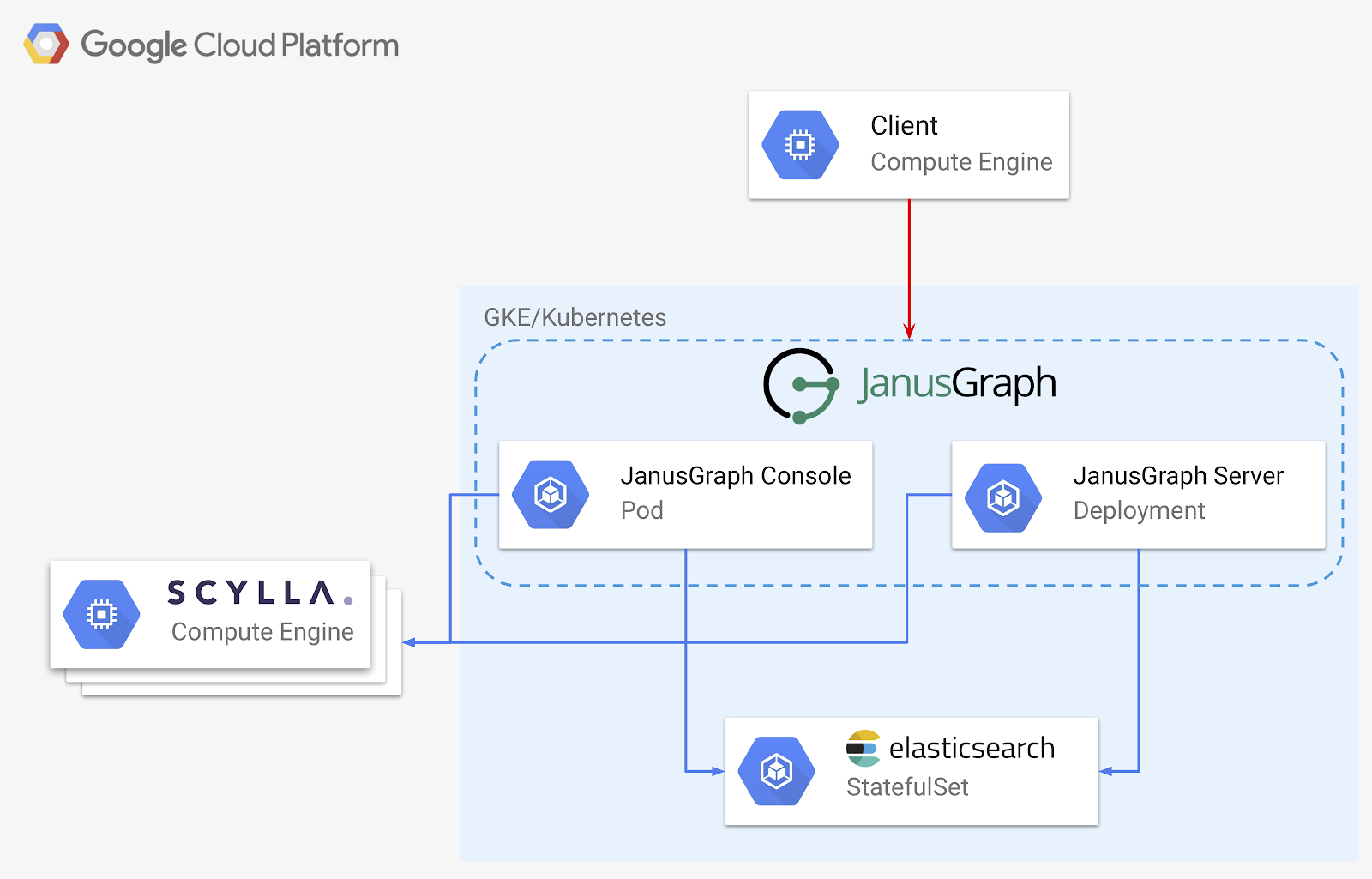
我们的架构有三个关键部分:
- Scylla ——我们的存储后端,我们数据存储的最终场所
- Elasticsearch–我们的索引后端,加速了一些搜索,并提供强大的范围和模糊匹配功能
- JanusGraph–提供我们的图形本身,作为服务器或嵌入到独立应用程序中
我们将尽可能多地使用Kubernetes进行部署。这使得扩展和部署变得容易和可重复,而不管部署具体在哪里进行。
我们是否选择使用K8s来部署“Scylla ”,这取决于我们有多冒险!“Scylla ”小组一直在努力为K8s(Kubernetes:Scylla Operator)的生产准备部署。目前作为Alpha版本提供,Scylla 操作员遵循CoreOS Kubernetes“操作员”范式。虽然我认为这最终将是JanusGraph的100%k8s部署的一个极好的选择,但现在我们将研究VMs上更传统的Scylla部署。
为了继续,您可以在 https://github.com/EnharmonicAI/scylla-janusgraph-examples。在进入生产阶段时,您会希望更改一些选项,但这个起点应该演示概念并使您快速前进。
最好在GCP虚拟机上运行此部署,并完全访问Google云api。您可以使用已有的虚拟机,也可以创建新的虚拟机。
gcloud compute instances create deployment-manager \
--zone us-west1-b \
--machine-type n1-standard-1 \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--image 'centos-7-v20190423' --image-project 'centos-cloud' \
--boot-disk-size 10 --boot-disk-type "pd-standard"然后ssh进入VM:
gcloud compute ssh deployment-manager [ryan@deployment-manager ~]$ ..
我们假设所有其他东西都是从这个GCP VM运行的。让我们安装一些prereq:
sudo yum install -y bzip2 kubectl docker git sudo systemctl start docker curl -O https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh sh Miniconda3-latest-Linux-x86_64.sh
部署Scylla
我们可以使用Scylla 自己的Google计算引擎部署脚本作为Scylla 集群部署的起点。
git clone https://github.com/scylladb/scylla-code-samples.git cd scylla-code-samples/gce_deploy_and_install_scylla_cluster
创建一个新的conda环境并安装一些必需的包,包括Ansible。
conda create --name graphdev python=3.7 -y conda activate graphdev pip install ruamel-yaml==0.15.94 ansible==2.7.10 gremlinpython==3.4.0 absl-py==0.7.1
我们还将做一些ssh密钥管理和应用项目范围的元数据,这将简化到我们的实例的连接。
touch ~/.ssh/known_hosts SSH_USERNAME=$(whoami) KEY_PATH=$HOME/.ssh/id_rsa ssh-keygen -t rsa -f $KEY_PATH -C $SSH_USERNAME chmod 400 $KEY_PATH gcloud compute project-info add-metadata --metadata ssh-keys="$SSH_USERNAME:$(cat $KEY_PATH.pub)"
我们现在可以设置集群了。在上面克隆的scylla-code-samples/gce_deploy_and_install_scylla_cluster 目录中,我们将运行gce_deploy_and_install_scylla_cluster.sh。我们将创建一个由三个Scylla 3.0节点组成的集群,每个节点都是一个n1-standard-16vm,带有两个NVMe本地ssd。
./gce_deploy_and_install_scylla_cluster.sh \
-p symphony-graph17038 \
-z us-west1-b \
-t n1-standard-4 \
-n -c2 \
-v3.0完成配置需要几分钟的时间,但完成后,我们可以继续部署JanusGraph的其余组件。
克隆 scylla-janusgraph-examples GitHub repo:
git clone https://github.com/EnharmonicAI/scylla-janusgraph-examples cd scylla-janusgraph-examples
接下来的每个命令都将从克隆的repo的顶级目录运行。
建立Kubernetes集群
为了保持部署的灵活性,而不是锁定在任何云提供商的基础设施中,我们将通过Kubernetes部署所有其他内容。Google Cloud通过他们的Google Kubernetes引擎(GKE)服务提供一个托管的Kubernetes集群。
让我们用足够的资源创建一个新的集群。
gcloud container clusters create graph-deployment \
--project [MY-PROJECT] \
--zone us-west1-b \
--machine-type n1-standard-4 \
--num-nodes 3 \
--cluster-version 1.12.7-gke.10 \
--disk-size=40我们还需要创建一个防火墙规则,允许GKE pod访问其他非GKE vm。
CLUSTER_NETWORK=$(gcloud container clusters describe graph-deployment \
--format=get"(network)" --zone us-west1-b)
CLUSTER_IPV4_CIDR=$(gcloud container clusters describe graph-deployment \
--format=get"(clusterIpv4Cidr)" --zone us-west1-b)
gcloud compute firewall-rules create "graph-deployment-to-all-vms-on-network" \
--network="$CLUSTER_NETWORK" \
--source-ranges="$CLUSTER_IPV4_CIDR" \
--allow=tcp,udp,icmp,esp,ah,sctpDeploying Elasticsearch
部署Elasticsearch
在GCP上部署Elasticsearch有很多方法——我们将选择在Kubernetes上部署ES集群作为有状态集。我们将从一个3节点集群开始,每个节点有10 GB的可用磁盘。
kubectl apply -f k8s/elasticsearch/es-storage.yaml kubectl apply -f k8s/elasticsearch/es-service.yaml kubectl apply -f k8s/elasticsearch/es-statefulset.yaml
(感谢Bayu Aldi Yansyah和他的媒体文章为部署Elasticsearch设计了这个框架)
运行Gremlin控制台
我们现在已经启动并运行了存储和索引后端,所以让我们为图形定义一个初始模式。一个简单的方法是启动一个控制台连接到我们运行的Scylla 和Elasticsearch集群。
构建JanusGraph docker映像并将其部署到Google容器注册中心。
scripts/setup/build_and_deploy_janusgraph_image.sh -p [MY-PROJECT]
更新k8s/gremlin-console/janusgraph-gremlin-console.yaml使用项目名指向GCR存储库映像名的文件,并添加Scylla 节点之一的正确主机名。您会注意到在YAML文件中,我们使用环境变量帮助创建JanusGraph属性文件,我们将使用该文件在控制台中用JanusGraphFactory实例化JanusGraph对象。
创建并连接到JanusGraph Gremlin控制台:
kubectl create -f k8s/gremlin-console/janusgraph-gremlin-console.yaml
kubectl exec -it janusgraph-gremlin-console -- bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
...
gremlin> graph = JanusGraphFactory.open('/etc/opt/janusgraph/janusgraph.properties')现在我们可以继续为我们的图创建一个初始模式。我们将在这里从更高的层次讨论这个问题,但我将在本文中详细讨论模式创建和管理过程。
在本例中,我们将查看联邦选举委员会关于2020年总统竞选捐款的数据样本。样本数据已经过分析,并对其进行了一些清理(向我的兄弟Patrick Stauffer致敬,因为他允许我利用他在这个数据集上的一些工作),并且作为资源包含在repo中/贡献.csv.
以下是我们的贡献数据集的架构定义的开始:
mgmt = graph.openManagement()
// Define Vertex labels
Candidate = mgmt.makeVertexLabel("Candidate").make()
ename = mgmt.makePropertyKey("name").
dataType(String.class).cardinality(Cardinality.SINGLE).make()
filerCommitteeIdNumber = mgmt.makePropertyKey("filerCommitteeIdNumber").
dataType(String.class).cardinality(Cardinality.SINGLE).make()
mgmt.addProperties(Candidate, type, name, filerCommitteeIdNumber)
mgmt.commit()您可以在scripts/load/define中找到完整的模式定义代码_schema.groovy模式存储库中的文件。只需将其复制并粘贴到Gremlin控制台中即可执行。
加载模式后,我们可以关闭Gremlin控制台并删除pod。
kubectl delete -f k8s/gremlin-console/janusgraph-gremlin-console.yaml
部署JanusGraph服务器
最后,让我们将JanusGraph部署为服务器,准备接受客户机请求。我们将利用JanusGraph对Apache TinkerPop的Gremlin服务器的内置支持,这意味着我们的图形将可以被多种客户端语言(包括Python)访问。
编辑k8s/janusgraph/janusgraph-server-service.yaml指向正确的GCR存储库映像名的文件。部署JanusGraph服务器现在非常简单:
kubectl apply -f k8s/janusgraph/janusgraph-server-service.yaml kubectl apply -f k8s/janusgraph/janusgraph-server.yaml
加载数据
我们将通过在图中加载一些初始数据来演示对JanusGraph服务器部署的访问。
无论何时我们将数据加载到任何类型的数据库(Scylla 、关系、图表等),我们都需要定义源数据将如何映射到数据库中定义的模式。对于graph,我喜欢使用一个简单的映射文件。回购协议中包含了一个示例,下面是一个小示例:
vertices:
- vertex_label: Candidate
lookup_properties:
FilerCommitteeIdNumber: filerCommitteeIdNumber
other_properties:
CandidateName: name
edges:
- edge_label: CONTRIBUTION_TO
out_vertex:
vertex_label: Contribution
lookup_properties:
TransactionId: transactionId
in_vertex:
vertex_label: Candidate
lookup_properties:
FilerCommitteeIdNumber: filerCommitteeIdNumber此映射是为演示目的而设计的,因此您可能会注意到此映射定义中存在重复数据。这个简单的映射结构允许客户端保持相对“哑”的状态,而不是强制它预处理映射文件。
我们的示例repo包含一个简单的Python脚本load_fron_csv.py年,它接受一个CSV文件和一个映射文件作为输入,然后将每一行加载到图形中。它一般采用您想要的任何映射文件和CSV,但它是单线程的,不是为速度而构建的,它旨在演示从客户端加载数据的概念。
python scripts/load/load_from_csv.py \
--data ~/scylla-janusgraph-examples/resources/Contributions.csv \
--mapping ~/scylla-janusgraph-examples/resources/campaign_mapping.yaml \
--hostname [MY-JANUSGRAPH-SERVER-LOAD-BALANCER-IP] \
--row_limit 1000这样,我们就可以启动并运行数据系统,包括定义数据模式和加载一些初始记录。
结束
我希望你喜欢这个进入JanusGraph-Scylla 图形数据系统的短暂尝试。它应该为您提供一个良好的起点,并演示如何轻松地部署所有组件。记住关闭任何不想保留的云资源,以避免产生费用。
我们真的只是触及了这个强大的系统所能完成的事情的表面,而你的胃口也被激起了。请给我任何想法和问题,我期待着看到你的建设!
原文:https://www.scylladb.com/2019/05/14/powering-a-graph-data-system-with-scylla-janusgraph/
本文:http://jiagoushi.pro/node/1045
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
最新内容
- 1 day 3 hours ago
- 1 week 2 days ago
- 1 week 6 days ago
- 2 months ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago