
category
引言
大型语言模型(LLMs)在生成上下文相关响应方面表现出了很强的性能。然而,它们受到固定上下文窗口的限制,这限制了它们在扩展交互中保持一致性的能力。当对话超出模型的上下文窗口时,这个问题就会变得明显,导致重要细节的丢失并影响整体一致性。
为了应对这一挑战,Chhikara等人(2025)引入了Mem0,这是一种可扩展的内存架构,旨在从正在进行的对话中动态提取、整合和检索关键信息。通过整合持久内存,Mem0使LLM能够在固定输入限制之外保留相关上下文,从而提高较长对话的连贯性。
本文研究了Mem0及其基于图的变体Mem0g的技术细节,Mem0g通过将实体之间的关系建模为有向图来增强内存表示。此外,还探讨了现有存储系统的性能、效率和实际意义,强调了它们与现实世界应用的相关性。
有限上下文窗口的挑战
LLM使用固定的上下文窗口,这意味着它们一次只能记住有限数量的信息。这限制了他们在长时间对话中保持连贯性的能力。与人类不同,人类自然会记住过去的经历并将其组织成一个连续的故事,一旦信息超出其上下文窗口,LLM就会“重置”。
例如,假设用户在一次对话中告诉系统,他们是素食主义者,不吃奶制品。在稍后的对话中,当用户要求晚餐推荐时,没有记忆的系统可能会建议吃鸡肉,而忽略用户的饮食偏好。这种内存故障会使系统看起来不可靠,并损害用户对它的信任。
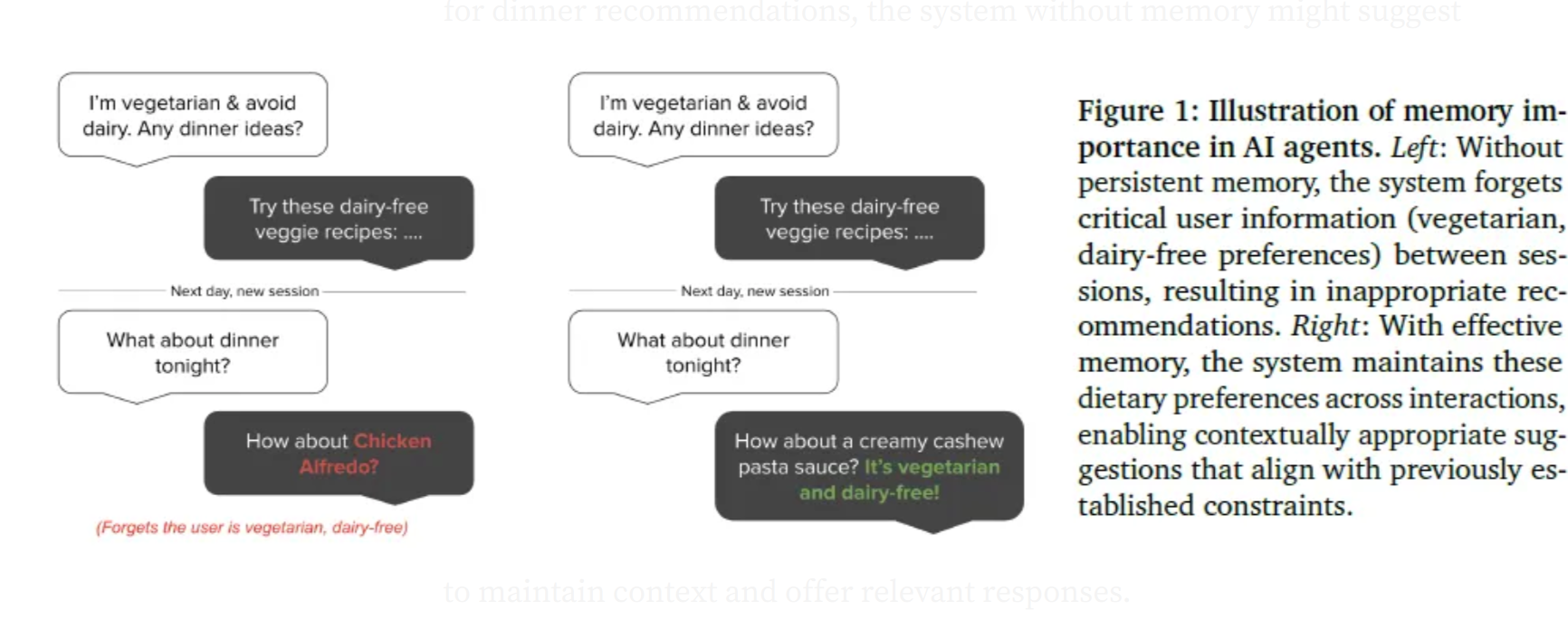
随着对话时间的延长,这个问题变得更加明显。即使使用OpenAI的GPT-4(最多可处理128K个令牌)、Claude 3.7 Sonnet(拥有20万个令牌)或谷歌的Gemini(据说可处理1000万个令牌的)等高级模型,现实世界的对话仍可能超过这些限制。除此之外,谈话往往会改变话题。用户可能会谈论饮食偏好,然后转移到编程任务上几个小时,然后再回到与食物相关的问题上。这些转变使系统更难保持上下文并提供相关响应。
Mem0架构:增量内存处理
Mem0系统采用增量处理方法运行,包括两个不同的阶段:提取和更新。这种设计使正在进行的对话能够顺利整合,有助于随着时间的推移保持内存存储的一致性。
在提取阶段,系统处理新的消息对,通常由用户消息和助手的响应以及其他上下文信息组成。为了建立适当的上下文,Mem0使用了两个互补的来源:一个捕获整个对话历史语义内容的对话摘要,以及一系列来自正在进行的对话的最新消息。这些最近的消息代表了为当前互动提供背景的相关交流。异步摘要生成模块定期刷新对话摘要,确保最新的上下文信息始终可用,而不会在处理过程中引入延迟。
组合的上下文信息(摘要、最近的消息和新的消息对)用于形成提取功能的综合提示,该功能使用LLM实现。此功能从新的交流中提取相关记忆,同时保持对更广泛对话背景的认识。结果是一组候选事实,然后对其进行评估以纳入知识库。
在更新阶段,系统根据现有内存评估每个候选事实,以确保一致性并避免冗余。对于每个事实,系统使用向量嵌入检索语义相似的记忆,然后将检索到的记忆与候选事实一起呈现给LLM。LLM决定执行哪种操作:添加以创建新的内存,更新以增强现有的内存,删除以删除矛盾的信息,或者在不需要修改的情况下执行NOOP。
Mem0还可以处理用户在话题之间切换或在间隔后回到之前的对话的情况。该系统的记忆机制确保当用户回到前一个话题时,相关的上下文会从记忆中检索出来,即使在对话转移焦点后,系统也能保持反应的连贯性和连续性。这种记忆检索过程与检索增强生成(RAG)方法有一些相似之处,但旨在通过关注最相关的事实而不是大的文本块来提高效率。
Mem0g架构:基于图的内存增强
在Mem0的基础上,Mem0g引入了一种基于图的记忆方法,改进了上下文信息的捕获、存储和检索方式。在这种更新的架构中,内存被表示为有向标记图G=(V,E,L),其中节点(V)表示实体(如人、位置或对象),边(E)表示这些实体之间的关系,标签(L)为节点分配语义类型。
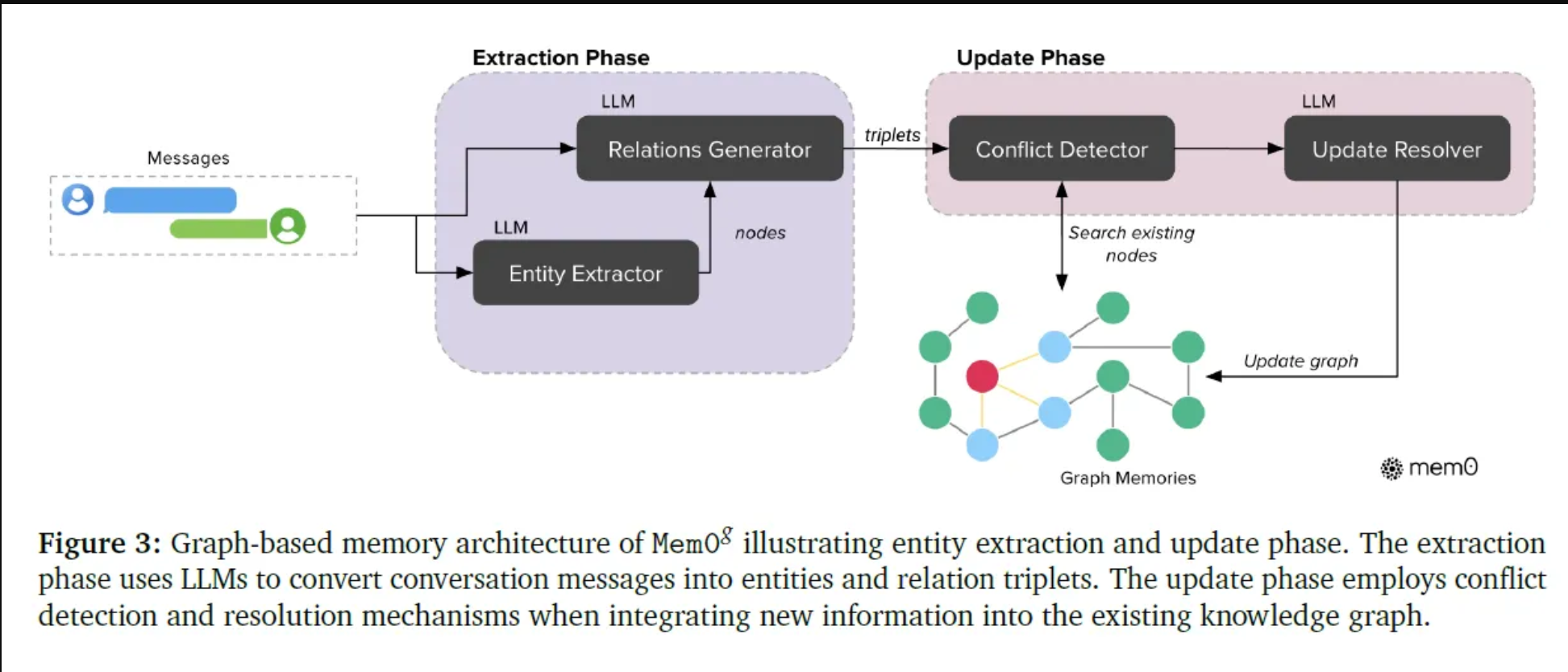
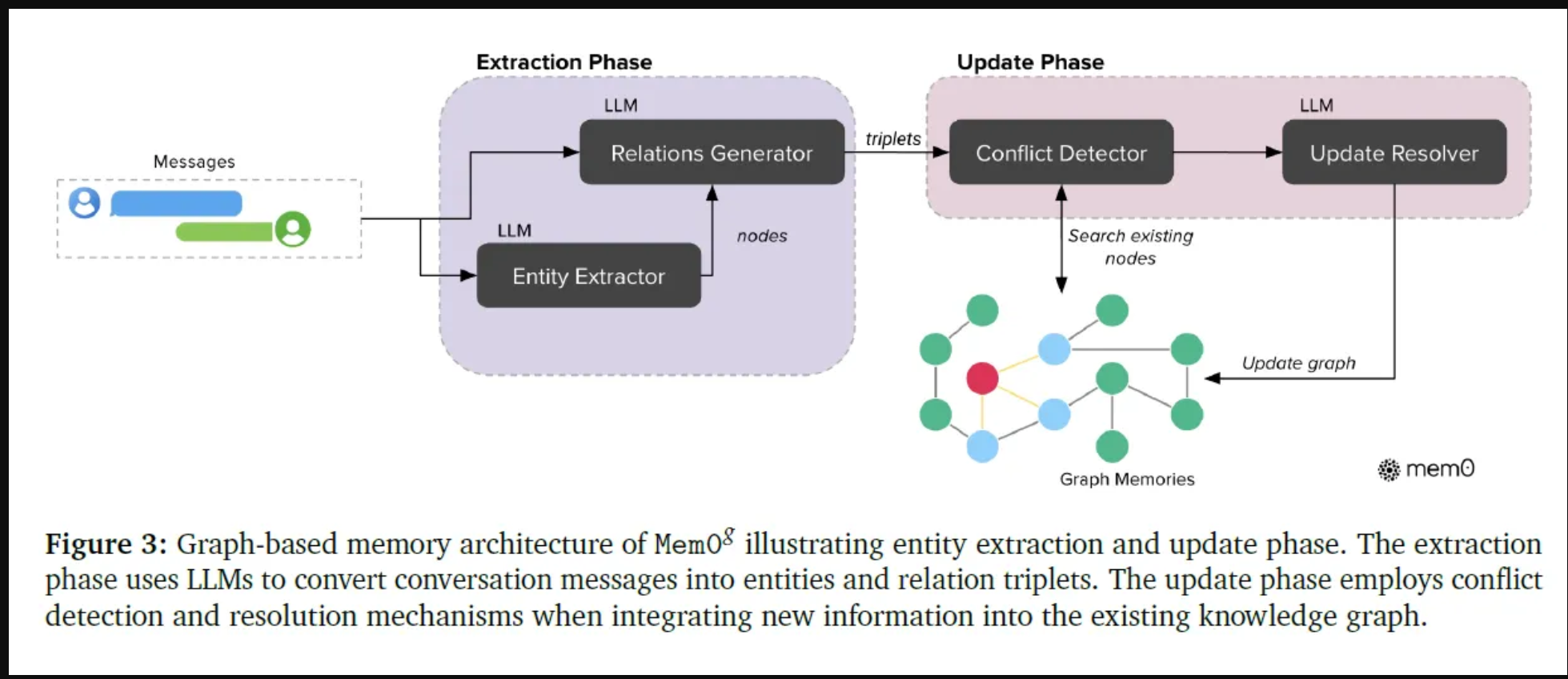
Mem0g中的提取过程是一个利用LLM的两级管道。首先,实体提取器识别关键信息元素,如人、位置、概念和事件,这些实体在内存图中表示为节点。接下来,关系生成器分析上下文并在实体之间建立有意义的连接,形成捕获信息语义结构的关系三元组。
为了管理这种基于图形的内存,Mem0g采用了存储和更新策略。每个新关系都使用嵌入进行编码,然后将其与图中的现有实体进行比较。如果新关系涉及尚未表示的实体,系统将为这些实体创建新节点。如果实体已经存在,系统会将新关系链接到现有节点,确保图形反映最新的连接。
为了保持图中的一致性并处理潜在的冲突,Mem0g包含了一个冲突检测机制。当整合新信息时,系统会检查与现有关系的冲突。如果检测到冲突,基于LLM的更新解析器将确定是否应将关系标记为过时。这使得Mem0g能够支持时态推理,在不删除过时关系的情况下对其进行修改,从而保留了一个动态和不断发展的知识库。
对于记忆检索,Mem0g使用两种策略。第一种是以实体为中心的方法,它侧重于查询中的关键实体,在图中标识它们的对应节点,并探索与这些节点连接的关系。第二种方法是语义三元组方法,它将整个查询编码为密集嵌入,并将其与图中的关系三元组进行匹配。然后,系统计算查询和三元组之间的相似性得分,根据预定义的相关性阈值检索最相关的信息。
Mem0g的记忆检索过程也与RAG方法有相似之处,在RAG方法中,信息是根据与当前查询的相关性检索的。然而,与检索较大文本块的传统RAG方法相比,Mem0g对基于图的关系及其内存的结构化、关系性的关注使得检索更加复杂和高效。这些检索方法使Mem0g能够有效地处理特定于实体的查询和更广泛的概念查询。
在实现方面,Mem0g使用Neo4j作为底层图数据库,而GPT-4o-mini用于提取信息和更新内存图。这种基于图的表示、语义嵌入和LLM驱动的信息提取的结合创建了一个系统,该系统在结构上丰富,适用于复杂的推理,在自然语言理解方面也足够灵活。
评估结果和效率
评估使用了LOCOMO数据集,该数据集由10个扩展对话组成,每个对话包含多个会话中的约600个对话和26000个令牌,每个对话平均有200个问题。该评估将Mem0和Mem0g与几个基线系统进行了比较,包括内存增强方法(LoCoMo、ReadAgent、MemoryBank、MemGPT、A-Mem)、全上下文方法RAG、开源内存解决方案(LangMem)、专有系统(OpenAI)和专用内存管理平台Zep。
在性能方面,Mem0在单跳问题上的表现优于其他系统。Mem0g的性能略有下降,表明基于图的内存结构对更简单的单圈查询的好处有限。对于多跳问题,Mem0也领先,但Mem0g没有显示出显著的改善,这表明在需要跨多个会话集成信息的任务中使用图形内存效率低下。在开放域问题中,Zep基线得分最高,但相比之下Mem0g表现良好。在时间推理任务中,Mem0g表现出色,证实了关系结构对于需要对事件序列进行建模的任务是有用的。
在计算效率方面,全上下文方法具有最高的准确性,但速度较慢,大约需要17秒才能响应。Mem0减少了令牌的使用,响应速度更快,延迟仅为1.44秒,提高了92%。Mem0g的延迟略高,为2.6秒,但仍然显示出85%的改善,同时在内存增强系统中实现了最佳的准确性。
随着对话时间的延长,Mem0和Mem0g保持了一致的性能,而全上下文方法则面临着计算开销增加的问题。Mem0每次对话只使用7k个令牌,而具有图形内存的Mem0g需要14k个令牌。相比之下,Zep消耗了超过60万个令牌,主要是因为在每个节点上缓存了完整的抽象摘要。
结论
Mem0和Mem0g通过随着时间的推移实现更连贯、上下文感知的交互,解决了LLM中固定上下文窗口的局限性。与全上下文方法相比,它们在各种问题类型上的表现和计算开销的显著减少突显了它们的效率。Mem0在简单的检索任务中表现出色,而Mem0g更适合时间和关系推理,这展示了适应性记忆结构在不同人工智能应用中的价值。
参考:
Chhikara,P.、Khant,D.、Aryan,S.、Singh,T.和Yadav,D.(2025)。Mem0:构建具有可扩展长期内存的生产就绪AI代理。arXiv电子版,arXiv:2504.19413v1。https://doi.org/10.48550/arXiv.2504.19413
- 登录 发表评论
- 123 次浏览
最新内容
- 1 month 1 week ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago
- 5 months ago