
选择在何处托管数据库,将数据具体化,并将数据库用作作业队列。
这不是我第一次使用大型数据集进行竞技。我为英国最大的公共Wi-Fi提供商设计的认证和产品管理数据库的容量也令人印象深刻。我们每天都在跟踪数百万台设备的身份验证。但是,该项目的资金允许我们选择任何硬件、任何支持服务,并雇佣任何DBA来协助复制/数据仓库/故障排除。此外,所有的分析查询/报告都是在逻辑副本上完成的,并且有多个系统管理员负责管理支持基础设施。而这是我自己的冒险,资金有限,数量是20倍。
别人的错误
这并不是说,如果我们有 loadsamoney,我们就会把它花在购买顶级硬件、花哨的监控系统或DBA上(好吧,或许有一个专门的DBA就更好了)。经过多年的咨询工作,我形成了一种观点,认为所有罪恶的根源在于不必要的复杂数据处理管道。不需要消息队列来做ETL,数据库查询也不需要应用程序层缓存。通常情况下,这些都是针对底层数据库问题(例如,延迟、索引策略差)的解决方案,这些问题会导致更多的问题。在理想的场景中,您希望将所有数据包含在单个数据库中,并将所有数据加载操作抽象为原子事务。我的目标是不要重复这些错误。
我们的目标
正如你已经猜到的,我们的PostgreSQL数据库成为了业务的核心部分(恰当地称为“母亲”,尽管我的联合创始人坚持认为我把各种基础设施组件称为“母亲”、“母舰”、“祖国”等令人担忧)。我们没有独立的消息队列服务、缓存服务或用于数据仓库的副本。我没有维护支持基础设施,而是致力于通过最小化延迟、提供最合适的硬件和仔细规划数据库模式来消除任何瓶颈。我们拥有的是一个易于扩展的基础设施,只有一个数据库和许多数据处理代理。我喜欢它的简洁性——如果有什么东西坏了,我们可以在几分钟内确定并解决问题。然而,在这个过程中出现了许多错误——本文总结了其中的一些。
数据集
在深入讨论之前,让我们快速总结一下数据集。
我是Applaudience公司的联合创始人。我们汇总影院数据。我们的主要数据集包括电影放映时间、票价和门票。我们将这些数据与各种支持数据相结合,包括我们从YouTube、Twitter和天气报告中获得的数据。最终结果是一个全面的时间序列数据集,描述了整个影院电影的发布窗口。其目的是预测未来电影的表现。
我们目前追踪了欧洲和美国22个地区的3200多家影院。这大约是47,000次/天。每当有人从这两个电影院预订或购买一张票时,我们都会捕捉到描述观众席中每个座位属性的快照。
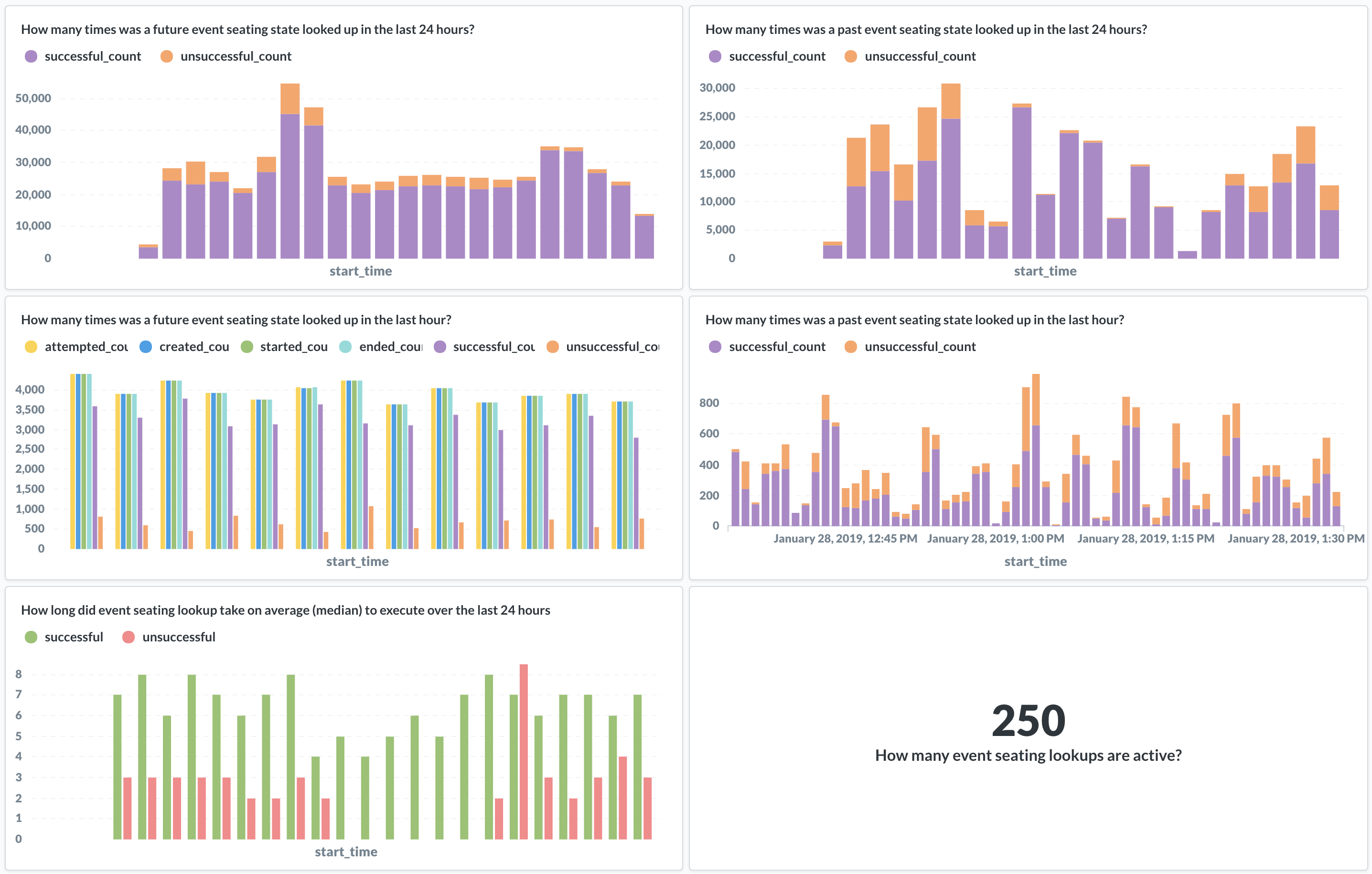
我们如何监控数据聚合和检测异常则完全是另一个主题。然而,使用PostgreSQL作为所有正在被聚合的数据的真实来源,以及所有聚合数据的过程,使得它变得更加容易。
这总计是每月12亿次的记录,而这还只是入场数据。
选择在何处Host数据库
我们找了几个供应商:
- 1. 谷歌
- 2. 亚马逊
- 3.Aiven.io
- 4. 自托管
Google Cloud SQL for PostgreSQL
我们从谷歌获得了10万美元的启动积分。这是他们选择服务的主要决定因素。我们在PostgreSQL中使用了大约6个月的云SQL。我们从谷歌SQL迁移到PostgreSQL的主要原因是我们发现了一个导致数据损坏的bug。这是一个已知的bug,在更新的PostgreSQL版本中得到了修复。但是,用于PostgreSQL的谷歌SQL落后几个版本。支持者没有回应承认这一问题,这是一个足以让我们继续前进的危险信号。我很高兴我们继续前进,因为我们提出这个问题已经8个月了,而且PostgreSQL的版本还没有更新:
postgres=> SELECT version(); PostgreSQL 9.6.6 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit(1 row)
Amazon RDS for PostgreSQL
然后我们从Amazon获得了信用,并迁移到Amazon RDS for PostgreSQL——他们的PostgreSQL版本一直在更新,而我对RDS社区的研究也没有引起任何关注。然而,Amazon RDS for PostgreSQL不支持TimescaleDB扩展,这是我们计划用于数据库分区的扩展。随着Amazon宣布Timestream(他们自己的时间序列数据库),这一需求在可预见的未来将不会得到解决(这个问题已经开放了2年)。
Aiven.io
然后我们搬到了Aiven.io。Aiven.io为您管理PostgreSQL数据库在您的云服务提供商的选择。它有我需要的所有扩展(包括TimescaleDB),它没有把我们锁定在一个特定的服务器提供商(这意味着我们可以在任何一个Aiven上托管我们的Kubernetes集群。Aiven.io支持提供商),他们的支持从第一次互动中就起到了帮助作用,我的尽职调查得到的只是赞扬。然而,我忽略了一点,你不能获得超级用户访问。这导致了很多问题(例如,我们一直在使用的各种维护程序停止工作,我们的监控软件由于权限问题无法使用;无法使用auto_explain;逻辑复制需要自定义扩展)和本可以避免的长时间中断。
更新2019-02-05:
Aiven.io现在已经推出了auto_explain支持以及固定的1.2版本,作为可用的维护更新。
总的来说,我不明白Aiven的附加值是什么。Aiven.io提供-我们甚至没有警告,当数据库的存储快用完。
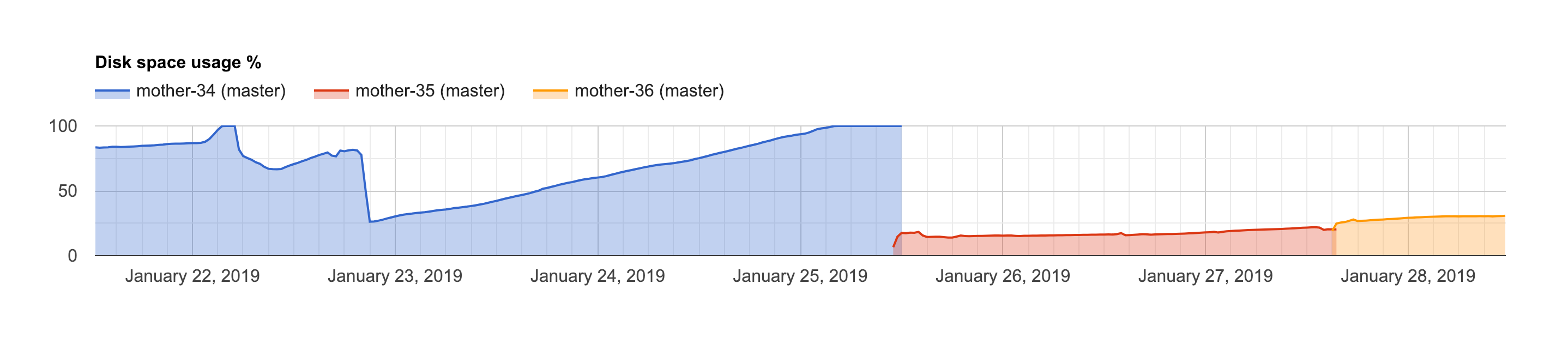
由于无人参与的复制槽导致WAL不断增长,耗尽磁盘空间。
当发生这种情况时,提供了将实例升级为具有更大容量的实例的支持。虽然这是一个很好的解决方案,但它导致了比必要的更长的停机时间。有SSH访问权限的人可以在几分钟内诊断并解决这个问题。
当我们开始经历由于Aiven使用的TimescaleDB扩展的错误(后来证明是)而导致的连续中断时。Aiven.io支持没有为这个问题提供任何解决方案。
我们正在研究这个问题,并与TimescaleDB团队合作,但对大多数事情的反应不是立即的。我们的帮助文章在https://help.aiven.io/support/aiven-support-details描述了我们提供的响应时间。
这是一个可怕的被动响应,当你的客户的服务器处于崩溃循环(两天后:没有从Aiven.io跟进)。
尽管我把狗屎都给了艾文。在一些问题上,总的来说他们的支持是伟大的。容忍文档中已经提到的问题,并帮助解决问题。我们放弃的主要原因是缺少SSH/超级用户。
自托管
一直以来,我都在试图避免不可避免的事情——自己管理数据库。现在我们租用自己的硬件来维护数据库。我们有比任何云服务提供商提供的更好的硬件,及时恢复(多亏了巴曼),没有供应商锁定,而且(纸面上)它比使用谷歌云或AWS的托管便宜30%左右。我们可以用这30%来雇佣一位自由职业者DBA,每天检查一次服务器。
Takeaway(要点)
这里的结论是,谷歌和亚马逊优先考虑他们的专有解决方案(谷歌BigQuery, AWS Redshift)。因此,您必须计划将来需要什么特性。为一个简单的数据库,不会成长为数十亿的记录,不需要自定义扩展,我将选择不加考虑(近即时扩展能力实例,服务器迁移到不同的地区,时间点恢复,内置监控工具和管理复制节省了很多时间。)。
如果您的业务都是关于数据的,并且您知道您将需要定制的硬件配置和诸如此类的东西,那么您最好的选择是自己托管和管理数据库。也就是说,逻辑迁移是非常简单的——如果你可以从任何一个托管提供者开始并利用他们的启动资金,那么这是启动一个项目的好方法,如果有必要的话,你可以在以后迁移。
如果我重新开始,花时间估计我们将增长多快和多大,我将使用裸机设置并从第一天开始雇佣一个自由DBA。
奖金:性能
我选择托管服务的主要标准是减少管理开销。我认为成本和硬件将是差不多的。Aiven.io写了一篇文章,比较了PostgreSQL在AWS、GCP、Azure、DO和UpCloud中的性能(GCP在所有测试中都比AWS好2倍)。
物化数据
我有没有提到这是我第一次使用PostgreSQL?
在这次冒险中,我主要使用的是MySQL。我决定在这个启动项目中使用PostgreSQL的原因是,PostgreSQL支持物化视图和编程语言。我认为物化视图本身就是学习PostgreSQL的一个很好的特性。相反,我认为我永远不会在数据库中运行脚本(MySQL告诉你,数据库只用于存储数据,所有逻辑必须在应用程序代码中实现)。
两年后,我们摆脱了大多数物化视图,使用了数百个定制过程。但在那之前,有多次使用物化视图的拙劣尝试。
第一次尝试使用PostgreSQL物化视图
我对物化视图的第一个用例可以总结为“拥有一个用元数据丰富的基表”,例如。
CREATE MATERIALIZED VIEW venue_view AS
WITH
auditorium_with_future_events AS (
SELECT
e1.venue_id,
e1.auditorium_id
FROM event e1
WHERE
-- The 30 days interval ensures that we do not remove auditoriums
-- that are temporarily unavailable.
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL
GROUP BY
e1.venue_id,
e1.auditorium_id
),
auditorium_with_future_events_count AS (
SELECT
awfe1.venue_id,
count(*) auditorium_count
FROM auditorium_with_future_events awfe1
GROUP BY
awfe1.venue_id
),
venue_auditorium_seat_count AS (
SELECT DISTINCT ON (e1.venue_id, e1.auditorium_id)
e1.venue_id,
e1.auditorium_id,
e1.seat_count
FROM auditorium_with_future_events awfe1
INNER JOIN event e1 ON e1.venue_id = awfe1.venue_id AND e1.auditorium_id = awfe1.auditorium_id
WHERE
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL AND
e1.seat_count IS NOT NULL
ORDER BY
e1.venue_id,
e1.auditorium_id
),
venue_seat_count AS (
SELECT
vasc1.venue_id,
sum(vasc1.seat_count) seat_count
FROM venue_auditorium_seat_count vasc1
GROUP BY vasc1.venue_id
)
SELECT DISTINCT ON (v1.id)
v1.id,
v1.google_place_id,
v1.fuid,
v1.cinema_id,
v1.street_1,
v1.street_2,
v1.postcode,
v1.coordinates,
gp1.country_id,
gp1.timezone_id,
COALESCE(v1.phone_number, c1.phone_number) AS phone_number,
v1.display_name AS name,
COALESCE(v1.alternative_url, v1.url) AS url,
v1.permanently_closed_at,
awfec1.auditorium_count,
nearest_venue.id nearest_venue_id,
CASE
WHEN nearest_venue.id IS NULL
THEN NULL
ELSE round(ST_DistanceSphere(gp1.location, nearest_venue.location))
END nearest_venue_distance,
vsc1.seat_count seat_count
FROM venue v1
LEFT JOIN venue_seat_count vsc1 ON vsc1.venue_id = v1.id
LEFT JOIN google_place gp1 ON gp1.id = v1.google_place_id
LEFT JOIN LATERAL (
SELECT
v2.id,
gp2.location
FROM venue v2
INNER JOIN google_place gp2 ON gp2.id = v2.google_place_id
WHERE v2.id != v1.id
ORDER BY gp1.location <-> gp2.location
LIMIT 1
) nearest_venue ON TRUE
LEFT JOIN auditorium_with_future_events_count awfec1 ON awfec1.venue_id = v1.id
INNER JOIN cinema c1 ON c1.id = v1.cinema_id
WITH NO DATA;CREATE UNIQUE INDEX ON venue_view (id);CREATE INDEX ON venue_view (google_place_id);
CREATE INDEX ON venue_view (cinema_id);
CREATE INDEX ON venue_view (country_id);
CREATE INDEX ON venue_view (nearest_venue_id);这里,地点是我们用附加数据扩展的基本表,并称之为venue_view。只有两条规则需要遵守:
- _view必须包含基表的所有列。
- _view必须包含基表的所有行。
以上查询没有问题。这种方法在很长一段时间内都有效。然而,随着记录的数量增加到数百万或数十亿,刷新物化视图所需的时间从几秒钟增加到几个小时。(如果你不熟悉物化视图,那么值得注意的是,你只能刷新整个物化视图;无法根据条件刷新视图的子集。)
第二次尝试:分治
我试图通过将mv分解为多个更小的mv来解决这个问题。
(注意,我们已经将查询从CTEs移动到专用的MVs。)
CREATE MATERIALIZED VIEW auditorium_with_future_events_view
SELECT
e1.venue_id,
e1.auditorium_id
FROM event e1
WHERE
-- The 30 days interval ensures that we do not remove auditoriums
-- that are temporarily unavailable.
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL
GROUP BY
e1.venue_id,
e1.auditorium_id
WITH NO DATA;CREATE UNIQUE INDEX ON auditorium_with_future_events_view (venue_id, auditorium_id);CREATE MATERIALIZED VIEW venue_auditorium_seat_count_view
SELECT DISTINCT ON (e1.venue_id, e1.auditorium_id)
e1.venue_id,
e1.auditorium_id,
e1.seat_count
FROM auditorium_with_future_events_view awfe1
INNER JOIN event e1 ON e1.venue_id = awfe1.venue_id AND e1.auditorium_id = awfe1.auditorium_id
WHERE
e1.start_time > now() - INTERVAL '30 day' AND
e1.auditorium_id IS NOT NULL AND
e1.seat_count IS NOT NULL
ORDER BY
e1.venue_id,
e1.auditorium_id
WITH NO DATA;CREATE UNIQUE INDEX ON venue_auditorium_seat_count_view (venue_id, auditorium_id);CREATE MATERIALIZED VIEW venue_view AS
WITH
auditorium_with_future_events_count AS (
SELECT
awfe1.venue_id,
count(*) auditorium_count
FROM auditorium_with_future_events_view awfe1
GROUP BY
awfe1.venue_id
),
venue_seat_count AS (
SELECT
vasc1.venue_id,
sum(vasc1.seat_count) seat_count
FROM venue_auditorium_seat_count_view vasc1
GROUP BY vasc1.venue_id
)
SELECT DISTINCT ON (v1.id)
v1.id,
v1.google_place_id,
v1.fuid,
v1.cinema_id,
v1.street_1,
v1.street_2,
v1.postcode,
v1.coordinates,
gp1.country_id,
gp1.timezone_id,
COALESCE(v1.phone_number, c1.phone_number) AS phone_number,
v1.display_name AS name,
COALESCE(v1.alternative_url, v1.url) AS url,
v1.permanently_closed_at,
awfec1.auditorium_count,
nearest_venue.id nearest_venue_id,
CASE
WHEN nearest_venue.id IS NULL
THEN NULL
ELSE round(ST_DistanceSphere(gp1.location, nearest_venue.location))
END nearest_venue_distance,
vsc1.seat_count seat_count
FROM venue v1
LEFT JOIN venue_seat_count vsc1 ON vsc1.venue_id = v1.id
LEFT JOIN google_place gp1 ON gp1.id = v1.google_place_id
LEFT JOIN LATERAL (
SELECT
v2.id,
gp2.location
FROM venue v2
INNER JOIN google_place gp2 ON gp2.id = v2.google_place_id
WHERE v2.id != v1.id
ORDER BY gp1.location <-> gp2.location
LIMIT 1
) nearest_venue ON TRUE
LEFT JOIN auditorium_with_future_events_count awfec1 ON awfec1.venue_id = v1.id
INNER JOIN cinema c1 ON c1.id = v1.cinema_id
WITH NO DATA;CREATE UNIQUE INDEX ON venue_view (id);CREATE INDEX ON venue_view (google_place_id);
CREATE INDEX ON venue_view (cinema_id);
CREATE INDEX ON venue_view (country_id);
CREATE INDEX ON venue_view (nearest_venue_id);这种方法的好处是:
- 1. 我们把一笔长交易分解成许多短交易。
- 2. 我们可以使用索引来加速连接。
- 3.我们能够刷新单个的物化视图(有些数据比其他数据更经常地更改)。
这种方法的缺点是它增加了物化视图的数量,我们使用这些视图并需要开发定制的解决方案来协调物化视图的刷新。当时,这似乎很合理,我就这么做了。因此materialized_view_refresh_schedule表born和我们的第一个数据库内队列:
CREATE TABLE materialized_view_refresh_schedule (
id SERIAL PRIMARY KEY,
materialized_view_name citext NOT NULL,
refresh_interval interval NOT NULL,
last_attempted_at timestamp with time zone,
maximum_execution_duration interval NOT NULL DEFAULT '00:30:00'::interval
);
CREATE UNIQUE INDEX materialized_view_refresh_schedule_materialized_view_name_idx ON materialized_view_refresh_schedule(materialized_view_name citext_ops);CREATE TABLE materialized_view_refresh_schedule_execution (
id integer DEFAULT nextval('materialized_view_refresh_id_seq'::regclass) PRIMARY KEY,
materialized_view_refresh_schedule_id integer NOT NULL REFERENCES materialized_view_refresh_schedule(id) ON DELETE CASCADE,
started_at timestamp with time zone NOT NULL,
ended_at timestamp with time zone,
execution_is_successful boolean,
error_name text,
error_message text,
terminated_at timestamp with time zone,
CONSTRAINT materialized_view_refresh_schedule_execution_check CHECK (terminated_at IS NULL OR ended_at IS NOT NULL)
);
CREATE INDEX materialized_view_refresh_schedule_execution_materialized_view_ ON materialized_view_refresh_schedule_execution(materialized_view_refresh_schedule_id int4_ops);物化视图的名称存储在materialized_view_refresh_schedule表中,并带有关于需要多久刷新一次视图的说明。一个单独的程序被编写来执行这些指令的具体化。
CREATE OR REPLACE FUNCTION schedule_new_materialized_view_refresh_schedule_execution()
RETURNS table(materialized_view_refresh_schedule_id int)
AS $$
BEGIN
RETURN QUERY
UPDATE materialized_view_refresh_schedule
SET last_attempted_at = now()
WHERE id IN (
SELECT mvrs1.id
FROM materialized_view_refresh_schedule mvrs1
LEFT JOIN LATERAL (
SELECT 1
FROM materialized_view_refresh_schedule_execution mvrse1
WHERE
mvrse1.ended_at IS NULL AND
mvrse1.materialized_view_refresh_schedule_id = mvrs1.id
) AS unendeded_materialized_view_refresh_schedule_execution ON TRUE
WHERE
unendeded_materialized_view_refresh_schedule_execution IS NULL AND
(
mvrs1.last_attempted_at IS NULL OR
mvrs1.last_attempted_at + mvrs1.refresh_interval < now()
)
ORDER BY mvrs1.last_attempted_at ASC NULLS FIRST
LIMIT 1
FOR UPDATE OF mvrs1 SKIP LOCKED
)
RETURNING id;
END
$$
LANGUAGE plpgsql;
这个程序将调用schedule_new_materialized_view_refresh_schedule_execution来调度一个物化视图刷新,并发地评估刷新物化视图,并记录结果。一般来说,这种方法很有效。然而,我们很快就超越了这种方法。需要扫描整个表的视图对于具有数十亿条记录的大型表是不可行的。
第三次尝试:使用MVs抽象数据子集
我已经描述了如何使用MVs有效地扩展表。这种方法不适用于大型表。这样就产生了第三次迭代:不是使用物化视图来扩展基表,而是创建抽象数据域的物化视图。由于它的大小,venue_view可以保持它原来的样子,但是一个假设的视图,比如event_view,有数十亿条记录,将变成last_week_event, future_event等等。这种方法有效,我们继续使用几个这样的物化视图。
第四次尝试:物化表列
虽然后一种方法涵盖了我们所有的日常操作,但我们仍然需要对历史数据运行查询。在没有物化视图的情况下运行这些查询将需要为各个查询进行大量的索引规划。此外,在主实例上运行长时间事务将防止autovacuum并导致表膨胀。我本可以创建一个逻辑复制,并允许分析人员在该实例上运行任何查询,而不阻止autovacuum。然而,更大的问题是,作为一个初创公司,我们负担不起需要运行数小时或数天的查询。我们需要比任何人都快。这样就产生了当前的解决方案:物化表列。
原则很简单:
描述我们想要用附加信息充实的实体的表被修改为包含一个materialized_at timestamptz列和一个用于我们想要具体化的每个数据点的列。在venue_view的例子中,我们将完全删除物化视图,并将物化视图中的materialized_at、country_id、timezone_id、phone_number和其他列添加到场馆表中。
然后有一个脚本,观察所有已经materialized_at列的表,每次它检测到materialized_at为NULL的行,它计算物化列的新值并更新行,例如。
CREATE OR REPLACE FUNCTION materialize_event_seat_state_change()
RETURNS void
AS $$
BEGIN
WITH
event_seat_state_count AS (
SELECT
essc1.id,
count(*)::smallint seat_count,
count(*) FILTER (WHERE ss1.nid = 'BLOCKED')::smallint seat_blocked_count,
count(*) FILTER (WHERE ss1.nid = 'BROKEN')::smallint seat_broken_count,
count(*) FILTER (WHERE ss1.nid = 'EMPTY')::smallint seat_empty_count,
count(*) FILTER (WHERE ss1.nid = 'HOUSE')::smallint seat_house_count,
count(*) FILTER (WHERE ss1.nid = 'SOLD')::smallint seat_sold_count,
count(*) FILTER (WHERE ss1.nid = 'UNKNOWN')::smallint seat_unknown_count,
count(*) FILTER (WHERE ss1.id IS NULL)::smallint seat_unmapped_count,
count(*) FILTER (WHERE ss1.nid IN ('BLOCKED', 'BROKEN', 'HOUSE', 'SOLD', 'UNKNOWN')) seat_unavailable_count
FROM event e1
LEFT JOIN event_seat_state_change essc1 ON essc1.event_id = e1.id
LEFT JOIN event_seat_state_change_seat_state esscss1 ON esscss1.event_seat_state_change_id = essc1.id
LEFT JOIN cinema_foreign_seat_state fcss1 ON fcss1.id = cinema_foreign_seat_state_id
LEFT JOIN seat_state ss1 ON ss1.id = fcss1.seat_state_id
WHERE
essc1.id IN (
SELECT id
FROM event_seat_state_change
WHERE
materialized_at IS NULL
ORDER BY materialized_at DESC
LIMIT 100
)
GROUP BY essc1.id
)
UPDATE event_seat_state_change essc1
SET
materialized_at = now(),
seat_count = essc2.seat_count,
seat_blocked_count = essc2.seat_blocked_count,
seat_broken_count = essc2.seat_broken_count,
seat_empty_count = essc2.seat_empty_count,
seat_house_count = essc2.seat_house_count,
seat_sold_count = essc2.seat_sold_count,
seat_unknown_count = essc2.seat_unknown_count,
seat_unmapped_count = essc2.seat_unmapped_count
FROM event_seat_state_count essc2
WHERE
essc1.id = essc2.id;
END
$$
LANGUAGE plpgsql
SET work_mem='1GB'
SET max_parallel_workers_per_gather=4;
同样,这需要编写一个定制的解决方案来观察表并管理它们的物化、行和列过期逻辑等。我目前正在开发一个开源版本,并计划在不久的将来发布。
这种方法最大的好处是,你可以尽可能细粒度更新物化表列:你可以更新单个行和更新单个列(例如当新的物化列添加,需要填充新列值,您只需要生成列的值;不需要运行完整的物化查询)。此外,由于更新是细粒度的,它们都可以在接近实时的情况下应用。
要点
这里的要点是,PostgreSQL物化视图对于小型数据集是一个很好的特性。但是,随着数据集的增长,需要仔细规划如何访问数据,以及什么物化策略支持这样的需求。通过使用细粒度物化视图和物化表列的组合,我们能够实时地丰富数据库,并将其用于所有的分析查询,而不会增加数据仓库逻辑复制的复杂性。
使用数据库作为作业队列
这与我们处理的数据量无关,更多的是与我们如何使用数据库有关。如前所述,我的目标是减少参与数据处理管道的服务数量。在数据库中包含作业队列的额外好处是,您可以保存和查询与数据库中的每个数据点关联的所有作业(及其属性)的记录。能够查询与每个数据点相关联的作业和日志,将其与父作业和子代作业连接,等等,这对于标记失败的作业和确定问题的根源非常有价值。

使用PostgreSQL构建一个简单、可靠、高效的并发工作队列。
值得注意的是,对于并发任务队列,RDBMs通常不是一个好的选择(原因在What is SKIP LOCKED for in PostgreSQL 9.5?)然而,对于PostgreSQL,我们可以使用UPDATE…SKIP LOCKED来构建一个简单、可靠、高效的并发工作队列。缺点是性能:
每个事务都扫描表并跳过锁定的行,因此对于大量的活动工作者,它可以执行一些工作来获取新项。它不仅仅是从堆栈中取出项目。查询可能必须通过索引扫描遍历索引,从堆中获取每个候选项并检查锁状态。对于任何合理的队列,它都将在内存中,但仍有一些混乱。
——https://blog.2ndquadrant.com/what-is-select-skip-locked-for-in-postgres…
我没有对这个警告给予足够的重视,给自己惹了不少麻烦。
简短的版本是,用于调度作业的查询的第一个版本执行时间很长,这意味着工作节点主要处于空闲状态,我们在浪费宝贵的资源,重要的任务没有及时完成。
解决方案非常简单:用一个未完成任务列表填充一个专用表。从这张桌子上拿起一份工作非常简单:
CREATE OR REPLACE FUNCTION schedule_cinema_data_task()
RETURNS table(cinema_data_task_id int)
AS $$
DECLARE
scheduled_cinema_data_task_id int;
BEGIN
UPDATE
cinema_data_task_queue
SET
attempted_at = now()
WHERE
id = (
SELECT cdtq1.id
FROM cinema_data_task_queue cdtq1
WHERE cdtq1.attempted_at IS NULL
ORDER BY cdtq1.id ASC
LIMIT 1
FOR UPDATE OF cdtq1 SKIP LOCKED
)
RETURNING cinema_data_task_queue.cinema_data_task_id
INTO scheduled_cinema_data_task_id;
UPDATE cinema_data_task
SET last_attempted_at = now()
WHERE id = scheduled_cinema_data_task_id;
RETURN QUERY SELECT scheduled_cinema_data_task_id;
END
$$
LANGUAGE plpgsql
SET work_mem='100MB';
主任务定义存储在cinema_data_task中。cinema_data_task_queue仅用于排队准备执行任务。
最大的问题是,每次执行新任务时,可以运行的任务的优先级和限制都会改变。因此,我们不是调度大量的作业,而是每隔一秒运行一个进程,检查队列是否已经干了,然后用新任务填充它。
CREATE OR REPLACE FUNCTION update_cinema_data_task_queue()
RETURNS void
AS $$
DECLARE
outstanding_task_count int;
BEGIN
SELECT count(*)
FROM cinema_data_task_queue
WHERE attempted_at IS NULL
INTO outstanding_task_count;IF outstanding_task_count < 100 THEN
INSERT INTO cinema_data_task_queue (cinema_data_task_id)
SELECT
cdtq1.cinema_data_task_id
FROM cinema_data_task_queue(100, 50, 100, false) cdtq1
WHERE
NOT EXISTS (
SELECT 1
FROM cinema_data_task_queue
WHERE
cinema_data_task_id = cdtq1.cinema_data_task_id AND
attempted_at IS NULL
)
ON CONFLICT (cinema_data_task_id) WHERE attempted_at IS NULL
DO NOTHING;
END IF;
END
$$
LANGUAGE plpgsql
SET work_mem='50MB';任务完成后,对任务的引用将从cinema_data_task_queue中删除。这确保了表扫描是快速的,并且不会让CPU繁忙。
这种方法允许我们扩展到2000多个并发数据聚合代理。
注意:100个未完成任务的限制有些随意。我尝试过使用大到10k的值,但没有任何可测量的性能损失。然而,只要我们能保持队列不干涸,那么调度的粒度越细,我们就能更好地在不同的数据源之间进行负载平衡数据聚合,就能越快地停止从失败的数据源提取数据,等等。
收获
如果要使用database作为作业队列,则包含作业的表的大小必须合理,用于调度下一个作业执行的查询所花费的时间不得超过几毫秒。
misc
在扩展数据库时,这三件事是最大的挑战。其他一些问题包括:
- 当你有数百个客户端每秒钟运行几十个查询时,数据库和数据库客户端之间的延迟就会变得很重要。我观察到我们在AWS RDS上的数据库(当时)和在GKE上的Kubernetes集群之间的延迟是12ms。通过将数据库移动到相同的数据中心并将延迟降低到1毫秒,我们的任务增加了4倍。
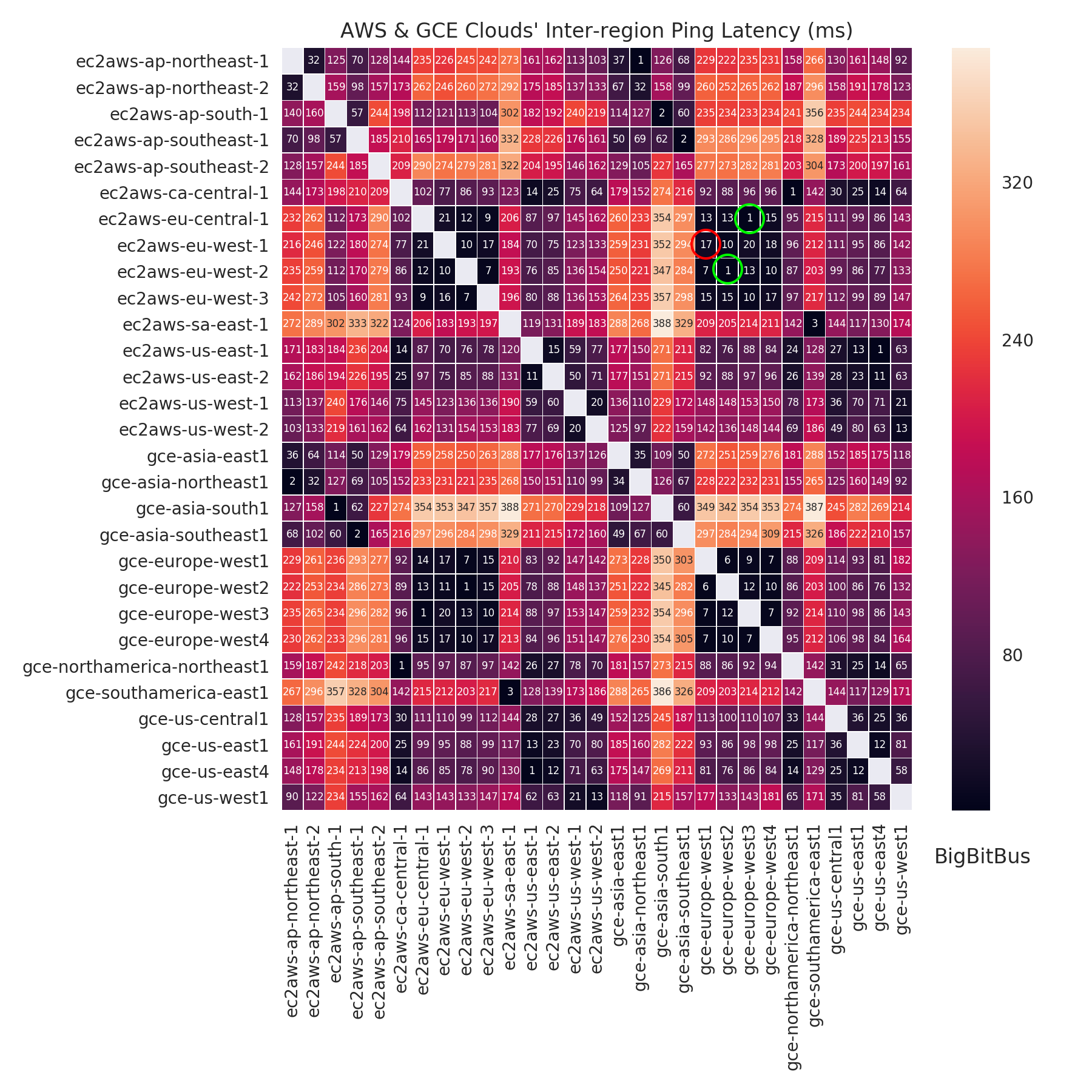
识别不同云提供商之间的延迟。
- 列顺序很重要。我们有60多列的表。排序列以避免填充节省了20%以上的存储空间(https://blog.2ndquadrant.com/onrocks-and sand/)。
- 如果要在master上运行长时间查询,请对vacuum_freeze_table_age进行评估,以防止表膨胀。
- 我认为有两种配置没有被充分讨论:from_collapse_limit和join_collapse_limit。这两种配置的默认值都是8。不知道这些配置会导致很多调试混乱的执行计划。我们从_collapse_limit增加到20,join_collapse_limit增加到50。我不清楚违约率低的原因是什么。让它们无限高似乎没有什么惩罚。
- 为表格膨胀和如何修复做好计划。随着数据库变得越来越大,真空填充变得不可行的。探索pg_repack和pg_squeeze。
- 持续监视pg_stat_statements。total_time排序。最热门的查询是容易实现的结果。
- 不断地监控pg_stat_user_tables。识别未充分使用的索引并监视死元组的积累。
- 持续监视pg_stat_activity。识别由于锁造成的瓶颈,并重构出错的事务。
额外奖励:Slonik PostgreSQL客户端
我们经常使用PostgreSQL。我们一开始用的是node-postgres。node-postgres提供了一个很好的协议抽象。但是,代码感觉很冗长,我们不断添加新的助手来抽象重复的模式,并提供调试体验。我们在许多不同的项目中都需要这些助手。因此,我最终开发了Slonik—一个具有严格类型、详细日志记录和断言的PostgreSQL客户端。
Slonik帮助我们保持代码精简,防止SQL注入,通过auto_explain支持详细日志记录和应用程序日志关联。
本文:http://jiagoushi.pro/node/1177
讨论:请加入知识星球【首席架构师圈】或者小号【jiagoushi_pro】
- 登录 发表评论
- 219 次浏览
最新内容
- 6 days 14 hours ago
- 1 week 3 days ago
- 1 month 4 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago
- 5 months 3 weeks ago